- info@i-genie.co.uk
- 0207 148 4785
The field of text-to-image generation has been extensively explored over the years, and significant progress has been made recently. Researchers have achieved remarkable advancements by training large-scale models on extensive datasets, enabling zero-shot text-to-image generation with arbitrary text inputs. Groundbreaking works like DALL-E and CogView have paved the way for numerous methods proposed by researchers, resulting in impressive capabilities to generate high-resolution images aligned with textual descriptions, exhibiting exceptional fidelity. These large-scale models have not only revolutionized text-to-image generation but have also had a profound impact on various other applications, including image manipulation and video generation.
While the aforementioned large-scale text-to-image generation models excel at producing text-aligned and creative outputs, they often encounter challenges when it comes to generating novel and unique concepts as specified by users. As a result, researchers have explored various methods to customize pre-trained text-to-image generation models.
For instance, some approaches involve fine-tuning the pre-trained generative models using a limited number of samples. To prevent overfitting, different regularization techniques are employed. Other methods aim to encode the novel concept provided by the user into a word embedding. This embedding is obtained either through an optimization process or from an encoder network. These approaches enable the customized generation of novel concepts while meeting additional requirements specified in the user’s input text.
Despite the significant progress in text-to-image generation, recent research has raised concerns about the potential limitations of customization when employing regularization methods. There is suspicion that these regularization techniques may inadvertently restrict the capability of customized generation, resulting in the loss of fine-grained details.
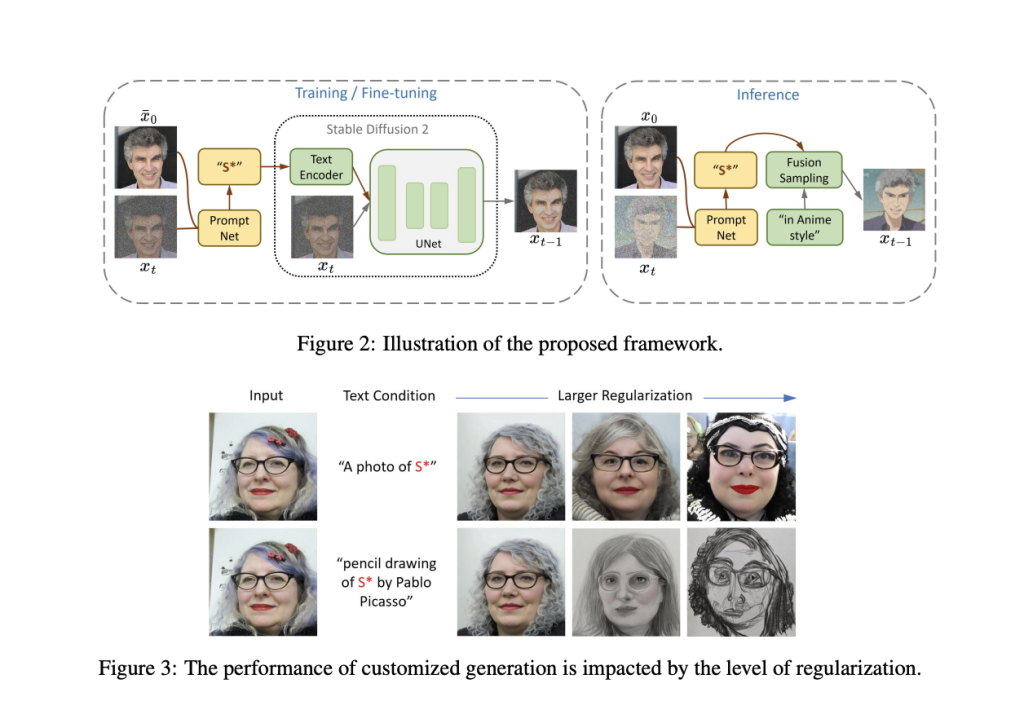
To overcome this challenge, a novel framework called ProFusion has been proposed. Its architecture is presented below.
ProFusion consists of a pre-trained encoder called PromptNet, which infers the conditioning word embedding from an input image and random noise, and a novel sampling method called Fusion Sampling. In contrast to previous methods, ProFusion eliminates the requirement for regularization during the training process. Instead, the problem is effectively addressed during inference using the Fusion Sampling method.
Indeed, the authors argue that although regularization enables faithful content creation conditioned by text, it also leads to the loss of detailed information, resulting in inferior performance.
Fusion Sampling consists of two stages at each timestep. The first step involves a fusion stage which encodes information from both the input image embedding and the conditioning text into a noisy partial outcome. Afterward, a refinement stage follows, which updates the prediction based on chosen hyper-parameters. Updating the prediction helps Fusion Sampling preserve fine-grained information from the input image while conditioning the output on the input prompt.
This approach not only saves training time but also obviates the need for tuning hyperparameters related to regularization methods.
The results reported below talk for themselves.
We can see a comparison between ProFusion and state-of-the-art approaches. The proposed approach outperforms all other presented techniques, preserving fine-grained details mainly related to facial traits.
This was the summary of ProFusion, a novel regularization-free framework for text-to-image generation with state-of-the-art quality. If you are interested, you can learn more about this technique in the links below.
Check Out The Paper and Github Link. Don’t forget to join our 25k+ ML SubReddit, Discord Channel, and Email Newsletter, where we share the latest AI research news, cool AI projects, and more. If you have any questions regarding the above article or if we missed anything, feel free to email us at Asif@marktechpost.com
Check Out 100’s AI Tools in AI Tools Club
The post Meet ProFusion: An AI Regularization-Free Framework For Detail Preservation In Text-to-Image Synthesis appeared first on MarkTechPost.