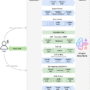
As AI agents move from single-app copilots to autonomous systems that browse, transact, and coordinate with each other, a new infrastructure layer is emerging underneath them. This article compares six key “agent-native rails” — MCP, A2A, AP2, ACP, x402, and Kite — focusing on how they standardize tool access, inter-agent communication, payment authorization, and settlement, and what that means for engineers designing secure, commerce-capable agentic systems.
The agent stack is around six trending agentic ‘rails’:
MCP – standard interface for tools and data.
A2A – transport and lifecycle for agent-to-agent calls.
AP2 – trust and mandates for agent-initiated payments.
ACP – interaction model for agentic checkout and commerce flows.
x402 – HTTP-native, on-chain payment protocol for APIs and agents.
Kite – L1 + state channels for high-frequency agent payments and policy-enforced autonomy.
They are complementary, not competing: MCP and A2A wire agents to context and each other, AP2/ACP encode commercial intent, and x402/Kite handle settlement.
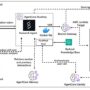
The 6 rails at a glance
RailLayerPrimary roleTransport / substrateMCP (Model Context Protocol)Tools & dataStandard interface to tools, data sources, promptsJSON-RPC over stdio / process, HTTP / SSEA2A (Agent2Agent)Agent meshDiscovery and task lifecycle between agentsJSON-RPC 2.0 over HTTPS, optional SSE streamsAP2 (Agent Payments Protocol)Payment control planeVerifiable mandates and roles for agent paymentsProtocol-agnostic over existing rails, including blockchains like SuiACP (Agentic Commerce Protocol)Commerce flowsShared language for catalog, offers, checkout stateProtocol spec + HTTP APIs, open standard co-developed by OpenAI and Stripex402Settlement railInternet-native, per-request payments for APIs and agentsHTTP 402 with on-chain stablecoins such as USDCKiteL1 + state channelsAgent-centric chain with identity and streaming micropaymentsL1 chain + off-chain state-channel rails for agents
The rest of the article unpacks each rail along four axes:
Capabilities
Security posture
Ecosystem traction
OS / runtime integration trajectory
1. MCP: tool and context rail
Capabilities
The Model Context Protocol is an open protocol for connecting LLM applications to external tools and data. It defines a client–server architecture:
MCP clients (agents, IDEs, chat UIs) connect to
MCP servers that expose tools, resources, and prompts via a standardized JSON-RPC schema.
Tools are strongly typed (name + JSON schema for parameters and results) and can wrap arbitrary systems: HTTP APIs, databases, file operations, internal services, etc.
The same protocol works across transports (stdio for local processes, HTTP/SSE for remote servers), which is why multiple runtimes can consume the same MCP servers.
Security posture
MCP is deliberately agnostic about identity and payments. Security is inherited from the host:
Servers can run locally or remotely and may have full access to files, networks, and cloud APIs.
The main risks are classic: arbitrary code execution in tools, prompt injection, over-privileged credentials, and exfiltration of sensitive data.
Security guidance from Red Hat and others focuses on:
Least-privilege credentials per MCP server.
Sandboxing tools where possible.
Strong review and signing of server configurations.
Logging and audit for tool calls.
MCP itself does not give you access control semantics like ‘this agent can call this tool only under policy P’; those are layered on by hosts and IAM systems.
Ecosystem traction
MCP moved from Anthropic-only to ecosystem standard quickly:
Anthropic launched MCP and open-sourced the spec and TypeScript schemas.
OpenAI added full MCP client support in ChatGPT Developer Mode and the platform ‘Connectors’ system.
Microsoft integrated MCP into VS Code, Visual Studio, GitHub Copilot, and Copilot for Azure, including an “Azure MCP server.”
LangChain and LangGraph ship langchain-mcp-adapters for treating MCP tools as first-class LangChain tools.
Cloudflare runs a catalog of managed remote MCP servers and exposes them via its Agents SDK.
