Building an AI agent that can handle a real-life use case in production is a complex undertaking. Although creating a proof of concept demonstrates the potential, moving to production requires addressing scalability, security, observability, and operational concerns that don’t surface in development environments.
This post explores how Amazon Bedrock AgentCore helps you transition your agentic applications from experimental proof of concept to production-ready systems. We follow the journey of a customer support agent that evolves from a simple local prototype to a comprehensive, enterprise-grade solution capable of handling multiple concurrent users while maintaining security and performance standards.
Amazon Bedrock AgentCore is a comprehensive suite of services designed to help you build, deploy, and scale agentic AI applications. If you’re new to AgentCore, we recommend exploring our existing deep-dive posts on individual services: AgentCore Runtime for secure agent deployment and scaling, AgentCore Gateway for enterprise tool development, AgentCore Identity for securing agentic AI at scale, AgentCore Memory for building context-aware agents, AgentCore Code Interpreter for code execution, AgentCore Browser Tool for web interaction, and AgentCore Observability for transparency on your agent behavior. This post demonstrates how these services work together in a real-world scenario.
The customer support agent journey
Customer support represents one of the most common and compelling use cases for agentic AI. Modern businesses handle thousands of customer inquiries daily, ranging from simple policy questions to complex technical troubleshooting. Traditional approaches often fall short: rule-based chatbots frustrate customers with rigid responses, and human-only support teams struggle with scalability and consistency. An intelligent customer support agent needs to seamlessly handle diverse scenarios: managing customer orders and accounts, looking up return policies, searching product catalogs, troubleshooting technical issues through web research, and remembering customer preferences across multiple interactions. Most importantly, it must do all this while maintaining the security and reliability standards expected in enterprise environments. Consider the typical evolution path many organizations follow when building such agents:
The proof of concept stage – Teams start with a simple local prototype that demonstrates core capabilities, such as a basic agent that can answer policy questions and search for products. This works well for demos but lacks the robustness needed for real customer interactions.
The reality check – As soon as you try to scale beyond a few test users, challenges emerge. The agent forgets previous conversations, tools become unreliable under load, there’s no way to monitor performance, and security becomes a paramount concern.
The production challenge – Moving to production requires addressing session management, secure tool sharing, observability, authentication, and building interfaces that customers actually want to use. Many promising proofs of concept stall at this stage due to the complexity of these requirements.
In this post, we address each challenge systematically. We start with a prototype agent equipped with three essential tools: return policy lookup, product information search, and web search for troubleshooting. From there, we add the capabilities needed for production deployment: persistent memory for conversation continuity and a hyper-personalized experience, centralized tool management for reliability and security, full observability for monitoring and debugging, and finally a customer-facing web interface. This progression mirrors the real-world path from proof of concept to production, demonstrating how Amazon Bedrock AgentCore services work together to solve the operational challenges that emerge as your agentic applications mature. For simplification and demonstration purposes, we consider a single-agent architecture. In real-life use cases, customer support agents are often created as multi-agent architectures and those scenarios are also supported by Amazon Bedrock AgentCore services.
Solution overview
Every production system starts with a proof of concept, and our customer support agent is no exception. In this first phase, we build a functional prototype that demonstrates the core capabilities needed for customer support. In this case, we use Strands Agents, an open source agent framework, to build the proof of concept and Anthropic’s Claude 3.7 Sonnet on Amazon Bedrock as the large language model (LLM) powering our agent. For your application, you can use another agent framework and model of your choice.
Agents rely on tools to take actions and interact with live systems. Several tools are used in customer support agents, but to keep our example simple, we focus on three core capabilities to handle the most common customer inquiries:
Return policy lookup – Customers frequently ask about return windows, conditions, and processes. Our tool provides structured policy information based on product categories, covering everything from return timeframes to refund processing and shipping policies.
Product information retrieval – Technical specifications, warranty details, and compatibility information are essential for both pre-purchase questions and troubleshooting. This tool serves as a bridge to your product catalog, delivering formatted technical details that customers can understand.
