- info@i-genie.co.uk
- 0207 148 4785
Today, Amazon SageMaker launches a new version (0.25.0) of Large Model Inference (LMI) Deep Learning Containers (DLCs) and adds support for NVIDIA’s TensorRT-LLM Library. With these upgrades, you can effortlessly access state-of-the-art tooling to optimize large language models (LLMs) on SageMaker and achieve price-performance benefits – Amazon SageMaker LMI TensorRT-LLM DLC reduces latency by 33% on average and improves throughput by 60% on average for Llama2-70B, Falcon-40B and CodeLlama-34B models, compared to previous version.
LLMs have seen an unprecedented growth in popularity across a broad spectrum of applications. However, these models are often too large to fit on a single accelerator or GPU device, making it difficult to achieve low-latency inference and scale. SageMaker offers LMI DLCs to help you maximize the utilization of available resources and improve performance. The latest LMI DLCs offer continuous batching support for inference requests to improve throughput, efficient inference collective operations to improve latency, Paged Attention V2 (which improves the performance of workloads with longer sequence lengths), and the latest TensorRT-LLM library from NVIDIA to maximize performance on GPUs. LMI DLCs offer a low-code interface that simplifies compilation with TensorRT-LLM by just requiring the model ID and optional model parameters; all of the heavy lifting required with building a TensorRT-LLM optimized model and creating a model repo is managed by the LMI DLC. In addition, you can use the latest quantization techniques—GPTQ, AWQ, and SmoothQuant—that are available with LMI DLCs. As a result, with LMI DLCs on SageMaker, you can accelerate time-to-value for your generative AI applications and optimize LLMs for the hardware of your choice to achieve best-in-class price-performance.
In this post, we dive deep into the new features with the latest release of LMI DLCs, discuss performance benchmarks, and outline the steps required to deploy LLMs with LMI DLCs to maximize performance and reduce costs.
New features with SageMaker LMI DLCs
In this section, we discuss three new features with SageMaker LMI DLCs.
SageMaker LMI now supports TensorRT-LLM
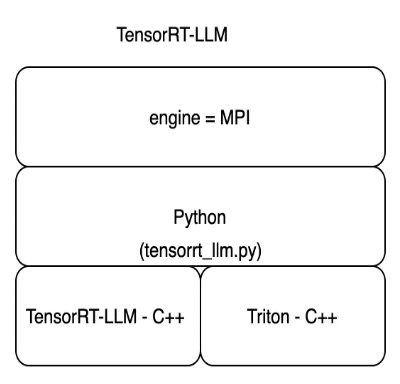
SageMaker now offers NVIDIA’s TensorRT-LLM as part of the latest LMI DLC release (0.25.0), enabling state-of-the-art optimizations like SmoothQuant, FP8, and continuous batching for LLMs when using NVIDIA GPUs. TensorRT-LLM opens the door to ultra-low latency experiences that can greatly improve performance. The TensorRT-LLM SDK supports deployments ranging from single-GPU to multi-GPU configurations, with additional performance gains possible through techniques like tensor parallelism. To use the TensorRT-LLM library, choose the TensorRT-LLM DLC from the available LMI DLCs and set engine=MPI among other settings such as option.model_id. The following diagram illustrates the TensorRT-LLM tech stack.
Efficient inference collective operations
In a typical deployment of LLMs, model parameters are spread across multiple accelerators to accommodate the requirements of a large model that can’t fit on a single accelerator. This enhances inference speed by enabling each accelerator to carry out partial calculations in parallel. Afterwards, a collective operation is introduced to consolidate these partial results at the end of these processes, and redistribute them among the accelerators.
For P4D instance types, SageMaker implements a new collective operation that speeds up communication between GPUs. As a result, you get lower latency and higher throughput with the latest LMI DLCs compared to previous versions. Furthermore, this feature is supported out of the box with LMI DLCs, and you don’t need to configure anything to use this feature because it’s embedded in the SageMaker LMI DLCs and is exclusively available for Amazon SageMaker.
Quantization support
SageMaker LMI DLCs now support the latest quantization techniques, including pre-quantized models with GPTQ, Activation-aware Weight Quantization (AWQ), and just-in-time quantization like SmoothQuant.
GPTQ allows LMI to run popular INT3 and INT4 models from Hugging Face. It offers the smallest possible model weights that can fit on a single GPU/multi-GPU. LMI DLCs also support AWQ inference, which allows faster inference speed. Finally, LMI DLCs now support SmoothQuant, which allows INT8 quantization to reduce the memory footprint and computational cost of models with minimal loss in accuracy. Currently, we allow you to do just-in-time conversion for SmoothQuant models without any additional steps. GPTQ and AWQ need to be quantized with a dataset to be used with LMI DLCs. You can also pick up popular pre-quantized GPTQ and AWQ models to use on LMI DLCs. To use SmoothQuant, set option.quantize=smoothquant with engine=DeepSpeed in serving.properties. A sample notebook using SmoothQuant for hosting GPT-Neox on ml.g5.12xlarge is located on GitHub.
Using SageMaker LMI DLCs
You can deploy your LLMs on SageMaker using the new LMI DLCs 0.25.0 without any changes to your code. SageMaker LMI DLCs use DJL serving to serve your model for inference. To get started, you just need to create a configuration file that specifies settings like model parallelization and inference optimization libraries to use. For instructions and tutorials on using SageMaker LMI DLCs, refer to Model parallelism and large model inference and our list of available SageMaker LMI DLCs.
The DeepSpeed container includes a library called LMI Distributed Inference Library (LMI-Dist). LMI-Dist is an inference library used to run large model inference with the best optimization used in different open-source libraries, across vLLM, Text-Generation-Inference (up to version 0.9.4), FasterTransformer, and DeepSpeed frameworks. This library incorporates open-source popular technologies like FlashAttention, PagedAttention, FusedKernel, and efficient GPU communication kernels to accelerate the model and reduce memory consumption.