MCP is now effectively the ‘USB-C port’ for agent tools across IDEs, browsers, cloud agents, and edge runtimes
2. A2A: agent-to-agent protocol
Capabilities
The Agent2Agent (A2A) protocol is an open standard for inter-agent communication and task handoff. The spec defines:
A2A client – initiates tasks on behalf of a user or system.
A2A server (remote agent) – exposes a JSON-RPC endpoint that executes tasks.
Agent cards – JSON metadata at well-known paths (for example, /.well-known/agent-card.json) describing capabilities, endpoint, and auth.
Transport is standardized:
JSON-RPC 2.0 over HTTPS for requests and responses.
Optional SSE streams for long-running or streaming tasks.
This gives agents a common ‘RPC fabric’ independent of vendor or framework.
Security posture
At the protocol layer, A2A leans on common web primitives:
HTTPS with standard auth (API keys, OAuth-like tokens, mTLS) negotiated based on agent cards.
JSON-RPC 2.0 message format; parser correctness is a concern, since bugs in JSON-RPC handling become a security vector.
Red Hat and other analyses highlight:
Keep JSON-RPC libraries patched.
Protect against replay and downgrade attacks at the HTTP / TLS layer.
Treat agent-to-agent traffic like service-mesh traffic: identity, authz, and rate-limiting matter.
The protocol does not itself decide which agents should talk; that is a policy question for the platform.
Ecosystem traction
Google introduced A2A and is driving it as an interoperability layer for agents across enterprise platforms.
The A2A open-source org maintains the reference spec and implementation.
Amazon Bedrock AgentCore Runtime now supports A2A as a first-class protocol, with documented contract requirements.
Third-party frameworks (for example, CopilotKit) are adopting A2A for cross-agent and app-agent communication.
3. AP2: payment control layer
Capabilities
Agent Payments Protocol (AP2) is Google’s open standard for agent-initiated payments. Its core problem statement: when an AI agent pays, how do we know it had permission, the payment matches user intent, and someone is clearly accountable?
AP2 introduces:
Mandates – cryptographically signed digital contracts that encode who can pay, under which limits, for what kinds of transactions.
Role separation – payer agents, merchants, issuers, networks, and wallets each have explicit protocol roles.
Rail-agnostic design – AP2 can authorize payments over cards, bank transfers, or programmable blockchains such as Sui.
The protocol is designed to compose with A2A and MCP: A2A handles the messaging, MCP connects to tools, AP2 governs the payment semantics.
Security posture
Security is the main reason AP2 exists:
Mandates are signed using modern public-key cryptography and can be independently verified.
The protocol explicitly targets authorization, authenticity, and accountability: did the agent have permission, does the action match user intent, and who is liable if something goes wrong.
Ecosystem traction
AP2 is still early but already has meaningful backing:
Google announced AP2 with more than 60 organizations across ecommerce, payments, banking, and crypto as collaborators or early supporters.
Cohorts include networks like Mastercard and American Express, wallets and PSPs such as PayPal, and crypto players including Coinbase.
4. ACP: commerce interaction model
Capabilities
The Agentic Commerce Protocol (ACP), co-developed by OpenAI and Stripe, is the interaction model underlying ChatGPT Instant Checkout. It gives agents and merchants a shared language for:
Product discovery (catalog and offers).
Configuration (variants, shipping options).
Checkout state (selected item, price, shipping, terms).
Fulfillment and post-purchase status.
ACP is designed to:
Work across processors and business types without forcing backend rewrites.
Keep merchants as the merchant of record for fulfillment, returns, and support, even when the interaction starts in an agent.
Security posture
In ACP deployments:
Payments are handled by processors such as Stripe; ACP itself focuses on the structure of the commerce interaction, not on cryptography.
OpenAI’s Instant Checkout uses limited-scope payment credentials and explicit confirmation steps in the ChatGPT UI, which makes agent-initiated purchases visible to the user.
ACP does not replace anti-fraud, KYC, or PCI responsibilities; those remain with the PSPs and merchants.
Ecosystem traction
OpenAI and Stripe have open-sourced ACP and are actively recruiting merchants and platforms.
