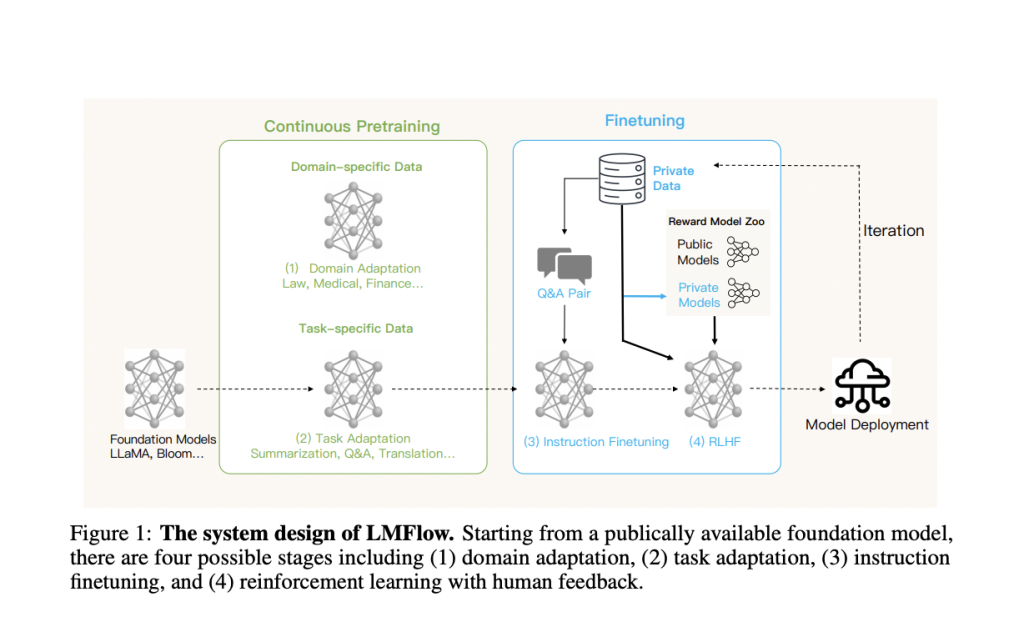
The landscape of many businesses is altering due to artificial intelligence, and picture creation is one area where this is happening significantly. Numerous AI picture generators use artificial intelligence algorithms to turn text into graphics. These AI tools may be a terrific method to visualize your thoughts or notions swiftly in a couple of seconds.
So, Which AI image generator is worth trying? Here are some cool AI image generators available in 2023:
Shutterstock AI Image Generator
Shutterstock AI Image Generator is a game-changer in the world of design. By harnessing the power of AI, users can create truly breathtaking and unique designs with ease. This incredible new feature was made possible through a partnership with OpenAI, which provided the tool with DALL-E 2 technology. What sets this software apart from others is that it was trained with Shutterstock images and data, making the end result a fully licensable image. This breakthrough has huge implications for the art world, as it allows people to use AI-generated art without infringing on the intellectual property rights of others. With ethical artworks ready for download in just seconds, there’s never been a better time to get creative. With Shutterstock’s Free Trial Offer, you can get up to 10 AI-Generated Images for free!
FotorAI Image Generator
The FotorAI Image Generator is a tool that the company offers that creates fresh photographs using Artificial Intelligence (AI) technology. Users can enter a sample image, and it will use that sample to create a brand-new, original image. The new photos claimed to be extremely realistic and of the highest quality, are produced by the feature using a Generative Adversarial Network (GAN). It can be used for many things, including making fresh images for graphic design and digital art. Fotor’s premium version is the only place it can be found.
Nightcafe
Nightcafe is the best AI text-to-image generator, converting keywords into creative and realistic pictures. Using only the most basic English words, you may produce customized graphics that exactly capture your desire. Nightcafe also provides several creatives and styles that can be utilized to create various digital artwork. For example, you can employ neural style transfer to transform commonplace images into artistic creations. Nightcafe’s user-friendly software makes it essentially accessible to beginners. Thanks to the user-friendly and appealing website design, anyone may create and improve images with only one click. You need not consider saving any creation you produce elsewhere because it is forever preserved in your account.
Dream By Wombo
In contrast to other AI picture generators, Dream By Wombo allows for continuous image production without restrictions on its capabilities or cost. This AI generator is a great alternative for individuals who are on a small budget or who are still learning. Additionally, Dream By Wombo is simple to utilize. You must sign up, write a text, and select the style of the image. Once your vision has been generated, you can keep it or start over by choosing a different sort.
DALL-E 2
In 2021, OpenAI published DALL-E 2. A follow-up to OpenAI’s DALL-E image-generating AI model, DALL-E 2, was created. Similar to its predecessor, DALL-E 2 is made to produce high-quality graphics from text prompts. DALL-E 2, on the other hand, has several advantages over the first model, such as a greater capacity that enables it to produce images at a better quality and with more detail. DALL-E 2 can have a wider range of graphics and comprehend and react to more intricate text cues. Additionally, it can be tailored to certain activities or domains, such as creating photographs of particular objects or scenes.
