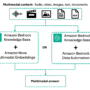
Today, most agents operate only on what’s visible in the current interaction: they can access facts and knowledge, but they can’t remember how they solved similar problems before or why certain approaches worked or failed. This creates a significant gap in their ability to learn and improve over time. Amazon Bedrock AgentCore episodic memory addresses this limitation by capturing and surfacing experience-level knowledge for AI agents. Although semantic memory helps an agent remember what it knows, episodic memory documents how it arrived there: the goal, reasoning steps, actions, outcomes, and reflections. By converting each interaction into a structured episode, you can enable agents to recall knowledge and interpret and apply prior reasoning. This helps agents adapt across sessions, avoid repeating mistakes, and evolve their planning over time.
Amazon Bedrock AgentCore Memory is a fully managed service that helps developers create context-aware AI agents through both short-term memory and long-term intelligent memory capabilities. To learn more, see Amazon Bedrock AgentCore Memory: Building context-aware agents and Building smarter AI agents: AgentCore long-term memory deep dive.
In this post, we walk you through the complete architecture to structure and store episodes, discuss the reflection module, and share compelling benchmarks that demonstrate significant improvements in agent task success rates.
Key challenges in designing agent episodic memory
Episodic memory enables agents to retain and reason over their own experiences. However, designing such a system requires solving several key challenges to make sure experiences remain coherent, evaluable, and reusable:
Maintaining temporal and causal coherence – Episodes need to preserve the order and cause-effect flow of reasoning steps, actions, and outcomes so the agent can understand how its decisions evolved.
Detecting and segmenting multiple goals – Sessions often involve overlapping or shifting goals. The episodic memory must identify and separate them to avoid mixing unrelated reasoning traces.
Learning from experience – Each episode should be evaluated for success or failure. Reflection should then compare similar past episodes to identify generalizable patterns and principles, enabling the agent to adapt those insights to new goals rather than replaying prior trajectories.
In the next section, we describe how to build an AgentCore episodic memory strategy, covering its extraction, storage, retrieval, and reflection pipeline and how these components work together to help transform experience into adaptive intelligence.
How AgentCore episodic memory works
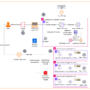
When your agentic application sends conversational events to AgentCore Memory, raw interactions get transformed into rich episodic memory records through an intelligent extraction and reflection process. The following diagram illustrates how this episodic memory strategy works and how simple agent conversations become meaningful, reflective memories that shape future interactions.
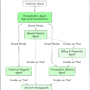
The following diagram illustrates the detailed data flow of the same architecture with more elaborate details.
The preceding diagrams illustrate the different steps in the episodic memory strategy. The first two steps (marked pink and purple) are grouped together as a two-stage approach of the episode extraction module that serves distinct but complementary purposes. The third step (marked as blue) is the reflection module, which helps the agent learn from the past experience. In the following sections, we discuss the steps in detail.
Episode extraction module
The episode extraction module is the foundational step in the episodic strategy that transforms raw user-agent interaction data into structured, meaningful episodes. We follow a two-stage approach where the stages are designed to capture both granular step-wise mechanics of each interaction (called turn extraction) and broader episode-wise knowledge to create coherent narratives (called episode extraction). To make an analogy, think of it in terms of taking notes during a meeting (turn level) and writing the meeting summary at the end of the meeting (episode). Both stages are valuable but serve different purposes when learning from experience.
In the first stage of episode extraction, the system performs turn-level processing to understand what went right or wrong. Here, single exchange units between the user and the agent called conversational turns are identified, segmented, and transformed into structured summaries in the following dimensions:
Turn situation – A brief description of the circumstances and context that the assistant is responding to in this turn. This includes the immediate context, the user’s overarching objectives that might span multiple turns, and the relevant history from previous interactions that informed the current exchange.
Turn intent – The assistant’s specific purpose and primary goal for this turn, essentially answering the question “What was the assistant trying to accomplish in this moment?”
Turn action – A detailed record of the concrete steps taken during the interaction, documenting which specific tools were used, what input arguments or parameters were provided to each tool, and how the assistant translated intent into executable actions.