Web search for troubleshooting – Complex technical issues often require the latest solutions or community-generated fixes not found in internal documentation. Web search capability allows the agent to access the web for current troubleshooting guides and technical solutions in real time.
The tools implementation and the end-to-end code for this use case are available in our GitHub repository. In this post, we focus on the main code that connects with Amazon Bedrock AgentCore, but you can follow the end-to-end journey in the repository.
Create the agent
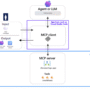
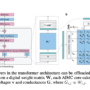
With the tools available, let’s create the agent. The architecture for our proof of concept will look like the following diagram.
You can find the end-to-end code for this post on the GitHub repository. For simplicity, we show only the essential parts for our end-to-end code here:
from strands import Agent
from strands.models import BedrockModel
@tool
def get_return_policy(product_category: str) -> str:
“””Get return policy information for a specific product category.”””
# Returns structured policy info: windows, conditions, processes, refunds
# check github for full code
return {“return_window”: “10 days”, “conditions”: “”}
@tool
def get_product_info(product_type: str) -> str:
“””Get detailed technical specifications and information for electronics products.”””
# Returns warranty, specs, features, compatibility details
# check github for full code
return {“product”: “ThinkPad X1 Carbon”, “info”: “ThinkPad X1 Carbon info”}
@tool
def web_search(keywords: str, region: str = “us-en”, max_results: int = 5) -> str:
“””Search the web for updated troubleshooting information.”””
# Provides access to current technical solutions and guides
# check github for full code
return “results from websearch”
# Initialize the Bedrock model
model = BedrockModel(
model_id=”us.anthropic.claude-3-7-sonnet-20250219-v1:0″,
temperature=0.3
)
# Create the customer support agent
agent = Agent(
model=model,
tools=[
get_product_info,
get_return_policy,
web_search
],
system_prompt=”””You are a helpful customer support assistant for an electronics company.
Use the appropriate tools to provide accurate information and always offer additional help.”””
)
Test the proof of concept
When we test our prototype with realistic customer queries, the agent demonstrates the correct tool selection and interaction with real-world systems:
# Return policy inquiry
response = agent(“What’s the return policy for my ThinkPad X1 Carbon?”)
# Agent correctly uses get_return_policy with “laptops” category
# Technical troubleshooting
response = agent(“My iPhone 14 heats up, how do I fix it?”)
# Agent uses web_search to find current troubleshooting solutions
The agent works well for these individual queries, correctly mapping laptop inquiries to return policy lookups and complex technical issues to web search, providing comprehensive and actionable responses.
The proof of concept reality check
Our proof of concept successfully demonstrates that an agent can handle diverse customer support scenarios using the right combination of tools and reasoning. The agent runs perfectly on your local machine and handles queries correctly. However, this is where the proof of concept gap becomes obvious. The tools are defined as local functions in your agent code, the agent responds quickly, and everything seems production-ready. But several critical limitations become apparent the moment you think beyond single-user testing:
Memory loss between sessions – If you restart your notebook or application, the agent completely forgets previous conversations. A customer who was discussing a laptop return yesterday would need to start from scratch today, re-explaining their entire situation. This isn’t just inconvenient—it’s a poor customer experience that breaks the conversational flow that makes AI agents valuable.
Single customer limitation – Your current agent can only handle one conversation at a time. If two customers try to use your support system simultaneously, their conversations would interfere with each other, or worse, one customer might see another’s conversation history. There’s no mechanism to maintain separate conversation context for different users.
Tools embedded in code – Your tools are defined directly in the agent code. This means:
You can’t reuse these tools across different agents (sales agent, technical support agent, and so on).
Updating a tool requires changing the agent code and redeploying everything.
Different teams can’t maintain different tools independently.
No production infrastructure – The agent runs locally with no consideration for scalability, security, monitoring, and reliability.
