Agentic AI applications represent a significant development in enterprise automation, where intelligent agents autonomously execute complex workflows, access sensitive datasets, and make real-time decisions across your organization’s infrastructure. Amazon Bedrock AgentCore accelerates enterprise AI transformation by providing fully managed services that remove infrastructure complexity, maintain session isolation, and enable seamless integration with enterprise tools so organizations can deploy trustworthy AI agents at scale. AgentCore Gateway, a modular service under AgentCore, simplifies integration by securely transforming APIs, AWS Lambda functions, and services into Model Context Protocol (MCP)-compatible tools and making them available to agents through a unified endpoint, with built-in authentication and serverless infrastructure that minimizes operational overhead.
In production environments, AI agents are typically deployed within virtual private clouds (VPCs) to maintain secure, isolated network access and to meet enterprise security and compliance requirements. Amazon Web Services (AWS) interface VPC endpoints can enhance agentic AI security by creating private connections between VPC-hosted agents and AgentCore Gateway, keeping sensitive communications within the secure infrastructure of AWS. These endpoints use dedicated network interfaces with private IP addresses to deliver reduced latency and superior performance through direct connectivity. Additionally, VPC interface endpoints offer granular access control through endpoint policies, streamline operations by avoiding proxy server management, reduce data transfer costs, and establish the secure foundation that autonomous AI systems require when processing confidential data in regulated environments at enterprise scale.
In this post, we demonstrate how to access AgentCore Gateway through a VPC interface endpoint from an Amazon Elastic Compute Cloud (Amazon EC2) instance in a VPC. We also show how to configure your VPC endpoint policy to provide secure access to the AgentCore Gateway while maintaining the principle of least privilege access.
Architecture overview
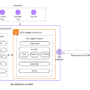
This architecture diagram illustrates a user accessing an application supported by backend agents deployed across various AWS compute services, including EC2 instances, Lambda functions, Amazon Elastic Kubernetes Service (Amazon EKS), or Amazon Elastic Container Service (Amazon ECS), all operating within a VPC environment. These agents communicate with AgentCore Gateway to discover, access, and invoke external tools and services that have been transformed into agent-compatible resources, such as enterprise APIs and Lambda functions. In the standard configuration, agent requests to AgentCore Gateway traverse the public internet. By implementing interface VPC endpoints, organizations can route these communications through the AWS secure internal network backbone instead, delivering significant benefits that can include enhanced security, reduced latency, and improved compliance alignment for regulated workloads that require strict network isolation and data protection standards. The solution follows this workflow:
AI agent interaction – An agent running within the VPC obtains the required inbound authorization from identity providers, authenticates with Gateway, and sends a tool-use request (invokes the MCP tool) to the gateway through the interface VPC endpoint.
Gateway processing: Gateway manages OAuth authorization to make sure only valid users and agents can access tools and resources. The inbound request is authorized by Gateway. Converts agent requests using protocols like Model Context Protocol (MCP) into API requests and Lambda invocations
Secure access: The gateway handles credential injection for each tool, enabling agents to use tools with different authentication requirements seamlessly. It uses AgentCore Identity to securely access backend resources (the targets) on behalf of the agent.
Target execution: The gateway data plane invokes the target, which can be a Lambda function, an OpenAPI specification, or a Smithy model.
Monitoring: AgentCore Gateway provides built-in observability and auditing. Additionally, AWS PrivateLink publishes metrics to Amazon CloudWatch for monitoring interface endpoints. You can optionally enable VPC Flow Logs for logging IP traffic to AgentCore Gateway.
Be aware of the following key considerations:
Private and public network communication – The interface VPC endpoint enables secure communication for inbound traffic from agents to AgentCore Gateway through AWS PrivateLink, making sure this traffic remains within the private network. However, authentication workflows—including OAuth access token retrieval and credential exchange processes between agents and external Identity Provider systems for both inbound and outbound flows—and outbound access from the gateway to MCP tools continue to require internet connectivity for establishing secure sessions with identity systems and external resources hosted outside the AWS environment.
