Amazon Bedrock is a fully managed service provided by AWS that offers developers access to foundation models (FMs) and the tools to customize them for specific applications. It allows developers to build and scale generative AI applications using FMs through an API, without managing infrastructure. You can choose from various FMs from Amazon and leading AI startups such as AI21 Labs, Anthropic, Cohere, and Stability AI to find the model that’s best suited for your use case. With the Amazon Bedrock serverless experience, you can quickly get started, easily experiment with FMs, privately customize them with your own data, and seamlessly integrate and deploy them into your applications using AWS tools and capabilities.
Customers are building innovative generative AI applications using Amazon Bedrock APIs using their own proprietary data. When accessing Amazon Bedrock APIs, customers are looking for mechanism to set up a data perimeter without exposing their data to internet so they can mitigate potential threat vectors from internet exposure. The Amazon Bedrock VPC endpoint powered by AWS PrivateLink allows you to establish a private connection between the VPC in your account and the Amazon Bedrock service account. It enables VPC instances to communicate with service resources without the need for public IP addresses.
In this post, we demonstrate how to set up private access on your AWS account to access Amazon Bedrock APIs over VPC endpoints powered by PrivateLink to help you build generative AI applications securely with your own data.
Solution overview
You can use generative AI to develop a diverse range of applications, such as text summarization, content moderation, and other capabilities. When building such generative AI applications using FMs or base models, customers want to generate a response without going over the public internet or based on their proprietary data that may reside in their enterprise databases.
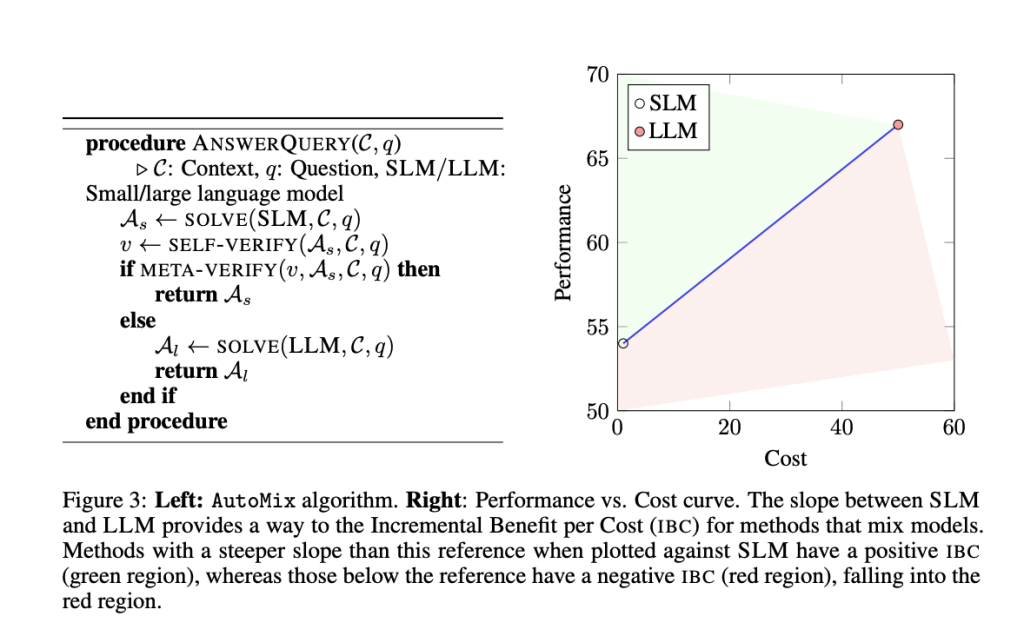
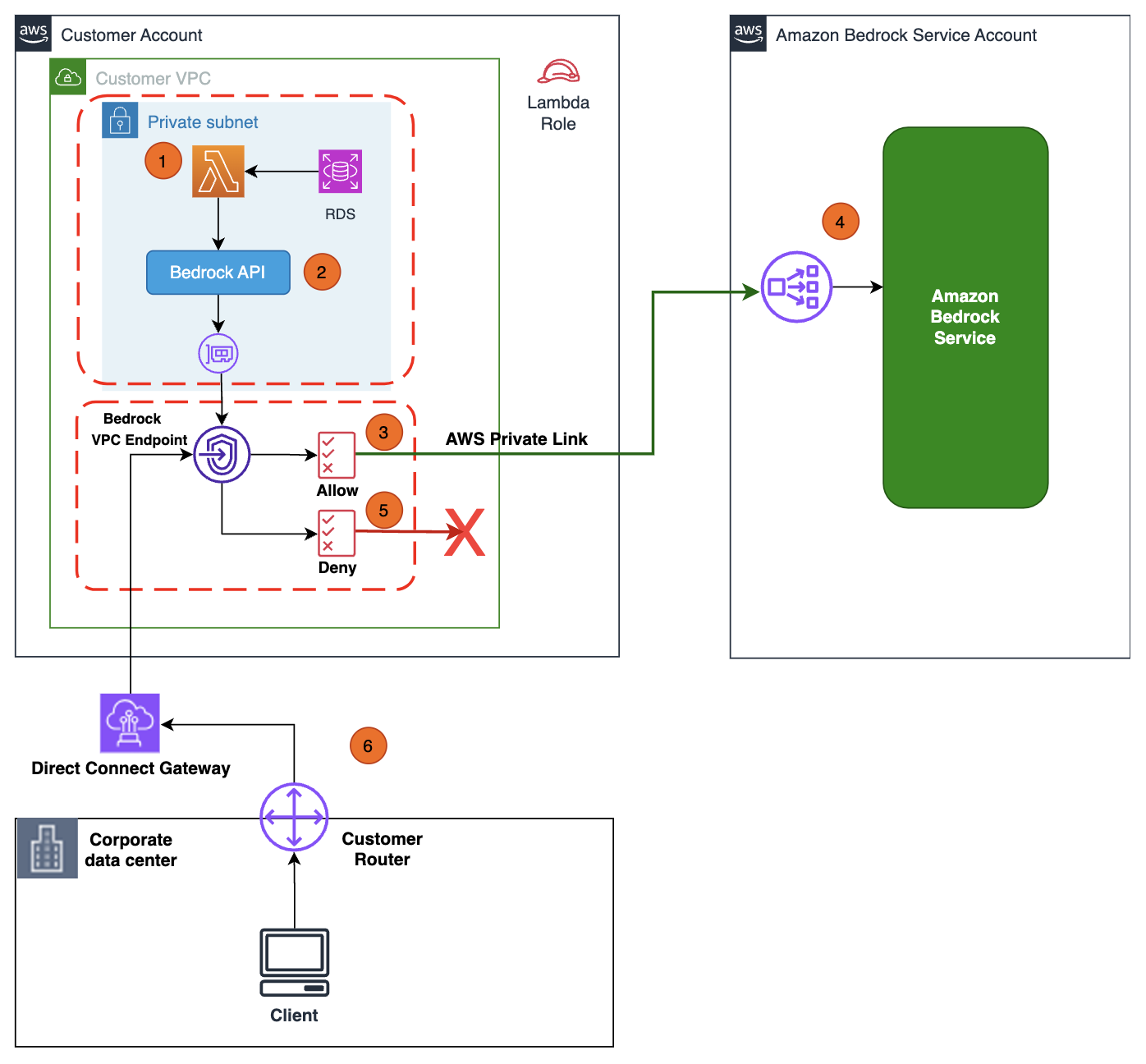
In the following diagram, we depict an architecture to set up your infrastructure to read your proprietary data residing in Amazon Relational Database Service (Amazon RDS) and augment the Amazon Bedrock API request with product information when answering product-related queries from your generative AI application. Although we use Amazon RDS in this diagram for illustration purposes, you can test the private access of the Amazon Bedrock APIs end to end using the instructions provided in this post.
The workflow steps are as follows:
AWS Lambda running in your private VPC subnet receives the prompt request from the generative AI application.
Lambda makes a call to proprietary RDS database and augments the prompt query context (for example, adding product information) and invokes the Amazon Bedrock API with the augmented query request.
The API call is routed to the Amazon Bedrock VPC endpoint that is associated to the VPC endpoint policy with Allow permissions to Amazon Bedrock APIs.