These fundamental architectural barriers can prevent real customer deployment. Agent building teams can take months to address these issues, which delays the time to value from their work and adds significant costs to the application. This is where Amazon Bedrock AgentCore services become essential. Rather than spending months building these production capabilities from scratch, Amazon Bedrock AgentCore provides managed services that address each gap systematically.
Let’s begin our journey to production by solving the memory problem first, transforming our agent from one that forgets every conversation into one that remembers customers across conversations and can hyper-personalize conversations using Amazon Bedrock AgentCore Memory.
Add persistent memory for hyper-personalized agents
The first major limitation we identified in our proof of concept was memory loss—our agent forgot everything between sessions, forcing customers to repeat their context every time. This “goldfish agent” behavior breaks the conversational experience that makes AI agents valuable in the first place.
Amazon Bedrock AgentCore Memory solves this by providing managed, persistent memory that operates on two complementary levels:
Short-term memory – Immediate conversation context and session-based information for continuity within interactions
Long-term memory – Persistent information extracted across multiple conversations, including customer preferences, facts, and behavioral patterns
After adding Amazon Bedrock AgentCore Memory to our customer support agent, our new architecture will look like the following diagram.
Install dependencies
Before we start, let’s install our dependencies: boto3, the AgentCore SDK, and the AgentCore Starter Toolkit SDK. Those will help us quickly add Amazon Bedrock AgentCore capabilities to our agent proof of concept. See the following code:
pip install boto3 bedrock-agentcore bedrock-agentcore-starter-toolkit
Create the memory resources
Amazon Bedrock AgentCore Memory uses configurable strategies to determine what information to extract and store. For our customer support use case, we use two complementary strategies:
USER_PREFERENCE – Automatically extracts and stores customer preferences like “prefers ThinkPad laptops,” “uses Linux,” or “plays competitive FPS games.” This enables personalized recommendations across conversations.
SEMANTIC – Captures factual information using vector embeddings, such as “customer has MacBook Pro order #MB-78432” or “reported overheating issues during video editing.” This provides relevant context for troubleshooting.
See the following code:
from bedrock_agentcore.memory import MemoryClient
from bedrock_agentcore.memory.constants import StrategyType
memory_client = MemoryClient(region_name=region)
strategies = [
{
StrategyType.USER_PREFERENCE.value: {
“name”: “CustomerPreferences”,
“description”: “Captures customer preferences and behavior”,
“namespaces”: [“support/customer/{actorId}/preferences”],
}
},
{
StrategyType.SEMANTIC.value: {
“name”: “CustomerSupportSemantic”,
“description”: “Stores facts from conversations”,
“namespaces”: [“support/customer/{actorId}/semantic”],
}
},
]
# Create memory resource with both strategies
response = memory_client.create_memory_and_wait(
name=”CustomerSupportMemory”,
description=”Customer support agent memory”,
strategies=strategies,
event_expiry_days=90,
)
Integrate with Strands Agents hooks
The key to making memory work seamlessly is automation—customers shouldn’t need to think about it, and agents shouldn’t require manual memory management. Strands Agents provides a powerful hook system that lets you intercept agent lifecycle events and handle memory operations automatically. The hook system enables both built-in components and user code to react to or modify agent behavior through strongly-typed event callbacks. For our use case, we create CustomerSupportMemoryHooks to retrieve the customer context and save the support interactions:
MessageAddedEvent hook – Triggered when customers send messages, this hook automatically retrieves relevant memory context and injects it into the query. The agent receives both the customer’s question and relevant historical context without manual intervention.
AfterInvocationEvent hook – Triggered after agent responses, this hook automatically saves the interaction to memory. The conversation becomes part of the customer’s persistent history immediately.
