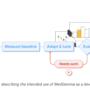
In this tutorial, we demonstrate how an autonomous, agentic AI system can simulate the end-to-end prior authorization workflow within healthcare Revenue Cycle Management (RCM). We show how an agent continuously monitors incoming surgery orders, gathers the required clinical documentation, submits prior authorization requests to payer systems, tracks their status, and intelligently responds to denials through automated analysis and appeals. We design the system to act conservatively and responsibly, escalating to a human reviewer when uncertainty crosses a defined threshold. While the implementation uses mocked EHR and payer portals for clarity and safety, we intentionally mirror real-world healthcare workflows to make the logic transferable to production environments. Also, we emphasize that it is strictly a technical simulation and not a substitute for clinical judgment, payer policy interpretation, or regulatory compliance. Check out the FULL CODES here.
Copy CodeCopiedUse a different Browser!pip -q install “pydantic>=2.0.0” “httpx>=0.27.0”
import os, time, json, random, hashlib
from typing import List, Dict, Optional, Any
from enum import Enum
from datetime import datetime, timedelta
from pydantic import BaseModel, Field
We set up the execution environment and installed the minimal dependencies required to run the tutorial. We configure optional OpenAI usage in a safe, fail-open manner so the system continues to work even without external models. We ensure the foundation is lightweight, reproducible, and suitable for healthcare simulations. Check out the FULL CODES here.
Copy CodeCopiedUse a different BrowserUSE_OPENAI = False
OPENAI_AVAILABLE = False
try:
from getpass import getpass
if not os.environ.get(“OPENAI_API_KEY”):
pass
if os.environ.get(“OPENAI_API_KEY”):
USE_OPENAI = True
except Exception:
USE_OPENAI = False
if USE_OPENAI:
try:
!pip -q install openai
from openai import OpenAI
client = OpenAI()
OPENAI_AVAILABLE = True
except Exception:
OPENAI_AVAILABLE = False
USE_OPENAI = False
We define strongly typed domain models for patients, surgical orders, clinical documents, and authorization decisions. We use explicit enums and schemas to mirror real healthcare RCM structures while avoiding ambiguity. We enforce clarity and validation to reduce downstream errors in automated decision-making. Check out the FULL CODES here.
Copy CodeCopiedUse a different Browserclass DocType(str, Enum):
H_AND_P = “history_and_physical”
LABS = “labs”
IMAGING = “imaging”
MED_LIST = “medication_list”
CONSENT = “consent”
PRIOR_TX = “prior_treatments”
CLINICAL_NOTE = “clinical_note”
class SurgeryType(str, Enum):
KNEE_ARTHROPLASTY = “knee_arthroplasty”
SPINE_FUSION = “spine_fusion”
CATARACT = “cataract”
BARIATRIC = “bariatric_surgery”
class InsurancePlan(str, Enum):
PAYER_ALPHA = “PayerAlpha”
PAYER_BETA = “PayerBeta”
PAYER_GAMMA = “PayerGamma”
class Patient(BaseModel):
patient_id: str
name: str
dob: str
member_id: str
plan: InsurancePlan
class SurgeryOrder(BaseModel):
order_id: str
patient: Patient
surgery_type: SurgeryType
scheduled_date: str
ordering_provider_npi: str
diagnosis_codes: List[str] = Field(default_factory=list)
created_at: str
class ClinicalDocument(BaseModel):
doc_id: str
doc_type: DocType
created_at: str
content: str
source: str
class PriorAuthRequest(BaseModel):
request_id: str
order: SurgeryOrder
submitted_at: Optional[str] = None
docs_attached: List[ClinicalDocument] = Field(default_factory=list)
payload: Dict[str, Any] = Field(default_factory=dict)
class AuthStatus(str, Enum):
DRAFT = “draft”
SUBMITTED = “submitted”
IN_REVIEW = “in_review”
APPROVED = “approved”
DENIED = “denied”
NEEDS_INFO = “needs_info”
APPEALED = “appealed”
class DenialReason(str, Enum):
MISSING_DOCS = “missing_docs”
MEDICAL_NECESSITY = “medical_necessity”
MEMBER_INELIGIBLE = “member_ineligible”
DUPLICATE = “duplicate”
CODING_ISSUE = “coding_issue”
OTHER = “other”
class PayerResponse(BaseModel):
status: AuthStatus
payer_ref: str
message: str
denial_reason: Optional[DenialReason] = None
missing_docs: List[DocType] = Field(default_factory=list)
confidence: float = 0.9
class AgentDecision(BaseModel):
action: str
missing_docs: List[DocType] = Field(default_factory=list)
rationale: str = “”
uncertainty: float = 0.0
next_wait_seconds: int = 0
appeal_text: Optional[str] = None
We simulate an EHR system that emits surgery orders and stores clinical documentation. We intentionally model incomplete charts to reflect real-world documentation gaps that often drive prior authorization denials. We show how an agent can retrieve and augment patient records in a controlled manner. Check out the FULL CODES here.
