Embedding models power many modern applications—from semantic search and Retrieval-Augmented Generation (RAG) to recommendation systems and content understanding. However, selecting an embedding model requires careful consideration—after you’ve ingested your data, migrating to a different model means re-embedding your entire corpus, rebuilding vector indexes, and validating search quality from scratch. The right embedding model should deliver strong baseline performance, adapt to your specific use-case, and support the modalities you need now and in the future.
The Amazon Nova Multimodal Embeddings model generates embeddings tailored to your specific use case—from single-modality text or image search to complex multimodal applications spanning documents, videos, and mixed content.
In this post, you will learn how to use Amazon Nova Multimodal Embeddings for your specific use cases:
Simplify your architecture with cross-modal search and visual document retrieval
Optimize performance by selecting embedding parameters matched to your workload
Implement common patterns through solution walkthroughs for media search, ecommerce discovery, and intelligent document retrieval
This guide provides a practical foundation to configure Amazon Nova Multimodal Embeddings for media asset search systems, product discovery experiences, and document retrieval applications.
Multimodal business use cases
You can use Amazon Nova Multimodal Embeddings across multiple business scenarios. The following table provides typical use cases and query examples:
Modality
Content type
Use cases
Typical query examples
Video retrieval
Short video search
Asset library and media management
“Children opening Christmas presents,” “Blue whale breaching the ocean surface”
Long video segment search
Film and entertainment, broadcast media, security surveillance
“Specific scene in a movie,” “Specific footage in news,” “Specific behavior in surveillance”
Duplicate content identification
Media content management
Similar or duplicate video identification
Image retrieval
Thematic image search
Asset library, storage, and media management
“Red car with sunroof driving along the coast”
Image reference search
E-commerce, design
“Shoes similar to this” +<image>
Reverse image search
Content management
Find similar content based on uploaded image
Document retrieval
Specific information pages
Financial services, marketing markups, advertising brochures
Text information, data tables, chart page
Cross-page comprehensive information
Knowledge retrieval enhancement
Comprehensive information extraction from multi-page text, charts, and tables
Text retrieval
Thematic information retrieval
Knowledge retrieval enhancement
“Next steps in reactor decommissioning procedures”
Text similarity analysis
Media content management
Duplicate headline detection
Automatic topic clustering
Finance, healthcare
Symptom classification and summarization
Contextual association retrieval
Finance, legal, insurance
“Maximum claim amount for corporate inspection accident violations”
Audio and voice retrieval
Audio retrieval
Asset library and media asset management
“Christmas music ringtone,” “Natural tranquil sound effects”
Long audio segment search
Podcasts, meeting recordings
“Podcast host discussing neuroscience and sleep’s impact on brain health”
Optimize performance for specific use cases
Amazon Nova Multimodal Embeddings model optimizes its performance for specific use cases with embeddingPurpose parameter settings. It has different vectorization strategies: retrieval system mode and ML task mode.
Retrieval system mode (including GENERIC_INDEX and various *_RETRIEVAL parameters) targets information retrieval scenarios, distinguishing between two asymmetric phases: storage/INDEX and query/RETRIEVAL. See the following table for retrieval system categories and parameter selection.
Phase
Parameter selection
Reason
Storage phase (all types)
GENERIC_INDEX
Optimized for indexing and storage
Query phase (mixed-modal repository)
GENERIC_RETRIEVAL
Search in mixed content
Query phase (text-only repository)
TEXT_RETRIEVAL
Search in text-only content
Query phase (image-only repository)
IMAGE_RETRIEVAL
Search in images (photos, illustrations, and so on)
Query phase (document image-only repository)
DOCUMENT_RETRIEVAL
Search in document images (scans, PDF screenshots, and so on)
Query phase (video-only repository)
VIDEO_RETRIEVAL
Search in videos
Query phase (audio-only repository)
AUDIO_RETRIEVAL/td>
Search in audio
ML task mode (including CLASSIFICATION and CLUSTERING parameters) targets machine learning scenarios. This parameter enables the model to flexibly adapt to different types of downstream task requirements.
CLASSIFICATION: Generated vectors are more suitable for distinguishing classification boundaries, facilitating downstream classifier training or direct classification.
CLUSTERING: Generated vectors are more suitable for forming cluster centers, facilitating downstream clustering algorithms.
Walkthrough of building multimodal search and retrieval solution
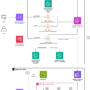
Amazon Nova Multimodal Embeddings is purpose-built for multimodal search and retrieval, which is the foundation of multimodal agentic RAG systems. The following diagrams show how to build a multimodal search and retrieval solution.
In a multimodal search and retrieval solution, shown in the preceding diagram, raw content—including text, images, audio, and video—is initially transformed into vector representations through an embedding model to encapsulate semantic features. Subsequently, these vectors are stored in a vector database. User queries are similarly converted into query vectors within the same vector space. The retrieval of the top K most relevant items is achieved by calculating the similarity between the query vector and the indexed vectors. This multimodal search and retrieval solution can be encapsulated as a Model Context Protocol (MCP) tool, thereby facilitating access within a multimodal agentic RAG solution, shown in the following diagram.
The multimodal search and retrieval solution can be divided into two distinct data flows:
Data ingestion
Runtime search and retrieval
The following lists the common modules within each data flow, along with the associated tools and technologies:
Data flow
Module
Description
Common tools and technologies
Data ingestion
Generate embeddings
Convert inputs (text, images, audio, video, and so on) into vector representations
Embeddings model.