Turn thought – The reasoning behind the assistant’s decisions, explaining the “why” behind tool selection and approach.
Turn assessment – An honest evaluation of whether the assistant successfully achieved its stated goal for this specific turn, providing immediate feedback on the effectiveness of the chosen approach and actions taken.
Goal assessment – A broader perspective on whether the user’s overall objective across the entire conversation appears to be satisfied or progressing toward completion, looking beyond individual turns to evaluate holistic success.
After processing and structuring individual turns, the system proceeds to the episode extraction stage, when a user completes their goal (detected by the large language model) or an interaction ends. This helps capture the complete user journey, because a user’s goal often spans multiple turns and individual turn data alone can’t convey whether the overall objective was achieved or what the holistic strategy looked like. In this stage, sequentially related turns are synthesized into coherent episodic memories that capture complete user journeys, from initial request to final resolution:
Episode situation – The broader circumstances that initiated the user’s need for assistance
Episode intent – A clear articulation of what the user ultimately wanted to accomplish
Success evaluation – A definitive assessment of whether the conversation achieved its intended purpose for each episode
Evaluation justification – Concrete reasoning for success or failure assessments, grounded in specific conversational moments that demonstrate progress toward or away from user goals
Episode insights – Insights capturing proven effective approaches and identifying pitfalls to avoid for the current episode
Reflection module
The reflection module highlights the ability of Amazon Bedrock AgentCore episodic memory to learn from past experiences and generate insights that help improve future performance. This is where individual episode learnings evolve into generalizable knowledge that can guide agents across diverse scenarios.
The reflection module operates through cross-episodic reflection, retrieving past similar successful episodes based on user intent and reflecting across multiple episodes to achieve more generalizable insights. When new episodes are processed, the system performs the following actions:
Using the user intent as a semantic key, the system identifies historically successful and relevant episodes from the vector store that share similar goals, contexts, or problem domains.
The system analyzes patterns across the main episode and relevant episodes, looking for transferable insights about what approaches work consistently across different contexts.
Existing reflection knowledge is reviewed and either enhanced with new insights or expanded with entirely new patterns discovered through cross-episodic analysis.
At the end of the process, each reflection memory record contains the following information:
Use case – When and where the insight applies, including relevant user goals and trigger conditions
Hints (insights) – Actionable guidance covering tool selection strategies, effective approaches, and pitfalls to avoid
Confidence scoring – A score (0.1–1.0) indicating how well the insight generalizes across different scenarios
Episodes provide agents with concrete examples of how similar problems were solved before. These case studies show the specific tools used, reasoning applied, and outcomes achieved, including both successes and failures. This creates a learning framework where agents can follow proven strategies and avoid documented mistakes.
Reflection memories extract patterns from multiple episodes to deliver strategic insights. Instead of individual cases, they reveal which tools work best, what decision-making approaches succeed, and which factors drive outcomes. These distilled principles give agents higher-level guidance for navigating complex scenarios.
Custom override configurations
Although built-in memory strategies cover the common use cases, many domains require tailored approaches for memory processing. The system supports built-in strategy overrides through custom prompts that extend the built-in logic, helping teams adapt memory handling to their specific requirement. You can implement the following custom override configurations:
Custom prompts – These prompts focus on criteria and logic rather than output formats and help developers define the following:
Extraction criteria – What information gets extracted or filtered out.
Consolidation rules – How related memories should be consolidated.
Conflict resolution – How to handle contradictory information.
Insight generation – How cross-episode reflections are synthesized.
Custom model: AgentCore Memory supports custom model selection for memory extraction, consolidation, and reflection operations. This flexibility helps developers balance accuracy and latency based on their specific requirements. You can define them using APIs when you create the _memory_resource_ as a strategy override or through the Amazon Bedrock AgentCore console (as shown in the following screenshot).
