- info@i-genie.co.uk
- 0207 148 4785
In the rapidly advancing era of Artificial Intelligence, the introduction of Large Language Models (LLMs) has transformed the way machines and humans interact with each other. Recent months have seen an exponential increase in the number of LLMs developed, with incredible capabilities and super-advanced algorithms. Models like GPT 3.5, GPT 4, LLaMa, PaLM, etc., have demonstrated some exceptional human-imitating abilities in Natural Language Understanding (NLU), processing, translation, summarization, and even content generation.
These LLMs are trained on massive amounts of data. However, there comes a challenge when these models have to adjust to new datasets. Researchers usually face issues when adapting these massive LLMs to new datasets, as full fine-tuning has a number of expenses and memory requirements. In order to address the issue of memory efficiency in LLM fine-tuning, recently, a team of researchers has presented the idea of parameter-efficient fine-tuning methods.
By learning a smaller, fine-tuned extension to the original pretrained model, these techniques can lower the amount of memory needed for fine-tuning. Low-Rank Adaptation (LoRA), which is a well-liked strategy for effective LLM adaptation, involves re-parametrizing the weight matrix of the pretrained model and fine-tuning only two of its components, i.e., L1 and L2. The remaining components remain unchanged.
Researchers have enhanced the memory efficiency of LoRA by applying it to a quantized pre-trained model. In order to conserve memory, quantization decreases the model’s parameter precision, and if the quantization is significant, zero initialization may not be optimal. To overcome the quantization error, the team has introduced a variant of LoRA called LQ-LoRA.
LQ-LoRA breaks down the weight matrix into a quantized component, Q, and a low-rank component, L1L2, using an iterative technique influenced by the Principal Component Analysis (PCA). In LQ-LoRa, L1 and L2 are refined during adaptation, and the high-variance subspaces of the initial weight matrix are captured.
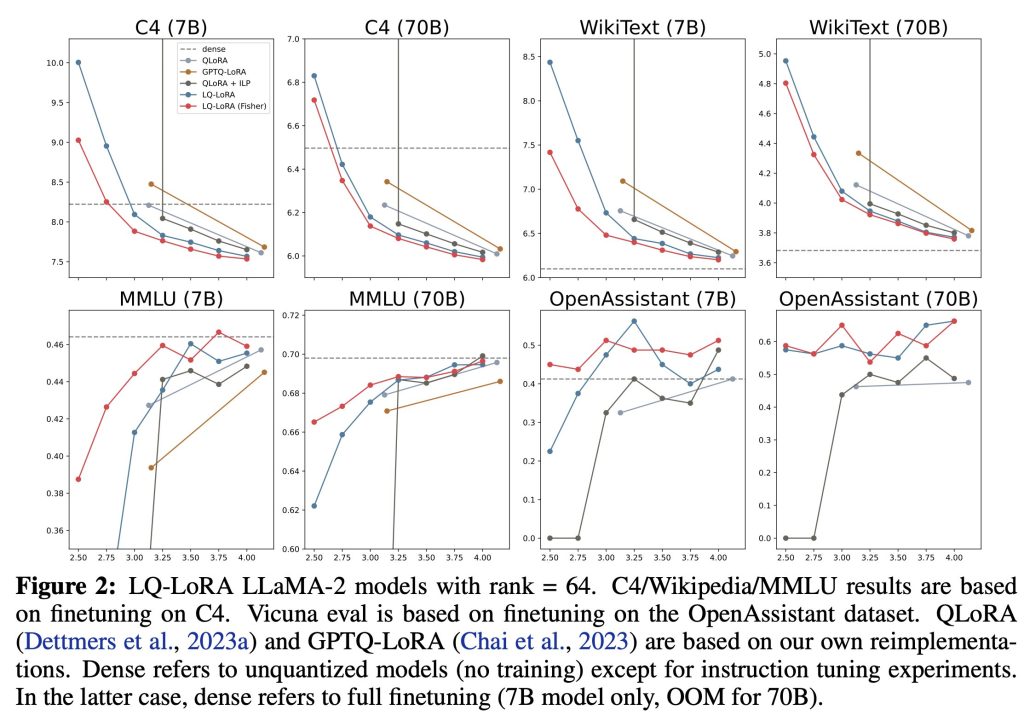
The team has shared that this work uses integer linear programming to find a mixed quantization method to solve the problem of applying the same quantization configuration to all layers. Given an overall desired bit rate, this technique permits assigning various configurations, including bits and block size, to each matrix.
The team has modified RoBERTa and LLaMA-2 models of varying sizes, 7B and 70B, using LQ-LoRA. The findings have shown that LQ-LoRA performs better than GPTQ-LoRA and strong QLoRA baselines. The ability to train a 2.5-bit LLaMA-2 model on the OpenAssistant benchmark, which is competitive with a model fine-tuned using 4-bit QLoRA, has shown that the suggested approach allows for more aggressive quantization.
LQ-LoRA has also shown great performance in model compression after being adjusted on a dataset-calibrating language model. Despite the decreased bit rate, the team was able to produce a 2.75-bit LLaMA-2-70B model that is competitive with the original model in complete precision. This indicates that the suggested method may be able to drastically lower the memory needs of big language models without sacrificing functionality for particular activities.
In conclusion, LQ-LoRA is a significant turning point in the development of language models. Its method of memory-efficient adaptation and data-aware considerations, along with dynamic quantization parameter tuning, can definitely lead to a paradigm shift in the field of Artificial Intelligence.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
The post Meet LQ-LoRA: A Variant of LoRA that Allows Low-Rank Quantized Matrix Decomposition for Efficient Language Model Finetuning appeared first on MarkTechPost.