See the following code:
class CustomerSupportMemoryHooks(HookProvider):
def retrieve_customer_context(self, event: MessageAddedEvent):
“””Inject customer context before processing queries”””
user_query = event.agent.messages[-1][“content”][0][“text”]
# Retrieve relevant memories from both strategies
all_context = []
for context_type, namespace in self.namespaces.items():
memories = self.client.retrieve_memories(
memory_id=self.memory_id,
namespace=namespace.format(actorId=self.actor_id),
query=user_query,
top_k=3,
)
# Format and add to context
for memory in memories:
if memory.get(“content”, {}).get(“text”):
all_context.append(f”[{context_type.upper()}] {memory[‘content’][‘text’]}”)
# Inject context into the user query
if all_context:
context_text = “n”.join(all_context)
original_text = event.agent.messages[-1][“content”][0][“text”]
event.agent.messages[-1][“content”][0][“text”] = f”Customer Context:n{context_text}nn{original_text}”
def save_support_interaction(self, event: AfterInvocationEvent):
“””Save interactions after agent responses”””
# Get last customer query and agent response check github for implementation
customer_query = “This is a sample query”
agent_response = “LLM gave a sample response”
# Extract customer query and agent response
# Save to memory for future retrieval
self.client.create_event(
memory_id=self.memory_id,
actor_id=self.actor_id,
session_id=self.session_id,
messages=[(customer_query, “USER”), (agent_response, “ASSISTANT”)]
)
In this code, we can see that our hooks are the ones interacting with Amazon Bedrock AgentCore Memory to save and retrieve memory events.
Integrate memory with the agent
Adding memory to our existing agent requires minimal code changes; you can simply instantiate the memory hooks and pass them to the agent constructor. The agent code then only needs to connect with the memory hooks to use the full power of Amazon Bedrock AgentCore Memory. We will create a new hook for each session, which will help us handle different customer interactions. See the following code:
# Create memory hooks for this customer session
memory_hooks = CustomerSupportMemoryHooks(
memory_id=memory_id,
client=memory_client,
actor_id=customer_id,
session_id=session_id
)
# Create agent with memory capabilities
agent = Agent(
model=model,
tools=[get_product_info, get_return_policy, web_search],
system_prompt=SYSTEM_PROMPT
)
Test the memory in action
Let’s see how memory transforms the customer experience. When we invoke the agent, it uses the memory from previous interactions to show customer interests in gaming headphones, ThinkPad laptops, and MacBook thermal issues:
# Test personalized recommendations
response = agent(“Which headphones would you recommend?”)
# Agent remembers: “prefers low latency for competitive FPS games”
# Response includes gaming-focused recommendations
# Test preference recall
response = agent(“What is my preferred laptop brand?”)
# Agent remembers: “prefers ThinkPad models” and “needs Linux compatibility”
# Response acknowledges ThinkPad preference and suggests compatible models
The transformation is immediately apparent. Instead of generic responses, the agent now provides personalized recommendations based on the customer’s stated preferences and past interactions. The customer doesn’t need to re-explain their gaming needs or Linux requirements—the agent already knows.
Benefits of Amazon Bedrock AgentCore Memory
With Amazon Bedrock AgentCore Memory integrated, our agent now delivers the following benefits:
Conversation continuity – Customers can pick up where they left off, even across different sessions or support channels
Personalized service – Recommendations and responses are tailored to individual preferences and past issues
Contextual troubleshooting – Access to previous problems and solutions enables more effective support
Seamless experience – Memory operations happen automatically without customer or agent intervention
However, we still have limitations to address. Our tools remain embedded in the agent code, preventing reuse across different support agents or teams. Security and access controls are minimal, and we still can’t handle multiple customers simultaneously in a production environment.
In the next section, we address these challenges by centralizing our tools using Amazon Bedrock AgentCore Gateway and implementing proper identity management with Amazon Bedrock AgentCore Identity, creating a scalable and secure foundation for our customer support system.
Centralize tools with Amazon Bedrock AgentCore Gateway and Amazon Bedrock AgentCore Identity
With memory solved, our next challenge is tool architecture. Currently, our tools are embedded directly in the agent code—a pattern that works for prototypes but creates significant problems at scale. When you need multiple agents (customer support, sales, technical support), each one duplicates the same tools, leading to extensive code, inconsistent behavior, and maintenance nightmares.