Instant Checkout is live for Etsy sellers, with Shopify merchants and additional regions coming next, and multiple press reports highlight ACP as the underlying protocol.
Salesforce has announced ACP-based integrations for its Agentforce Commerce stack.
ACP is essentially becoming the agent-side ‘checkout API‘ for multiple commerce ecosystems.
5. x402: HTTP-native settlement
Capabilities
x402 is Coinbase’s open payment protocol for AI agents and APIs. It revives HTTP status code 402 Payment Required as the trigger for machine-initiated, per-request payments.
Key properties:
Instant, automatic stablecoin payments over HTTP, primarily using USDC on chains like Base.
Clients (agents, apps) can pay for API calls, content, or services without accounts or sessions, by programmatically responding to 402 challenges.
Designed for both human and machine consumers, but the machine-to-machine case is explicitly emphasized.
Security posture
Settlement is on-chain, so the usual blockchain guarantees (and risks) apply: immutability, transparent balances, but exposure to contract bugs and key theft.
Coinbase runs the compliant infrastructure (KYT, sanctions screening, etc.) behind its managed offering.
There are no chargebacks; dispute handling must be layered at ACP/AP2 or application level.
Ecosystem traction
Coinbase and Cloudflare announced the x402 Foundation to push x402 as an open standard for internet payments, targeting both agents and human-facing APIs.
Cloudflare integrated x402 into its Agents SDK and MCP integration, so Workers and agents can offer paywalled endpoints and call x402 servers with a single wrapper.
6. Kite: agent-native L1 and state channels
Capabilities
Kite is an AI-oriented L1 chain and payment rail designed for agentic commerce. It states:
State-channel based micropayments– agents open off-chain channels and stream tiny payments with instant finality, settling periodically on-chain.
Agent-centric identity and constraints– cryptographic identity is used to bind agents and users, with protocol-level spend constraints and policy enforcement.
PoAI-oriented design– the chain is explicitly tuned for the AI-agent economy, not generic DeFi.
Security posture
Kite inherits L1 security concerns (consensus safety, smart-contract correctness) plus state-channel specifics:
Off-chain channels must be protected against fraud (for example, outdated state publication) and key compromise.
Policy constraints are enforced at protocol level; if implemented correctly, this can significantly reduce the chance of runaway spending by agents.
Because the design is agent-specific, there is less ‘legacy baggage’ than in generalized DeFi chains, but also less battle-tested code.
Ecosystem traction
PayPal Ventures and others have publicly backed Kite as part of the agentic commerce stack.
Crypto and infra publications describe it as a complementary rail to x402, optimized for streaming, high-frequency interactions between agents.
The ecosystem is still young compared to mainstream L1s, but it is clearly positioned as an ‘AI-payments L1,’ not a general-purpose chain.
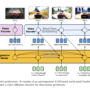
How the rails compose in real systems
A realistic agentic workflow will touch several of these rails:
Tooling and data
An IDE agent, OS agent, or backend agent connects to internal APIs, file systems, and monitoring systems via MCP servers.
Multi-agent orchestration
The primary agent delegates specialized tasks (for example, cost optimization, legal review, marketing ops) to other agents via A2A.
Commerce flow
For purchasing, the agent enters an ACP flow with a merchant: fetch catalog, configure a product, receive a priced offer, confirm checkout state.
Payment authorization
The user has previously granted an AP2 mandate to a wallet-backed payment agent, specifying limits and scope. The commerce or orchestration agent requests payment via that AP2-capable payment agent.
Settlement
Depending on the scenario, the payment agent may:
Use traditional rails (card, bank) under AP2, or
Use x402 for per-call on-chain payments to an API, or
Use Kite state channels for streaming micro-transactions between agents.
This composition preserves separation of concerns:
MCP & A2A: who talks to whom, and about what.
AP2 & ACP: how intent, consent, and liability for commerce are encoded.
x402 & Kite: how value is actually moved at low latency.
