Asure, a company of over 600 employees, is a leading provider of cloud-based workforce management solutions designed to help small and midsized businesses streamline payroll and human resources (HR) operations and ensure compliance. Their offerings include a comprehensive suite of human capital management (HCM) solutions for payroll and tax, HR compliance services, time tracking, 401(k) plans, and more.
Asure anticipated that generative AI could aid contact center leaders to understand their team’s support performance, identify gaps and pain points in their products, and recognize the most effective strategies for training customer support representatives using call transcripts. The Asure team was manually analyzing thousands of call transcripts to uncover themes and trends, a process that lacked scalability. The overarching goal of this engagement was to improve upon this manual approach. Failing to adopt a more automated approach could have potentially led to decreased customer satisfaction scores and, consequently, a loss in future revenue. Therefore, it was valuable to provide Asure a post-call analytics pipeline capable of providing beneficial insights, thereby enhancing the overall customer support experience and driving business growth.
Asure recognized the potential of generative AI to further enhance the user experience and better understand the needs of the customer and wanted to find a partner to help realize it.
Pat Goepel, chairman and CEO of Asure, shares,
“In collaboration with the AWS Generative AI Innovation Center, we are utilizing Amazon Bedrock, Amazon Comprehend, and Amazon Q in QuickSight to understand trends in our own customer interactions, prioritize items for product development, and detect issues sooner so that we can be even more proactive in our support for our customers. Our partnership with AWS and our commitment to be early adopters of innovative technologies like Amazon Bedrock underscore our dedication to making advanced HCM technology accessible for businesses of any size.”
“We are thrilled to partner with AWS on this groundbreaking generative AI project. The robust AWS infrastructure and advanced AI capabilities provide the perfect foundation for us to innovate and push the boundaries of what’s possible. This collaboration will enable us to deliver cutting-edge solutions that not only meet but exceed our customers’ expectations. Together, we are poised to transform the landscape of AI-driven technology and create unprecedented value for our clients.”
—Yasmine Rodriguez, CTO of Asure.
“As we embarked on our journey at Asure to integrate generative AI into our solutions, finding the right partner was crucial. Being able to partner with the Gen AI Innovation Center at AWS brings not only technical expertise with AI but the experience of developing solutions at scale. This collaboration confirms that our AI solutions are not just innovative but also resilient. Together, we believe that we can harness the power of AI to drive efficiency, enhance customer experiences, and stay ahead in a rapidly evolving market.”
—John Canada, VP of Engineering at Asure.
In this post, we explore why Asure used the Amazon Web Services (AWS) post-call analytics (PCA) pipeline that generated insights across call centers at scale with the advanced capabilities of generative AI-powered services such as Amazon Bedrock and Amazon Q in QuickSight. Asure chose this approach because it provided in-depth consumer analytics, categorized call transcripts around common themes, and empowered contact center leaders to use natural language to answer queries. This ultimately allowed Asure to provide its customers with improvements in product and customer experiences.
Solution Overview
At a high level, the solution consists of first converting audio into transcripts using Amazon Transcribe and generating and evaluating summary fields for each transcript using Amazon Bedrock. In addition, Q&A can be done at a single call level using Amazon Bedrock or for many calls using Amazon Q in QuickSight. In the rest of this section, we describe these components and the services used in greater detail.
We added upon the existing PCA solution with the following services:
Amazon Bedrock
Amazon Q in QuickSight
Customer service and call center operations are highly dynamic, with evolving customer expectations, market trends, and technological advancements reshaping the industry at a rapid pace. Staying ahead in this competitive landscape demands agile, scalable, and intelligent solutions that can adapt to changing demands.
In this context, Amazon Bedrock emerges as an exceptional choice for developing a generative AI-powered solution to analyze customer service call transcripts. This fully managed service provides access to cutting-edge foundation models (FMs) from leading AI providers, enabling the seamless integration of state-of-the-art language models tailored for text analysis tasks. Amazon Bedrock offers fine-tuning capabilities that allow you to customize these pre-trained models using proprietary call transcript data, facilitating high accuracy and relevance without the need for extensive machine learning (ML) expertise. Moreover, Amazon Bedrock offers integration with other AWS services like Amazon SageMaker, which streamlines the deployment process, and its scalable architecture makes sure the solution can adapt to increasing call volumes effortlessly.
