Generative AI applications are gaining widespread adoption across various industries, including regulated industries such as financial services and healthcare. As these advanced systems accelerate in playing a critical role in decision-making processes and customer interactions, customers should work towards ensuring the reliability, fairness, and compliance of generative AI applications with industry regulations. To address this need, AWS generative AI best practices framework was launched within AWS Audit Manager, enabling auditing and monitoring of generative AI applications. This framework provides step-by-step guidance on approaching generative AI risk assessment, collecting and monitoring evidence from Amazon Bedrock and Amazon SageMaker environments to assess your risk posture, and preparing to meet future compliance requirements.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI. Amazon Bedrock Agents can be used to configure specialized agents that run actions seamlessly based on user input and your organization’s data. These managed agents play conductor, orchestrating interactions between FMs, API integrations, user conversations, and knowledge bases loaded with your data.
Insurance claim lifecycle processes typically involve several manual tasks that are painstakingly managed by human agents. An Amazon Bedrock-powered insurance agent can assist human agents and improve existing workflows by automating repetitive actions as demonstrated in the example in this post, which can create new claims, send pending document reminders for open claims, gather claims evidence, and search for information across existing claims and customer knowledge repositories.
Generative AI applications should be developed with adequate controls for steering the behavior of FMs. Responsible AI considerations such as privacy, security, safety, controllability, fairness, explainability, transparency and governance help ensure that AI systems are trustworthy. In this post, we demonstrate how to use the AWS generative AI best practices framework on AWS Audit Manager to evaluate this insurance claim agent from a responsible AI lens.
Use case
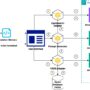
In this example of an insurance assistance chatbot, the customer’s generative AI application is designed with Amazon Bedrock Agents to automate tasks related to the processing of insurance claims and Amazon Bedrock Knowledge Bases to provide relevant documents. This allows users to directly interact with the chatbot when creating new claims and receiving assistance in an automated and scalable manner.
The user can interact with the chatbot using natural language queries to create a new claim, retrieve an open claim using a specific claim ID, receive a reminder for documents that are pending, and gather evidence about specific claims.
The agent then interprets the user’s request and determines if actions need to be invoked or information needs to be retrieved from a knowledge base. If the user request invokes an action, action groups configured for the agent will invoke different API calls, which produce results that are summarized as the response to the user. Figure 1 depicts the system’s functionalities and AWS services. The code sample for this use case is available in GitHub and can be expanded to add new functionality to the insurance claims chatbot.
How to create your own assessment of the AWS generative AI best practices framework
To create an assessment using the generative AI best practices framework on Audit Manager, go to the AWS Management Console and navigate to AWS Audit Manager.
Choose Create assessment.
Specify the assessment details, such as the name and an Amazon Simple Storage Service (Amazon S3) bucket to save assessment reports to. Select AWS Generative AI Best Practices Framework for assessment.
Select the AWS accounts in scope for assessment. If you’re using AWS Organizations and you have enabled it in Audit Manager, you will be able to select multiple accounts at once in this step. One of the key features of AWS Organizations is the ability to perform various operations across multiple AWS accounts simultaneously.
Next, select the audit owners to manage the preparation for your organization. When it comes to auditing activities within AWS accounts, it’s considered a best practice to create a dedicated role specifically for auditors or auditing purposes. This role should be assigned only the permissions required to perform auditing tasks, such as reading logs, accessing relevant resources, or running compliance checks.
Finally, review the details and choose Create assessment.
Principles of AWS generative AI best practices framework
Generative AI implementations can be evaluated based on eight principles in the AWS generative AI best practices framework. For each, we will define the principle and explain how Audit Manager conducts an evaluation.
Accuracy
A core principle of trustworthy AI systems is accuracy of the application and/or model. Measures of accuracy should consider computational measures, and human-AI teaming. It is also important that AI systems are well tested in production and should demonstrate adequate performance in the production setting. Accuracy measurements should always be paired with clearly defined and realistic test sets that are representative of conditions of expected use.
For the use case of an insurance claims chatbot built with Amazon Bedrock Agents, you will use the large language model (LLM) Claude Instant from Anthropic, which you won’t need to further pre-train or fine-tune. Hence, it is relevant for this use case to demonstrate the performance of the chatbot through performance metrics for the tasks through the following:
A prompt benchmark
Source verification of documents ingested in knowledge bases or databases that the agent has access to
Integrity checks of the connected datasets as well as the agent
Error analysis to detect the edge cases where the application is erroneous
Schema compatibility of the APIs
Human-in-the-loop validation.