Namespaces: Namespaces provide a hierarchical organization for episodes and reflections, enabling access to your agent’s experiences at different levels of granularity and providing a seamless natural logical grouping. For instance, to design a namespace for a travel application, episodes could be stored under travel_booking/users/userABC/episodes and reflections could reside at travel_booking/users/userABC. Note that the namespace for reflections must be a sub-path of the namespace for episodes.
Performance evaluation
We evaluated Amazon Bedrock AgentCore episodic memory on real-world goal completion benchmarks from the retail and airline domain (sampled from τ2-bench). These benchmarks contain tasks that mirror actual customer service scenarios where agents need to help users achieve specific goals.
We compared three different setups in our experiments:
For the baseline, we ran the agent (built with Anthropic’s Claude 3.7) without interacting with the memory component.
For memory-augmented agents, we explored two methods of using memories:
In-context learning examples – The first method uses extracted episodes as in-context learning examples. Specifically, we constructed a tool named retrieve_exemplars (tool definition in appendix) that agents can use by issuing a query (for example, “how to get refund?”) to get step-by-step instructions from the episodes repository. When agents face similar problems, the retrieved episodes will be added into the context to guide the agent to take the next action.
Reflection-as-guidance – The second method we explored is reflection-as-guidance. Specifically, we construct a tool named retrieve_reflections (tool definition in appendix) that agents can use to access broader insights from past experiences. Similar to retrieve_exemplars, the agent can generate a query to retrieve reflections as context, gaining insights to make informed decisions about strategy and approach rather than specific step-by-step actions.
We used the following evaluation methodology:
The baseline agent first processes a set of historical customer interactions, which become the source for memory extraction.
The agent then receives new user queries from τ2-bench.
Each query is attempted four times in parallel.
To evaluate, pass rate metrics are measured across these four attempts. Pass^k measures the percentage of tasks where the agent succeeded in at least k out of four attempts:
Pass^1: Succeeded at least once (measures capability)
Pass^2: Succeeded at least twice (measures reliability)
Pass^3: Succeeded at least three times (measures consistency)
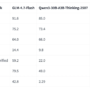
The results in the following table show clear improvements across both domains and multiple attempts.
System
Memory Type used by Agent
Retail
Pass^1
Pass^2
Pass^3
Pass^1
Pass^2
Pass^3
Baseline
No Memory
65.80%
49.70%
42.10%
47%
33.30%
24%
Memory-Augmented Agent
Episodes as ICL Example
69.30%
53.80%
43.40%
55.00%
46.70%
43.00%
Cross Episodes Reflection Memory
77.20%
64.30%
55.70%
58%
46%
41%
Memory-augmented agents consistently outperform the baseline across domains and consistency levels. Crucially, these results demonstrate that different memory retrieval strategies are better suited to different task characteristics. Cross-episode reflection improved Pass^1 by +11.4% and Pass^3 by +13.6% over the baseline, suggesting that generalized strategic insights are particularly valuable when handling open-ended customer service scenarios with diverse interaction patterns. In contrast, the airline domain – characterized by complex, rule-based policies and multi-step procedures—benefits more from episodes as examples, which achieved the highest Pass^3 (43.0% vs 41.0% for reflection). This indicates that concrete step-by-step examples help agents navigate structured workflows reliably. The relative improvement is most pronounced at higher consistency thresholds (Pass^3), where memory helps agents avoid the mistakes that cause intermittent failures.
Best practices for using episodic memory
The key to effective episodic memory is knowing when to use it and which type fits your situation. In this section, we discuss what we’ve learned works best.
When to use episodic memory
Episodic memory delivers the most value when you match the right memory type to your current need. It is ideal for complex, multi-step tasks where context matters and past experience matters significantly, such as debugging code, planning trips, and analyzing data. It’s also particularly valuable for repetitive workflows where learning from previous attempts can dramatically improve outcomes, and for domain-specific problems where accumulated expertise makes a real difference.