With robust security measures, data privacy safeguards, and a cost-effective pay-as-you-go model, Amazon Bedrock offers a secure, flexible, and cost-efficient service to harness generative AI’s potential in enhancing customer service analytics, ultimately leading to improved customer experiences and operational efficiencies.
Furthermore, by integrating a knowledge base containing organizational data, policies, and domain-specific information, the generative AI models can deliver more contextual, accurate, and relevant insights from the call transcripts. This knowledge base allows the models to understand and respond based on the company’s unique terminology, products, and processes, enabling deeper analysis and more actionable intelligence from customer interactions.
In this use case, Amazon Bedrock is used for both generation of summary fields for sample call transcripts and evaluation of these summary fields against a ground truth dataset. Its value comes from its simple integration into existing pipelines and various evaluation frameworks. Amazon Bedrock also allows you to choose various models for different use cases, making it an obvious choice for the solution due to its flexibility. Using Amazon Bedrock allows for iteration of the solution using knowledge bases for simple storage and access of call transcripts as well as guardrails for building responsible AI applications.
Amazon Bedrock
Amazon Bedrock is a fully managed service that makes FMs available through an API, so you can choose from a wide range of FMs to find the model that is best suited for your use case. With the Amazon Bedrock serverless experience, you can get started quickly, privately customize FMs with your own data, and quickly integrate and deploy them into your applications using AWS tools without having to manage the infrastructure.
Amazon Q in Quicksight
Amazon Q in QuickSight is a generative AI assistant that accelerates decision-making and enhances business productivity with generative business intelligence (BI) capabilities.
The original PCA solution includes the following services:
AWS Lambda
Amazon Simple Storage Service (Amazon S3)
Amazon CloudFront
Amazon Athena
Amazon Comprehend
Amazon Transcribe
Amazon Cognito
The solution consisted of the following components:
Call metadata generation – After the file ingestion step when transcripts are generated for each call transcript using Amazon Transcribe, Anthropic’s Claude Haiku FM in Amazon Bedrock is used to generate call-related metadata. This includes a summary, the category, the root cause, and other high-level fields generated from a call transcript. This is orchestrated using AWS Step Functions.
Individual call Q&A – For questions requiring a specific call, such as, “How did the customer react in call ID X,” Anthropic’s Claude Haiku is used to power a Q&A assistant located in a CloudFront application. This is powered by the web app portion of the architecture diagram (provided in the next section).
Aggregate call Q&A – To answer questions requiring multiple calls, such as “What are the most common issues detected,” Amazon Q on QuickSight is used to enhance the Agent Assist interface. This step is shown by business analysts interacting with QuickSight in the storage and visualization step through natural language.
To learn more about the architectural components of the PCA solution, including file ingestion, insight extraction, storage and visualization, and web application components, refer to Post call analytics for your contact center with Amazon language AI services.
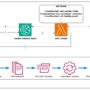
Architecture
The following diagram illustrates the solution architecture. The evaluation framework, call metadata generation, and Amazon Q in QuickSight were new components introduced from the original PCA solution.
Ragas and a human-in-the-loop UI (as described in the customer blogpost with Tealium) were used to evaluate the metadata generation and individual call Q&A portions. Ragas is an open source evaluation framework that helps evaluate FM-generated text.
The high-level takeaways from this work are the following:
Anthropic’s Claude 3 Haiku successfully took in a call transcript and determined its summary, root cause, if the issue was resolved, and, if it was a callback, next steps by the customer and agent (generative AI-powered fields). When using Anthropic’s Claude 3 Haiku as opposed to Anthropic’s Claude Instant, there was a reduction in latency. With chain-of-thought reasoning, there was an increase in overall quality (includes how factual, understandable, and relevant responses are on a 1–5 scale, described in more detail later in this post) as measured by subject matter experts (SMEs). With the use of Amazon Bedrock, various models can be chosen based on different use cases, illustrating its flexibility in this application.
Amazon Q in QuickSight proved to be a powerful analytical tool in understanding and generating relevant insights from data through intuitive chart and table visualizations. It can perform simple calculations whenever necessary while also facilitating deep dives into issues and exploring data from multiple perspectives, demonstrating great value in insight generation.
