This post is co-written with David Gildea and Tom Nijs from Druva.
Generative AI is transforming the way businesses interact with their customers and revolutionizing conversational interfaces for complex IT operations. Druva, a leading provider of data security solutions, is at the forefront of this transformation. In collaboration with Amazon Web Services (AWS), Druva is developing a cutting-edge generative AI-powered multi-agent copilot that aims to redefine the customer experience in data security and cyber resilience.
Powered by Amazon Bedrock and using advanced large language models (LLMs), this innovative solution will provide Druva’s customers with an intuitive, conversational interface to access data management, security insights, and operational support across their product suite. By harnessing the power of generative AI and agentic AI, Druva aims to streamline operations, increase customer satisfaction, and enhance the overall value proposition of its data security and cyber resilience solutions.
In this post, we examine the technical architecture behind this AI-powered copilot, exploring how it processes natural language queries, maintains context across complex workflows, and delivers secure, accurate responses to streamline data protection operations.
Challenges and opportunities
Druva wants to effectively serve enterprises moving beyond traditional query-based AI and into agentic systems and meet their complex data management and security needs with greater speed, simplicity, and confidence.
Comprehensive data security necessitates tracking a high volume of data and metrics to identify potential cyber threats. As threats evolve, it can be difficult for customers to stay abreast of new data anomalies to hunt for within their organization’s data, but missing any threat signals can lead to unauthorized access to sensitive information. For example, a global financial services company managing more than 500 servers across multiple regions currently spends hours manually checking logs across dozens of systems when backup fails. With an AI-powered copilot, they could simply ask, “Why did my backups fail last night?” and instantly receive an analysis showing that a specific policy update caused conflicts in their European data centers, along with a step-by-step remediation, reducing investigation time from hours to minutes. This solution not only reduces the volume of support requests and accelerates the time to resolution, but also unlocks greater operational efficiency for end users.
By reimagining how users engage with the system—from AI-powered workflows to smarter automation—Druva saw a clear opportunity to deliver a more seamless customer experience that strengthens customer satisfaction, loyalty, and long-term success.
The key opportunities for Druva in implementing a generative AI-powered multi-agent copilot include:
Simplified user experience: By providing a natural language interface, the copilot can simplify complex data protection tasks and help users access the information they need quickly.
Intelligent Troubleshooting: The copilot can leverage AI capabilities to analyze data from various sources, identify the root causes of backup failures, and provide personalized recommendations for resolution.
Streamlined Policy Management: The multi-agent copilot can guide users through the process of creating, modifying, and implementing data protection policies, reducing the potential for human errors and improving compliance.
Proactive Support: By continuously monitoring data protection environments, the copilot can proactively identify potential issues and provide guidance to help prevent failures or optimize performance.
Scalable and Efficient Operations: The AI-powered solution can handle a large volume of customer inquiries and tasks simultaneously, reducing the burden on Druva’s support team so that they can focus on more complex and strategic initiatives.
Solution overview
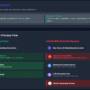
The proposed solution for Druva’scopilot leverages a sophisticated architecture that combines the power of Amazon Bedrock (including Amazon Bedrock Knowledge Bases), LLMs, and a dynamic API selection process to deliver an intelligent and efficient user experience. In the following diagram, we demonstrate the end-to-end architecture and various sub-components.
At the core of the system is the supervisor agent, which serves as the central coordination component of the multi-agent system. This agent is responsible for overseeing the entire conversation flow, delegating tasks to specialized sub-agents, and maintaining seamless communication between the various components.
The user interacts with the supervisor agent through a user interface, submitting natural language queries related to data protection, backup management, and troubleshooting. The supervisor agent analyzes the user’s input and routes the request to the appropriate sub-agents based on the nature of the query.
The data agent is responsible for retrieving relevant information from Druva’s systems by interacting with the GET APIs. This agent fetches data such as scheduled backup jobs, backup status, and other pertinent details to provide the user with accurate and up-to-date information.
The help agent assists users by providing guidance on best practices, step-by-step instructions, and troubleshooting tips. This agent draws upon an extensive knowledge base, which includes detailed API documentation, user manuals, and frequently asked questions, to deliver context-specific assistance to users.
When a user needs to perform critical actions, such as initiating a backup job or modifying data protection policies, the action agent comes into play. This agent interacts with the POST API endpoints to execute the necessary operations, making sure that the user’s requirements are met promptly and accurately.