Copy CodeCopiedUse a different Browserdef _now_iso() -> str:
return datetime.utcnow().replace(microsecond=0).isoformat() + “Z”
def _stable_id(prefix: str, seed: str) -> str:
h = hashlib.sha256(seed.encode(“utf-8″)).hexdigest()[:10]
return f”{prefix}_{h}”
class MockEHR:
def __init__(self):
self.orders_queue: List[SurgeryOrder] = []
self.patient_docs: Dict[str, List[ClinicalDocument]] = {}
def seed_data(self, n_orders: int = 5):
random.seed(7)
def make_patient(i: int) -> Patient:
pid = f”PT{i:04d}”
plan = random.choice(list(InsurancePlan))
return Patient(
patient_id=pid,
name=f”Patient {i}”,
dob=”1980-01-01″,
member_id=f”M{i:08d}”,
plan=plan,
)
def docs_for_order(patient: Patient, surgery: SurgeryType) -> List[ClinicalDocument]:
base = [
ClinicalDocument(
doc_id=_stable_id(“DOC”, patient.patient_id + “H&P”),
doc_type=DocType.H_AND_P,
created_at=_now_iso(),
content=”H&P: Relevant history, exam findings, and surgical indication.”,
source=”EHR”,
),
ClinicalDocument(
doc_id=_stable_id(“DOC”, patient.patient_id + “NOTE”),
doc_type=DocType.CLINICAL_NOTE,
created_at=_now_iso(),
content=”Clinical note: Symptoms, conservative management attempted, clinician assessment.”,
source=”EHR”,
),
ClinicalDocument(
doc_id=_stable_id(“DOC”, patient.patient_id + “MEDS”),
doc_type=DocType.MED_LIST,
created_at=_now_iso(),
content=”Medication list: Current meds, allergies, contraindications.”,
source=”EHR”,
),
]
maybe = []
if surgery in [SurgeryType.KNEE_ARTHROPLASTY, SurgeryType.SPINE_FUSION, SurgeryType.BARIATRIC]:
maybe.append(
ClinicalDocument(
doc_id=_stable_id(“DOC”, patient.patient_id + “LABS”),
doc_type=DocType.LABS,
created_at=_now_iso(),
content=”Labs: CBC/CMP within last 30 days.”,
source=”LabSystem”,
)
)
if surgery in [SurgeryType.SPINE_FUSION, SurgeryType.KNEE_ARTHROPLASTY]:
maybe.append(
ClinicalDocument(
doc_id=_stable_id(“DOC”, patient.patient_id + “IMG”),
doc_type=DocType.IMAGING,
created_at=_now_iso(),
content=”Imaging: MRI/X-ray report supporting diagnosis and severity.”,
source=”Radiology”,
)
)
final = base + [d for d in maybe if random.random() > 0.35]
if random.random() > 0.6:
final.append(
ClinicalDocument(
doc_id=_stable_id(“DOC”, patient.patient_id + “PRIOR_TX”),
doc_type=DocType.PRIOR_TX,
created_at=_now_iso(),
content=”Prior treatments: PT, meds, injections tried over 6+ weeks.”,
source=”EHR”,
)
)
if random.random() > 0.5:
final.append(
ClinicalDocument(
doc_id=_stable_id(“DOC”, patient.patient_id + “CONSENT”),
doc_type=DocType.CONSENT,
created_at=_now_iso(),
content=”Consent: Signed procedure consent and risk disclosure.”,
source=”EHR”,
)
)
return final
for i in range(1, n_orders + 1):