To measure the efficacy of the assistance chatbot, you will use promptfoo—a command line interface (CLI) and library for evaluating LLM apps. This involves three steps:
Create a test dataset containing prompts with which you test the different features.
Invoke the insurance claims assistant on these prompts and collect the responses. Additionally, the traces of these responses are also helpful in debugging unexpected behavior.
Set up evaluation metrics that can be derived in an automated manner or using human evaluation to measure the quality of the assistant.
In the example of an insurance assistance chatbot, designed with Amazon Bedrock Agents and Amazon Bedrock Knowledge Bases, there are four tasks:
getAllOpenClaims: Gets the list of all open insurance claims. Returns all claim IDs that are open.
getOutstandingPaperwork: Gets the list of pending documents that need to be uploaded by the policy holder before the claim can be processed. The API takes in only one claim ID and returns the list of documents that are pending to be uploaded. This API should be called for each claim ID.
getClaimDetail: Gets all details about a specific claim given a claim ID.
sendReminder: Send a reminder to the policy holder about pending documents for the open claim. The API takes in only one claim ID and its pending documents at a time, sends the reminder, and returns the tracking details for the reminder. This API should be called for each claim ID you want to send reminders for.
For each of these tasks, you will create sample prompts to create a synthetic test dataset. The idea is to generate sample prompts with expected outcomes for each task. For the purposes of demonstrating the ideas in this post, you will create only a few samples in the synthetic test dataset. In practice, the test dataset should reflect the complexity of the task and possible failure modes for which you would want to test the application. Here are the sample prompts that you will use for each task:
getAllOpenClaims
What are the open claims?
List open claims.
getOutstandingPaperwork
What are the missing documents from {{claim}}?
What is missing from {{claim}}?
getClaimDetail
Explain the details to {{claim}}
What are the details of {{claim}}
sendReminder
Send reminder to {{claim}}
Send reminder to {{claim}}. Include the missing documents and their requirements.
Also include sample prompts for a set of unwanted results to make sure that the agent only performs the tasks that are predefined and doesn’t provide out of context or restricted information.
List all claims, including closed claims
What is 2+2?
Set up
You can start with the example of an insurance claims agent by cloning the use case of Amazon Bedrock-powered insurance agent. After you create the agent, set up promptfoo. Now, you will need to create a custom script that can be used for testing. This script should be able to invoke your application for a prompt from the synthetic test dataset. We created a Python script, invoke_bedrock_agent.py, with which we invoke the agent for a given prompt.
python invoke_bedrock_agent.py “What are the open claims?”
Step 1: Save your prompts
Create a text file of the sample prompts to be tested. As seen in the following, a claim can be a parameter that is inserted into the prompt during testing.
%%writefile prompts_getClaimDetail.txt
Explain the details to {{claim}}.
—
What are the details of {{claim}}.
Step 2: Create your prompt configuration with tests
For prompt testing, we defined test prompts per task. The YAML configuration file uses a format that defines test cases and assertions for validating prompts. Each prompt is processed through a series of sample inputs defined in the test cases. Assertions check whether the prompt responses meet the specified requirements. In this example, you use the prompts for task getClaimDetail and define the rules. There are different types of tests that can be used in promptfoo. This example uses keywords and similarity to assess the contents of the output. Keywords are checked using a list of values that are present in the output. Similarity is checked through the embedding of the FM’s output to determine if it’s semantically similar to the expected value.
%%writefile promptfooconfig.yaml
prompts: [prompts_getClaimDetail.txt] # text file that has the prompts
providers: [‘bedrock_agent_as_provider.js’] # custom provider setting
defaultTest:
options:
provider:
embedding:
id: huggingface:sentence-similarity:sentence-transformers/all-MiniLM-L6-v2
tests:
– description: ‘Test via keywords’
vars:
claim: claim-008 # a claim that is open
assert:
– type: contains-any
value:
– ‘claim’
– ‘open’
– description: ‘Test via similarity score’
vars:
claim: claim-008 # a claim that is open
assert:
– type: similar
value: ‘Providing the details for claim with id xxx: it is created on xx-xx-xxxx, last activity date on xx-xx-xxxx, status is x, the policy type is x.’
threshold: 0.6
Step 3: Run the tests
Run the following commands to test the prompts against the set rules.
npx promptfoo@latest eval -c promptfooconfig.yaml npx promptfoo@latest share
The promptfoo library generates a user interface where you can view the exact set of rules and the outcomes. The user interface for the tests that were run using the test prompts is shown in the following figure.
