Amazon Bedrock has emerged as the preferred choice for tens of thousands of customers seeking to build their generative AI strategy. It offers a straightforward, fast, and secure way to develop advanced generative AI applications and experiences to drive innovation.
With the comprehensive capabilities of Amazon Bedrock, you have access to a diverse range of high-performing foundation models (FMs), empowering you to select the most suitable option for your specific needs, customize the model privately with your own data using techniques such as fine-tuning and Retrieval Augmented Generation (RAG), and create managed agents that run complex business tasks.
Fine-tuning pre-trained language models allows organizations to customize and optimize the models for their specific use cases, providing better performance and more accurate outputs tailored to their unique data and requirements. By using fine-tuning capabilities, businesses can unlock the full potential of generative AI while maintaining control over the model’s behavior and aligning it with their goals and values.
In this post, we delve into the essential security best practices that organizations should consider when fine-tuning generative AI models.
Security in Amazon Bedrock
Cloud security at AWS is the highest priority. Amazon Bedrock prioritizes security through a comprehensive approach to protect customer data and AI workloads.
Amazon Bedrock is built with security at its core, offering several features to protect your data and models. The main aspects of its security framework include:
Access control – This includes features such as:
Fine-grained access control using AWS Identity and Access Management (IAM)
Resource-based policies to control access to specific Amazon Bedrock resources
Data encryption – Amazon Bedrock offers the following encryption:
Data at rest is encrypted using AWS Key Management Service (AWS KMS)
Data in transit is encrypted using TLS 1.2 or higher
Network security – Amazon Bedrock offers several security options, including:
Support for AWS PrivateLink to establish private connectivity between your virtual private cloud (VPC) and Amazon Bedrock
VPC endpoints for secure communication within your AWS environment
Compliance – Amazon Bedrock is in alignment with various industry standards and regulations, including HIPAA, SOC, and PCI DSS
Solution overview
Model customization is the process of providing training data to a model to improve its performance for specific use cases. Amazon Bedrock currently offers the following customization methods:
Continued pre-training – Enables tailoring an FM’s capabilities to specific domains by fine-tuning its parameters with unlabeled, proprietary data, allowing continuous improvement as more relevant data becomes available.
Fine-tuning – Involves providing labeled data to train a model on specific tasks, enabling it to learn the appropriate outputs for given inputs. This process adjusts the model’s parameters, enhancing its performance on the tasks represented by the labeled training dataset.
Distillation – Process of transferring knowledge from a larger more intelligent model (known as teacher) to a smaller, faster, cost-efficient model (known as student).
Model customization in Amazon Bedrock involves the following actions:
Create training and validation datasets.
Set up IAM permissions for data access.
Configure a KMS key and VPC.
Create a fine-tuning or pre-training job with hyperparameter tuning.
Analyze results through metrics and evaluation.
Purchase provisioned throughput for the custom model.
Use the custom model for tasks like inference.
In this post, we explain these steps in relation to fine-tuning. However, you can apply the same concepts for continued pre-training as well.
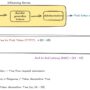
The following architecture diagram explains the workflow of Amazon Bedrock model fine-tuning.
The workflow steps are as follows:
The user submits an Amazon Bedrock fine-tuning job within their AWS account, using IAM for resource access.
The fine-tuning job initiates a training job in the model deployment accounts.
To access training data in your Amazon Simple Storage Service (Amazon S3) bucket, the job employs Amazon Security Token Service (AWS STS) to assume role permissions for authentication and authorization.
Network access to S3 data is facilitated through a VPC network interface, using the VPC and subnet details provided during job submission.
The VPC is equipped with private endpoints for Amazon S3 and AWS KMS access, enhancing overall security.
The fine-tuning process generates model artifacts, which are stored in the model provider AWS account and encrypted using the customer-provided KMS key.
This workflow provides secure data handling across multiple AWS accounts while maintaining customer control over sensitive information using customer managed encryption keys.
The customer is in control of the data; model providers don’t have access to the data, and they don’t have access to a customer’s inference data or their customization training datasets. Therefore, data will not be available to model providers for them to improve their base models. Your data is also unavailable to the Amazon Bedrock service team.
In the following sections, we go through the steps of fine-tuning and deploying the Meta Llama 3.1 8B Instruct model in Amazon Bedrock using the Amazon Bedrock console.
