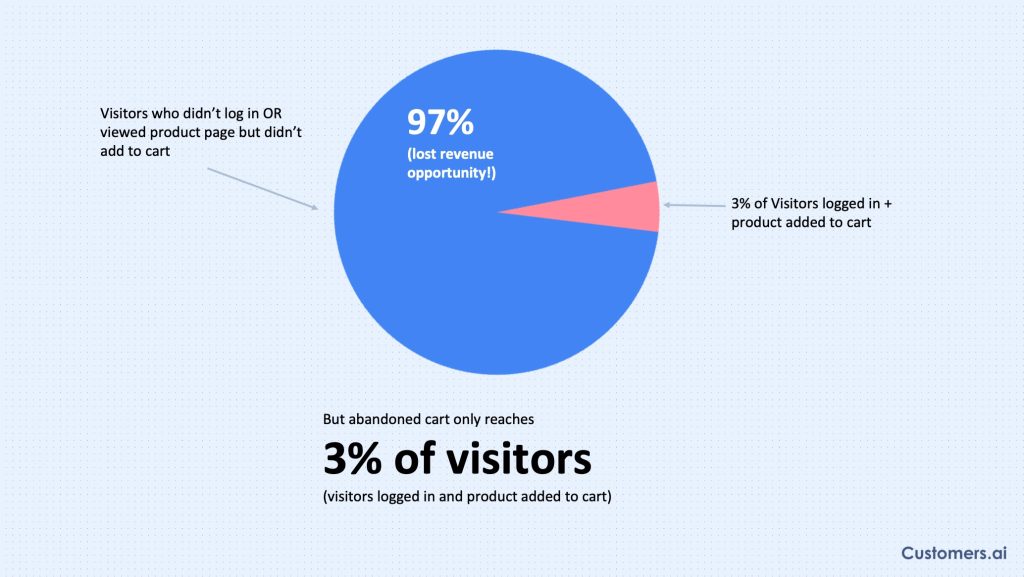
In the world of B2B sales, reaching your target audience has become a bit like finding a needle in a haystack.
It’s a challenge, and with the recent email spam filter updates from the likes of Google and Yahoo, getting into those coveted inboxes is becoming even trickier.
It’s why we launched B2B by Customers.ai. For years, B2B sales teams have relied on tools like Demandbase, ZoomInfo, and Clearbit to identify who has visited their site. The problem as most people know – is these tools identify the companies visiting you. But companies are not buying from you – people are!
And now, Customers.ai bridges that gap. We can tell you who is visiting your site at the individual level, giving you names, business emails, Linkedin profiles, and more!
It’s a true game changer and we are excited to see just how fast B2B sales teams can improve their outreach efforts.
We aren’t done helping yet though. Along with the launch of our B2B solution, we are going to dive deep into the dynamic landscape of B2B outbound sales, unpacking the challenges, and serving up actionable strategies to help your sales team not just survive but thrive in this inbox battleground. Let’s do it!
What is B2B Outbound Sales?
Challenges in B2B Outbound Sales
5 Strategies for Highly Targeted B2B Sales Outreach
How to Do B2B Outbound Sales with Customers.ai
B2B Outbound Sales FAQs
What is B2B Outbound Sales?
To start, we have to understand what B2B outbound sales means:
B2B outbound sales, short for Business-to-Business outbound sales, is a proactive approach where businesses initiate direct communication with potential customers to generate leads and close deals.
Unlike inbound strategies that rely on attracting prospects organically, outbound sales involve reaching out to a carefully identified target audience through channels like email, phone calls, and social media.
The goal is to create meaningful connections, understand customer needs, and showcase how a product or service can address those needs.
Some sales pros use outbound sales and cold outreach interchangeably. But they aren’t quite the same.
Cold outreach refers to connecting with truly cold leads, or potential customers who haven’t interacted with your business before.
Outbound sales can refer to reaching out to prospects who have shown intent—by visiting your website or interacting with your social media content.
See Who Is On Your Site Right Now!
Turn anonymous visitors into genuine contacts.
Try it Free, No Credit Card Required
Get The X-Ray Pixel
Challenges in B2B Outbound Sales
We know that B2B buyers rely on email to make purchasing decisions. In fact, according to MarketingCharts, 41% say they use email to source information. Unfortunately, with the average person receiving over 100 emails per day, getting your email to stand out is no easy feat.
Getting in the inbox isn’t the only challenge facing B2B sales teams though. Let’s look at the current landscape and common challenges we are seeing and how Customers.ai can help overcome these challenges.
