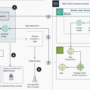
In this tutorial, we build an advanced Agentic AI using the control-plane design pattern, and we walk through each component step by step as we implement it. We treat the control plane as the central orchestrator that coordinates tools, manages safety rules, and structures the reasoning loop. Also, we set up a miniature retrieval system, defined modular tools, and integrated an agentic reasoning layer that dynamically plans and executes actions. At last, we observe how the entire system behaves like a disciplined, tool-aware AI capable of retrieving knowledge, assessing understanding, updating learner profiles, and logging all interactions through a unified, scalable architecture. Check out the FULL CODES here.
Copy CodeCopiedUse a different Browserimport subprocess
import sys
def install_deps():
deps = [‘anthropic’, ‘numpy’, ‘scikit-learn’]
for dep in deps:
subprocess.check_call([sys.executable, ‘-m’, ‘pip’, ‘install’, ‘-q’, dep])
try:
import anthropic
except ImportError:
install_deps()
import anthropic
import json
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
from dataclasses import dataclass, asdict
from typing import List, Dict, Any, Optional
from datetime import datetime
@dataclass
class Document:
id: str
content: str
metadata: Dict[str, Any]
embedding: Optional[np.ndarray] = None
class SimpleRAGRetriever:
def __init__(self):
self.documents = self._init_knowledge_base()
def _init_knowledge_base(self) -> List[Document]:
docs = [
Document(“cs101”, “Python basics: Variables store data. Use x=5 for integers, name=’Alice’ for strings. Print with print().”, {“topic”: “python”, “level”: “beginner”}),
Document(“cs102”, “Functions encapsulate reusable code. Define with def func_name(params): and call with func_name(args).”, {“topic”: “python”, “level”: “intermediate”}),
Document(“cs103”, “Object-oriented programming uses classes. class MyClass: defines structure, __init__ initializes instances.”, {“topic”: “python”, “level”: “advanced”}),
Document(“math101”, “Linear algebra: Vectors are ordered lists of numbers. Matrix multiplication combines transformations.”, {“topic”: “math”, “level”: “intermediate”}),
Document(“ml101”, “Machine learning trains models on data to make predictions. Supervised learning uses labeled examples.”, {“topic”: “ml”, “level”: “beginner”}),
Document(“ml102”, “Neural networks are composed of layers. Each layer applies weights and activation functions to transform inputs.”, {“topic”: “ml”, “level”: “advanced”}),
]
for i, doc in enumerate(docs):
doc.embedding = np.random.rand(128)
doc.embedding[i*20:(i+1)*20] += 2
return docs
def retrieve(self, query: str, top_k: int = 2) -> List[Document]:
query_embedding = np.random.rand(128)
scores = [cosine_similarity([query_embedding], [doc.embedding])[0][0] for doc in self.documents]
top_indices = np.argsort(scores)[-top_k:][::-1]
return [self.documents[i] for i in top_indices]
We set up all dependencies, import the libraries we rely on, and initialize the data structures for our knowledge base. We define a simple retriever and generate mock embeddings to simulate similarity search in a lightweight way. As we run this block, we prepare everything needed for retrieval-driven reasoning in the later components. Check out the FULL CODES here.
Copy CodeCopiedUse a different Browserclass ToolRegistry:
def __init__(self, retriever: SimpleRAGRetriever):
self.retriever = retriever
self.interaction_log = []
self.user_state = {“level”: “beginner”, “topics_covered”: []}
def search_knowledge(self, query: str, filters: Optional[Dict] = None) -> Dict:
docs = self.retriever.retrieve(query, top_k=2)
if filters:
docs = [d for d in docs if all(d.metadata.get(k) == v for k, v in filters.items())]
return {
“tool”: “search_knowledge”,
“results”: [{“content”: d.content, “metadata”: d.metadata} for d in docs],
“count”: len(docs)
}
def assess_understanding(self, topic: str) -> Dict:
questions = {
“python”: [“What keyword defines a function?”, “How do you create a variable?”],
“ml”: [“What is supervised learning?”, “Name two types of ML algorithms.”],
“math”: [“What is a vector?”, “Explain matrix multiplication.”]