Prerequisites
Before you get started, make sure you have the following prerequisites:
An AWS account
An IAM federation role with access to do the following:
Create, edit, view, and delete VPC network and security resources
Create, edit, view, and delete KMS keys
Create, edit, view, and delete IAM roles and policies for model customization
Create, upload, view, and delete S3 buckets to access training and validation data and permission to write output data to Amazon S3
List FMs on the base model that will be used for fine-tuning
Create a custom training job for the Amazon Bedrock FM
Provisioned model throughputs
List custom models and invoke model permissions on the fine-tuned model
Model access, which you can request through the Amazon Bedrock console
For this post, we use the us-west-2 AWS Region. For instructions on assigning permissions to the IAM role, refer to Identity-based policy examples for Amazon Bedrock and How Amazon Bedrock works with IAM.
Prepare your data
To fine-tune a text-to-text model like Meta Llama 3.1 8B Instruct, prepare a training and optional validation dataset by creating a JSONL file with multiple JSON lines.
Each JSON line is a sample containing a prompt and completion field. The format is as follows:
{“prompt”: “<prompt1>”, “completion”: “<expected generated text>”}
{“prompt”: “<prompt2>”, “completion”: “<expected generated text>”}
The following is an example from a sample dataset used as one-line input for fine-tuning Meta Llama 3.1 8B Instruct in Amazon Bedrock. In JSONL format, each record is one text line.
{“prompt”: “consumer complaints and resolutions for financial products”, “completion”: “{‘Date received’: ’01/01/24′, ‘Product’: ‘Credit card’, ‘Sub-product’: ‘Store credit card’, ‘Issue’: ‘Other features, terms, or problems’, ‘Sub-issue’: ‘Other problem’, ‘Consumer complaint narrative’: None, ‘Company public response’: None, ‘Company’: ‘Bread Financial Holdings, Inc.’, ‘State’: ‘MD’, ‘ZIP code’: ‘21060’, ‘Tags’: ‘Servicemember’, ‘Consumer consent provided?’: ‘Consent not provided’, ‘Submitted via’: ‘Web’, ‘Date sent to company’: ’01/01/24′, ‘Company response to consumer’: ‘Closed with non-monetary relief’, ‘Timely response?’: ‘Yes’, ‘Consumer disputed?’: None, ‘Complaint ID’: 8087806}”}
Create a KMS symmetric key
When uploading your training data to Amazon S3, you can use server-side encryption with AWS KMS. You can create KMS keys on the AWS Management Console, the AWS Command Line Interface (AWS CLI) and SDKs, or an AWS CloudFormation template. Complete the following steps to create a KMS key in the console:
On the AWS KMS console, choose Customer managed keys in the navigation pane.
Choose Create key.
Create a symmetric key. For instructions, see Create a KMS key.
Create an S3 bucket and configure encryption
Complete the following steps to create an S3 bucket and configure encryption:
On the Amazon S3 console, choose Buckets in the navigation pane.
Choose Create bucket.
For Bucket name, enter a unique name for your bucket.
For Encryption type¸ select Server-side encryption with AWS Key Management Service keys.
For AWS KMS key, select Choose from your AWS KMS keys and choose the key you created.
Complete the bucket creation with default settings or customize as needed.
Upload the training data
Complete the following steps to upload the training data:
On the Amazon S3 console, navigate to your bucket.
Create the folders fine-tuning-datasets and outputs and keep the bucket encryption settings as server-side encryption.
Choose Upload and upload your training data file.
Create a VPC
To create a VPC using Amazon Virtual Private Cloud (Amazon VPC), complete the following steps:
On the Amazon VPC console, choose Create VPC.
Create a VPC with private subnets in all Availability Zones.
Create an Amazon S3 VPC gateway endpoint
You can further secure your VPC by setting up an Amazon S3 VPC endpoint and using resource-based IAM policies to restrict access to the S3 bucket containing the model customization data.
Let’s create an Amazon S3 gateway endpoint and attach it to VPC with custom IAM resource-based policies to more tightly control access to your Amazon S3 files.
The following code is a sample resource policy. Use the name of the bucket you created earlier.