patient = make_patient(i)
surgery = random.choice(list(SurgeryType))
order = SurgeryOrder(
order_id=_stable_id(“ORD”, patient.patient_id + surgery.value),
patient=patient,
surgery_type=surgery,
scheduled_date=(datetime.utcnow().date() + timedelta(days=random.randint(3, 21))).isoformat(),
ordering_provider_npi=str(random.randint(1000000000, 1999999999)),
diagnosis_codes=[“M17.11”, “M54.5”] if surgery != SurgeryType.CATARACT else [“H25.9”],
created_at=_now_iso(),
)
self.orders_queue.append(order)
self.patient_docs[patient.patient_id] = docs_for_order(patient, surgery)
def poll_new_surgery_orders(self, max_n: int = 1) -> List[SurgeryOrder]:
pulled = self.orders_queue[:max_n]
self.orders_queue = self.orders_queue[max_n:]
return pulled
def get_patient_documents(self, patient_id: str) -> List[ClinicalDocument]:
return list(self.patient_docs.get(patient_id, []))
def fetch_additional_docs(self, patient_id: str, needed: List[DocType]) -> List[ClinicalDocument]:
generated = []
for dt in needed:
generated.append(
ClinicalDocument(
doc_id=_stable_id(“DOC”, patient_id + dt.value + str(time.time())),
doc_type=dt,
created_at=_now_iso(),
content=f”Auto-collected document for {dt.value}: extracted and formatted per payer policy.”,
source=”AutoCollector”,
)
)
self.patient_docs.setdefault(patient_id, []).extend(generated)
return generated
class MockPayerPortal:
def __init__(self):
self.db: Dict[str, Dict[str, Any]] = {}
random.seed(11)
def required_docs_policy(self, plan: InsurancePlan, surgery: SurgeryType) -> List[DocType]:
base = [DocType.H_AND_P, DocType.CLINICAL_NOTE, DocType.MED_LIST]
if surgery in [SurgeryType.SPINE_FUSION, SurgeryType.KNEE_ARTHROPLASTY]:
base += [DocType.IMAGING, DocType.LABS, DocType.PRIOR_TX]
if surgery == SurgeryType.BARIATRIC:
base += [DocType.LABS, DocType.PRIOR_TX]
if plan in [InsurancePlan.PAYER_BETA, InsurancePlan.PAYER_GAMMA]:
base += [DocType.CONSENT]
return sorted(list(set(base)), key=lambda x: x.value)
def submit(self, pa: PriorAuthRequest) -> PayerResponse:
payer_ref = _stable_id(“PAYREF”, pa.request_id + _now_iso())
docs_present = {d.doc_type for d in pa.docs_attached}
required = self.required_docs_policy(pa.order.patient.plan, pa.order.surgery_type)
missing = [d for d in required if d not in docs_present]
self.db[payer_ref] = {
“status”: AuthStatus.SUBMITTED,
“order_id”: pa.order.order_id,
“plan”: pa.order.patient.plan,
“surgery”: pa.order.surgery_type,
“missing”: missing,
“polls”: 0,
“submitted_at”: _now_iso(),
“denial_reason”: None,
}
msg = “Submission received. Case queued for review.”
if missing:
msg += ” Initial validation indicates incomplete documentation.”