}
return {
“tool”: “assess_understanding”,
“topic”: topic,
“questions”: questions.get(topic, [“General comprehension check.”])
}
def update_learner_profile(self, topic: str, level: str) -> Dict:
if topic not in self.user_state[“topics_covered”]:
self.user_state[“topics_covered”].append(topic)
self.user_state[“level”] = level
return {
“tool”: “update_learner_profile”,
“status”: “updated”,
“profile”: self.user_state.copy()
}
def log_interaction(self, event: str, details: Dict) -> Dict:
log_entry = {
“timestamp”: datetime.now().isoformat(),
“event”: event,
“details”: details
}
self.interaction_log.append(log_entry)
return {“tool”: “log_interaction”, “status”: “logged”, “entry_id”: len(self.interaction_log)}
We build the tool registry that our agent uses while interacting with the system. We define tools such as knowledge search, assessments, profile updates, and logging, and we maintain a persistent user-state dictionary. As we use this layer, we see how each tool becomes a modular capability that the control plane can route to. Check out the FULL CODES here.
Copy CodeCopiedUse a different Browserclass ControlPlane:
def __init__(self, tool_registry: ToolRegistry):
self.tools = tool_registry
self.safety_rules = {
“max_tools_per_request”: 4,
“allowed_tools”: [“search_knowledge”, “assess_understanding”,
“update_learner_profile”, “log_interaction”]
}
self.execution_log = []
def execute(self, plan: Dict[str, Any]) -> Dict[str, Any]:
if not self._validate_request(plan):
return {“error”: “Safety validation failed”, “plan”: plan}
action = plan.get(“action”)
params = plan.get(“parameters”, {})
result = self._route_and_execute(action, params)
self.execution_log.append({
“timestamp”: datetime.now().isoformat(),
“plan”: plan,
“result”: result
})
return {
“success”: True,
“action”: action,
“result”: result,
“metadata”: {
“execution_count”: len(self.execution_log),
“safety_checks_passed”: True
}
}
def _validate_request(self, plan: Dict) -> bool:
action = plan.get(“action”)
if action not in self.safety_rules[“allowed_tools”]:
return False
if len(self.execution_log) >= 100:
return False
return True
def _route_and_execute(self, action: str, params: Dict) -> Any:
tool_map = {
“search_knowledge”: self.tools.search_knowledge,
“assess_understanding”: self.tools.assess_understanding,
“update_learner_profile”: self.tools.update_learner_profile,
“log_interaction”: self.tools.log_interaction
}
tool_func = tool_map.get(action)
if tool_func:
return tool_func(**params)
return {“error”: f”Unknown action: {action}”}
We implement the control plane that orchestrates tool execution, checks safety rules, and manages permissions. We validate every request, route actions to the right tool, and keep an execution log for transparency. As we run this snippet, we observe how the control plane becomes the governing system that ensures predictable and safe agentic behavior. Check out the FULL CODES here.