The Amazon Bedrock service API endpoint receives the API request over PrivateLink without traversing the public internet.
You can change the Amazon Bedrock VPC endpoint policy to Deny permissions to validate that Amazon Bedrock APIs calls are denied.
You can also privately access Amazon Bedrock APIs over the VPC endpoint from your corporate network through an AWS Direct Connect gateway.
Prerequisites
Before you get started, make sure you have the following prerequisites:
An AWS account
An AWS Identity and Access Management (IAM) federation role with access to do the following:
Create, edit, view, and delete VPC network resources
Create, edit, view and delete Lambda functions
Create, edit, view and delete IAM roles and policies
List foundation models and invoke the Amazon Bedrock foundation model
For this post, we use the us-east-1 Region
Request foundation model access via the Amazon Bedrock console
Set up the private access infrastructure
In this section, we set up the infrastructure such as VPC, private subnets, security groups, and Lambda function using an AWS CloudFormation template.
Use the following template to create the infrastructure stack Bedrock-GenAI-Stack in your AWS account.
The CloudFormation template creates the following resources on your behalf:
A VPC with two private subnets in separate Availability Zones
Security groups and routing tables
IAM role and policies for use by Lambda, Amazon Bedrock, and Amazon Elastic Compute Cloud (Amazon EC2)
Set up the VPC endpoint for Amazon Bedrock
In this section, we use Amazon Virtual Private Cloud (Amazon VPC) to set up the VPC endpoint for Amazon Bedrock to facilitate private connectivity from your VPC to Amazon Bedrock.
On the Amazon VPC console, under Virtual private cloud in the navigation pane, choose Endpoints.
Choose Create endpoint.
For Name tag, enter bedrock-vpce.
Under Services, search for bedrock-runtime and select com.amazonaws.<region>.bedrock-runtime.
For VPC, specify the VPC Bedrock-GenAI-Project-vpc that you created through the CloudFormation stack in the previous section.
In the Subnets section, and select the Availability Zones and choose the corresponding subnet IDs from the drop-down menu.
For Security groups, select the security group with the group name Bedrock-GenAI-Stack-VPCEndpointSecurityGroup- and description Allow TLS for VPC Endpoint.
A security group acts as a virtual firewall for your instance to control inbound and outbound traffic. Note that this VPC endpoint security group only allows traffic originating from the security group attached to your VPC private subnets, adding a layer of protection.
Choose Create endpoint.
In the Policy section, select Custom and enter the following least privilege policy to ensure only certain actions are allowed on the specified foundation model resource, arn:aws:bedrock:*::foundation-model/anthropic.claude-instant-v1 for a given principal (such as Lambda function IAM role).
{
“Version”: “2012-10-17”,
“Statement”: [
{
“Action”: [
“bedrock:InvokeModel”
],
“Resource”: [
“arn:aws:bedrock:*::foundation-model/anthropic.claude-instant-v1”
],
“Effect”: “Allow”,
“Principal”: {
“AWS”: “arn:aws:iam::<accountid>:role/GenAIStack-Bedrock”
}
}
]
}
It may take up to 2 minutes until the interface endpoint is created and the status changes to Available. You can refresh the page to check the latest status.
Set up the Lambda function over private VPC subnets
Complete the following steps to configure the Lambda function:
On the Lambda console, choose Functions in the navigation pane.
Choose the function gen-ai-lambda-stack-BedrockTestLambdaFunction-XXXXXXXXXXXX.
On the Configuration tab, choose Permissions in the left pane.
Under Execution role¸ choose the link for the role gen-ai-lambda-stack-BedrockTestLambdaFunctionRole-XXXXXXXXXXXX.
You’re redirected to the IAM console.
In the Permissions policies section, choose Add permissions and choose Create inline policy.
On the JSON tab, modify the policy as follows:
{
“Version”: “2012-10-17”,
“Statement”: [
{
“Sid”: “eniperms”,
“Effect”: “Allow”,
“Action”: [
“ec2:CreateNetworkInterface”,
“ec2:DescribeNetworkInterfaces”,
“ec2:DeleteNetworkInterface”,
“ec2:*VpcEndpoint*”
],
“Resource”: “*”
}
]
}
Choose Next.
For Policy name, enter enivpce-policy.