Data plane scope – It’s important to understand that, currently, the interface VPC endpoint support is applicable only to the data plane endpoints of your gateway—the runtime endpoints where your applications interact with agent tools. To clarify the distinction: although you can now access your gateway’s runtime endpoint through the interface VPC endpoint, the control plane operations, such as creating gateways, managing tools, and configuring security settings, must still be performed through the standard public AgentCore control plane endpoint (for example, bedrock-agentcore-control.<region>.amazonaws.com)
Prerequisites
To perform the solution, you need the following prerequisites:
An AWS account with appropriate AWS Identity and Access Management (IAM) permissions for VPC and Amazon Elastic Compute Cloud (Amazon EC2) management
Existing VPC setup with subnet configuration and route tables
AgentCore Gateway already provisioned and configured in your AWS account
Basic understanding of VPC networking concepts and security group configurations
Solution walkthrough
In the following sections, we demonstrate how to configure the interface VPC endpoint using the AWS Management Console and establish secure connectivity from a test EC2 instance within the VPC to AgentCore Gateway.
Create a security group for the EC2 instance
To create a security group for the EC2 instance, follow these steps, as shown in the following screenshot:
Navigate to the Amazon EC2 console in your preferred AWS Region and choose Security Groups in the navigation pane under Network & Security.
Choose Create security group.
For Security group name, enter a descriptive name such as ec2-agent-sg.
For Description, enter a meaningful description such as Security group for EC2 instances running AI agents.
For VPC, choose your target VPC.
Add relevant Inbound rules for the EC2 instance management such as SSH (port 22) from your management network or bastion host.
Leave Outbound rules as default (allows all outbound traffic) to make sure agents can communicate with necessary services.
Choose Create security group.
Create a security group for the interface VPC endpoint
To create a security group for the interface VPC endpoint, follow these steps:
Create a second security group named vpce-agentcore-sg that will be attached to the AgentCore Gateway interface VPC endpoint using similar steps to the preceding instructions and selecting the same VPC. For this security group, configure the following rules to enable secure and restricted access:
Inbound rules – Allow HTTPS (port 443) for secure communication to the AgentCore Gateway
Source – Select the EC2 security group (ec2-agent-sg) you created in the preceding section to allow traffic only from authorized agent instances
Outbound rules – Leave as default (all traffic allowed) to support response traffic
This security group configuration implements the principle of least privilege by making sure only EC2 instances with the agent security group can access the VPC endpoint while blocking unauthorized access from other resources in the VPC. These steps are illustrated by the following screenshot.
Provision an EC2 instance within the VPC
Provision an EC2 instance in the same VPC and select an appropriate Availability Zone for your workload requirements. Configure the instance with the network settings shown in the following list, making sure you select the same VPC and note the chosen subnet for VPC endpoint configuration:
VPC – Select your target VPC
Subnet – Choose a private subnet for enhanced security (note this subnet for VPC endpoint configuration)
Security group – Attach the EC2 security group (ec2-agent-sg) you created in the previous steps
IAM role – Configure an IAM role with necessary permissions for Amazon Bedrock and AgentCore Gateway access
Instance type – Choose an appropriate instance type based on your agent workload requirements
Remember the chosen subnet because you’ll need to configure the VPC endpoint in the same subnet to facilitate optimal network routing and minimal latency. These configurations are shown in the following screenshot.
Create an interface VPC endpoint
Create an interface VPC endpoint using Amazon Virtual Private Cloud (Amazon VPC) that automatically uses AWS PrivateLink technology, enabling secure communication from your EC2 instance to AgentCore Gateway without traversing the public internet. Follow these steps:
Navigate to the Amazon VPC console and choose Endpoints in the navigation pane under the PrivateLink and Lattice section.
Choose Create endpoint.
For Name tag, enter a descriptive name (for example, vpce-agentcore-gateway).
For Service category, choose AWS services.
For Services, search for and choose com.amazonaws.<region>.bedrock-agentcore.gateway (replace <region> with your actual AWS Region).
These settings are shown in the following screenshot.
Set the VPC to the same VPC you’ve been working with throughout this setup.
Select Enable DNS name to allow access to the AgentCore Gateway using its default domain name, which simplifies application configuration and maintains compatibility with existing code.
Specify the subnet where the EC2 instance is running to maintain optimal network routing and minimal latency, as shown in the following screenshot.
Set the security group to the VPC endpoint security group (vpce-agentcore-sg) you created earlier to control access to the endpoint.
For initial testing, leave the policy set to Full access to allow agents within your VPC to communicate with AgentCore Gateway in your AWS account. In production environments, implement more restrictive policies based on the principle of least privilege.