Amazon Bedrock AgentCore Gateway simplifies this process by centralizing tools into reusable, secure endpoints that agents can access. Combined with Amazon Bedrock AgentCore Identity for authentication, it creates an enterprise-grade tool sharing infrastructure.
We will now update our agent to use Amazon Bedrock AgentCore Gateway and Amazon Bedrock AgentCore Identity. The architecture will look like the following diagram.
In this case, we convert our web search tool to be used in the gateway and keep the return policy and get product information tools local to this agent. That is important because web search is a common capability that can be reused across different use cases in an organization, and return policy and production information are capabilities commonly associated with customer support services. With Amazon Bedrock AgentCore services, you can decide which capabilities to use and how to combine them. In this case, we also use two new tools that could have been developed by other teams: check warranty and get customer profile. Because those teams have already exposed those tools using AWS Lambda functions, we can use them as targets to our Amazon Bedrock AgentCore Gateway. Amazon Bedrock AgentCore Gateway can also support REST APIs as target. That means that if we have an OpenAPI specification or a Smithy model, we can also quickly expose our tools using Amazon Bedrock AgentCore Gateway.
Convert existing services to MCP
Amazon Bedrock AgentCore Gateway uses the Model Context Protocol (MCP) to standardize how agents access tools. Converting existing Lambda functions into MCP endpoints requires minimal changes—mainly adding tool schemas and handling the MCP context. To use this functionality, we convert our local tools to Lambda functions and create the tools schema definitions to make these functions discoverable by agents:
# Original Lambda function (simplified)
def web_search(keywords: str, region: str = “us-en”, max_results: int = 5) -> str:
# web_search functionality
def lambda_handler(event, context):
if get_tool_name(event) == “web_search”:
query = get_named_parameter(event=event, name=”query”)
search_result = web_search(keywords)
return {“statusCode”: 200, “body”: search_result}
The following code is the tool schema definition:
{
“name”: “web_search”,
“description”: “Search the web for updated information using DuckDuckGo”,
“inputSchema”: {
“type”: “object”,
“properties”: {
“keywords”: {
“type”: “string”,
“description”: “The search query keywords”
},
“region”: {
“type”: “string”,
“description”: “The search region (e.g., us-en, uk-en, ru-ru)”
},
“max_results”: {
“type”: “integer”,
“description”: “The maximum number of results to return”
}
},
“required”: [
“keywords”
]
}
}
For demonstration purposes, we build a new Lambda function from scratch. In reality, organizations already have different functionalities available as REST services or Lambda functions, and this approach lets you expose existing enterprise services as agent tools without rebuilding them.
Configure security with Amazon Bedrock AgentCore Gateway and integrate with Amazon Bedrock AgentCore Identity
Amazon Bedrock AgentCore Gateway requires authentication for both inbound and outbound connections. Amazon Bedrock AgentCore Identity handles this through standard OAuth flows. After you set up an OAuth authorization configuration, you can create a new gateway and pass this configuration to it. See the following code:
# Create gateway with JWT-based authentication
auth_config = {
“customJWTAuthorizer”: {
“allowedClients”: [cognito_client_id],
“discoveryUrl”: cognito_discovery_url
}
}
gateway_response = gateway_client.create_gateway(
name=”customersupport-gw”,
roleArn=gateway_iam_role,
protocolType=”MCP”,
authorizerType=”CUSTOM_JWT”,
authorizerConfiguration=auth_config,
description=”Customer Support AgentCore Gateway”
)
For inbound authentication, agents must present valid JSON Web Token (JWT) tokens (from identity providers like Amazon Cognito, Okta, and EntraID) as a compact, self-contained standard for securely transmitting information between parties to access Amazon Bedrock AgentCore Gateway tools.
