Generative AI has created unprecedented opportunities for Canadian organizations to transform their operations and customer experiences. We are excited to announce that customers in Canada can now access advanced foundation models including Anthropic’s Claude Sonnet 4.5 and Claude Haiku 4.5 on Amazon Bedrock through cross-Region inference (CRIS).
This post explores how Canadian organizations can use cross-Region inference profiles from the Canada (Central) Region to access the latest foundation models to accelerate AI initiatives. We will demonstrate how to get started with these new capabilities, provide guidance for migrating from older models, and share recommended practices for quota management.
Canadian cross-Region inference: Your gateway to global AI innovation
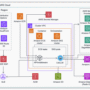
To help customers achieve the scale of their Generative AI applications, Amazon Bedrock offers Cross-Region Inference (CRIS) profiles, a powerful feature that enables organizations to seamlessly distribute inference processing across multiple AWS Regions. This capability helps you get higher throughput while building at scale, helping to ensure your generative AI applications remain responsive and reliable even under heavy load.
Amazon Bedrock provides two types of cross-Region Inference profiles:
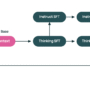
Geographic CRIS: Amazon Bedrock automatically selects the optimal commercial Region within that geography to process your inference request.
Global CRIS: Global CRIS further enhances cross-Region inference by enabling the routing of inference requests to supported commercial Regions worldwide, optimizing available resources and enabling higher model throughput.
Cross-Region Inference operates through the secure AWS network with end-to-end encryption for both data in transit and at rest. When a customer submits an inference request from the Canada (Central) Region, CRIS intelligently routes the request to one of the destination regions configured for the inference profile (US or Global profiles).
The key distinction is that while inference processing (the transient computation) may occur in another Region, all data at rest—including logs, knowledge bases, and any stored configurations—remains exclusively within the Canada (Central) Region. The inference request travels over the AWS Global Network, never traversing the public internet, and responses are returned encrypted to your application in Canada.
Cross-Region inference configuration for Canada
With CRIS, Canadian organizations gain earlier access to foundation models, including cutting-edge models like Claude Sonnet 4.5 with enhanced reasoning capabilities, providing a faster path to innovation. CRIS also delivers enhanced capacity and performance by providing access to capacity across multiple Regions. This enables higher throughput during peak periods such as tax season, Black Friday, and holiday shopping, automatic burst handling without manual intervention, and greater resiliency by serving requests from a larger pool of resources.
Canadian customers can choose between two inference profile types based on their requirements:
CRIS profile
Source Region
Destination Regions
Description
US cross-Region inference
ca-central-1
Multiple US Regions
Requests from Canada (Central) can be routed to supported US Regions with capacity.
Global inference
ca-central-1
Global AWS Regions
Requests from Canada (Central) can be routed to a Region in the AWS global CRIS profile.
Getting started with CRIS from Canada
To begin using cross-Region Inference from Canada, follow these steps:
Configure AWS Identity and Access Management (IAM) permissions
First, verify your IAM role or user has the necessary permissions to invoke Amazon Bedrock models using cross-Region inference profiles.
Here’s an example of a policy for US cross-Region inference:
{
“Version”: “2012-10-17”,
“Statement”: [
{
“Effect”: “Allow”,
“Action”: [
“bedrock:InvokeModel*”
],
“Resource”: [
“arn:aws:bedrock:ca-central-1::inference-profile/us.anthropic.claude-sonnet-4-5-20250929-v1:0”
]
},
{
“Effect”: “Allow”,
“Action”: [
“bedrock:InvokeModel*”
],
“Resource”: [
“arn:aws:bedrock:*::foundation-model/anthropic.claude-sonnet-4-5-20250929-v1:0”
],
“Condition”: {
“StringLike”: {
“bedrock:InferenceProfileArn”: “arn:aws:bedrock:ca-central-1::inference-profile/us.anthropic.claude-sonnet-4-5-20250929-v1:0″
}
}
}
]
}
For global CRIS refer to the blog post, Unlock global AI inference scalability using new global cross-Region inference on Amazon Bedrock with Anthropic’s Claude Sonnet 4.5.
Use cross-Region inference profiles
Configure your application to use the relevant inference profile ID. The profiles use prefixes to indicate their routing scope:
Model
Routing scope
Inference profile ID
Claude Sonnet 4.5
US Regions
us.anthropic.claude-sonnet-4-5-20250929-v1:0
Claude Sonnet 4.5
Global
global.anthropic.claude-sonnet-4-5-20250929-v1:0
Claude Haiku 4.5
US Regions
us.anthropic.claude-haiku-4-5-20251001-v1:0
Claude Haiku 4.5
Global
global.anthropic.claude-haiku-4-5-20251001-v1:0
Example code
Here’s how to use the Amazon Bedrock Converse API with a US CRIS inference profile from Canada:
import boto3
# Initialize Bedrock Runtime client
bedrock_runtime = boto3.client(
service_name=”bedrock-runtime”,
region_name=”ca-central-1″ # Canada (Central) Region
)
# Define the inference profile ID
inference_profile_id = “us.anthropic.claude-sonnet-4-5-20250929-v1:0”
# Prepare the conversation
response = bedrock_runtime.converse(
modelId=inference_profile_id,
messages=[
{
“role”: “user”,
“content”: [
{
“text”: “What are the benefits of using Amazon Bedrock for Canadian organizations?”