After you create the endpoint, it will take approximately 2–5 minutes to become available. You can monitor the status on the Amazon VPC console, and when it shows as Available, you can proceed with testing the connection.
Test the connection
Log in to the EC2 instance to perform following the tests.
Check traffic flow over an interface VPC endpoint
To confirm the traffic flow through the Amazon Bedrock AgentCore Gateway endpoint, check the IP address of the source resource that connects to the AgentCore Gateway endpoint. When you set up an interface VPC endpoint, AWS deploys an elastic network interface with a private IP address in the subnet. This deployment allows communication with AgentCore Gateway from resources within the Amazon VPC and on-premises resources that connect to the interface VPC endpoint through AWS Direct Connect or AWS Site-to-Site VPN. It also allows communication with resources in other Amazon VPC endpoints when you use centralized interface VPC endpoint architecture patterns.
Check whether you turned on private DNS for the AgentCore Gateway endpoint. If you turn on private DNS, then AgentCore Gateway endpoints resolve to the private endpoint IP addresses. For AgentCore Gateway, enabling private DNS means your agents can continue using the standard gateway endpoint URL while benefiting from private network routing through the VPC endpoint.
Before VPC interface endpoint, as shown in the following example, the DNS resolves to a public IP address for AgentCore Gateway endpoint:
nslookup gateway.bedrock-agentcoreamazonaws.com
Non-authoritative answer:
Name: gateway.bedrock-agentcore..amazonaws.com
Address: 52.86.152.150
After VPC interface endpoint creation with private DNS resolution, as shown in the following example, the DNS resolves to private IP address from the CIDR range of the subnet of the VPC in which the VPC endpoint was created.
nslookup .gateway.bedrock-agentcore..amazonaws.com
Non-authoritative answer:
Name: .gateway.bedrock-agentcore..amazonaws.com
Address: 172.31.91.174
When you select Enable DNS name for AgentCore Gateway VPC interface endpoints, by default AWS turns on the Enable private DNS only for inbound endpoints option.
Private DNS enabled (cURL) (recommended)
When private DNS is enabled, your applications can seamlessly use the standard gateway URL endpoint in the format https://{gateway-id}.gateway.bedrock-agentcore.{region}.amazonaws.com while traffic automatically routes through the VPC endpoint.
The following is a sample cURL request to be executed from a resource within the VPC. The command sends a JSON-RPC POST request to retrieve available tools from the AgentCore Gateway:
curl -sS -i -X POST https://<gatewayid>.gateway.bedrock-agentcore.<region>.amazonaws.com/mcp
–header ‘Content-Type: application/json’
–header “Authorization: Bearer $TOKEN”
–data ‘{
“jsonrpc”: “2.0”,
“id”: “‘”$UNIQUE_ID”‘”,
“method”: “tools/list”,
“params”: {}
}’
This cURL command sends a JSON-RPC 2.0 POST request to the AgentCore Gateway MCP endpoint to retrieve a list of available tools. It uses bearer token authentication and includes response headers in the output, calling the tools/list method to discover what tools are accessible through the gateway.
Private DNS disabled (Python)
When Private DNS is disabled, you can’t access the gateway directly through the standard AgentCore Gateway endpoint. Instead, you must route traffic through the VPC DNS name shown in the following screenshot and include the original gateway domain name in the Host header.
curl -sS -i -X POST https://<vpce-dns-name>/mcp
–header ‘Host: <gatewayid>.gateway.bedrock-agentcore.<region>.amazonaws.com
–header ‘Content-Type: application/json’
–header “Authorization: Bearer $TOKEN”
–data ‘{
“jsonrpc”: “2.0”,
“id”: “‘$UNIQUE_ID'”,
“method”: “tools/list”,
“params”: {}
}’
The following steps below walk through executing a Python script that uses the Host header:
Access your EC2 instance. Log in to your EC2 instance that has access to the VPC endpoint.
Configure the required environment variables for the connection:
GATEWAY_URL – The VPC endpoint URL used to access the AgentCore Gateway through your private network connection
TOKEN – Your authentication bearer token for accessing the gateway
GATEWAY_HOST – The original AgentCore Gateway domain name that must be included in the Host header when Private DNS is disabled
For example:
export GATEWAY_URL=https://<vpce_id>.gateway.bedrock-agentcore.ap-southeast-2.vpce.amazonaws.com/mcp
export TOKEN=<your-token-here>
export GATEWAY_HOST=<gateway_id>.gateway.bedrock-agentcore.ap-southeast-2.amazonaws.com
Create and execute the test script.