1. Identifying the Right Prospects
Who are your prospects? Challenges arise in the initial phase of B2B outbound sales when identifying the right prospects. Defining your Ideal Customer Profile (ICP) is crucial, as it provides a clear blueprint of your target audience’s characteristics and needs.
How Customers.ai Can Help:
Our Website Visitor ID X-Ray pixel tells you who is on your site, helping you identify the right prospects.
By capturing real-time data on website visitors, you can see who is visiting your site, what they are interested in, and tailor your outreach strategies based on genuine insights into their behavior and preferences.
It’s like having a personal detective for your website, revealing the clues that lead straight to your most promising leads.
To install the Website Visitor ID X-Ray Pixel, sign up (for FREE!), go to your dashboard, and navigate to My Automations.
Select + New Automation and get your pixel. We have easy install options for Google Tag Manager, WordPress, and Shopify, or you can install the pixel manually.
2. Building and Maintaining a High-Quality Contact List
Ensuring a high-quality contact list is a perpetual challenge in B2B outbound sales. Strategies for data hygiene play a pivotal role, involving regular cleansing to eliminate outdated or irrelevant contacts.
Furthermore, leveraging CRM tools for contact management streamlines the process, offering functionalities for segmentation, personalization, and efficient list maintenance.
How Customers.ai Can Help:
With our Signs of Life Detector, we automatically know if an email is valid, ensuring you aren’t wasting time on the wrong people.
Additionally, Customers.ai integrates with your CRM, offering seamless contact management, segmentation, and personalization, making it the go-to ally for keeping your contact list not just extensive, but exceptionally high-quality.
3. Crafting Compelling Outreach Messages
Crafting messages that resonate with your target audience is a persistent challenge in B2B sales outreach.
Tailoring messages to specific industries or personas demonstrates a deep understanding of the recipient’s context, while A/B testing for message optimization allows for continuous improvement by experimenting with different elements such as subject lines and content.
How Customers.ai Can Help:
Customers.ai makes outreach easy – the key is our AI email writer.
Tailoring messages to specific industries or personas becomes a breeze as AI Email Writer understands the nuances and preferences of your target audience and can inject a personalized touch based on the information captured.
It’s like having a virtual wordsmith that not only understands your audience but also knows the exact words that will capture their attention.
4. Avoiding Promotions Tabs & Spam Folders
With the ever-evolving algorithms of email providers, the challenge extends to avoiding promotions tabs and spam folders. Staying out of these sections requires meticulous attention to email content relevance and adherence to best practices.
Encouraging recipients to whitelist your emails is an additional proactive step to improve deliverability.
How Customers.ai Can Help:
By exclusively targeting individuals who have actively engaged with your site, we ensure that your emails enter inboxes as warm messages.
This tailored approach not only enhances deliverability but also mitigates the risk of being marked as spam. Coupled with strong personalization, your communications should not only reach your audience but also grab their attention in the best way possible.
5. Navigating Gatekeepers and Overcoming Objections
Gatekeepers can be formidable barriers in B2B outbound sales, necessitating techniques for engaging gatekeepers effectively.
Strategies that establish a connection and convey the value of your outreach can prove instrumental.
Simultaneously, addressing objections is an inherent part of the process, and addressing common objections effectively involves anticipating and preparing persuasive responses that transform objections into opportunities for meaningful engagement.
How Customers.ai Can Help:
Customers.ai helps navigate gatekeepers and overcome objections by providing a unique advantage—insight into exactly what pages your prospects have visited.
With this powerful feature, segmentation becomes more than just a strategy; it becomes a precision tool.
By tailoring your outreach to resonate with the specific products or services your prospects have shown interest in, you’re not just navigating gatekeepers, you’re opening doors.
Convert Website Visitors into Real Contacts!
Identify who is visiting your site with name, email and more. Get 50 contacts for free!
Please enable JavaScript in your browser to complete this form.Website / URL *Grade my website
5 Strategies for Highly Targeted B2B Sales Outreach
You will always face challenges but having a toolkit of highly targeted outreach strategies isn’t just an advantage—it’s a necessity. Here are five strategies to help you cut through the noise, connect with the right prospects, and elevate your outreach game.
1. Segmentation and Personalization
Segmenting your audience is imperative when it comes to sales outreach. By categorizing your audience based on shared characteristics or behaviors, you can tailor your messages to be more relevant and impactful. This not only boosts engagement but also allows for a more strategic allocation of resources, ensuring your efforts are laser-focused on the right targets.
It also lends to personalization. Personalization goes beyond just addressing someone by their first name. Use the data you have to craft messages that resonate with their specific interests, pain points, or product preferences, creating a connection that feels not just personalized but genuinely tailored to their needs.