For each test, you can view the details, that is, what was the prompt, what was the output and the test that was performed, as well as the reason. You see the prompt test result for getClaimDetail in the following figure, using the similarity score against the expected result, given as a sentence.
Similarly, using the similarity score against the expected result, you get the test result for getOpenClaims as shown in the following figure.
Step 4: Save the output
For the final step, you want to attach evidence for both the FM as well as the application as a whole to the control ACCUAI 3.1: Model Evaluation Metrics. To do so, save the output of your prompt testing into an S3 bucket. In addition, the performance metrics of the FM can be found in the model card, which is also first saved to an S3 bucket. Within Audit Manager, navigate to the corresponding control, ACCUAI 3.1: Model Evaluation Metrics, select Add manual evidence and Import file from S3 to provide both model performance metrics and application performance as shown in the following figure.
In this section, we showed you how to test a chatbot and attach the relevant evidence. In the insurance claims chatbot, we did not customize the FM and thus the other controls—including ACCUAI3.2: Regular Retraining for Accuracy, ACCUAI3.11: Null Values, ACCUAI3.12: Noise and Outliers, and ACCUAI3.15: Update Frequency—are not applicable. Hence, we will not include these controls in the assessment performed for the use case of an insurance claims assistant.
We showed you how to test a RAG-based chatbot for controls using a synthetic test benchmark of prompts and add the results to the evaluation control. Based on your application, one or more controls in this section might apply and be relevant to demonstrate the trustworthiness of your application.
Fair
Fairness in AI includes concerns for equality and equity by addressing issues such as harmful bias and discrimination.
Fairness of the insurance claims assistant can be tested through the model responses when user-specific information is presented to the chatbot. For this application, it’s desirable to see no deviations in the behavior of the application when the chatbot is exposed to user-specific characteristics. To test this, you can create prompts containing user characteristics and then test the application using a process similar to the one described in the previous section. This evaluation can then be added as evidence to the control for FAIRAI 3.1: Bias Assessment.
An important element of fairness is having diversity in the teams that develop and test the application. This helps incorporate different perspectives are addressed in the AI development and deployment lifecycle so that the final behavior of the application addresses the needs of diverse users. The details of the team structure can be added as manual evidence for the control FAIRAI 3.5: Diverse Teams. Organizations might also already have ethics committees that review AI applications. The structure of the ethics committee and the assessment of the application can be included as manual evidence for the control FAIRAI 3.6: Ethics Committees.
Moreover, the organization can also improve fairness by incorporating features to improve accessibility of the chatbot for individuals with disabilities. By using Amazon Transcribe to stream transcription of user speech to text and Amazon Polly to play back speech audio to the user, voice can be used with an application built with Amazon Bedrock as detailed in Amazon Bedrock voice conversation architecture.
Privacy
NIST defines privacy as the norms and practices that help to safeguard human autonomy, identity, and dignity. Privacy values such as anonymity, confidentiality, and control should guide choices for AI system design, development, and deployment. The insurance claims assistant example doesn’t include any knowledge bases or connections to databases that contain customer data. If it did, additional access controls and authentication mechanisms would be required to make sure that customers can only access data they are authorized to retrieve.
Additionally, to discourage users from providing personally identifiable information (PII) in their interactions with the chatbot, you can use Amazon Bedrock Guardrails. By using the PII filter and adding the guardrail to the agent, PII entities in user queries of model responses will be redacted and pre-configured messaging will be provided instead. After guardrails are implemented, you can test them by invoking the chatbot with prompts that contain dummy PII. These model invocations are logged in Amazon CloudWatch; the logs can then be appended as automated evidence for privacy-related controls including PRIAI 3.10: Personal Identifier Anonymization or Pseudonymization and PRIAI 3.9: PII Anonymization.
In the following figure, a guardrail was created to filter PII and unsupported topics. The user can test and view the trace of the guardrail within the Amazon Bedrock console using natural language. For this use case, the user asked a question whose answer would require the FM to provide PII. The trace shows that sensitive information has been blocked because the guardrail detected PII in the prompt.