However, episodic memory isn’t always the right choice. You can skip it for simple, one-time questions like weather checks or basic facts that don’t need reasoning or context. Simple customer service conversations, basic Q&A, or casual chats don’t need the advanced features that episodic memory adds. The true benefit of episodic memory is observed over time. For short tasks, a session summary provides sufficient information. However, for complex tasks and repetitive workflows, episodic memory helps agents build on past experiences and continuously improve their performance.
Choosing episodes vs. reflection
Episodes work best when you’re facing similar specific problems and need clear guidance. If you’re debugging a React component that won’t render, episodes can show you exactly how similar problems were fixed before, including the specific tools used, thinking process, and results. They give you real examples when general advice isn’t enough, showing the complete path from finding the problem to solving it.
Reflection memories work best when you need strategic guidance across broader contexts rather than specific step-by-step solutions. Use reflections when you’re facing a new type of problem and need to understand general principles, like “What’s the most effective approach for data visualization tasks?” or “Which debugging strategies tend to work best for API integration issues?” Reflections are particularly valuable when you’re making high-level decisions about tool selection and which method to follow, or understanding why certain patterns consistently succeed or fail.
Before starting tasks, check reflections for strategy guidance, look at similar episodes for solution patterns, and find high-confidence mistakes documented in previous attempts. During tasks, look at episodes when you hit roadblocks, use reflection insights for tool choices, and think about how your current situation differs from past examples.
Conclusion
Episodic memory fills a critical gap in current agent capabilities. By storing complete reasoning paths and learning from outcomes, agents can avoid repeating mistakes and build on successful strategies.
Episodic memory completes the memory framework of Amazon Bedrock AgentCore alongside summarization, semantic, and preference memory. Each serves a specific purpose: summarization manages context length, semantic memory stores facts, preference memory handles personalization, and episodic memory captures experience. The combination helps give agents both structured knowledge and practical experience to handle complex tasks more effectively.
To learn more about episodic memory, refer to Episodic memory strategy, How to best retrieve episodes to improve agentic performance, and the AgentCore Memory GitHub samples.
Appendix
In this section, we discuss two methods of using memories for memory-augmented agents.
Episode example
The following is an example using extracted episodes as in-context learning examples:
** Context **
A customer (Jane Doe) contacted customer service expressing frustration
about a recent flight delay that disrupted their travel plans and wanted
to discuss compensation or resolution options for the inconvenience they
experienced.
** Goal **
The user’s primary goal was to obtain compensation or some form of resolution
for a flight delay they experienced, seeking acknowledgment of the disruption
and appropriate remediation from the airline.
—
### Step 1:
**Thought:**
The assistant chose to gather information systematically rather than making
assumptions, as flight delay investigations require specific reservation and
flight details. This approach facilitates accurate assistance and demonstrates
professionalism by acknowledging the customer’s frustration while taking concrete
steps to help resolve the issue.
**Action:**
The assistant responded conversationally without using any tools, asking the
user to provide their user ID to access reservation details.
— End of Step 1 —
…
** Episode Reflection **:
The conversation demonstrates an excellent systematic approach to flight
modifications: starting with reservation verification, then identifying
confirmation, followed by comprehensive flight searches, and finally processing
changes with proper authorization. The assistant effectively used appropriate
tools in a logical sequence – get_reservation_details for verification, get_user_details
for identity/payment info, search_direct_flight for options, and update tools for
processing changes. Key strengths included transparent pricing calculations,
proactive mention of insurance benefits, clear presentation of options, and proper
handling of policy constraints (explaining why mixed cabin classes aren’t allowed).
The assistant successfully leveraged user benefits (Gold status for free bags) and
maintained security protocols throughout. This methodical approach made sure user
needs were addressed while following proper procedures for reservation modifications.
Reflection example
The following is an example of Reflection memory, which can be used for agent guidance:
**Title:** Proactive Alternative Search Despite Policy Restrictions
**Use Cases:**
This applies when customers request flight modifications or changes that
are blocked by airline policies (such as basic economy no-change rules,
fare class restrictions, or booking timing limitations). Rather than simply
declining the request, this pattern involves immediately searching for
alternative solutions to help customers achieve their underlying goals.