2. Multi-Channel Outreach Approach
We mentioned earlier that 41% of people rely on email to get content. Those same people also rely on social media, internet searches, and publications for information. A holistic approach to outreach is a must.
A multi-channel strategy ensures that your message reaches your audience through their preferred platforms, maximizing the chances of engagement. Plus, by diversifying your communication channels, you amplify your outreach efforts and meet your prospects where they are.
But remember, consistency is key. Make sure that your messaging across email, phone, and social media aligns seamlessly, creating a unified brand voice. This not only strengthens your brand identity but also enhances the overall customer experience, fostering trust and recognition across various touchpoints.
3. Content Marketing Integration
Content is how you capture your audience’s attention. By understanding the topics and products that resonate with your prospects, you can create content that not only educates but also adds value to their decision-making process. It positions you as an authority in your industry and makes your outreach more compelling.
However, it can feel like content marketing efforts aren’t always aligned with outreach efforts. Content is a powerful ally in your outreach journey.
Use the data you have to create personalized email campaigns or targeted social media messaging. Aligning your content with your outreach efforts enhances engagement and reinforces the value you offer.
4. Utilizing Technology and Automation
Two of the biggest challenges facing any organization are resources and time. You have to build something that is scalable.
Automation tools help you handle repetitive tasks, allowing your team to focus on building genuine connections. From email campaigns to lead scoring, these tools revolutionize how you approach outbound sales.
While automation brings efficiency, maintaining personalization is paramount. Customers.ai ensures that your automated outreach retains a human touch by incorporating personalization features. Whether it’s dynamically adjusting email content based on prospect behavior or timing outreach for maximum impact, our best practices keep your automated efforts personalized and effective.
5. Continuous Monitoring and Iteration
Perpetual improvement in your outbound sales strategy can only be done through continuous monitoring. Utilize real-time analytics and tracking tools to keep a finger on the pulse of your campaigns. This proactive approach allows you to spot trends, identify successful strategies, and promptly address any areas that may need adjustment.
You also can’t stay stagnant. Iterate based on results for ongoing enhancement. Use the insights gained from monitoring key performance indicators to adapt and improve on your outreach strategies.
Whether it’s refining your messaging, adjusting target segments, or experimenting with different channels, a commitment to ongoing enhancement ensures your outreach efforts remain agile and effective in the ever-evolving landscape of B2B sales.
Email Deliverability Hacks:
Unlocking Inboxes
HOSTED BY
Larry Kim
Founder and CEO, Customers.ai
Free Webinar: Watch Now
How to Do B2B Outbound Sales with Customers.ai
To excel at outbound sales, you need an automated process and powerful tools. We’ll show you how to set up a solid sales strategy with Customers.ai.
Step #1: Know Your Ideal Customer
You could spend time cold emailing a huge list of prospects who may or may not be a good fit for your offer. But you’re probably going to waste a ton of time chatting with donkey leads.
Instead, focus on connecting with your target audience. That starts with knowing your ideal customer. Grab your buyer persona and make a note of:
Demographics, including age, gender, and location
Interests and behaviors that define your customers
Problems and challenges your customers deal with
How your solution can help potential customers
As we mentioned earlier, install the Website Visitor ID X-Ray Pixel and start gathering data on your website visitors.
See Who Is On Your Site Right Now!
Turn anonymous visitors into genuine contacts.
Try it Free, No Credit Card Required
Get The X-Ray Pixel
Step #2: Fine-Tune Your Prospect List
Now you know exactly who you’re looking for—but you’re going to need a hand finding those prospects. Along with identifying who is on your site, you can also find prospects who fit your ICP through our Consumer Directory.
Consumer directory is our lead database of over 250,000,000 consumers in the United States. Filter, search, and purchase consumer directory leads and add them to a custom outreach automation to qualify and close leads.
Once you’ve identified the best prospects for you, you can plug their contact information right into your existing campaigns or build new ones.
Step #3: Warm Up Email Accounts
You’re almost ready to start sending targeted outbound outreach. But before you start reaching out to prospects, it’s important to warm up your email address.
Customers.ai has a built-in email warmup tool. All you have to do is click Integrations to link all the email addresses you want to use for outreach.
Not sure how many to add? If you’re using new email accounts, keep in mind that you probably shouldn’t send more than 100 emails from each account per day.
Once you connect your email addresses, click the Configure Sending button in your automation. Select Multiple Emails to give Customers.ai permission to rotate senders.