return PayerResponse(status=AuthStatus.SUBMITTED, payer_ref=payer_ref, message=msg)
def check_status(self, payer_ref: str) -> PayerResponse:
if payer_ref not in self.db:
return PayerResponse(
status=AuthStatus.DENIED,
payer_ref=payer_ref,
message=”Case not found (possible payer system error).”,
denial_reason=DenialReason.OTHER,
confidence=0.4,
)
case = self.db[payer_ref]
case[“polls”] += 1
if case[“status”] == AuthStatus.SUBMITTED and case[“polls”] >= 1:
case[“status”] = AuthStatus.IN_REVIEW
if case[“status”] == AuthStatus.IN_REVIEW and case[“polls”] >= 3:
if case[“missing”]:
case[“status”] = AuthStatus.DENIED
case[“denial_reason”] = DenialReason.MISSING_DOCS
else:
roll = random.random()
if roll < 0.10:
case[“status”] = AuthStatus.DENIED
case[“denial_reason”] = DenialReason.CODING_ISSUE
elif roll < 0.18:
case[“status”] = AuthStatus.DENIED
case[“denial_reason”] = DenialReason.MEDICAL_NECESSITY
else:
case[“status”] = AuthStatus.APPROVED
if case[“status”] == AuthStatus.DENIED:
dr = case[“denial_reason”] or DenialReason.OTHER
missing = case[“missing”] if dr == DenialReason.MISSING_DOCS else []
conf = 0.9 if dr != DenialReason.OTHER else 0.55
return PayerResponse(
status=AuthStatus.DENIED,
payer_ref=payer_ref,
message=f”Denied. Reason={dr.value}.”,
denial_reason=dr,
missing_docs=missing,
confidence=conf,
)
if case[“status”] == AuthStatus.APPROVED:
return PayerResponse(
status=AuthStatus.APPROVED,
payer_ref=payer_ref,
message=”Approved. Authorization issued.”,
confidence=0.95,
)
return PayerResponse(
status=case[“status”],
payer_ref=payer_ref,
message=f”Status={case[‘status’].value}. Polls={case[‘polls’]}.”,
confidence=0.9,
)
def file_appeal(self, payer_ref: str, appeal_text: str, attached_docs: List[ClinicalDocument]) -> PayerResponse:
if payer_ref not in self.db:
return PayerResponse(
status=AuthStatus.DENIED,
payer_ref=payer_ref,
message=”Appeal failed: case not found.”,
denial_reason=DenialReason.OTHER,
confidence=0.4,
)
case = self.db[payer_ref]
docs_present = {d.doc_type for d in attached_docs}
still_missing = [d for d in case[“missing”] if d not in docs_present]
case[“missing”] = still_missing
case[“status”] = AuthStatus.APPEALED
case[“polls”] = 0
msg = “Appeal submitted and queued for review.”
if still_missing:
msg += f” Warning: still missing {‘, ‘.join([d.value for d in still_missing])}.”
return PayerResponse(status=AuthStatus.APPEALED, payer_ref=payer_ref, message=msg, confidence=0.9)
We model payer-side behavior, including documentation policies, review timelines, and denial logic. We encode simplified but realistic payer rules to demonstrate how policy-driven automation works in practice. We expose predictable failure modes that the agent must respond to safely. Check out the FULL CODES here.
Copy CodeCopiedUse a different Browserdef required_docs_for_order(payer: MockPayerPortal, order: SurgeryOrder) -> List[DocType]:
return payer.required_docs_policy(order.patient.plan, order.surgery_type)
def attach_best_docs(ehr_docs: List[ClinicalDocument], required: List[DocType]) -> List[ClinicalDocument]:
by_type: Dict[DocType, List[ClinicalDocument]] = {}
for d in ehr_docs:
by_type.setdefault(d.doc_type, []).append(d)
attached = []
for dt in required:
if dt in by_type:
attached.append(by_type[dt][-1])
return attached
def compute_uncertainty(payer_resp: PayerResponse, missing_docs: List[DocType], llm_used: bool) -> float:
base = 0.15
if payer_resp.denial_reason in [DenialReason.OTHER]:
base += 0.35
if payer_resp.denial_reason in [DenialReason.MEDICAL_NECESSITY]:
base += 0.25
if payer_resp.denial_reason in [DenialReason.CODING_ISSUE]:
base += 0.20
if missing_docs:
base += 0.10
if llm_used:
base -= 0.05
return max(0.0, min(1.0, base + (1 – payer_resp.confidence) * 0.6))
def rule_based_denial_analysis(order: SurgeryOrder, payer_resp: PayerResponse) -> Dict[str, Any]:
rec = {“missing_docs”: [], “rationale”: “”, “appeal_text”: “”}
if payer_resp.denial_reason == DenialReason.MISSING_DOCS:
rec[“missing_docs”] = payer_resp.missing_docs
rec[“rationale”] = “Denial indicates incomplete documentation per payer policy. Collect and resubmit as appeal.”