{
“Version”: “2012-10-17”,
“Statement”: [
{
“Sid”: “RestrictAccessToTrainingBucket”,
“Effect”: “Allow”,
“Principal”: “*”,
“Action”: [
“s3:GetObject”,
“s3:PutObject”,
“s3:ListBucket”
],
“Resource”: [
“arn:aws:s3:::$your-bucket”,
“arn:aws:s3:::$your-bucket/*”
]
}
]
}
Create a security group for the AWS KMS VPC interface endpoint
A security group acts as a virtual firewall for your instance to control inbound and outbound traffic. This VPC endpoint security group only allows traffic originating from the security group attached to your VPC private subnets, adding a layer of protection. Complete the following steps to create the security group:
On the Amazon VPC console, choose Security groups in the navigation pane.
Choose Create security group.
For Security group name, enter a name (for example, bedrock-kms-interface-sg).
For Description, enter a description.
For VPC, choose your VPC.
Add an inbound rule to HTTPS traffic from the VPC CIDR block.
Create a security group for the Amazon Bedrock custom fine-tuning job
Now you can create a security group to establish rules for controlling Amazon Bedrock custom fine-tuning job access to the VPC resources. You use this security group later during model customization job creation. Complete the following steps:
On the Amazon VPC console, choose Security groups in the navigation pane.
Choose Create security group.
For Security group name, enter a name (for example, bedrock-fine-tuning-custom-job-sg).
For Description, enter a description.
For VPC, choose your VPC.
Add an inbound rule to allow traffic from the security group.
Create an AWS KMS VPC interface endpoint
Now you can create an interface VPC endpoint (PrivateLink) to establish a private connection between the VPC and AWS KMS.
For the security group, use the one you created in the previous step.
Attach a VPC endpoint policy that controls the access to resources through the VPC endpoint. The following code is a sample resource policy. Use the Amazon Resource Name (ARN) of the KMS key you created earlier.
{
“Statement”: [
{
“Sid”: “AllowDecryptAndView”,
“Principal”: {
“AWS”: “*”
},
“Effect”: “Allow”,
“Action”: [
“kms:Decrypt”,
“kms:DescribeKey”,
“kms:ListAliases”,
“kms:ListKeys”
],
“Resource”: “$Your-KMS-KEY-ARN”
}
]
}
Now you have successfully created the endpoints needed for private communication.
Create a service role for model customization
Let’s create a service role for model customization with the following permissions:
A trust relationship for Amazon Bedrock to assume and carry out the model customization job
Permissions to access your training and validation data in Amazon S3 and to write your output data to Amazon S3
If you encrypt any of the following resources with a KMS key, permissions to decrypt the key (see Encryption of model customization jobs and artifacts)
A model customization job or the resulting custom model
The training, validation, or output data for the model customization job
Permission to access the VPC
Let’s first create the required IAM policies:
On the IAM console, choose Policies in the navigation pane.
Choose Create policy.
Under Specify permissions¸ use the following JSON to provide access on S3 buckets, VPC, and KMS keys. Provide your account, bucket name, and VPC settings.