Step #4: Send Outbound Outreach
Then open the email template at the top of the automation and write your first outreach message. This is a great opportunity to introduce your business, product, or service and offer something of value. To make your message sound more natural, use Customers.ai’s AI Email Writer.
Once you have your message, configure the waiting period before the next message, and so on and so forth.
Continue to add email follow-ups to your automation and use your sales team’s benchmarks to decide on the right number of follow-ups for your list.
Superpower Your B2B Outbound Sales Efforts
In the dynamic realm of B2B sales, the challenges are real and the competition fierce. The recent email spam filter updates from industry giants like Google and Yahoo have added an extra layer of complexity, making inbox visibility an even trickier feat.
That’s why we introduced B2B by Customers.ai. Traditional tools identify companies visiting your site, but we understand that people make the decisions. With our Website Visitor ID X-Ray pixel, we bridge the gap, providing individual-level insights into your site visitors—names, business emails, LinkedIn profiles, and more.
But we’re not stopping there. As we launch our B2B solution, we’re delving deep into the intricacies of B2B outbound sales, unraveling challenges, and serving up actionable strategies. In this inbox battleground, survival is not enough; thriving is the goal.
B2B outbound sales is not just about sending emails; it’s about sending the right emails to the right people. Whether it’s identifying the right prospects, building a high-quality contact list, crafting compelling messages, avoiding spam folders, or navigating gatekeepers, Customers.ai is your ally in this journey.
Ready to transform your B2B outbound sales game? Let’s do it together. Explore B2B by Customers.ai now and unlock a new era of precision and effectiveness in your outreach efforts.
Important Next Steps
See what targeted outbound marketing is all about. Capture and engage your first 50 website visitor leads with Customers.ai X-Ray website visitor identification for free.
Talk and learn about sales outreach automation with other growth enthusiasts. Join Customers.ai Island, our Facebook group of 40K marketers and entrepreneurs who are ready to support you.
Advance your marketing performance with Sales Outreach School, a free tutorial and training area for sales pros and marketers.
Convert Website Visitors into Real Contacts!
Identify who is visiting your site with name, email and more. Get 50 contacts for free!
Please enable JavaScript in your browser to complete this form.Website / URL *Grade my website
B2B Outbound Sales FAQs
Q. What’s the difference between inbound and outbound sales?
Whether you’re using inbound or outbound tactics, you have the same end goal: to close the deal. But the way you start and nurture relationships with prospects differs, depending on which approach you choose.
With inbound, prospects find the organization through social media, the company website, or another marketing channel. They request information or sign up for a list and receive a series of general marketing campaigns.
With outbound, sales reps use one of the channels above to initiate a connection with a potential customer. Sales reps typically tailor their offers for customer segments so they appeal to prospects’ unique needs and challenges.
Because outbound is more targeted, it tends to have a lower signal-to-noise ratio—as long as you’re reaching out to the right prospects. That means outbound is ideal for finding unicorns in a sea of donkeys.
Q. What are the most effective outbound channels?
It’s easy to assume that outbound sales is all about cold calling. But in practice, phone calls often work best at the end of the sales process, when hot leads are ready to hear your pitch.
Let’s look at a few of the best places to reach out to outbound leads:
Email outreach is the ideal channel to start with since it’s great for introducing your business and offering something of value. With email, you can continue to connect with prospects over time, increasing trust and sharing solutions.
SMS outreach is ideal for prospects who are closer to completing their customer journeys. Because SMS inboxes are private spaces for your inner circle, it’s a good idea to build trust first before connecting with prospects over text.
Social selling via channels like Facebook and Instagram is helpful for building relationships and engaging with leads. Once potential customers show intent by commenting or sending a DM, you can shift the conversation to email or text.
Q. Who does outbound sales?
A successful sales team typically needs three types of representatives:
Sales development reps (SDRs) handle the first few steps of the sales process. They generate leads and then nurture and qualify them before handing them over to an account executive.
Business development reps (BDRs) are experts at prospecting and finding potential customers who fit the target audience. They excel at lead generation—turning cold prospects into warm leads and so account executives can get the sale.
Lead response reps (LRRs) often focus on higher-intent prospects who have indicated interest in the business. Like SDRs, they nurture and qualify leads before tasking the account executive with closing the deal.
Q. What are the best outbound sales tools?
To close more deals, sales teams need tools that automate manual tasks and organize prospects:
Prospecting data tools connect you with your ideal customers so you can focus on building relationships. Tools like Customers.ai RoboBDR let you create customer segments for targeted sales outreach.
Outreach automation tools send targeted messages to prospect lists and follow up on key channels over time. Tools like Customers.ai automate email, SMS, and social media sequences to streamline prospecting and lead qualification.
