New Relic Inc. is a San Francisco-based technology company that pioneered application performance monitoring (APM) and provides comprehensive observability solutions. Serving leading customers worldwide, including major brands like Ryanair, New Relic helps organizations monitor and optimize their digital systems to deliver better customer experiences.
New Relic faced a challenge common to many rapidly growing enterprises. Their engineers were spending valuable time searching through fragmented documentation across multiple systems, with time consuming internal system queries, in some cases, taking more than a day. As a leading observability platform supporting thousands of customers worldwide, New Relic knew a more efficient way to access and utilize organizational knowledge was needed.
This challenge led to the creation of New Relic NOVA (New Relic Omnipresence Virtual Assistant): an innovative artificial intelligence (AI) tool built on Amazon Web Services (AWS). New Relic NOVA has transformed how New Relic employees access and interact with company knowledge and systems.
Working with the Generative AI Innovation Center, New Relic NOVA evolved from a knowledge assistant into a comprehensive productivity engine. New Relic NOVA is built on AWS services including Amazon Bedrock, Amazon Kendra, Amazon Simple Storage Service (Amazon S3), and Amazon DynamoDB. Through Strands Agents, New Relic NOVA provides intelligent code reviews, AI governance, and managed Model Context Protocol (MCP) services.
Amazon Bedrock is a fully managed service that provides access to leading foundation models for building generative AI applications, eliminating the need to manage infrastructure while enabling teams to customize models for their specific use cases. Through a single API, developers can experiment with and evaluate different foundation models, integrate them with enterprise systems, and build secure AI applications at scale.
The solution has reduced information search time while automating complex operational workflows. Through collaboration with the Generative AI Innovation Center, New Relic NOVA was developed into a solution that now processes over 1,000 daily queries across their organization. New Relic NOVA integrates seamlessly with Confluence, GitHub, Salesforce, Slack, and various internal systems, maintaining 80% accuracy in its responses for both knowledge-based queries and transactional tasks.
We will show how New Relic NOVA is architected using AWS services to create a scalable, intelligent assistant that goes beyond document retrieval to handle complex tasks like automated team permission requests and rate limit management. We explore the technical architecture, development journey, and key lessons learned in building an enterprise-grade AI solution that delivers measurable productivity gains at scale.
Solution overview
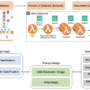
In designing New Relic NOVA, New Relic established several critical objectives beyond the initial goal of improving documentation search. These included maintaining data security during knowledge retrieval and achieving consistent response quality across different data sources. As shown in Figure 1, New Relic NOVA’s AWS architecture enables seamless interaction between users and various AWS services while maintaining security and scalability. The solution required a flexible framework that could evolve with the organization’s needs for both knowledge retrieval and transactional tasks. A key challenge was balancing these requirements while keeping response times under 20 seconds to maintain user engagement.
Figure 1 – Solution architecture of New Relic NOVA framework
The development team identified several potential risks early in the project. These included the possibility of exposing sensitive information through AI responses, maintaining accuracy when retrieving from multiple data sources, and ensuring system reliability at enterprise scale. Figure 2 illustrates New Relic NOVA’s detailed agent workflow, demonstrating how queries are processed and routed through various specialized agents to address user intentions. Additionally, the team implemented comprehensive security controls which included personable identifiable information (PII) detection and masking, along with a robust evaluation framework to monitor and maintain response quality.
Figure 2 – New Relic NOVA agent workflow architecture
The project also revealed opportunities for future optimization. These include expanding an agent hierarchy architecture to support additional automated workflows and developing more sophisticated analytics for tracking user interaction patterns. The team’s experience suggests that organizations undertaking similar projects should focus on establishing clear evaluation metrics early and building flexible architectures that can accommodate evolving business needs.
Solution
New Relic NOVA was developed over an eight-week period, involving a collaborative effort between internal engineering, security, legal, and compliance teams and the AWS Generative AI Innovation Center. This partnership accelerated rapid development and iteration, leveraging AWS expertise in large-scale AI implementations.
Agent architecture
The New Relic NOVA architecture consists of three key layers:
Main agent layer – This acts as a controllable orchestration for executing different workflows by identifying the user intent and delegating efforts to the following downstream layers:
Retrieval Augmented Generation (RAG) with customized ingested knowledge from Amazon Bedrock Knowledge Bases or Amazon Kendra.
Agents for direct interaction with third-party platforms.
Customized agents for handling internal New Relic tasks.
Fallback handling if users’ responses cannot be determined.
Data source layers (vector DB, enrich, data sources) – These layers represent resources where internal knowledge (for example, New Relic standards documentation and code repository documentation) are ingested for retrieval or RAG purposes. The benefit of these custom resources is to enhance information and search performance for use information requests.
Agents layer – Comprises two distinct agent types:
Strands Agents with MCP: Handle multi-step processes for third-party services, leveraging MCP for standardized service interactions.