The human-in-the-loop UI plus Ragas metrics proved effective to evaluate outputs of FMs used throughout the pipeline. Particularly, answer correctness, answer relevance, faithfulness, and summarization metrics (alignment and coverage score) were used to evaluate the call metadata generation and individual call Q&A components using Amazon Bedrock. Its flexibility in various FMs allowed the testing of many types of models to generate evaluation metrics, including Anthropic’s Claude Sonnet 3.5 and Anthropic’s Claude Haiku 3.
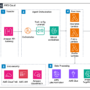
Call metadata generation
The call metadata generation pipeline consisted of converting an audio file to a call transcript in a JSON format using Amazon Transcribe and then generating key information for each transcript using Amazon Bedrock and Amazon Comprehend. The following diagram shows a subset of the preceding architecture diagram that demonstrates this.
The original PCA post linked previously shows how Amazon Transcribe and Amazon Comprehend are used in the metadata generation pipeline.
The call transcript input that was outputted from the Amazon Transcribe step of the Step Functions workflow followed the format in the following code example:
{
call_id: <call id>,
agent_id: <agent_id>
customer_id: <customer_id>
transcript: “””
Agent: <Agent message>.
Customer: <Customer message>
Agent: <Agent message>.
Customer: <Customer message>
Agent: <Agent message>.
Customer: <Customer message>
………..
“””
}
Metadata was generated using Amazon Bedrock. Specifically, it extracted the summary, root cause, topic, and next steps, and answered key questions such as if the call was a callback and if the issue was ultimately resolved.
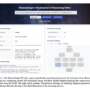
Prompts were stored in Amazon DynamoDB, allowing Asure to quickly modify prompts or add new generative AI-powered fields based on future enhancements. The following screenshot shows how prompts can be modified through DynamoDB.
Individual call Q&A
The chat assistant powered by Anthropic’s Claude Haiku was used to answer natural language queries on a single transcript. This assistant, the call metadata values generated from the previous section, and sentiments generated from Amazon Comprehend were displayed in an application hosted by CloudFront.
The user of the final chat assistant can modify the prompt in DynamoDB. The following screenshot shows the general prompt for an individual call Q&A.
The UI hosted by CloudFront allows an agent or supervisor to analyze a specific call to extract additional details. The following screenshot shows the insights Asure gleaned for a sample customer service call.
The following screenshot shows the chat assistant, which exists in the same webpage.
Evaluation Framework
This section outlines components of the evaluation framework used. It ultimately allows Asure to highlight important metrics for their use case and provides visibility into the generative AI application’s strengths and weaknesses. This was done using automated quantitative metrics provided by Ragas, DeepEval, and traditional ML metrics as well as human-in-the-loop evaluation done by SMEs.
Quantitative Metrics
The results of the generated call metadata and individual call Q&A were evaluated using quantitative metrics provided by Ragas: answer correctness, answer relevance, and faithfulness; and DeepEval: alignment and coverage, both powered by FMs from Amazon Bedrock. Its simple integration with external libraries allowed Amazon Bedrock to be configured with existing libraries. In addition, traditional ML metrics were used for “Yes/No” answers. The following are the metrics used for different components of the solution:
Call metadata generation – This included the following:
Summary – Alignment and coverage (find a description of these metrics in the DeepEval repository) and answer correctness
Issue resolved, callback – F1-score and accuracy
Topic, next steps, root cause – Answer correctness, answer relevance, and faithfulness
Individual call Q&A – Answer correctness, answer relevance, and faithfulness
Human in the loop – Both individual call Q&A and call metadata generation used human-in-the-loop metrics
For a description of answer correctness, answer relevance, and faithfulness, refer to the customer blogpost with Tealium.
The use of Amazon Bedrock in the evaluation framework allowed for a flexibility of different models based on different use cases. For example, Anthropic’s Claude Sonnet 3.5 was used to generate DeepEval metrics, whereas Anthropic’s Claude 3 Haiku (with its low latency) was ideal for Ragas.
Human in the Loop
The human-in-the-loop UI is described in the Human-in-the-Loop section of the customer blogpost with Tealium. To use it to evaluate this solution, some changes had to be made:
There is a choice for the user to analyze one of the generated metadata fields for a call (such as a summary) or a specific Q&A pair.