Copy the following Python code into a file named agent.py. This code tests the AgentCore Gateway workflow by discovering available tools, creating a Strands Agent with the tools, and then testing both conversational interactions (tool listing and weather queries) and direct MCP tool calls. Copy the code:
from strands.models import BedrockModel
from mcp.client.streamable_http import streamablehttp_client
from strands.tools.mcp.mcp_client import MCPClient
from strands import Agent
import logging
import os
# Read authentication token and gateway URL from environment variables
token = os.getenv(‘TOKEN’)
gatewayURL = os.getenv(‘GATEWAY_URL’) #vpc endpoint url
gatewayHost = os.getenv(‘GATEWAY_HOST’) #domain name of the agentcore gateway
def create_streamable_http_transport():
“””Create HTTP transport with proper authentication headers”””
return streamablehttp_client(
gatewayURL,
headers={
“Authorization”: f”Bearer {token}”,
“Host”:gatewayHost
}
)
# Initialize MCP client with the transport
client = MCPClient(create_streamable_http_transport)
# Configure Bedrock model – ensure IAM credentials in ~/.aws/credentials have Bedrock access
yourmodel = BedrockModel(
model_id=”amazon.nova-pro-v1:0″,
temperature=0.7,
)
# Configure logging for debugging and monitoring
logging.getLogger(“strands”).setLevel(logging.INFO)
logging.basicConfig(
format=”%(levelname)s | %(name)s | %(message)s”,
handlers=[logging.StreamHandler()]
)
# Test the complete agent workflow
with client:
targetname = ‘TestGatewayTarget36cb2ebf’
# List available tools from the MCP server
tools = client.list_tools_sync()
# Create an Agent with the model and available tools
agent = Agent(model=yourmodel, tools=tools)
print(f”Tools loaded in the agent: {agent.tool_names}”)
# Test agent with a simple query to list available tools
response1 = agent(“Hi, can you list all tools available to you?”)
print(f”Agent response for tool listing: {response1}”)
# Test agent with a tool invocation request
response2 = agent(“Get the current weather for Seattle and show me the exact response from the tool”)
print(f”Agent response for weather query: {response2}”)
# Direct MCP tool invocation for validation
result = client.call_tool_sync(
tool_use_id=”get-weather-seattle-call-1″, # Unique identifier for this call
name=f”{targetname}___get_weather”, # Tool name format for Lambda targets
arguments={“location”: “Seattle”}
)
print(f”Direct MCP tool response: {result}”)
Invoke the script using the following command:
python3 agent.py
Advanced configuration: VPC endpoint access policies
A VPC endpoint policy is a resource-based policy that controls access to AWS services through the endpoint. Unlike identity-based policies, endpoint policies provide an additional layer of access control at the network level. You can configure access policies for AgentCore Gateway VPC endpoints with specific considerations.When creating endpoint policies for AgentCore Gateway, consider these key elements:
Principal configuration – The Principal field can’t be modified because AgentCore Gateway doesn’t use IAM for authentication. Authentication is handled through bearer tokens rather than IAM principals.
Resource specification – Clearly define the Resource field if you want to restrict access to specific gateway endpoints. Use the full Amazon Resource Name (ARN) format to target particular gateways within your account as shown in the following sample policy structure.
Action permissions – For the Action field, avoid specifying control plane operations. Use a wildcard (*) to allow the necessary data plane operations for gateway functionality.
Here is a sample policy structure:
{
“Version”: “2012-10-17”,
“Statement”: [
{
“Principal”: “*”,
“Effect”: “Allow”,
“Action”: “*”,
“Resource”: “arn:aws:bedrock-agentcore:<region>:<AWS_Account_ID>:gateway/<gateway_id>”
}
]
}
When the VPC endpoint policy blocks a request, you will see error responses such as:
{“jsonrpc”:”2.0″,”id”:2,”error”:{“code”:-32002,”message”:”Authorization error – Insufficient permissions”}}
Policy caching behavior
AgentCore Gateway implements a caching mechanism for access policies that introduces a delay of up to 15 minutes before policy changes take effect. Although this caching significantly improves gateway performance, it means that policy modifications might not be immediately reflected in access controls. To work effectively with this behavior, you should allow at least 15 minutes for policy changes to fully propagate throughout the system after making updates. When possible, schedule policy modifications during planned maintenance windows to minimize operational impact. Always test policy changes in nonproduction environments before applying them to production gateways and factor in the caching delay when diagnosing access-related issues to avoid premature troubleshooting efforts.