For outbound authentication, Amazon Bedrock AgentCore Gateway can authenticate to downstream services using AWS Identity and Access Management (IAM) roles, API keys, or OAuth tokens.
For demonstration purposes, we have created an Amazon Cognito user pool with a dummy user name and password. For your use case, you should set a proper identity provider and manage the users accordingly. This configure makes sure only authorized agents can access specific tools and a full audit trail is provided.
Add Lambda targets
After you set up Amazon Bedrock AgentCore Gateway, adding Lambda functions as tool targets is straightforward:
lambda_target_config = {
“mcp”: {
“lambda”: {
“lambdaArn”: lambda_function_arn,
“toolSchema”: {“inlinePayload”: api_spec},
}
}
}
gateway_client.create_gateway_target(
gatewayIdentifier=gateway_id,
name=”LambdaTools”,
targetConfiguration=lambda_target_config,
credentialProviderConfigurations=[{
“credentialProviderType”: “GATEWAY_IAM_ROLE”
}]
)
The gateway now exposes your Lambda functions as MCP tools that authorized agents can discover and use.
Integrate MCP tools with Strands Agents
Converting our agent to use centralized tools requires updating the tool configuration. We keep some tools local, such as product info and return policies specific to customer support that will likely not be reused in other use cases, and use centralized tools for shared capabilities. Because Strands Agents has a native integration for MCP tools, we can simply use the MCPClient from Strands with a streamablehttp_client. See the following code:
# Get OAuth token for gateway access
gateway_access_token = get_token(
client_id=cognito_client_id,
client_secret=cognito_client_secret,
scope=auth_scope,
url=token_url
)
# Create authenticated MCP client
mcp_client = MCPClient(
lambda: streamablehttp_client(
gateway_url,
headers={“Authorization”: f”Bearer {gateway_access_token[‘access_token’]}”}
)
)
# Combine local and MCP tools
tools = [
get_product_info, # Local tool (customer support specific)
get_return_policy, # Local tool (customer support specific)
] + mcp_client.list_tools_sync() # Centralized tools from gateway
agent = Agent(
model=model,
tools=tools,
hooks=[memory_hooks],
system_prompt=SYSTEM_PROMPT
)
Test the enhanced agent
With the centralized tools integrated, our agent now has access to enterprise capabilities like warranty checking:
# Test web search using centralized tool
response = agent(“How can I fix Lenovo ThinkPad with a blue screen?”)
# Agent uses web_search from AgentCore Gateway
The agent seamlessly combines local tools with centralized ones, providing comprehensive support capabilities while maintaining security and access control.
However, we still have a significant limitation: our entire agent runs locally on our development machine. For production deployment, we need scalable infrastructure, comprehensive observability, and the ability to handle multiple concurrent users.
In the next section, we address this by deploying our agent to Amazon Bedrock AgentCore Runtime, transforming our local prototype into a production-ready system with Amazon Bedrock AgentCore Observability and automatic scaling capabilities.
Deploy to production with Amazon Bedrock AgentCore Runtime
With the tools centralized and secured, our final major hurdle is production deployment. Our agent currently runs locally on your laptop, which is ideal for experimentation but unsuitable for real customers. Production requires scalable infrastructure, comprehensive monitoring, automatic error recovery, and the ability to handle multiple concurrent users reliably.
Amazon Bedrock AgentCore Runtime transforms your local agent into a production-ready service with minimal code changes. Combined with Amazon Bedrock AgentCore Observability, it provides enterprise-grade reliability, automatic scaling, and comprehensive monitoring capabilities that operations teams need to maintain agentic applications in production.
Our architecture will look like the following diagram.