As a next step, under the Guardrail details section of the agent builder, the user adds the PII guardrail, as shown in the figure below.
Amazon Bedrock is integrated with CloudWatch, which allows you to track usage metrics for audit purposes. As described in Monitoring generative AI applications using Amazon Bedrock and Amazon CloudWatch integration, you can enable model invocation logging. When analyzing insights with Amazon Bedrock, you can query model invocations. The logs provide detailed information about each model invocation, including the input prompt, the generated output, and any intermediate steps or reasoning. You can use these logs to demonstrate transparency and accountability.
Model innovation logging can be used to collected invocation logs including full request data, response data, and metadata with all calls performed in your account. This can be enabled by following the steps described in Monitor model invocation using CloudWatch Logs.
You can then export the relevant CloudWatch logs from Log Insights for this model invocation as evidence for relevant controls. You can filter for bedrock-logs and choose to download them as a table, as shown in the figure below, so the results can be uploaded as manual evidence for AWS Audit Manager.
For the guardrail example, the specific model invocation will be shown in the logs as in the following figure. Here, the prompt and the user who ran it are captured. Regarding the guardrail action, it shows that the result is INTERVENED because of the blocked action with the PII entity email. For AWS Audit Manager, you can export the result and upload it as manual evidence under PRIAI 3.9: PII Anonymization.
Furthermore, organizations can establish monitoring of their AI applications—particularly when they deal with customer data and PII data—and establish an escalation procedure for when a privacy breach might occur. Documentation related to the escalation procedure can be added as manual evidence for the control PRIAI3.6: Escalation Procedures – Privacy Breach.
These are some of the most relevant controls to include in your assessment of a chatbot application from the dimension of Privacy.
Resilience
In this section, we show you how to improve the resilience of an application to add evidence of the same to controls defined in the Resilience section of the AWS generative AI best practices framework.
AI systems, as well as the infrastructure in which they are deployed, are said to be resilient if they can withstand unexpected adverse events or unexpected changes in their environment or use. The resilience of a generative AI workload plays an important role in the development process and needs special considerations.
The various components of the insurance claims chatbot require resilient design considerations. Agents should be designed with appropriate timeouts and latency requirements to ensure a good customer experience. Data pipelines that ingest data to the knowledge base should account for throttling and use backoff techniques. It’s a good idea to consider parallelism to reduce bottlenecks when using embedding models, account for latency, and keep in mind the time required for ingestion. Considerations and best practices should be implemented for vector databases, the application tier, and monitoring the use of resources through an observability layer. Having a business continuity plan with a disaster recovery strategy is a must for any workload. Guidance for these considerations and best practices can be found in Designing generative AI workloads for resilience. Details of these architectural elements should be added as manual evidence in the assessment.
Responsible
Key principles of responsible design are explainability and interpretability. Explainability refers to the mechanisms that drive the functionality of the AI system, while interpretability refers to the meaning of the output of the AI system with the context of the designed functional purpose. Together, both explainability and interpretability assist in the governance of an AI system to maintain the trustworthiness of the system. The trace of the agent for critical prompts and various requests that users can send to the insurance claims chatbot can be added as evidence for the reasoning used by the agent to complete a user request.
The logs gathered from Amazon Bedrock offer comprehensive insights into the model’s handling of user prompts and the generation of corresponding answers. The figure below shows a typical model invocation log. By analyzing these logs, you can gain visibility into the model’s decision-making process. This logging functionality can serve as a manual audit trail, fulfilling RESPAI3.4: Auditable Model Decisions.
Another important aspect of maintaining responsible design, development, and deployment of generative AI applications is risk management. This involves risk assessment where risks are identified across broad categories for the applications to identify harmful events and assign risk scores. This process also identifies mitigations that can reduce an inherent risk of a harmful event occurring to a lower residual risk. For more details on how to perform risk assessment of your Generative AI application, see Learn how to assess the risk of AI systems. Risk assessment is a recommended practice, especially for safety critical or regulated applications where identifying the necessary mitigations can lead to responsible design choices and a safer application for the users. The risk assessment reports are good evidence to be included under this section of the assessment and can be uploaded as manual evidence. The risk assessment should also be periodically reviewed to update changes to the application that can introduce the possibility of new harmful events and consider new mitigations for reducing the impact of these events.