Customer relationship management (CRM) tools keep track of prospects and touchpoints so you know where everyone is in their customer journey. CRMs like HubSpot integrate with Customers.ai so you can streamline your efforts.
Q: What is the difference between B2B outbound sales and cold outreach?
Cold outreach involves contacting entirely new leads, while B2B outbound sales may include reaching out to prospects who have shown some level of interest or intent.
Q. How can I identify the right prospects for my B2B outbound sales efforts?
Define your Ideal Customer Profile (ICP) and leverage tools like Customers.ai’s Website Visitor ID X-Ray pixel to see who is actively engaging with your site.
Q: What challenges do B2B sales teams face in reaching their target audience via email?
Email saturation is a challenge, with the average person receiving over 100 emails per day. Standing out in crowded inboxes requires strategic and personalized messaging.
Q: How does segmentation and personalization enhance B2B sales outreach?
Segmentation categorizes your audience, allowing you to tailor messages for relevance. Personalization goes beyond names, crafting messages that resonate with specific interests or pain points.
Q: What role does multi-channel outreach play in B2B sales strategies?
Multi-channel outreach ensures your message reaches prospects through preferred platforms, enhancing engagement. Consistent messaging across channels builds brand trust.
Q: Why is content marketing integration crucial for B2B outbound sales?
Content marketing adds value to the customer’s decision-making process. Aligning content with outreach efforts positions your brand as an industry authority.
Q: How can technology and automation improve B2B outbound sales efficiency?
Automation tools handle repetitive tasks, optimizing resource use. Customers.ai’s automation retains a personalized touch, balancing efficiency with genuine connections.
Q: What are the benefits of continuous monitoring and iteration in outbound sales?
Continuous monitoring allows real-time adjustments, spotting trends and addressing issues promptly. Iteration based on results ensures ongoing enhancement and adaptation to market dynamics.
Q: How does Customers.ai help navigate gatekeepers and overcome objections?
Customers.ai provides insights into pages prospects visited, enabling precise segmentation. This tailoring of outreach to specific interests transforms objections into opportunities.
Q: Can B2B outbound sales be successful without an automated process?
While possible, an automated process, as offered by Customers.ai, streamlines tasks, saves time, and ensures scalability, making success more achievable in the competitive B2B landscape.
Q: Why is email deliverability crucial in B2B outbound sales?
Email deliverability determines whether your messages reach the intended inboxes. Customers.ai’s warm-up tools and targeted engagement contribute to improved deliverability.
Q: How does B2B outbound sales contribute to building a brand’s authority?
B2B outbound sales positions your brand as an industry expert by delivering valuable content and personalized messages, fostering trust and credibility among your target audience.
Q: What role does predictive analytics play in B2B outbound sales strategies?
Predictive analytics analyzes historical data to forecast outcomes and behaviors. Customers.ai integrates predictive analytics, helping make informed decisions and optimize resources.
Q: Can B2B outbound sales efforts be successful without continuous audience monitoring?
Continuous monitoring is vital for staying agile. It allows for real-time adjustments and ensures your outreach efforts align with changing customer behaviors and market dynamics.
Q: How does B2B outbound sales adapt to changes in customer preferences and behaviors?
Iteration based on continuous monitoring and data-driven insights ensures B2B outbound sales strategies evolve to meet changing customer preferences and behaviors effectively.
Q: What challenges does B2B outbound sales face in the era of information overload?
Standing out in a sea of information is a challenge. Crafting personalized and compelling messages, as well as utilizing targeted segmentation, helps overcome information overload.
Q: How does B2B outbound sales contribute to lead generation and conversion?
B2B outbound sales actively generates leads by initiating direct communication. Effective lead generation, combined with personalized outreach, contributes to higher conversion rates.
Q: Is there a limit to the number of follow-ups in B2B outbound sales campaigns?
The number of follow-ups depends on your industry and target audience. Test and adapt based on your specific benchmarks to find the optimal number for your campaigns.
Q: How does B2B outbound sales address the balance between automation and personalization?
B2B outbound sales tools like Customers.ai strike a balance by automating repetitive tasks while ensuring personalization features retain a human touch in outreach efforts.
Q: Can B2B outbound sales strategies be effective without a deep understanding of the target audience?
Deep understanding of the target audience is foundational. Identifying buyer personas, preferences, and pain points ensures B2B outbound sales strategies resonate and drive meaningful engagement.
The post B2B Outbound Sales: Your Guide to Highly Targeted Outreach appeared first on Customers.ai.