You can use the following IAM permissions policy as a template for VPC permissions:
{
“Version”: “2012-10-17”,
“Statement”: [
{
“Effect”: “Allow”,
“Action”: [
“ec2:DescribeNetworkInterfaces”,
“ec2:DescribeVpcs”,
“ec2:DescribeDhcpOptions”,
“ec2:DescribeSubnets”,
“ec2:DescribeSecurityGroups”
],
“Resource”: “*”
},
{
“Effect”: “Allow”,
“Action”: [
“ec2:CreateNetworkInterface”,
],
“Resource”:[
“arn:aws:ec2:${{region}}:${{account-id}}:network-interface/*”
],
“Condition”: {
“StringEquals”: {
“aws:RequestTag/BedrockManaged”: [“true”]
},
“ArnEquals”: {
“aws:RequestTag/BedrockModelCustomizationJobArn”: [“arn:aws:bedrock:${{region}}:${{account-id}}:model-customization-job/*”]
}
}
},
{
“Effect”: “Allow”,
“Action”: [
“ec2:CreateNetworkInterface”,
],
“Resource”:[
“arn:aws:ec2:${{region}}:${{account-id}}:subnet/${{subnet-id}}”,
“arn:aws:ec2:${{region}}:${{account-id}}:subnet/${{subnet-id2}}”,
“arn:aws:ec2:${{region}}:${{account-id}}:security-group/security-group-id”
]
},
{
“Effect”: “Allow”,
“Action”: [
“ec2:CreateNetworkInterfacePermission”,
“ec2:DeleteNetworkInterface”,
“ec2:DeleteNetworkInterfacePermission”,
],
“Resource”: “*”,
“Condition”: {
“ArnEquals”: {
“ec2:Subnet”: [
“arn:aws:ec2:${{region}}:${{account-id}}:subnet/${{subnet-id}}”,
“arn:aws:ec2:${{region}}:${{account-id}}:subnet/${{subnet-id2}}”
],
“ec2:ResourceTag/BedrockModelCustomizationJobArn”: [“arn:aws:bedrock:${{region}}:${{account-id}}:model-customization-job/*”]
},
“StringEquals”: {
“ec2:ResourceTag/BedrockManaged”: “true”
}
}
},
{
“Effect”: “Allow”,
“Action”: [
“ec2:CreateTags”
],
“Resource”: “arn:aws:ec2:${{region}}:${{account-id}}:network-interface/*”,
“Condition”: {
“StringEquals”: {
“ec2:CreateAction”: [
“CreateNetworkInterface”
]
},
“ForAllValues:StringEquals”: {
“aws:TagKeys”: [
“BedrockManaged”,
“BedrockModelCustomizationJobArn”
]
}
}
}
]
}
You can use the following IAM permissions policy as a template for Amazon S3 permissions:
{
“Version”: “2012-10-17”,
“Statement”: [
{
“Effect”: “Allow”,
“Action”: [
“s3:GetObject”,
“s3:ListBucket”
],
“Resource”: [
“arn:aws:s3:::training-bucket”,
“arn:aws:s3:::training-bucket/*”,
“arn:aws:s3:::validation-bucket”,
“arn:aws:s3:::validation-bucket/*”
]
},
{
“Effect”: “Allow”,
“Action”: [
“s3:GetObject”,
“s3:PutObject”,
“s3:ListBucket”
],
“Resource”: [
“arn:aws:s3:::output-bucket”,
“arn:aws:s3:::output-bucket/*”
]
}
]
}
Now let’s create the IAM role.
On the IAM console, choose Roles in the navigation pane.
Choose Create roles.
Create a role with the following trust policy (provide your AWS account ID):
{
“Version”: “2012-10-17”,
“Statement”: [
{
“Effect”: “Allow”,
“Principal”: {
“Service”: “bedrock.amazonaws.com”
},
“Action”: “sts:AssumeRole”,
“Condition”: {
“StringEquals”: {
“aws:SourceAccount”: “account-id”
},
“ArnEquals”: {
“aws:SourceArn”: “arn:aws:bedrock:us-west-2:account-id:model-customization-job/*”
}
}
}
]
}
Assign your custom VPC and S3 bucket access policies.
Give a name to your role and choose Create role.
Update the KMS key policy with the IAM role
In the KMS key you created in the previous steps, you need to update the key policy to include the ARN of the IAM role. The following code is a sample key policy:
{
“Version”: “2012-10-17”,
“Id”: “key-consolepolicy-3”,
“Statement”: [
{
“Sid”: “BedrockFineTuneJobPermissions”,
“Effect”: “Allow”,
“Principal”: {
“AWS”: “$IAM Role ARN”
},
“Action”: [
“kms:Decrypt”,
“kms:GenerateDataKey”,
“kms:Encrypt”,
“kms:DescribeKey”,
“kms:CreateGrant”,
“kms:RevokeGrant”
],
“Resource”: “$ARN of the KMS key”
}
]
}
For more details, refer to Encryption of model customization jobs and artifacts.
Initiate the fine-tuning job
Complete the following steps to set up your fine-tuning job:
On the Amazon Bedrock console, choose Custom models in the navigation pane.
In the Models section, choose Customize model and Create fine-tuning job.
Under Model details, choose Select model.
Choose Llama 3.1 8B Instruct as the base model and choose Apply.
For Fine-tuned model name, enter a name for your custom model.
Select Model encryption to add a KMS key and choose the KMS key you created earlier.
For Job name, enter a name for the training job.