References:
Model Context Protocol – official sitehttps://modelcontextprotocol.io/
Anthropic: “Introducing the Model Context Protocol”https://www.anthropic.com/news/model-context-protocol
Claude Docs: “Model Context Protocol (MCP)”https://docs.claude.com/en/docs/mcp
OpenAI Docs: “Connectors and MCP servers”https://platform.openai.com/docs/guides/tools-connectors-mcp
OpenAI Docs: “MCP Server Documentation”https://platform.openai.com/docs/mcp
LangChain MCP Adapters – GitHubhttps://github.com/langchain-ai/langchain-mcp-adapters
LangChain Docs: “Model Context Protocol (MCP)”https://docs.langchain.com/oss/python/langchain/mcp
npm package: @langchain/mcp-adaptershttps://www.npmjs.com/package/%40langchain/mcp-adapters
Azure AI Foundry: “Create an MCP Server with Azure AI Agent Service”https://devblogs.microsoft.com/foundry/integrating-azure-ai-agents-mcp/
Azure AI Foundry Docs: “Connect to Model Context Protocol servers (preview)”https://learn.microsoft.com/en-us/azure/ai-foundry/agents/how-to/tools/model-context-protocol
Azure AI Foundry MCP Server – May 2025 updatehttps://devblogs.microsoft.com/foundry/azure-ai-foundry-mcp-server-may-2025/
Windows AI Foundry (MCP integration in Windows)https://developer.microsoft.com/en-us/windows/ai/
The Verge: “Windows is getting support for the ‘USB-C of AI apps’”https://www.theverge.com/news/669298/microsoft-windows-ai-foundry-mcp-support
Agent2Agent (A2A) Protocol – official specificationhttps://a2a-protocol.org/latest/specification/
Google Developers Blog: “Announcing the Agent2Agent Protocol (A2A)”https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/
IBM Think: “What is A2A protocol (Agent2Agent)?”https://www.ibm.com/think/topics/agent2agent-protocol
Amazon Bedrock: “Deploy A2A servers in AgentCore Runtime”https://docs.aws.amazon.com/bedrock-agentcore/latest/devguide/runtime-a2a.html
Amazon Bedrock: “A2A protocol contract”https://docs.aws.amazon.com/bedrock-agentcore/latest/devguide/runtime-a2a-protocol-contract.html
AWS News: “Amazon Bedrock AgentCore is now generally available”https://aws.amazon.com/about-aws/whats-new/2025/10/amazon-bedrock-agentcore-available/
Google Cloud Blog: “Announcing Agent Payments Protocol (AP2)”https://cloud.google.com/blog/products/ai-machine-learning/announcing-agents-to-payments-ap2-protocol
AP2 overview / technical details (Google / partner materials)https://cloud.google.com/blog/products/ai-machine-learning/announcing-agents-to-payments-ap2-protocol
Coinbase x402 + AP2 launch with Googlehttps://www.coinbase.com/developer-platform/discover/launches/google_x402
Omni (Swedish) coverage: “Google teamar upp med betaljättar – vill låta AI-agenter shoppa åt dig”https://omni.se/a/RzkWqO
OpenAI: “Buy it in ChatGPT: Instant Checkout and the Agentic Commerce Protocol”https://openai.com/index/buy-it-in-chatgpt/
OpenAI Developer Docs: “Agentic Commerce Protocol – Get started”https://developers.openai.com/commerce/guides/get-started/
Stripe Newsroom: “Stripe powers Instant Checkout in ChatGPT and releases the Agentic Commerce Protocol”https://stripe.com/newsroom/news/stripe-openai-instant-checkout
TechRadar Pro: “You can now buy things through ChatGPT with a single click”https://www.techradar.com/pro/you-can-now-buy-things-through-chatgpt-with-a-single-click-if-youre-one-of-the-lucky-ones
Reuters: “OpenAI partners with Etsy, Shopify on ChatGPT payment checkout”https://www.reuters.com/world/americas/openai-partners-with-etsy-shopify-chatgpt-checkout-2025-09-29/