Minimal code changes for production
Converting your local agent requires adding just four lines of code:
# Your existing agent code remains unchanged
model = BedrockModel(model_id=”us.anthropic.claude-3-7-sonnet-20250219-v1:0″)
memory_hooks = CustomerSupportMemoryHooks(memory_id, memory_client, actor_id, session_id)
agent = Agent(
model=model,
tools=[get_return_policy, get_product_info],
system_prompt=SYSTEM_PROMPT,
hooks=[memory_hooks]
)
def invoke(payload):
user_input = payload.get(“prompt”, “”)
response = agent(user_input)
return response.message[“content”][0][“text”]
if __name__ == “__main__”:
BedrockAgentCoreApp automatically creates an HTTP server with the required /invocations and /ping endpoints, handles proper content types and response formats, manages error handling according to AWS standards, and provides the infrastructure bridge between your agent code and Amazon Bedrock AgentCore Runtime.
Secure production deployment
Production deployment requires proper authentication and access control. Amazon Bedrock AgentCore Runtime integrates with Amazon Bedrock AgentCore Identity to provide enterprise-grade security. Using the Bedrock AgentCore Starter Toolkit, we can deploy our application using three simple steps: configure, launch, and invoke.
During the configuration, a Docker file is created to guide the deployment of our agent. It contains information about the agent and its dependencies, the Amazon Bedrock AgentCore Identity configuration, and the Amazon Bedrock AgentCore Observability configuration to be used. During the launch step, AWS CodeBuild is used to run this Dockerfile and an Amazon Elastic Container Registry (Amazon ECR) repository is created to store the agent dependencies. The Amazon Bedrock AgentCore Runtime agent is then created, using the image of the ECR repository, and an endpoint is generated and used to invoke the agent in applications. If your agent is configured with OAuth authentication through Amazon Bedrock AgentCore Identity, like ours will be, you also need to pass the authentication token during the agent invocation step. The following diagram illustrates this process.
The code to configure and launch our agent on Amazon Bedrock AgentCore Runtime will look as follows:
from bedrock_agentcore_starter_toolkit import Runtime
# Configure secure deployment with Cognito authentication
agentcore_runtime = Runtime()
response = agentcore_runtime.configure(
entrypoint=”lab_helpers/lab4_runtime.py”,
execution_role=execution_role_arn,
auto_create_ecr=True,
requirements_file=”requirements.txt”,
region=region,
agent_name=”customer_support_agent”,
authorizer_configuration={
“customJWTAuthorizer”: {
“allowedClients”: [cognito_client_id],
“discoveryUrl”: cognito_discovery_url,
}
}
)
# Deploy to production
launch_result = agentcore_runtime.launch()
This configuration creates a secure endpoint that only accepts requests with valid JWT tokens from your identity provider (such as Amazon Cognito, Okta, or Entra). For our agent, we use a dummy setup with Amazon Cognito, but your application can use an identity provider of your choosing. The deployment process automatically builds your agent into a container, creates the necessary AWS infrastructure, and establishes monitoring and logging pipelines.
Session management and isolation
One of the most critical production features for agents is proper session management. Amazon Bedrock AgentCore Runtime automatically handles session isolation, making sure different customers’ conversations don’t interfere with each other:
# Customer 1 conversation
response1 = agentcore_runtime.invoke(
{“prompt”: “My iPhone Bluetooth isn’t working. What should I do?”},
bearer_token=auth_token,
session_id=”session-customer-1″
)
# Customer 1 follow-up (maintains context)
response2 = agentcore_runtime.invoke(
{“prompt”: “I’ve turned Bluetooth on and off but it still doesn’t work”},
bearer_token=auth_token,
session_id=”session-customer-1″ # Same session, context preserved
)
# Customer 2 conversation (completely separate)
response3 = agentcore_runtime.invoke(
{“prompt”: “Still not working. What is going on?”},
bearer_token=auth_token,
session_id=”session-customer-2″ # Different session, no context
)
Customer 1’s follow-up maintains full context about their iPhone Bluetooth issue, whereas Customer 2’s message (in a different session) has no context and the agent appropriately asks for more information. This automatic session isolation is crucial for production customer support scenarios.