Store embeddings in vector stores
Store generated vectors in a vector database or storage structure for subsequent retrieval
Popular vector databases
Runtime search and retrieval
Similarity Retrieval Algorithm
Calculate similarity and distance between query vectors and indexed vectors, retrieve closest items
Common distances: cosine similarity, inner product, Euclidean distanceDatabase support for k-NN and ANN, such as Amazon OpenSearch k-NN
Top K Retrieval and Voting Mechanism
Select the top K nearest neighbors from retrieval results, then possibly combine multiple strategies (voting, reranking, fusion)
For example, top K nearest neighbors, fusion of keyword retrieval and vector retrieval (hybrid search)
Integration Strategy and Hybrid Retrieval
Combine multiple retrieval mechanisms or modal results, such as keyword and vector or, text and image retrieval fusion
Hybrid search (such as Amazon OpenSearch hybrid)
We will explore several cross-modal business use cases and provide a high-level overview of how to address them using Amazon Nova Multimodal Embeddings.
Use case: Product retrieval and classification
E-commerce applications require the capability to automatically classify product images and identify similar items without the need for manual tagging. The following diagram illustrates a high-level solution:
Convert product images to embeddings using Amazon Nova Multimodal Embeddings
Store embeddings and labels as metadata in a vector database
Query new product images and find the top K similar products
Use a voting mechanism on retrieved results to predict category
Key embeddings parameters:
Parameter
Value
Purpose
embeddingPurpose
GENERIC_INDEX (indexing) and IMAGE_RETRIEVAL (querying)
Optimizes for product image retrieval
embeddingDimension
1024
Balances accuracy and performance
detailLevel
STANDARD_IMAGE
Suitable for product photos
Use case: Intelligent document retrieval
Financial analysts, legal teams, and researchers need to quickly find specific information (tables, charts, clauses) across complex multi-page documents without manual review. The following diagram illustrates a high-level solution:
Convert each PDF page to a high-resolution image
Generate embeddings for all document pages
Store embeddings in a vector database
Accept natural language queries and convert to embeddings
Retrieve the top K most relevant pages based on semantic similarity
Return pages with financial tables, charts, or specific content
Key embeddings parameters:
Parameter
Value
Purpose
embeddingPurpose
GENERIC_INDEX (indexing) and DOCUMENT_RETRIEVAL (querying)
Optimizes for document content understanding
embeddingDimension
3072
Highest precision for complex document structures
detailLevel
DOCUMENT_IMAGE
Preserves tables, charts, and text layout
When dealing with text-based documents that lack visual elements, it’s recommended to extract the text content and apply a chunking strategy and to use GENERIC_INDEX for indexing and TEXT_RETRIEVAL for querying.
Use case: Video clips search
Media applications require efficient methods to locate specific video clips from extensive video libraries using natural language descriptions. By converting videos and text queries into embeddings within a unified semantic space, similarity matching can be used to retrieve relevant video segments. The following diagram illustrates a high-level solution:
Generate embeddings with Amazon Nova Multimodal Embeddings using the invoke_model API for short videos or the start_async_invoke API for long videos with segmentation
Store embeddings in a vector database
Accept natural language queries and convert to embeddings
Retrieve the top K video clips from the vector database for review or further editing
Key embeddings parameters:
Parameter
Value
Purpose
EmbeddingPurpose
GENERIC_INDEX (indexing) and VIDEO_RETRIEVAL (querying)
Optimize for video indexing and retrieval
embeddingDimension
1024
Balance precision and cost
embeddingMode
AUDIO_VIDEO_COMBINED
Fuse visual and audio content.
Use case: Audio fingerprinting
Music applications and copyright management systems need to identify duplicate or similar audio content, and match audio segments to source tracks for copyright detection and content recognition. The following diagram illustrates a high-level solution:
Convert audio files to embeddings using Amazon Nova Multimodal Embeddings
Store embeddings in a vector database with genre and other metadata
Query with audio segments and find the top K similar tracks
Compare similarity scores to identify source matches and detect duplicates
Key embeddings parameters:
Parameter
Value
Purpose
embeddingPurpose
GENERIC_INDEX (indexing) and AUDIO_RETRIEVAL (querying)
Optimizes for audio fingerprinting and matching
embeddingDimension
1024
Balances accuracy and performance for audio similarity
Conclusion
You can use Amazon Nova Multimodal Embeddings to work with diverse data types within a unified semantic space. By supporting text, images, documents, video, and audio through flexible purpose-optimized embedding API parameters, you can build more effective retrieval systems, classification pipelines, and semantic search applications. Whether you’re implementing cross-modal search, document intelligence, or product classification, Amazon Nova Multimodal Embeddings provides the foundation to extract insights from unstructured data at scale. Start exploring the Amazon Nova Multimodal Embeddings: State-of-the-art embedding model for agentic RAG and semantic search and GitHub samples to integrate Amazon Nova Multimodal Embeddings into your applications today.
About the authors
Yunyi Gao is a Generative AI Specialiat Solutions Architect at Amazon Web Services (AWS), responsible for consulting on the design of AWS AI/ML and GenAI solutions and architectures.
Sharon Li is an AI/ML Specialist Solutions Architect at Amazon Web Services (AWS) based in Boston, Massachusetts. With a passion for leveraging cutting-edge technology, Sharon is at the forefront of developing and deploying innovative generative AI solutions on the AWS cloud platform.