The user can bring in two model outputs for comparison. This can include outputs from the same FMs but using different prompts, outputs from different FMs but using the same prompt, and outputs from different FMs and using different prompts.
Additional checks for fluency, coherence, creativity, toxicity, relevance, completeness, and overall quality were added, where the user adds in a measure of this metric based on the model output from a range of 0–4.
The following screenshots show the UI.
The human-in-the-loop system establishes a mechanism between domain expertise and Amazon Bedrock outputs. This in turn will lead to improved generative AI applications and ultimately to high customer trust of such systems.
To demo the human-in-the-loop UI, follow the instructions in the GitHub repo.
Natural Language Q&A using Amazon Q in Quicksight
QuickSight, integrated with Amazon Q, enabled Asure to use natural language queries for comprehensive customer analytics. By interpreting queries on sentiments, call volumes, issue resolutions, and agent performance, the service delivered data-driven visualizations. This empowered Asure to quickly identify pain points, optimize operations, and deliver exceptional customer experiences through a streamlined, scalable analytics solution tailored for call center operations.
Integrate Amazon Q in QuickSight with the PCA solution
The Amazon Q in QuickSight integration was done by following three high-level steps:
Create a dataset on QuickSight.
Create a topic on QuickSight from the dataset.
Query using natural language.
Create a dataset on QuickSight
We used Athena as the data source, which queries data from Amazon S3. QuickSight can be configured through multiple data sources (for more information, refer to Supported data sources). For this use case, we used the data generated from the PCA pipeline as the data source for further analytics and natural language queries in Amazon Q in QuickSight. The PCA pipeline stores data in Amazon S3, which can be queried in Athena, an interactive query service that allows you to analyze data directly in Amazon S3 using standard SQL.
On the QuickSight console, choose Datasets in the navigation pane.
Choose Create new.
Choose Athena as the data source and input the particular catalog, database, and table that Amazon Q in QuickSight will reference.
Confirm the dataset was created successfully and proceed to the next step.
Create a topic on Amazon Quicksight from the dataset created
Users can use topics in QuickSight, powered by Amazon Q integration, to perform natural language queries on their data. This feature allows for intuitive data exploration and analysis by posing questions in plain language, alleviating the need for complex SQL queries or specialized technical skills. Before setting up a topic, make sure that the users have Pro level access. To set up a topic, follow these steps:
On the QuickSight console, choose Topics in the navigation pane.
Choose New topic.
Enter a name for the topic and choose the data source created.
Choose the created topic and then choose Open Q&A to start querying in natural language
Query using natural language
We performed intuitive natural language queries to gain actionable insights into customer analytics. This capability allows users to analyze sentiments, call volumes, issue resolutions, and agent performance through conversational queries, enabling data-driven decision-making, operational optimization, and enhanced customer experiences within a scalable, call center-tailored analytics solution. Examples of the simple natural language queries “Which customer had positive sentiments and a complex query?” and “What are the most common issues and which agents dealt with them?” are shown in the following screenshots.
These capabilities are helpful when business leaders want to dive deep on a particular issue, empowering them to make informed decisions on various issues.
Success metrics
The primary success metric gained from this solution is boosting employee productivity, primarily by quickly understanding customer interactions from calls to uncover themes and trends while also identifying gaps and pain points in their products. Before the engagement, analysts were taking 14 days to manually go through each call transcript to retrieve insights. After engagement, Asure observed how Amazon Bedrock and Amazon Q in QuickSight could reduce this time to minutes, even seconds, to obtain both insights queried directly from all stored call transcripts and visualizations that can be used for report generation.
In the pipeline, Anthropic’s Claude 3 Haiku was used to obtain initial call metadata fields (such as summary, root cause, next steps, and sentiments) that was stored in Athena. This allowed each call transcript to be queried using natural language from Amazon Q in QuickSight, letting business analysts answer high-level questions about issues, themes, and customer and agent insights in seconds.