Optionally, expand the Tags section to add tags for tracking.
Under VPC Settings, choose the VPC, subnets, and security group you created as part of previous steps.
When you specify the VPC subnets and security groups for a job, Amazon Bedrock creates elastic network interfaces (ENIs) that are associated with your security groups in one of the subnets. ENIs allow the Amazon Bedrock job to connect to resources in your VPC.
We recommend that you provide at least one subnet in each Availability Zone.
Under Input data, specify the S3 locations for your training and validation datasets.
Under Hyperparameters, set the values for Epochs, Batch size, Learning rate, and Learning rate warm up steps for your fine-tuning job.
Refer to Custom model hyperparameters for additional details.
Under Output data, for S3 location, enter the S3 path for the bucket storing fine-tuning metrics.
Under Service access, select a method to authorize Amazon Bedrock. You can select Use an existing service role and use the role you created earlier.
Choose Create Fine-tuning job.
Monitor the job
On the Amazon Bedrock console, choose Custom models in the navigation pane and locate your job.
You can monitor the job on the job details page.
Purchase provisioned throughput
After fine-tuning is complete (as shown in the following screenshot), you can use the custom model for inference. However, before you can use a customized model, you need to purchase provisioned throughput for it.
Complete the following steps:
On the Amazon Bedrock console, under Foundation models in the navigation pane, choose Custom models.
On the Models tab, select your model and choose Purchase provisioned throughput.
For Provisioned throughput name, enter a name.
Under Select model, make sure the model is the same as the custom model you selected earlier.
Under Commitment term & model units, configure your commitment term and model units. Refer to Increase model invocation capacity with Provisioned Throughput in Amazon Bedrock for additional insights. For this post, we choose No commitment and use 1 model unit.
Under Estimated purchase summary, review the estimated cost and choose Purchase provisioned throughput.
After the provisioned throughput is in service, you can use the model for inference.
Use the model
Now you’re ready to use your model for inference.
On the Amazon Bedrock console, under Playgrounds in the navigation pane, choose Chat/text.
Choose Select model.
For Category, choose Custom models under Custom & self-hosted models.
For Model, choose the model you just trained.
For Throughput, choose the provisioned throughput you just purchased.
Choose Apply.
Now you can ask sample questions, as shown in the following screenshot.
Implementing these procedures allows you to follow security best practices when you deploy and use your fine-tuned model within Amazon Bedrock for inference tasks.
When developing a generative AI application that requires access to this fine-tuned model, you have the option to configure it within a VPC. By employing a VPC interface endpoint, you can make sure communication between your VPC and the Amazon Bedrock API endpoint occurs through a PrivateLink connection, rather than through the public internet.
This approach further enhances security and privacy. For more information on this setup, refer to Use interface VPC endpoints (AWS PrivateLink) to create a private connection between your VPC and Amazon Bedrock.
Clean up
Delete the following AWS resources created for this demonstration to avoid incurring future charges:
Amazon Bedrock model provisioned throughput
VPC endpoints
VPC and associated security groups
KMS key
IAM roles and policies
S3 bucket and objects
Conclusion
In this post, we implemented secure fine-tuning jobs in Amazon Bedrock, which is crucial for protecting sensitive data and maintaining the integrity of your AI models.
By following the best practices outlined in this post, including proper IAM role configuration, encryption at rest and in transit, and network isolation, you can significantly enhance the security posture of your fine-tuning processes.
By prioritizing security in your Amazon Bedrock workflows, you not only safeguard your data and models, but also build trust with your stakeholders and end-users, enabling responsible and secure AI development.
As a next step, try the solution out in your account and share your feedback.
About the Authors
Vishal Naik is a Sr. Solutions Architect at Amazon Web Services (AWS). He is a builder who enjoys helping customers accomplish their business needs and solve complex challenges with AWS solutions and best practices. His core area of focus includes Generative AI and Machine Learning. In his spare time, Vishal loves making short films on time travel and alternate universe themes.
Sumeet Tripathi is an Enterprise Support Lead (TAM) at AWS in North Carolina. He has over 17 years of experience in technology across various roles. He is passionate about helping customers to reduce operational challenges and friction. His focus area is AI/ML and Energy & Utilities Segment. Outside work, He enjoys traveling with family, watching cricket and movies.