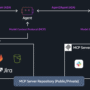
To make sure that the multi-agent copilot operates with the most suitable APIs and parameters, the solution incorporates a dynamic API selection process. In the following diagram, we highlight the various AWS services used to implement dynamic API selection, with which both the data agent and the action agent are equipped. Bedrock Knowledge Bases contains comprehensive information about available APIs, their functionalities, and optimal usage patterns. Once an input query is received, we use semantic search to retrieve the top K relevant APIs. This semantic search capability enables the system to adapt to the specific context of each user request, enhancing the Copilot’s accuracy, efficiency, and scalability. Once the appropriate APIs are identified, the agent prompts the LLM to parse the top K relevant APIs and finalize the API selection along with the required parameters. This step makes sure that the copilot is fully equipped to run the user’s request effectively.
Finally, the selected API is invoked, and the multi-agent copilot carries out the desired action or retrieves the requested information. The user receives a clear and concise response, along with relevant recommendations or guidance, through the user interface.
Throughout the interaction, users can provide additional information or explicit approvals by using the user feedback node before the copilot performs critical actions. With this human-in-the-loop approach, the system operates with the necessary safeguards and maintains user control over sensitive operations.
Evaluation
The evaluation process for Druva’s generative AI-powered multi-agent copilot focuses on assessing the performance and effectiveness of each critical component of the system. By thoroughly testing individual components such as dynamic API selection, isolated tests on individual agents, and end-to-end functionality, the copilot delivers accurate, reliable, and efficient results to its users.
Evaluation methodology:
Unit testing: Isolated tests are conducted for each component (individual agents, data extraction, API selection) to verify their functionality, performance, and error handling capabilities.
Integration Testing: Tests are performed to validate the seamless integration and communication between the various components of the multi-agent copilot, maintaining data flow and control flow integrity.
System Testing: End-to-end tests are executed on the complete system, simulating real-world user scenarios and workflows to assess the overall functionality, performance, and user experience.
Evaluation results
Choosing the right model for the right task is critical to the system’s performance. The dynamic tool selection represents one of the most critical parts of the system—invoking the correct API is essential for end-to-end solution success. A single incorrect API call can lead to fetching wrong data, which cascades into erroneous results throughout the multi-agent system. To optimize the dynamic tool selection component, various Nova and Anthropic models were tested and benchmarked against the ground truth created using Sonnet 3.7.
The findings showed that even smaller models like Nova Lite and Haiku 3 were able to select the correct API every time. However, these smaller models struggled with parameter parsing such as calling the API with the correct parameters relative to the input question. When parameter parsing accuracy was taken into account, the overall API selection accuracy dropped to 81% for Nova Micro, 88% for Nova Lite, and 93% for Nova Pro. The performance of Haiku 3, Haiku 3.5, and Sonnet 3.5 was comparable, ranging from 91% to 92%. Nova Pro provided an optimal tradeoff between accuracy and latency with an average response time of just over one second. In contrast, Sonnet 3.5 had a latency of eight seconds, although this could be attributed to Sonnet 3.5’s more verbose output, generating an average of 291 tokens compared to Nova Pro’s 86 tokens. The prompts could potentially be optimized to make Sonnet 3.5’s output more concise, thus reducing the latency.
For end-to-end testing of real world scenarios, it is essential to engage human subject matter expert evaluators familiar with the system to assess performance based on completeness, accuracy, and relevance of the solutions. Across 11 challenging questions during the initial development phase, the system achieved scores averaging 3.3 out of 5 across these dimensions. This represented solid performance considering the evaluation was conducted in the early stages of development, providing a strong foundation for future improvements.
By focusing on evaluating each critical component and conducting rigorous end-to-end testing, Druva has made sure that the generative AI-powered multi-agent copilot meets the highest standards of accuracy, reliability, and efficiency. The insights gained from this evaluation process have guided the continuous improvement and optimization of the copilot.