Custom action agents: Execute New Relic-specific tasks such as permission requests and service limit modifications, providing precise control over internal systems.
A central agent acts as an orchestrator, routing queries to specialized sub-agents in a delegation model where responses flow directly back to the user rather than requiring inter-agent reasoning or adjustments. Meanwhile, Strands Agents are used to efficiently manage third-party service integrations using MCP. This approach gives New Relic NOVA the best of both worlds: the orchestration model maintains flexibility for internal processes while standardizing external services through MCP, creating a scalable foundation for New Relic regarding future automation needs.
Data integration strategy
The power lies in the ability of New Relic NOVA to seamlessly integrate multiple data sources, providing a unified interface for knowledge retrieval. This approach includes:
Amazon Bedrock Knowledge Bases for Confluence: Confirms direct synchronization with Confluence spaces and maintains up-to-date information.
Amazon Kendra for GitHub Enterprise: Indexes and searches GitHub repositories, providing quick access to code documentation.
Strands Agents for Salesforce and Jira: Custom agents execute SOQL and JQL queries, respectively, to fetch relevant data from their respective platforms (Salesforce and Jira).
Amazon Q Index for Slack: Uses Amazon Q Index capabilities to implement a RAG solution for Slack channel history, chosen for its rapid development potential.
A unique aspect of the data integration of New Relic NOVA is the custom document enrichment process. During ingestion, documents are enhanced with metadata, keywords, and summaries, significantly improving retrieval relevance and accuracy.
Using Amazon Nova models
Amazon Nova is AWS’s new generation of foundation models designed to deliver frontier intelligence with industry-leading price performance for enterprise use cases. The Amazon Nova family of models can process diverse inputs including text, images, and video, excelling in tasks from interactive chat to document analysis, while supporting advanced capabilities like RAG systems and AI agent workflows.
To optimize performance and cost-efficiency, New Relic NOVA utilizes Amazon Nova Lite and Pro models through Amazon Bedrock. These models were carefully selected to balance response quality with latency, enabling New Relic NOVA to maintain sub-20 second response times while processing complex queries. Amazon Bedrock provides access to diverse foundation model families. Its standardized framework and prompt optimization supports seamless switching between models without code changes. This allows New Relic NOVA to optimize for speed with Amazon Nova Lite or, because of complexity, switch to Amazon Nova Pro while maintaining consistent performance and cost efficiency.
Advanced RAG implementation
New Relic NOVA employs a sophisticated RAG approach, utilizing Amazon Bedrock Knowledge Bases, Amazon Kendra, and Amazon Q Index. To maximize retrieval accuracy, New Relic NOVA implements several key optimization techniques:
Hierarchical chunking: Amazon Bedrock Knowledge Bases employs hierarchical chunking, a method proven most effective through extensive experimentation with various chunking methodologies.
Context enrichment: A custom AWS Lambda function enhances chunks during knowledge base ingestion, incorporating relevant keywords and contextual information. This process is particularly valuable for code-related content, where structural and semantic cues significantly impact retrieval performance.
Metadata integration: During knowledge base document ingestion, additional context, such as summaries, titles, authors, creation dates, and last modified dates, is appended as document metadata. This enriched metadata enhances the quality and relevance of retrieved information.
Custom document processing: For specific data sources like GitHub repositories, tailored document processing techniques are applied to preserve code structure and improve search relevance.
These techniques work in concert to optimize the RAG system within New Relic NOVA, delivering highly accurate retrieval across varied document types while minimizing development effort through existing connectors. The combination of hierarchical chunking, context enrichment, metadata integration, and custom document processing enables New Relic NOVA to provide precise, context-aware responses regardless of the data source or document format.
Evaluation framework
New Relic NOVA implements a comprehensive evaluation framework, leveraging Amazon Bedrock foundation models for its large language model (LLM)-as-a-judge approach, along with validation datasets that combine questions, ground truth answers, and source document URLs. This evaluation framework, which can be executed on-demand in development environments, encompasses three critical metrics for system validation:
Answer accuracy measurement utilizes a 1–5 discrete scale rating system, where the LLM evaluates the generated response’s factual alignment with the established ground truth data.
Context relevance assessment on a scale of 1–5, analyzing the retrieved context’s relevance to the user query.
Response latency tracking measures workflow performance, from initial query input to final answer generation, ensuring optimal user experience through comprehensive timing analysis.
This triple-metric evaluation approach supports detailed performance optimization across the New Relic NOVA solution core functionalities.
Observability and continuous improvements
The solution includes a comprehensive observability framework that collects metrics and analyzes user feedback. The metric and feedback collection is implemented through New Relic AI monitoring solutions. Feedback is implemented through the Slack reaction feature (emoji responses), users can quickly provide feedback on New Relic NOVA responses. These reactions are captured by a New Relic python agent and sent to a https://one.newrelic.com/ domain. The feedback collection system provides valuable insights for:
Measuring user satisfaction with responses.