Advanced patterns
In a shared gateway, multiple agents pattern, multiple agents from different services access a single centralized gateway through a shared VPC endpoint, simplifying network architecture while maintaining security through token-based authentication. This pattern is illustrated in the following diagram.
In a multi-gateway, multi-agent pattern, which is shown in the following diagram, multiple agents across different applications access multiple specialized gateways through dedicated VPC endpoints, providing maximum security isolation with access control per gateway.
In a cross-VPC gateway access pattern, shown in the following diagram, agents in multiple VPCs can access AgentCore Gateway through VPC peering or AWS Transit Gateway connections, allowing centralized gateway access across network boundaries while maintaining isolation.
In a hybrid cloud gateway pattern, on-premises agents can access cloud-based gateways through VPC endpoints with private DNS disabled, enabling hybrid cloud deployments through Direct Connect or VPN connections. The following diagram illustrates this pattern.
Clean up
To avoid ongoing charges and maintain good resource hygiene, clean up your resources by completing the following steps in order:Delete the EC2 instance:
Navigate to the Amazon EC2 console and select your test instance
Choose Instance state and Stop instance, then wait for it to stop
Choose Instance state and Terminate instance to permanently delete the instance
Delete the VPC endpoint:
Navigate to the Amazon VPC console and choose Endpoints
Select the VPC endpoint (vpce-agentcore-gateway) you created
Choose Actions and Delete VPC endpoints
Confirm the deletion
Delete the security groups:
Navigate to the Amazon EC2 console and choose Security groups
Select the EC2 security group (ec2-agent-sg) you created
Choose Actions and Delete security groups
Repeat for the VPC endpoint security group (vpce-agentcore-sg)
Conclusion
In this post, we demonstrated how to establish secure, private connectivity between VPC-hosted resources and Amazon Bedrock AgentCore Gateway using VPC interface endpoints and AWS PrivateLink. This architecture delivers comprehensive benefits for enterprise agentic AI deployments by implementing networks that are isolated from the internet, providing enhanced security through dedicated private network paths. The solution implements a robust data perimeter through VPC endpoint policies, which create granular access controls that establish strict data boundaries around your AI resources. Additionally, the architecture enables private connectivity to Gateway endpoints for on-premises environments, supporting distributed AI architectures that span cloud and on-premises infrastructure. For organizations deploying autonomous AI systems at scale, implementing VPC interface endpoints creates the secure networking foundation necessary for efficient agent operations while delivering reduced latency through optimized network paths. This enterprise-grade approach helps enable your agentic AI applications to achieve improved performance and reduced response times while meeting security and compliance requirements.
To learn more about implementing these patterns and best practices, visit the Amazon Bedrock documentation and AWS PrivateLink documentation for comprehensive guidance on AI deployments.
About the authors
Dhawal Patel is a Principal Machine Learning Architect at Amazon Web Services (AWS). He has worked with organizations ranging from large enterprises to midsized startups on problems related to distributed computing and AI. He focuses on deep learning, including natural language processing (NLP) and computer vision domains. He helps customers achieve high-performance model inference on Amazon SageMaker.
Sindhura Palakodety is a Senior Solutions Architect at Amazon Web Services (AWS) and Single-Threaded Leader (STL) for ISV Generative AI, where she is dedicated to empowering customers in developing enterprise-scale, Well-Architected solutions. She specializes in generative AI and data analytics domains, enabling organizations to leverage innovative technologies for transformative business outcomes.
Thomas Mathew Veppumthara is a Sr. Software Engineer at Amazon Web Services (AWS) with Amazon Bedrock AgentCore. He has previous generative AI leadership experience in Amazon Bedrock Agents and nearly a decade of distributed systems expertise across Amazon eCommerce Services and Amazon Elastic Block Store (Amazon EBS). He holds multiple patents in distributed systems, storage, and generative AI technologies.
June Won is a Principal Product Manager with Amazon SageMaker JumpStart. He focuses on making foundation models (FMs) easily discoverable and usable to help customers build generative AI applications. His experience at Amazon also includes mobile shopping applications and last-mile delivery.