It’s particularly valuable for emergency situations, budget-conscious travelers,
or when customers have specific timing needs that their current reservations
don’t accommodate.
**Hints:**
When policy restrictions prevent the requested modification, immediately pivot
to solution-finding rather than just explaining limitations. Use search_direct_flight
to find alternative options that could meet the customer’s needs, even if it requires
separate bookings or different approaches. Present both the policy constraint
explanation AND viable alternatives in the same response to maintain momentum toward
resolution. Consider the customer’s underlying goal (getting home earlier,
changing dates, etc.) and search for flights that accomplish this objective.
When presenting alternatives, organize options clearly by date and price, highlight
budget-friendly choices, and explain the trade-offs between keeping existing reservations
versus canceling and rebooking. This approach transforms policy limitations into problem-solving
opportunities and maintains customer satisfaction even when the original request cannot be fulfilled.
Tool definitions
The following code is the tool definition for retrieve_exemplars:
def retrieve_exemplars(task: str) -> str:
“””
Retrieve example processes to help solve the given task.
Args:
task: The task to solve that requires example processes.
Returns:
str: The example processes to help solve the given task.
“””
The following is the tool definition for retrieve_reflections:
def retrieve_reflections(task: str, k: int = 5) -> str:
“””
Retrieve synthesized reflection knowledge from past agent experiences by matching
against knowledge titles and use cases. Each knowledge entry contains: (1) a descriptive title,
(2) specific use cases describing the types of goals where this knowledge applies and when to apply it,
and (3) actionable hints including best practices from successful episodes and common pitfalls to avoid
from failed episodes. Use this to get strategic guidance for similar tasks.
Args:
task: The current task or goal you are trying to accomplish. This will be matched
against knowledge titles and use cases to find relevant reflection knowledge. Describe your task
clearly to get the most relevant matches.
k: Number of reflection knowledge entries to retrieve. Default is 5.
Returns:
str: The synthesized reflection knowledge from past agent experiences.
“””
About the Authors
Jiarong Jiang is a Principal Applied Scientist at AWS, driving innovations in Retrieval Augmented Generation (RAG) and agent memory systems to improve the accuracy and intelligence of enterprise AI. She’s passionate about helping customers build context-aware, reasoning-driven applications that use their own data effectively.
Akarsha Sehwag is a Generative AI Data Scientist for the Amazon Bedrock AgentCore Memory team. With over 6 years of expertise in AI/ML, she has built production-ready enterprise solutions across diverse customer segments in generative AI, deep learning, and computer vision domains. Outside of work, she likes to hike, bike, and play badminton.
Mani Khanuja is a Principal Generative AI Specialist SA and author of the book Applied Machine Learning and High-Performance Computing on AWS. She leads machine learning projects in various domains such as computer vision, natural language processing, and generative AI. She speaks at internal and external conferences such AWS re:Invent, Women in Manufacturing West, YouTube webinars, and GHC 23. In her free time, she likes to go for long runs along the beach.
Peng Shi is a Senior Applied Scientist at AWS, where he leads advancements in agent memory systems to enhance the accuracy, adaptability, and reasoning capabilities of AI. His work focuses on creating more intelligent and context-aware applications that bridge cutting-edge research with real-world impact.
Anil Gurrala is a Senior Solutions Architect at AWS based in Atlanta. With over 3 years at Amazon and nearly two decades of experience in digital innovation and transformation, he helps customers with modernization initiatives, architecture design, and optimization on AWS. Anil specializes in implementing agentic AI solutions while partnering with enterprises to architect scalable applications and optimize their deployment within the AWS cloud environment. Outside of work, Anil enjoys playing volleyball and badminton, and exploring new destinations around the world.
Ruo Cheng is a Senior UX Designer at AWS, designing enterprise AI and developer experiences across Amazon Bedrock and Amazon Bedrock AgentCore. With a decade of experience, she leads design for AgentCore Memory, shaping memory-related workflows and capabilities for agent-based applications. Ruo is passionate about translating complex AI and infrastructure concepts into intuitive, user-centered experiences.