Choose Create policy.
Add the following inline policy (provide your source VPC endpoints) for restricting Lambda access to Amazon Bedrock APIs only via VPC endpoints:
{
“Id”: “lambda-bedrock-sourcevpce-access-only”,
“Version”: “2012-10-17”,
“Statement”: [
{
“Effect”: “Allow”,
“Action”: [
“bedrock:ListFoundationModels”,
“bedrock:InvokeModel”
],
“Resource”: “*”,
“Condition”: {
“ForAnyValue:StringEquals”: {
“aws:sourceVpce”: [
“vpce-<bedrock-runtime-vpce>”
]
}
}
}
]
}
On Lambda function page, on the Configuration tab, choose VPC in the left pane, then choose Edit.
For VPC, choose Bedrock-GenAI-Project-vpc.
For Subnets, choose the private subnets.
For Security groups, choose gen-ai-lambda-stack-SecurityGroup- (the security group for the Amazon Bedrock workload in private subnets).
Choose Save.
Test private access controls
Now you can test the private access controls (Amazon Bedrock APIs over VPC endpoints).
On the Lambda console, choose Functions in the navigation pane.
Choose the function gen-ai-lambda-stack-BedrockTestLambdaFunction-XXXXXXXXXXXX.
On the Code tab, choose Test.
You should see the following response from the Amazon Bedrock API call (Status: Succeeded).
To deny access to Amazon Bedrock APIs over VPC endpoints, navigate to the Amazon VPC console.
Under Virtual private cloud in the navigation pane, choose Endpoints.
Choose your policy and navigate to the Policy tab.
Currently, the VPC endpoint policy is set to Allow.
To deny access, choose Edit Policy.
Change Allow to Deny and choose Save.
It may take up to 2 minutes for the policy for the VPC endpoint to update.
{
“Version”: “2012-10-17”,
“Statement”: [
{
“Action”: [
“bedrock:InvokeModel”
],
“Resource”: [
“arn:aws:bedrock:*::foundation-model/anthropic.claude-instant-v1”
],
“Effect”: “Deny”,
“Principal”: {
“AWS”: “arn:aws:iam::<accountid>:role/GenAIStack-Bedrock”
}
}
]
}
Return to the Lambda function page and on the Code tab, choose Test.
As shown in the following screenshot, the access request to Amazon Bedrock over the VPC endpoint was denied (Status: Failed).
Through this testing process, we demonstrated how traffic from your VPC to the Amazon Bedrock API endpoint is traversing over the PrivateLink connection and not through the internet connection.
Clean up
Follow these steps to avoid incurring future charges:
Clean up the VPC endpoints.
Clean up the VPC.
Delete the CloudFormation stack.
Conclusion
In this post, we demonstrated how to set up and operationalize a private connection between a generative AI workload deployed on your customer VPC and Amazon Bedrock using an interface VPC endpoint powered by PrivateLink. When using the architecture discussed in this post, the traffic between your customer VPC and Amazon Bedrock will not leave the Amazon network, ensuring your data is not exposed to the public internet and thereby helping with your compliance requirements.
As a next step, try the solution out in your account and share your feedback.
About the Authors
Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 3 decades of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure and scalable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he rides his motorcycle and walks with his 3-year-old Sheepadoodle!
Ray Khorsandi is an AI/ML specialist at AWS, supporting strategic customers with AI/ML best practices. With an M.Sc. and Ph.D. in Electrical Engineering and Computer Science, he leads enterprises to build secure, scalable AI/ML and big data solutions to optimize their cloud adoption. His passions include computer vision, NLP, generative AI, and MLOps. Ray enjoys playing soccer and spending quality time with family.
Michael Daniels is an AI/ML Specialist at AWS. His expertise lies in building and leading AI/ML and generative AI solutions for complex and challenging business problems, which is enhanced by his Ph.D. from the Univ. of Texas and his M.Sc. in Computer Science specialization in Machine Learning from the Georgia Institute of Technology. He excels in applying cutting-edge cloud technologies to innovate, inspire, and transform industry-leading organizations, while also effectively communicating with stakeholders at any level or scale. In his spare time, you can catch Michael skiing or snowboarding in the mountains.