Copy CodeCopiedUse a different Browserclass TutorAgent:
def __init__(self, control_plane: ControlPlane, api_key: str):
self.control_plane = control_plane
self.client = anthropic.Anthropic(api_key=api_key)
self.conversation_history = []
def teach(self, student_query: str) -> str:
plan = self._plan_actions(student_query)
results = []
for action_plan in plan:
result = self.control_plane.execute(action_plan)
results.append(result)
response = self._synthesize_response(student_query, results)
self.conversation_history.append({
“query”: student_query,
“plan”: plan,
“results”: results,
“response”: response
})
return response
def _plan_actions(self, query: str) -> List[Dict]:
plan = []
query_lower = query.lower()
if any(kw in query_lower for kw in [“what”, “how”, “explain”, “teach”]):
plan.append({
“action”: “search_knowledge”,
“parameters”: {“query”: query},
“context”: {“intent”: “knowledge_retrieval”}
})
if any(kw in query_lower for kw in [“test”, “quiz”, “assess”, “check”]):
topic = “python” if “python” in query_lower else “ml”
plan.append({
“action”: “assess_understanding”,
“parameters”: {“topic”: topic},
“context”: {“intent”: “assessment”}
})
plan.append({
“action”: “log_interaction”,
“parameters”: {“event”: “query_processed”, “details”: {“query”: query}},
“context”: {“intent”: “logging”}
})
return plan
def _synthesize_response(self, query: str, results: List[Dict]) -> str:
response_parts = [f”Student Query: {query}n”]
for result in results:
if result.get(“success”) and “result” in result:
tool_result = result[“result”]
if result[“action”] == “search_knowledge”:
response_parts.append(“n Retrieved Knowledge:”)
for doc in tool_result.get(“results”, []):
response_parts.append(f” • {doc[‘content’]}”)
elif result[“action”] == “assess_understanding”:
response_parts.append(“n Assessment Questions:”)
for q in tool_result.get(“questions”, []):
response_parts.append(f” • {q}”)
return “n”.join(response_parts)
We implement the TutorAgent, which plans actions, communicates with the control plane, and synthesizes final responses. We analyze queries, generate multi-step plans, and combine tool outputs into meaningful answers for learners. As we execute this snippet, we see the agent behaving intelligently by coordinating retrieval, assessment, and logging. Check out the FULL CODES here.
Copy CodeCopiedUse a different Browserdef run_demo():
print(“=” * 70)
print(“Control Plane as a Tool: RAG AI Tutor Demo”)
print(“=” * 70)
API_KEY = “your-api-key-here”
retriever = SimpleRAGRetriever()
tool_registry = ToolRegistry(retriever)
control_plane = ControlPlane(tool_registry)
print(“System initialized”)
print(f”Tools: {len(control_plane.safety_rules[‘allowed_tools’])}”)
print(f”Knowledge base: {len(retriever.documents)} documents”)
try:
tutor = TutorAgent(control_plane, API_KEY)
except:
print(“Mock mode enabled”)
tutor = None
demo_queries = [
“Explain Python functions to me”,
“I want to learn about machine learning”,
“Test my understanding of Python basics”
]
for query in demo_queries:
print(“n— Query —“)
if tutor:
print(tutor.teach(query))
else:
plan = [
{“action”: “search_knowledge”, “parameters”: {“query”: query}},
{“action”: “log_interaction”, “parameters”: {“event”: “query”, “details”: {}}}
]
print(query)
for action in plan:
result = control_plane.execute(action)
print(f”{action[‘action’]}: {result.get(‘success’, False)}”)
print(“Summary”)
print(f”Executions: {len(control_plane.execution_log)}”)
print(f”Logs: {len(tool_registry.interaction_log)}”)
print(f”Profile: {tool_registry.user_state}”)
if __name__ == “__main__”:
run_demo()
We run a complete demo that initializes all components, processes sample student queries, and prints system state summaries. We watch the agent step through retrieval and logging while the control plane enforces rules and tracks execution history. As we finish this block, we get a clear picture of how the entire architecture works together in a realistic teaching loop.
In conclusion, we gain a clear understanding of how the control-plane pattern simplifies orchestration, strengthens safety, and creates a clean separation between reasoning and tool execution. We now see how a retrieval system, tool registry, and agentic planning layer come together to form a coherent AI tutor that responds intelligently to student queries. As we experiment with the demo, we observe how the system routes tasks, applies rules, and synthesizes useful insights from tool outputs, all while remaining modular and extensible.
Check out the FULL CODES here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
The post A Coding Guide to Design an Agentic AI System Using a Control-Plane Architecture for Safe, Modular, and Scalable Tool-Driven Reasoning Workflows appeared first on MarkTechPost.