Identifying areas where accuracy can be improved.
Understanding usage patterns across different teams.
Tracking the effectiveness of different types of queries.
Monitoring the performance of various data sources.
Tracing each LLM call and latency.
The collected feedback data can be analyzed using AWS analytics services such as AWS Glue for ETL processing, Amazon Athena for querying, and Amazon QuickSight for visualization. This data-driven approach enables continuous improvement of New Relic NOVA and helps prioritize future enhancements based on actual user interactions.
Internal teams are already experiencing the advantages of New Relic NOVA. Figure 3 showcases some of the responses captured by the Slack feedback process.
Figure 3 – Users Slack message exchanges about New Relic NOVA experience
Considerations and next steps
The success of New Relic NOVA highlights several key learnings for organizations looking to implement similar solutions:
Start with a clear understanding of user pain points and measurable success criteria.
Implement robust data integration strategies with custom document enrichment.
Use the generative AI services and foundation models that best fit your use cases to achieve optimal results.
Build in feedback mechanisms from the start to enable continuous improvement.
Focus on both speed and accuracy to ensure user adoption.
In terms of next steps, New Relic NOVA is evolving from a standalone solution into a comprehensive enterprise AI platform by integrating cutting-edge AWS technologies and open-source frameworks. In the future, New Relic anticipates leveraging Amazon S3 Vectors. It offers up to 90% cost reduction for vector storage and querying compared to conventional approaches, enabling the handling of massive-scale AI workloads more efficiently. New Relic is looking to explore Amazon Bedrock AgentCore for enterprise-grade security, memory management, and scalable AI agent deployment, supporting robust production capabilities.
Additionally, New Relic is exploring Strands Agent Workflows, an open-source SDK that streamlines building AI agents from simple conversational assistants to complex autonomous workflows. This technology stack positions New Relic NOVA to deliver enterprise-ready AI solutions that scale seamlessly while maintaining cost efficiency and developer productivity.
Conclusion
The journey of creating New Relic NOVA demonstrates how enterprises can use the generative AI services of AWS to transform organizational productivity. Through the integration of Amazon Bedrock, Amazon Kendra, and other AWS services, New Relic created an AI assistant that transforms their internal operations. Working with the Generative AI Innovation Center of AWS, New Relic achieved a 95% reduction in information search time across their organization while automating complex operational workflows.
Learn more about transforming your business with generative AI by visiting the Generative AI Innovation Center or speak with an AWS Partner Specialist or AWS Representative to know how we can help accelerate your business.
Further reading
Building generative AI applications on AWS – AWS Classroom Training
Generative AI Lens – AWS Well-Architected Framework – Gain a deep understanding of how to design, deploy, and operate generative AI applications on AWS effectively
Build an end-to-end RAG solution using Amazon Bedrock Knowledge Bases and AWS CloudFormation
Open Protocols for Agent Interoperability Part 1: Inter-Agent Communication on MCP
About the authors
Yicheng Shen is a lead software engineer for New Relic NOVA, where he focuses on developing gen AI and agentic solutions that transform how businesses understand their application performance. When he’s not building intelligent systems, you’ll find him exploring the outdoors with his family and their dog.
Sarathy Varadarajan, Senior Director of Engineering at New Relic, drives AI-first transformation and developer productivity, aiming for tenfold gains via intelligent automation and enterprise AI. He scaled engineering teams from 15 to over 350 in Bangalore and Hyderabad. He enjoys family time and volleyball.
Joe King is an AWS Senior Data Scientist at the Generative AI Innovation Center, where he helps organizations architect and implement cutting-edge generative AI solutions. With deep expertise in science, engineering, and AI/ML architecture, he specializes in transforming complex generative AI use cases into scalable solutions on AWS.
Priyashree Roy is an AWS data scientist at the Generative AI Innovation Center, where she applies her deep expertise in machine learning and generative AI to build cutting-edge solutions for AWS strategic customers. With a PhD in experimental particle physics, she brings a rigorous scientific approach to solving complex real-world problems through advanced AI technologies.
Gene Su is an AWS Data Scientist at the Generative AI Innovation Center, specializing in generative AI solutions for finance, retail, and other industries. He uses his expertise in large language models (LLMs) to deliver generative AI applications on AWS.
Dipanshu Jain is a generative AI Strategist at AWS, helping unlock the potential of gen AI through strategic advisory and tailored solution development. Specialized in identifying high-impact generative AI use cases, shaping execution roadmaps, and guiding cross-functional teams through proofs of concept—from discovery to production.
Ameer Hakme is an AWS Solutions Architect that collaborates with Independent Software Vendors (ISVs) in the Northeast region, assisting in designing and building scalable and modern platforms on the AWS Cloud. An expert in AI/ML and generative AI, Ameer helps customers unlock the potential of these cutting-edge technologies. In his leisure time, he enjoys riding his motorcycle and spending quality time with his family.