}
]
}
],
inferenceConfig={
“maxTokens”: 512,
“temperature”: 0.7
}
)
# Print the response
print(f”Response: {response[‘output’][‘message’][‘content’][0][‘text’]}”)
Quota management for Canadian workloads
When using CRIS from Canada, quota management is performed at the source Region level (ca-central-1). This means quota increases requested for the Canada (Central) Region apply to all inference requests originating from Canada, regardless of where they’re processed.
Understanding quota calculations
Important: When calculating your required quota increases, you need to take into account the burndown rate, defined as the rate at which input and output tokens are converted into token quota usage for the throttling system. The following models have a 5x burn down rate for output tokens (1 output token consumes 5 tokens from your quotas):
Anthropic Claude Opus 4
Anthropic Claude Sonnet 4.5
Anthropic Claude Sonnet 4
Anthropic Claude 3.7 Sonnet
For other models, the burndown rate is 1:1 (1 output token consumes 1 token from your quota). For input tokens, the token to quota ratio is 1:1. The calculation for the total number of tokens per request is as follows:
Input token count + Cache write input tokens + (Output token count x Burndown rate)
Requesting quota increases
To request quota increases for CRIS in Canada:
Navigate to the AWS Service Quotas console in the Canada (Central) Region
Search for the specific model quota (for example, “Claude Sonnet 4.5 tokens per minute”)
Submit an increase request based on your projected usage
Migrating from older Claude models to Claude 4.5
Organizations currently using older Claude models should plan their migration to Claude 4.5 to leverage the latest model capabilities.
To plan your migration strategy, incorporate the following elements:
Benchmark current performance: Establish baseline metrics for your existing models.
Test with representative workloads and optimize prompts: Validate Claude 4.5 performance with your specific use cases, and adjust prompt to leverage Claude 4.5’s enhanced capabilities and make use of the Bedrock prompt optimizer tool.
Implement gradual rollout: Transition traffic progressively.
Monitor and adjust: Track performance metrics and adjust quotas as needed.
Choosing between US and Global inference profiles
When implementing CRIS from Canada, organizations can choose between US and Global inference profiles based on their specific requirements.
US cross-Region inference is recommended for organizations with existing US data processing agreements, high throughput and resilience requirements and development and testing environments.
Conclusion
Cross-Region inference for Amazon Bedrock represents an opportunity for Canadian organizations that want to use AI while maintaining data governance. By distinguishing between transient inference processing and persistent data storage, CRIS provides faster access to the latest foundation models without compromising compliance requirements.
With CRIS, Canadian organizations get access to new models within days instead of months. The system scales automatically during peak business periods while maintaining complete audit trails within Canada. This helps you meet compliance requirements and use the same advanced AI capabilities as organizations worldwide. To get started, review your data governance requirements and configure IAM permissions. Then test with the inference profile that matches your needs—US for lower latency to US Regions, or Global for maximum capacity.
About the authors
Daniel Duplessis is a Principal Generative AI Specialist Solutions Architect at Amazon Web Services (AWS), where he guides enterprises in crafting comprehensive AI implementation strategies and establish the foundational capabilities essential for scaling AI across the enterprise.
Dan MacKay is the Financial Services Compliance Specialist for AWS Canada. He advises customers on recommended practices and practical solutions for cloud-related governance, risk, and compliance. Dan specializes in helping AWS customers navigate financial services and privacy regulations applicable to the use of cloud technology in Canada with a focus on third-party risk management and operational resilience.
Melanie Li, PhD, is a Senior Generative AI Specialist Solutions Architect at AWS based in Sydney, Australia, where her focus is on working with customers to build solutions using state-of-the-art AI/ML tools. She has been actively involved in multiple generative AI initiatives across APJ, harnessing the power of LLMs. Prior to joining AWS, Dr. Li held data science roles in the financial and retail industries.
Serge Malikov is a Senior Solutions Architect Manager based out of Canada. His focus is on the financial services industry.
Saurabh Trikande is a Senior Product Manager for Amazon Bedrock and Amazon SageMaker Inference. He is passionate about working with customers and partners, motivated by the goal of democratizing AI. He focuses on core challenges related to deploying complex AI applications, inference with multi-tenant models, cost optimizations, and making the deployment of generative AI models more accessible. In his spare time, Saurabh enjoys hiking, learning about innovative technologies, following TechCrunch, and spending time with his family.
Sharadha Kandasubramanian is a Senior Technical Program Manager for Amazon Bedrock. She drives cross-functional GenAI programs for Amazon Bedrock, enabling customers to grow and scale their GenAI workloads. Outside of work, she’s an avid runner and biker who loves spending time outdoors in the sun.