rec[“appeal_text”] = (
f”Appeal for prior authorization ({payer_resp.payer_ref})n”
f”Patient: {order.patient.name} ({order.patient.member_id})n”
f”Procedure: {order.surgery_type.value}n”
f”Reason for appeal: Missing documentation has now been attached. Please re-review.n”
)
elif payer_resp.denial_reason == DenialReason.CODING_ISSUE:
rec[“rationale”] = “Potential coding mismatch. Verify diagnosis/procedure codes and include supporting note.”
rec[“appeal_text”] = (
f”Appeal ({payer_resp.payer_ref}): Requesting reconsideration.n”
f”Attached: Updated clinical note clarifying diagnosis and indication; please re-review coding alignment.n”
)
elif payer_resp.denial_reason == DenialReason.MEDICAL_NECESSITY:
rec[“rationale”] = “Medical necessity denial. Add prior treatments timeline, imaging severity, and functional impact.”
rec[“appeal_text”] = (
f”Appeal ({payer_resp.payer_ref}): Medical necessity reconsideration.n”
f”Attached: Prior conservative therapies, imaging, and clinician attestation of functional limitation.n”
)
else:
rec[“rationale”] = “Unclear denial. Escalate if payer message lacks actionable details.”
rec[“appeal_text”] = (
f”Appeal ({payer_resp.payer_ref}): Requesting clarification and reconsideration.n”
f”Please provide specific criteria not met; attached full clinical packet.n”
)
return rec
def llm_denial_analysis_and_appeal(order: SurgeryOrder, payer_resp: PayerResponse, docs: List[ClinicalDocument]) -> Dict[str, Any]:
if not OPENAI_AVAILABLE:
return rule_based_denial_analysis(order, payer_resp)
doc_summary = [{“doc_type”: d.doc_type.value, “source”: d.source, “created_at”: d.created_at} for d in docs]
prompt = {
“role”: “user”,
“content”: (
“You are an RCM prior authorization specialist agent.n”
“Given the order, attached docs, and payer denial response, do three things:n”
“1) Identify what documentation is missing or what needs clarification.n”
“2) Recommend next steps.n”
“3) Draft a concise appeal letter.nn”
f”ORDER:n{order.model_dump_json(indent=2)}nn”
f”PAYER_RESPONSE:n{payer_resp.model_dump_json(indent=2)}nn”
f”ATTACHED_DOCS_METADATA:n{json.dumps(doc_summary, indent=2)}nn”
“Return STRICT JSON with keys: missing_docs (list of strings), rationale (string), appeal_text (string).”
)
}
try:
resp = client.chat.completions.create(
model=”gpt-4o-mini”,
messages=[prompt],
temperature=0.2,
)
text = resp.choices[0].message.content.strip()
data = json.loads(text)
missing = []
for x in data.get(“missing_docs”, []):
try:
missing.append(DocType(x))
except Exception:
pass
return {
“missing_docs”: missing,
“rationale”: data.get(“rationale”, “”),
“appeal_text”: data.get(“appeal_text”, “”),
}
except Exception:
return rule_based_denial_analysis(order, payer_resp)
class PriorAuthAgent:
def __init__(self, ehr: MockEHR, payer: MockPayerPortal, uncertainty_threshold: float = 0.55):
self.ehr = ehr
self.payer = payer
self.uncertainty_threshold = uncertainty_threshold
self.audit_log: List[Dict[str, Any]] = []
def log(self, event: str, payload: Dict[str, Any]):
self.audit_log.append({“ts”: _now_iso(), “event”: event, **payload})
def build_prior_auth_request(self, order: SurgeryOrder) -> PriorAuthRequest:
required = required_docs_for_order(self.payer, order)
docs = self.ehr.get_patient_documents(order.patient.patient_id)
attached = attach_best_docs(docs, required)
req = PriorAuthRequest(
request_id=_stable_id(“PA”, order.order_id + order.patient.member_id),
order=order,
docs_attached=attached,
payload={
“member_id”: order.patient.member_id,
“plan”: order.patient.plan.value,
“procedure”: order.surgery_type.value,
“diagnosis_codes”: order.diagnosis_codes,
“scheduled_date”: order.scheduled_date,
“provider_npi”: order.ordering_provider_npi,
“attached_doc_types”: [d.doc_type.value for d in attached],
}
)
self.log(“pa_request_built”, {“order_id”: order.order_id, “required_docs”: [d.value for d in required], “attached”: req.payload[“attached_doc_types”]})
return req
def submit_and_monitor(self, pa: PriorAuthRequest, max_polls: int = 7) -> Dict[str, Any]:
pa.submitted_at = _now_iso()
submit_resp = self.payer.submit(pa)
self.log(“submitted”, {“request_id”: pa.request_id, “payer_ref”: submit_resp.payer_ref, “message”: submit_resp.message})