“Druva is at the forefront of leveraging advanced AI technologies to revolutionize the way organizations protect and manage their critical data. Our Generative AI-powered Multi-agent Copilot is a testament to our commitment to delivering innovative solutions that simplify complex processes and enhance customer experiences. By collaborating with the AWS Generative AI Innovation Center, we are embarking on a transformative journey to create an interactive, personalized, and efficient end-to-end experience for our customers. We are excited to harness the power of Amazon Bedrock and our proprietary data to continue reimagining the future of data security and cyber resilience.”- David Gildea, VP of Generative AI at Druva
Conclusion
Druva’s generative AI-powered multi-agent copilot showcases the immense potential of combining structured and unstructured data sources using AI to create next-generation virtual copilots. This innovative approach sets Druva apart from traditional data protection vendors by transforming hours-long manual investigations into instant, AI-powered conversational insights, with 90% of routine data protection tasks executable through natural language interactions, fundamentally redefining customer expectations in the data security space. For organizations in the data security and protection space, this technology enables more efficient operations, enhanced customer engagement, and data-driven decision-making. The insights and intelligence provided by the copilot empower Druva’s stakeholders, including customers, support teams, partners, and executives, to make informed decisions faster, reducing average time-to-resolution for data security issues by up to 70% and accelerating backup troubleshooting from hours to minutes. Although this project focuses on the data protection industry, the underlying principles and methodology can be applied across various domains. With careful design, testing, and continuous improvement, organizations in any industry can benefit from AI-powered copilots that contextualize their data, documents, and content to deliver intelligent and personalized experiences.
This implementation leverages Amazon Bedrock AgentCore Runtime and Amazon Bedrock AgentCore Gateway to provide robust agent orchestration and management capabilities. This approach has the potential to provide intelligent automation and data search capabilities through customizable agents, transforming user interactions with applications to be more natural, efficient, and effective. For those interested in implementing similar functionalities, explore Amazon Bedrock Agents, Amazon Bedrock Knowledge Bases and Amazon Bedrock AgentCore as a fully managed AWS solution.
About the authors
David Gildea With over 25 years of experience in cloud automation and emerging technologies, David has led transformative projects in data management and cloud infrastructure. As the founder and former CEO of CloudRanger, he pioneered innovative solutions to optimize cloud operations, later leading to its acquisition by Druva. Currently, David leads the Labs team in the Office of the CTO, spearheading R&D into Generative AI initiatives across the organization, including projects like Dru Copilot, Dru Investigate, and Amazon Q. His expertise spans technical research, commercial planning, and product development, making him a prominent figure in the field of cloud technology and generative AI.
Tom Nijs is an experienced backend and AI engineer at Druva, driven by a passion for both learning and sharing knowledge. As the Lead Architect for Druva’s Labs team, he channels this passion into developing cutting-edge solutions, leading projects such as Dru Copilot, Dru Investigate, and Dru AI Labs. With a core focus on optimizing systems and harnessing the power of AI, Tom is dedicated to helping teams and developers turn groundbreaking ideas into reality.
Gauhar Bains is a Deep Learning Architect at the AWS Generative AI Innovation Center, where he designs and delivers innovative GenAI solutions for enterprise customers. With a passion for leveraging cutting-edge AI technologies, Gauhar specializes in developing agentic AI applications, and implementing responsible AI practices across diverse industries.
Ayushi Gupta is a Senior Technical Account Manager at AWS who partners with organizations to architect optimal cloud solutions. She specializes in ensuring business-critical applications operate reliably while balancing performance, security, and cost efficiency. With a passion for GenAI innovation, Ayushi helps customers leverage cloud technologies that deliver measurable business value while maintaining robust data protection and compliance standards.
Marius Moisescu is a Machine Learning Engineer at the AWS Generative AI Innovation Center. He works with customers to develop agentic applications. His interests are deep research agents and evaluation of multi agent architectures.
Ahsan Ali is an Senior Applied Scientist at the Amazon Generative AI Innovation Center, where he works with customers from different industry verticals to solve their urgent and expensive problems using Generative AI.
Sandy Farr is an Applied Science Manager at the AWS Generative AI Innovation Center, where he leads a team of scientists, deep learning architects and software engineers to deliver innovative GenAI solutions for AWS customers. Sandy holds a PhD in Physics and has over a decade of experience developing AI/ML, NLP and GenAI solutions for large organizations.
Govindarajan Varadan is a Manager of the Solutions Architecture team at Amazon Web Services (AWS) based out of Silicon Valley in California. He works with AWS customers to help them achieve their business objectives through innovative applications of AI at scale.
Saeideh Shahrokh Esfahani is an Applied Scientist at the Amazon Generative AI Innovation Center, where she focuses on transforming cutting-edge AI technologies into practical solutions that address real-world challenges.