Midjourney
With its extensive features and lightning-fast image synthesis, Midjourney is also one of the greatest AI image generators. Give Midjourney a text prompt, and it will handle the rest. To create the visuals they need as inspiration for their work, many artists employ Midjourney. In a competition for fine art at the Colorado State Fair, the artificial intelligence artwork “Théâtre d’Opéra Spatial,” created with Midjourney, won first place, besting 20 other painters. Midjourney is currently housed on a Discord server, though. You must join MidJourney’s Discord server and use the commands in the bot to generate photos. But that’s simple; you can get going right away.
Dream Studio (Stable Diffusion)
One of the most well-liked text-to-image AI generators is Dream Studio, also known as Stable Diffusion. It is an open-source model that quickly transforms text suggestions into graphics. Dream Studio may produce every picture, including photographs, illustrations, 3D models, and logos. Photorealistic artwork can be created by combining an uploaded photo with a written description.
Craiyon
Craiyon is an intriguing AI picture generator with a website and an app that can be downloaded from the Google Play Store for Android devices. This free service, formerly known as DALL-E Mini, functions similarly to its paid counterpart. From comprehensive written descriptions, you can create photos of reasonably high quality. However, Craiyon is prone to server overload, leading to long creation wait times and regrettable design errors. You may use the photographs for personal and professional purposes, but you must give credit to Craiyon and abide by the usage guidelines outlined in their Terms of Use.
Deep Dream Generator
Deep Dream Generator is recognized for its superb and realistic pictures. Deep Dream Generator is the best option if you’re looking for an AI picture generator that creates visuals based on real-world occurrences. This AI picture generator focuses on making the photos seem from another time or place. It was created by Google researchers to make picture creation easy and accessible to everyone. As a result, even if you lack experience, you may quickly create an image from your words.
Starry AI
Starry AI is one of the leading online providers of text-to-picture AI pictures. You may create photographs with more personalization using its granular tool than with other AI image producers. Starry AI has divided the production of digital art into two stages to make things as easy as possible for its clients. You must choose between Orion and Altair before you can generate a picture. Orion produces visuals that portray fiction, whereas Altair produces images that show abstraction. The following step is picking a background and style for the images you take.
Artbreeder
The original AI image generator Artbreeder combines many images into a single image. Using Artbreeder, you can recreate the pictures in your collection as accurate, entirely new photographs. If you have a secure location to store them, you can receive thousands of unique and eye-catching art drawings on your Artbreeder account. In addition, ArtBreed’s user interface is remarkably simple, making it easy for inexperienced and seasoned graphic artists to use.
Photosonic by Writesonic
A potent AI writing tool called Writesonic also provides a free AI art generator called Photosonic. Using this AI picture generator, you may quickly create digital art from your thoughts. To make an AI image, you can either enter a prompt or use an existing image to generate something new. The latent diffusion model is used by Photosonic, which transforms a random image into a coherent image based on the provided description. Additionally, it supports a variety of art styles, making it simple to locate the one that is ideal for your job.
DeepAI
An AI Text-to-Image generator like this one. Using a word description as a starting point, its AI model can produce original visuals based on stable Diffusion. You can make a limitless amount of original photographs using DeepAI, free to use. Additionally, a developer can connect it to another software project using the free text-to-picture API. However, compared to the other AI picture generators featured on this page, the quality could be more lifelike.
Jasper Art
Jasper Art is a brand-new feature introduced by the AI copywriting tool Jasper. Text is decoded using artificial intelligence, and an image is provided in response. Text can be converted into images using Jasper art. Use Jasper if you’re a business owner, blogger, or content creator looking for a low-cost, user-friendly text-to-picture AI image generator that produces stunning, unique images. So if you need amazing, high-quality photographs for your blog or website, Jasper is a site to check out.
Pixray
Pixray is a versatile text-to-image converter available as an API, browser website, and PC application. Although Pixray has an attractive and straightforward user interface, tech-savvy people will adore its enigmatic changes and distinctive AI engine. When you explore the choices for post-image creation, Pixray really shines. It’s a wonderful tool for shooting images. You can edit your photo aesthetically, convert it to a movie, change the style, and use other tools under the settings section.
BigSleep
One of the most popular and well-known AI picture generators available today is called BigSleep. The explanation is that BigSleep’s powerful software creates real things from nothing. BigSleep produces photos of the highest caliber, but its platform is really simple to use and offers all the tools you need to put your photos together, edit them, and store them securely. Additionally, BigSleep contains a Python-based application that guarantees the speed and smooth operation of the software.
RunwayML
RunwayML offers a video editing feature for altering the background of your photographs when making films. RunwayML creates high-quality images from text input using machine learning models. There are many different image styles available. However, the main focus is employing AI to make animations and edit films. For instance, the program can eliminate the background in videos that don’t utilize green screen technology.
Also, don’t forget to join our Reddit Page, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you have any questions, feel free to message us at Asif@marktechpost.com
The post Best AI Image Generators (July 2023) appeared first on MarkTechPost.