payer_ref = submit_resp.payer_ref
for _ in range(max_polls):
time.sleep(0.25)
status = self.payer.check_status(payer_ref)
self.log(“status_polled”, {“payer_ref”: payer_ref, “status”: status.status.value, “message”: status.message})
if status.status == AuthStatus.APPROVED:
return {“final_status”: “APPROVED”, “payer_ref”: payer_ref, “details”: status.model_dump()}
if status.status == AuthStatus.DENIED:
decision = self.handle_denial(pa, payer_ref, status)
if decision.action == “escalate”:
return {
“final_status”: “ESCALATED_TO_HUMAN”,
“payer_ref”: payer_ref,
“decision”: decision.model_dump(),
“details”: status.model_dump(),
}
if decision.action == “appeal”:
appeal_docs = pa.docs_attached[:]
appeal_resp = self.payer.file_appeal(payer_ref, decision.appeal_text or “”, appeal_docs)
self.log(“appeal_filed”, {“payer_ref”: payer_ref, “message”: appeal_resp.message})
for _ in range(max_polls):
time.sleep(0.25)
post = self.payer.check_status(payer_ref)
self.log(“post_appeal_polled”, {“payer_ref”: payer_ref, “status”: post.status.value, “message”: post.message})
if post.status == AuthStatus.APPROVED:
return {“final_status”: “APPROVED_AFTER_APPEAL”, “payer_ref”: payer_ref, “details”: post.model_dump()}
if post.status == AuthStatus.DENIED:
return {“final_status”: “DENIED_AFTER_APPEAL”, “payer_ref”: payer_ref, “details”: post.model_dump(), “decision”: decision.model_dump()}
return {“final_status”: “APPEAL_PENDING”, “payer_ref”: payer_ref, “decision”: decision.model_dump()}
return {“final_status”: “DENIED_NO_ACTION”, “payer_ref”: payer_ref, “decision”: decision.model_dump(), “details”: status.model_dump()}
return {“final_status”: “PENDING_TIMEOUT”, “payer_ref”: payer_ref}
def handle_denial(self, pa: PriorAuthRequest, payer_ref: str, denial_resp: PayerResponse) -> AgentDecision:
order = pa.order
analysis = llm_denial_analysis_and_appeal(order, denial_resp, pa.docs_attached) if (USE_OPENAI and OPENAI_AVAILABLE) else rule_based_denial_analysis(order, denial_resp)
missing_docs: List[DocType] = analysis.get(“missing_docs”, [])
rationale: str = analysis.get(“rationale”, “”)
appeal_text: str = analysis.get(“appeal_text”, “”)
if denial_resp.denial_reason == DenialReason.MISSING_DOCS and denial_resp.missing_docs:
missing_docs = denial_resp.missing_docs
if missing_docs:
new_docs = self.ehr.fetch_additional_docs(order.patient.patient_id, missing_docs)
pa.docs_attached.extend(new_docs)
self.log(“missing_docs_collected”, {“payer_ref”: payer_ref, “collected”: [d.doc_type.value for d in new_docs]})
uncertainty = compute_uncertainty(denial_resp, missing_docs, llm_used=(USE_OPENAI and OPENAI_AVAILABLE))
self.log(“denial_analyzed”, {“payer_ref”: payer_ref, “denial_reason”: (denial_resp.denial_reason.value if denial_resp.denial_reason else None),
“uncertainty”: uncertainty, “missing_docs”: [d.value for d in missing_docs]})
if uncertainty >= self.uncertainty_threshold:
return AgentDecision(
action=”escalate”,
missing_docs=missing_docs,
rationale=f”{rationale} Escalating due to high uncertainty ({uncertainty:.2f}) >= threshold ({self.uncertainty_threshold:.2f}).”,
uncertainty=uncertainty,
next_wait_seconds=0,
)
if not appeal_text:
analysis2 = rule_based_denial_analysis(order, denial_resp)
appeal_text = analysis2.get(“appeal_text”, “”)
attached_types = sorted(list({d.doc_type.value for d in pa.docs_attached}))
appeal_text = (
appeal_text.strip()
+ “nnAttached documents:n- ”
+ “n- “.join(attached_types)
+ “nnRequested outcome: Reconsideration and authorization issuance.n”
)
return AgentDecision(
action=”appeal”,
missing_docs=missing_docs,
rationale=f”{rationale} Proceeding autonomously (uncertainty {uncertainty:.2f} < threshold {self.uncertainty_threshold:.2f}).”,
uncertainty=uncertainty,
appeal_text=appeal_text,
next_wait_seconds=1,
)
We implement the core intelligence layer that attaches documents, analyzes denials, and estimates uncertainty. We demonstrate how rule-based logic and optional LLM reasoning can coexist without compromising determinism. We explicitly gate automation decisions to maintain safety in a healthcare context. Check out the FULL CODES here.