Pat Goepel, chairman and CEO of Asure, shares,
“In collaboration with the AWS Generative AI Innovation Center, we have improved upon a post-call analytics solution to help us identify and prioritize features that will be the most impactful for our customers. We are utilizing Amazon Bedrock, Amazon Comprehend, and Amazon Q in QuickSight to understand trends in our own customer interactions, prioritize items for product development, and detect issues sooner so that we can be even more proactive in our support for our customers. Our partnership with AWS and our commitment to be early adopters of innovative technologies like Amazon Bedrock underscore our dedication to making advanced HCM technology accessible for businesses of any size.”
Takeaways
We had the following takeaways:
Enabling chain-of-thought reasoning and specific assistant prompts for each prompt in the call metadata generation component and calling it using Anthropic’s Claude 3 Haiku improved metadata generation for each transcript. Primarily, the flexibility of Amazon Bedrock in the use of various FMs allowed full experimentation of many types of models with minimal changes. Using Amazon Bedrock can allow for the use of various models depending on the use case, making it the obvious choice for this application due to its flexibility.
Ragas metrics, particularly faithfulness, answer correctness, and answer relevance, were used to evaluate call metadata generation and individual Q&A. However, summarization required different metrics, alignment, and coverage, which didn’t require ground truth summaries. Therefore, DeepEval was used to calculate summarization metrics. Overall, the ease of integrating Amazon Bedrock allowed it to power the calculation of quantitative metrics with minimal changes to the evaluation libraries. This also allowed the use of different types of models for different evaluation libraries.
The human-in-the-loop approach can be used by SMEs to further evaluate Amazon Bedrock outputs. There is an opportunity to improve upon an Amazon Bedrock FM based on this feedback, but this was not worked on in this engagement.
The post-call analytics workflow, with the use of Amazon Bedrock, can be iterated upon in the future using features such as Amazon Bedrock Knowledge Bases to perform Q&A over a specific number of call transcripts as well as Amazon Bedrock Guardrails to detect harmful and hallucinated responses while also creating more responsible AI applications.
Amazon Q in QuickSight was able to answer natural language questions on customer analytics, root cause, and agent analytics, but some questions required reframing to get meaningful responses.
Data fields within Amazon Q in QuickSight needed to be defined properly and synonyms needed to be added to make Amazon Q more robust with natural language queries.
Security best practices
We recommend the following security guidelines for building secure applications on AWS:
Building secure machine learning environments with Amazon SageMaker
Control root access to a SageMaker notebook instance
Security in Amazon S3
Data protection in Amazon Cognito
Conclusion
In this post, we showcased how Asure used the PCA solution powered by Amazon Bedrock and Amazon Q in QuickSight to generate consumer and agent insights both at individual and aggregate levels. Specific insights included those centered around a common theme or issue. With these services, Asure was able to improve employee productivity to generate these insights in minutes instead of weeks.
This is one of the many ways builders can deliver great solutions using Amazon Bedrock and Amazon Q in QuickSight. To learn more, refer to Amazon Bedrock and Amazon Q in QuickSight.
About the Authors
Suren Gunturu is a Data Scientist working in the Generative AI Innovation Center, where he works with various AWS customers to solve high-value business problems. He specializes in building ML pipelines using large language models, primarily through Amazon Bedrock and other AWS Cloud services.
Avinash Yadav is a Deep Learning Architect at the Generative AI Innovation Center, where he designs and implements cutting-edge GenAI solutions for diverse enterprise needs. He specializes in building ML pipelines using large language models, with expertise in cloud architecture, Infrastructure as Code (IaC), and automation. His focus lies in creating scalable, end-to-end applications that leverage the power of deep learning and cloud technologies.
John Canada is the VP of Engineering at Asure Software, where he leverages his experience in building innovative, reliable, and performant solutions and his passion for AI/ML to lead a talented team dedicated to using Machine Learning to enhance the capabilities of Asure’s software and meet the evolving needs of businesses.
Yasmine Rodriguez Wakim is the Chief Technology Officer at Asure Software. She is an innovative Software Architect & Product Leader with deep expertise in creating payroll, tax, and workforce software development. As a results-driven tech strategist, she builds and leads technology vision to deliver efficient, reliable, and customer-centric software that optimizes business operations through automation.
Vidya Sagar Ravipati is a Science Manager at the Generative AI Innovation Center, where he leverages his vast experience in large-scale distributed systems and his passion for machine learning to help AWS customers across different industry verticals accelerate their AI and cloud adoption.