Safe
AI systems should “not under defined conditions, lead to a state in which human life, health, property, or the environment is endangered.” (Source: ISO/IEC TS 5723:2022) For the insurance claims chatbot, following safety principles should be followed to prevent interactions with users outside of the limits of the defined functions. Amazon Bedrock Guardrails can be used to define topics that are not supported by the chatbot. The intended use of the chatbot should also be transparent to users to guide them in the best use of the AI application. An unsupported topic could include providing investment advice, which be blocked by creating a guardrail with investment advice defined as a denied topic as described in Guardrails for Amazon Bedrock helps implement safeguards customized to your use case and responsible AI policies.
After this functionality is enabled as a guardrail, the model will prohibit unsupported actions. The instance illustrated in the following figure depicts a scenario where requesting investment advice is a restricted behavior, leading the model to decline providing a response.
After the model is invoked, the user can navigate to CloudWatch to view the relevant logs. In cases where the model denies or intervenes in certain actions, such as providing investment advice, the logs will reflect the specific reasons for the intervention, as shown in the following figure. By examining the logs, you can gain insights into the model’s behavior, understand why certain actions were denied or restricted, and verify that the model is operating within the intended guidelines and boundaries. For the controls defined under the safety section of the assessment, you might want to design more experiments by considering various risks that arise from your application. The logs and documentation collected from the experiments can be attached as evidence to demonstrate the safety of the application.
Secure
NIST defines AI systems to be secure when they maintain confidentiality, integrity, and availability through protection mechanisms that prevent unauthorized access and use. Applications developed using generative AI should build defenses for adversarial threats including but not limited to prompt injection, data poisoning if a model is being fine-tuned or pre-trained, and model and data extraction exploits through AI endpoints.
Your information security teams should conduct standard security assessments that have been adapted to address the new challenges with generative AI models and applications—such as adversarial threats—and consider mitigations such as red-teaming. To learn more on various security considerations for generative AI applications, see Securing generative AI: An introduction to the Generative AI Security Scoping Matrix. The resulting documentation of the security assessments can be attached as evidence to this section of the assessment.
Sustainable
Sustainability refers to the “state of the global system, including environmental, social, and economic aspects, in which the needs of the present are met without compromising the ability of future generations to meet their own needs.”
Some actions that contribute to a more sustainable design of generative AI applications include considering and testing smaller models to achieve the same functionality, optimizing hardware and data storage, and using efficient training algorithms. To learn more about how you can do this, see Optimize generative AI workloads for environmental sustainability. Considerations implemented for achieving more sustainable applications can be added as evidence for the controls related to this part of the assessment.
Conclusion
In this post, we used the example of an insurance claims assistant powered by Amazon Bedrock Agents and looked at various principles that you need to consider when getting this application audit ready using the AWS generative AI best practices framework on Audit Manager. We defined each principle of safeguarding applications for trustworthy AI and provided some best practices for achieving the key objectives of the principles. Finally, we showed you how these development and design choices can be added to the assessment as evidence to help you prepare for an audit.
The AWS generative AI best practices framework provides a purpose-built tool that you can use for monitoring and governance of your generative AI projects on Amazon Bedrock and Amazon SageMaker. To learn more, see:
AWS generative AI best practices framework v2
AWS Audit Manager launches AWS Best Practices Framework for Generative AI
AWS Audit Manager extends generative AI best practices framework to Amazon SageMaker
About the Authors
Bharathi Srinivasan is a Generative AI Data Scientist at the AWS Worldwide Specialist Organisation. She works on developing solutions for Responsible AI, focusing on algorithmic fairness, veracity of large language models, and explainability. Bharathi guides internal teams and AWS customers on their responsible AI journey. She has presented her work at various learning conferences.
Irem Gokcek is a Data Architect in the AWS Professional Services team, with expertise spanning both Analytics and AI/ML. She has worked with customers from various industries such as retail, automotive, manufacturing and finance to build scalable data architectures and generate valuable insights from the data. In her free time, she is passionate about swimming and painting.
Fiona McCann is a Solutions Architect at Amazon Web Services in the public sector. She specializes in AI/ML with a focus on Responsible AI. Fiona has a passion for helping nonprofit customers achieve their missions with cloud solutions. Outside of building on AWS, she loves baking, traveling, and running half marathons in cities she visits.