TensorRT LLM is an open-source library released by NVIDIA in October 2023. We optimized the TensorRT-LLM library for inference speedup and created a toolkit to simplify the user experience by supporting just-in-time model conversion. This toolkit enables users to provide a Hugging Face model ID and deploy the model end-to-end. It also supports continuous batching with streaming. You can expect approximately 1–2 minutes to compile the Llama-2 7B and 13B models, and around 7 minutes for the 70B model. If you want to avoid this compilation overhead during SageMaker endpoint setup and scaling of instances , we recommend using ahead of time (AOT) compilation with our tutorial to prepare the model. We also accept any TensorRT LLM model built for Triton Server that can be used with LMI DLCs.
Performance benchmarking results
We compared the performance of the latest SageMaker LMI DLCs version (0.25.0) to the previous version (0.23.0). We conducted experiments on the Llama-2 70B, Falcon 40B, and CodeLlama 34B models to demonstrate the performance gain with TensorRT-LLM and efficient inference collective operations (available on SageMaker).
SageMaker LMI containers come with a default handler script to load and host models, providing a low-code option. You also have the option to bring your own script if you need to do any customizations to the model loading steps. You need to pass the required parameters in a serving.properties file. This file contains the required configurations for the Deep Java Library (DJL) model server to download and host the model. The following code is the serving.properties used for our deployment and benchmarking:
engine=MPI
option.use_custom_all_reduce=true
option.model_id={{s3url}}
option.tensor_parallel_degree=8
option.output_formatter=json
option.max_rolling_batch_size=64
option.model_loading_timeout=3600
The engine parameter is used to define the runtime engine for the DJL model server. We can specify the Hugging Face model ID or Amazon Simple Storage Service (Amazon S3) location of the model using the model_id parameter. The task parameter is used to define the natural language processing (NLP) task. The tensor_parallel_degree parameter sets the number of devices over which the tensor parallel modules are distributed. The use_custom_all_reduce parameter is set to true for GPU instances that have NVLink enabled to speed up model inference. You can set this for P4D, P4de, P5 and other GPUs that have NVLink connected. The output_formatter parameter sets the output format. The max_rolling_batch_size parameter sets the limit for the maximum number of concurrent requests. The model_loading_timeout sets the timeout value for downloading and loading the model to serve inference. For more details on the configuration options, refer to Configurations and settings.
Llama-2 70B
The following are the performance comparison results of Llama-2 70B. Latency reduced by 28% and throughput increased by 44% for concurrency of 16, with the new LMI TensorRT LLM DLC.
Falcon 40B
The following figures compare Falcon 40B. Latency reduced by 36% and throughput increased by 59% for concurrency of 16, with the new LMI TensorRT LLM DLC.
CodeLlama 34B
The following figures compare CodeLlama 34B. Latency reduced by 36% and throughput increased by 77% for concurrency of 16, with the new LMI TensorRT LLM DLC.
Recommended configuration and container for hosting LLMs
With the latest release, SageMaker is providing two containers: 0.25.0-deepspeed and 0.25.0-tensorrtllm. The DeepSpeed container contains DeepSpeed, the LMI Distributed Inference Library. The TensorRT-LLM container includes NVIDIA’s TensorRT-LLM Library to accelerate LLM inference.
We recommend the deployment configuration illustrated in the following diagram.
To get started, refer to the sample notebooks:
Deploy Llama-2 70B using the TRT-LLM 0.25.0 LMI container
Deploy Llama-2 70B using the DeepSpeed 0.25.0 LMI container
Conclusion
In this post, we showed how you can use SageMaker LMI DLCs to optimize LLMs for your business use case and achieve price-performance benefits. To learn more about LMI DLC capabilities, refer to Model parallelism and large model inference. We’re excited to see how you use these new capabilities from Amazon SageMaker.
About the authors
Michael Nguyen is a Senior Startup Solutions Architect at AWS, specializing in leveraging AI/ML to drive innovation and develop business solutions on AWS. Michael holds 12 AWS certifications and has a BS/MS in Electrical/Computer Engineering and an MBA from Penn State University, Binghamton University, and the University of Delaware.
Rishabh Ray Chaudhury is a Senior Product Manager with Amazon SageMaker, focusing on Machine Learning inference. He is passionate about innovating and building new experiences for Machine Learning customers on AWS to help scale their workloads. In his spare time, he enjoys traveling and cooking. You can find him on LinkedIn.
Qing Lan is a Software Development Engineer in AWS. He has been working on several challenging products in Amazon, including high performance ML inference solutions and high performance logging system. Qing’s team successfully launched the first Billion-parameter model in Amazon Advertising with very low latency required. Qing has in-depth knowledge on the infrastructure optimization and Deep Learning acceleration.
Jian Sheng is a Software Development Engineer at Amazon Web Services who has worked on several key aspects of machine learning systems. He has been a key contributor to the SageMaker Neo service, focusing on deep learning compilation and framework runtime optimization. Recently, he has directed his efforts and contributed to optimizing the machine learning system for large model inference.
Vivek Gangasani is a AI/ML Startup Solutions Architect for Generative AI startups at AWS. He helps emerging GenAI startups build innovative solutions using AWS services and accelerated compute. Currently, he is focused on developing strategies for fine-tuning and optimizing the inference performance of Large Language Models. In his free time, Vivek enjoys hiking, watching movies and trying different cuisines.
Harish Tummalacherla is Software Engineer with Deep Learning Performance team at SageMaker. He works on performance engineering for serving large language models efficiently on SageMaker. In his spare time, he enjoys running, cycling and ski mountaineering.