- info@i-genie.co.uk
- 0207 148 4785
The development of UltraFastBERT by researchers at ETH Zurich addressed the problem of reducing the number of neurons used during inference while maintaining performance levels similar to other models. It was achieved through fast feedforward networks (FFFs), which resulted in a significant speedup compared to baseline implementations.
The existing methods have been supported by the code, benchmarking setup, and model weights provided by the researchers at ETH Zurich. They have also suggested exploring multiple FFF trees for joint computation and the potential application in large language models like GPT-3. The study proposes further acceleration through hybrid sparse tensors and device-specific optimizations.
UltraFastBERT shows efficient language modeling with selective engagement during inference. It replaces the feedforward networks of traditional models with simplified FFFs, using consistent activation functions and all-node output weights while eliminating biases. Multiple FFF trees collaboratively compute intermediate layer outputs, allowing for diverse architectures. The provided high-level CPU and PyTorch implementations yield substantial speedups, and the research explores potential acceleration through multiple FFF trees and suggests replacing large language model feedforward networks with FFFs. Intel MKL and NVIDIA cuBLAS are proposed for device-specific optimization.
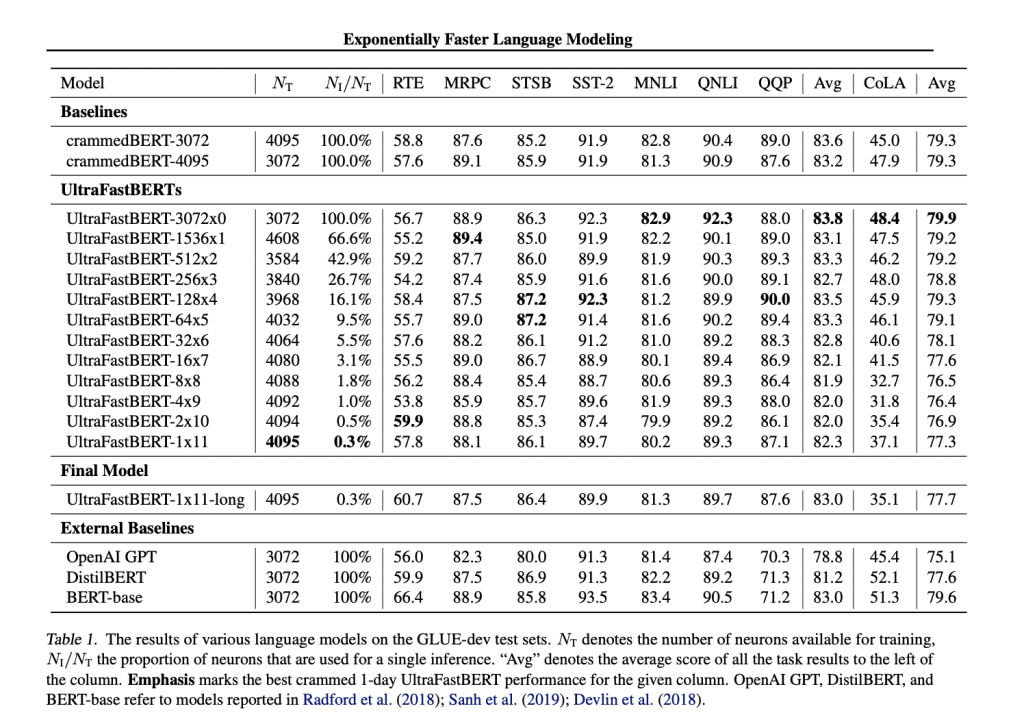
UltraFastBERT achieves comparable performance to BERT-base, using only 0.3% of its neurons during inference. Trained on a single GPU for a day, it retains at least 96.0% of GLUE predictive performance. UltraFastBERT-1×11-long matches BERT-base performance with 0.3% of its neurons. Performance decreases with deeper fast feedforward networks, but excluding CoLA, all UltraFastBERT models preserve at least 98.6% of predictive performance. Comparisons show significant speedups with quick feedforward layers, achieving 48x to 78x more immediate inference on CPU and a 3.15x speedup on GPU, suggesting potential for large model replacements.
In conclusion, UltraFastBERT is a modification of BERT that achieves efficient language modeling while using only a small fraction of its neurons during inference. The model employs FFFs for substantial speedup, with the provided CPU and PyTorch implementations achieving 78x and 40x speedups, respectively. The study suggests potential further acceleration by implementing primitives for conditional neural execution. Despite using only 0.3% of its neurons, UltraFastBERT’s best model matches BERT-base performance, showcasing the potential for efficient language modeling. UltraFastBERT showcases potential advancements in efficient language modeling, paving the way for faster and resource-friendly models in the future.
The proposed avenues for further research include implementing efficient FFF inference using hybrid vector-level sparse tensors and device-specific optimizations. Exploring the full potential of conditional neural execution for accelerated language modeling is suggested. The potential optimization of large language models by replacing feedforward networks with FFFs is discussed. Future work could focus on reproducible implementations in popular frameworks like PyTorch or TensorFlow and extensive benchmarking to evaluate the performance and practical implications of UltraFastBERT and similar efficient language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to join our 33k+ ML SubReddit, 41k+ Facebook Community, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more.
If you like our work, you will love our newsletter..
The post ETH Zurich Researchers Introduce UltraFastBERT: A BERT Variant that Uses 0.3% of its Neurons during Inference while Performing on Par with Similar BERT Models appeared first on MarkTechPost.