Salesforce Press Release: “Salesforce Announces Support for Agentic Commerce Protocol with Stripe and OpenAI”https://www.salesforce.com/news/press-releases/2025/10/14/stripe-openai-agentic-commerce-protocol-announcement/
Salesforce Investor News: “Salesforce and OpenAI Partner Across Enterprise Work and Commerce”https://investor.salesforce.com/news/news-details/2025/Salesforce-and-OpenAI-Partner-Across-Enterprise-Work-and-Commerce/default.aspx
Salesforce: Agentforce Commercehttps://www.salesforce.com/commerce/
Coinbase Developer Platform: “x402: The internet-native payment protocol”https://www.coinbase.com/developer-platform/products/x402
Base Docs: “Building Autonomous Payment Agents with x402”https://docs.base.org/base-app/agents/x402-agents
Cloudflare Agents Docs: “x402 · Cloudflare Agents docs”https://developers.cloudflare.com/agents/x402/
Cloudflare Blog: “Launching the x402 Foundation with Coinbase, and support for x402 transactions”https://blog.cloudflare.com/x402/
Cloudflare x402 tag pagehttps://blog.cloudflare.com/tag/x402/
Zuplo Blog: “Autonomous API & MCP Server Payments with x402”https://zuplo.com/blog/mcp-api-payments-with-x402
Kite whitepaper: “Building Trustless Payment Infrastructure for Agentic AI”https://gokite.ai/kite-whitepaper
Kite: “Whitepaper”https://gokite.ai/whitepaper
Kite Docs: “Introduction & Mission”https://docs.gokite.ai/get-started-why-kite/introduction-and-mission
PayPal Newsroom: “Kite Raises $18M in Series A Funding To Enforce Trust in the Agentic Web”https://newsroom.paypal-corp.com/2025-09-02-Kite-Raises-18M-in-Series-A-Funding-To-Enforce-Trust-in-the-Agentic-Web
PayPal Ventures: “The state of agentic commerce and why we invested in Kite AI”https://paypal.vc/news/news-details/2025/The-state-of-agentic-commerce-and-why-we-invested-in-Kite-AI-2025-LroAXfplpA/default.aspx
Binance Research: “Kite enables an agentic internet…”https://www.binance.com/en-KZ/research/projects/kite
Phemex Academy: “What Is Kite (KITE)? Guide to the AI Agent Economy”https://phemex.com/academy/what-is-kite-ai-agent-economy
Finextra: “PayPal leads funding round in agentic AI firm Kite”https://www.finextra.com/newsarticle/46535/paypal-leads-funding-round-in-agentic-ai-firm-kite
Plug and Play Tech Center: “How Kite is Building the Infrastructure for the Agentic Internet”https://www.plugandplaytechcenter.com/venture-capital/investment-announcements/kite-investment
PYMNTS: “PayPal Ventures-Backed Kite Nets $18M for Agentic AI”https://www.pymnts.com/news/investment-tracker/2025/paypal-backed-kite-raises-18-million-for-agentic-web/
GlobeNewswire: “Kite announces investment from Coinbase Ventures…”https://www.globenewswire.com/news-release/2025/10/27/3174837/0/en/Kite-announces-investment-from-Coinbase-Ventures-to-Advance-Agentic-Payments-with-the-x402-Protocol.html
Keycard – official sitehttps://www.keycard.ai/
Keycard: product page (alternate URL)https://www.keycard.sh/
Help Net Security: “Keycard emerges from stealth with identity and access platform for AI agents”https://www.helpnetsecurity.com/2025/10/22/keycard-ai-agents-identity-access-platform/
GlobeNewswire: “Keycard Launches to Solve the AI Agent Identity and Access Problem…”https://www.globenewswire.com/news-release/2025/10/21/3170297/0/en/Keycard-Launches-to-Solve-the-AI-Agent-Identity-and-Access-Problem-With-38-Million-in-Funding-From-Andreessen-Horowitz-Boldstart-Ventures-and-Acrew-Capital.html
The post Comparing the Top 6 Agent-Native Rails for the Agentic Internet: MCP, A2A, AP2, ACP, x402, and Kite appeared first on MarkTechPost.