Copy CodeCopiedUse a different Browserehr = MockEHR()
ehr.seed_data(n_orders=6)
payer = MockPayerPortal()
agent = PriorAuthAgent(ehr, payer, uncertainty_threshold=0.55)
results = []
print(“=== Starting Autonomous Prior Authorization Agent Demo ===”)
print(f”OpenAI enabled: {USE_OPENAI and OPENAI_AVAILABLE}n”)
while True:
new_orders = ehr.poll_new_surgery_orders(max_n=1)
if not new_orders:
break
order = new_orders[0]
print(f”n— New Surgery Order Detected —“)
print(f”Order: {order.order_id} | Patient: {order.patient.patient_id} | Plan: {order.patient.plan.value} | Surgery: {order.surgery_type.value}”)
pa = agent.build_prior_auth_request(order)
outcome = agent.submit_and_monitor(pa, max_polls=7)
results.append({“order_id”: order.order_id, “patient_id”: order.patient.patient_id, **outcome})
print(f”Outcome: {outcome[‘final_status’]} | PayerRef: {outcome.get(‘payer_ref’)}”)
print(“n=== Summary ===”)
status_counts = {}
for r in results:
status_counts[r[“final_status”]] = status_counts.get(r[“final_status”], 0) + 1
print(“Final status counts:”, status_counts)
print(“nSample result (first case):”)
print(json.dumps(results[0], indent=2))
print(“n=== Audit Log (last ~12 events) ===”)
for row in agent.audit_log[-12:]:
print(json.dumps(row, indent=2))
print(
“nHardening checklist (high level):n”
“- Swap mocks for real EHR + payer integrations (FHIR/HL7, payer APIs/portal automations)n”
“- Add PHI governance (tokenization, least-privilege access, encrypted logging, retention controls)n”
“- Add deterministic policy engine + calibrated uncertainty modeln”
“- Add human-in-the-loop UI with SLA timers, retries/backoff, idempotency keysn”
“- Add evidence packing (policy citations, structured attachments, templates)n”
)
We orchestrate the full end-to-end workflow and generate operational summaries and audit logs. We track outcomes, escalation events, and system behavior to support transparency and compliance. We emphasize observability and traceability as essential requirements for healthcare AI systems.
In conclusion, we illustrated how agentic AI can meaningfully reduce administrative friction in healthcare RCM by automating repetitive, rules-driven prior authorization tasks while preserving human oversight for ambiguous or high-risk decisions. We showed that combining deterministic policy logic, uncertainty estimation, and optional LLM-assisted reasoning enables a balanced approach that aligns with healthcare’s safety-critical nature. This work should be viewed as an architectural and educational reference rather than a deployable medical system; any real-world implementation must adhere to HIPAA and regional data protection laws, incorporate de-identification and access controls, undergo clinical and compliance review, and be validated against payer-specific policies.
Check out the FULL CODES here. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
The post How to Build a Safe, Autonomous Prior Authorization Agent for Healthcare Revenue Cycle Management with Human-in-the-Loop Controls appeared first on MarkTechPost.