Comprehensive observability with Amazon Bedrock AgentCore Observability
Production agents need comprehensive monitoring to diagnose issues, optimize performance, and maintain reliability. Amazon Bedrock AgentCore Observability automatically instruments your agent code and sends telemetry data to Amazon CloudWatch, where you can analyze patterns and troubleshoot issues in real time. The observability data includes session-level tracking, so you can trace individual customer session interactions and understand exactly what happened during a support interaction. You can use Amazon Bedrock AgentCore Observability with an agent of your choice, hosted in Amazon Bedrock AgentCore Runtime or not. Because Amazon Bedrock AgentCore Runtime automatically integrates with Amazon Bedrock AgentCore Observability, we don’t need extra work to observe our agent.
With Amazon Bedrock AgentCore Runtime deployment, your agent is ready to be used in production. However, we still have one limitation: our agent is accessible only through SDK or API calls, requiring customers to write code or use technical tools to interact with it. For true customer-facing deployment, we need a user-friendly web interface that customers can access through their browsers.
In the following section, we demonstrate the complete journey by building a sample web application using Streamlit, providing an intuitive chat interface that can interact with our production-ready Amazon Bedrock AgentCore Runtime endpoint. The exposed endpoint maintains the security, scalability, and observability capabilities we’ve built throughout our journey from proof of concept to production. In a real-world scenario, you would integrate this endpoint with your existing customer-facing applications and UI frameworks.
Create a customer-facing UI
With our agent deployed to production, the final step is creating a customer-facing UI that customers can use to interface with the agent. Although SDK access works for developers, customers need an intuitive web interface for seamless support interactions.
To demonstrate a complete solution, we build a sample Streamlit-based web-application that connects to our production-ready Amazon Bedrock AgentCore Runtime endpoint. The frontend includes secure Amazon Cognito authentication, real-time streaming responses, persistent session management, and a clean chat interface. Although we use Streamlit for rapid-prototyping, enterprises would typically integrate the endpoint with their existing interface or preferred UI frameworks.
The end-to-end application (shown in the following diagram) maintains full conversation context across the sessions while providing the security, scalability, and observability capabilities that we built throughout this post. The result is a complete customer support agentic system that handles everything from initial authentication to complex multi-turn troubleshooting conversations, demonstrating how Amazon Bedrock AgentCore services transform prototypes into production-ready customer applications.
Conclusion
Our journey from prototype to production demonstrates how Amazon Bedrock AgentCore services address the traditional barriers to deploying enterprise-ready agentic applications. What started as a simple local customer support chatbot transformed into a comprehensive, production-grade system capable of serving multiple concurrent users with persistent memory, secure tool sharing, comprehensive observability, and an intuitive web interface—without months of custom infrastructure development.
The transformation required minimal code changes at each step, showcasing how Amazon Bedrock AgentCore services work together to solve the operational challenges that typically stall promising proofs of concept. Memory capabilities avoid the “goldfish agent” problem, centralized tool management through Amazon Bedrock AgentCore Gateway creates a reusable infrastructure that securely serves multiple use cases, Amazon Bedrock AgentCore Runtime provides enterprise-grade deployment with automatic scaling, and Amazon Bedrock AgentCore Observability delivers the monitoring capabilities operations teams need to maintain production systems.
The following video provides an overview of AgentCore capabilities.
Ready to build your own production-ready agent? Start with our complete end-to-end tutorial, where you can follow along with the exact code and configurations we’ve explored in this post. For additional use cases and implementation patterns, explore the broader GitHub repository, and dive deeper into service capabilities and best practices in the Amazon Bedrock AgentCore documentation.
About the authors
Maira Ladeira Tanke is a Tech Lead for Agentic AI at AWS, where she enables customers on their journey to develop autonomous AI systems. With over 10 years of experience in AI/ML, Maira partners with enterprise customers to accelerate the adoption of agentic applications using Amazon Bedrock AgentCore and Strands Agents, helping organizations harness the power of foundation models to drive innovation and business transformation. In her free time, Maira enjoys traveling, playing with her cat, and spending time with her family someplace warm.