This post is co-authored with Joao Moura and Tony Kipkemboi from CrewAI.
The enterprise AI landscape is undergoing a seismic shift as agentic systems transition from experimental tools to mission-critical business assets. In 2025, AI agents are expected to become integral to business operations, with Deloitte predicting that 25% of enterprises using generative AI will deploy AI agents, growing to 50% by 2027. The global AI agent space is projected to surge from $5.1 billion in 2024 to $47.1 billion by 2030, reflecting the transformative potential of these technologies.
In this post, we explore how CrewAI’s open source agentic framework, combined with Amazon Bedrock, enables the creation of sophisticated multi-agent systems that can transform how businesses operate. Through practical examples and implementation details, we demonstrate how to build, deploy, and orchestrate AI agents that can tackle complex tasks with minimal human oversight. Although “agents” is the buzzword of 2025, it’s important to understand what an AI agent is and where deploying an agentic system could yield benefits.
Agentic design
An AI agent is an autonomous, intelligent system that uses large language models (LLMs) and other AI capabilities to perform complex tasks with minimal human oversight. Unlike traditional software, which follows pre-defined rules, AI agents can operate independently, learn from their environment, adapt to changing conditions, and make contextual decisions. They are designed with modular components, such as reasoning engines, memory, cognitive skills, and tools, that enable them to execute sophisticated workflows. Traditional SaaS solutions are designed for horizontal scalability and general applicability, which makes them suitable for managing repetitive tasks across diverse sectors, but they often lack domain-specific intelligence and the flexibility to address unique challenges in dynamic environments. Agentic systems, on the other hand, are designed to bridge this gap by combining the flexibility of context-aware systems with domain knowledge. Consider a software development use case AI agents can generate, evaluate, and improve code, shifting software engineers’ focus from routine coding to more complex design challenges. For example, for the CrewAI git repository, pull requests are evaluated by a set of CrewAI agents who review code based on code documentation, consistency of implementation, and security considerations. Another use case can be seen in supply chain management, where traditional inventory systems might track stock levels, but lack the capability to anticipate supply chain disruptions or optimize procurement based on industry insights. In contrast, an agentic system can use real-time data (such as weather or geopolitical risks) to proactively reroute supply chains and reallocate resources. The following illustration describes the components of an agentic AI system:
Overview of CrewAI
CrewAI is an enterprise suite that includes a Python-based open source framework. It simplifies the creation and management of AI automations using either AI flows, multi-agent systems, or a combination of both, enabling agents to work together seamlessly, tackling complex tasks through collaborative intelligence. The following figure illustrates the capability of CrewAI’s enterprise offering:
CrewAI’s design centers around the ability to build AI automation through flows and crews of AI agents. It excels at the relationship between agents and tasks, where each agent has a defined role, goal, and backstory, and can access specific tools to accomplish their objectives. This framework allows for autonomous inter-agent delegation, where agents can delegate tasks and inquire among themselves, enhancing problem-solving efficiency. This growth is fueled by the increasing demand for intelligent automation and personalized customer experiences across sectors like healthcare, finance, and retail.
CrewAI’s agents are not only automating routine tasks, but also creating new roles that require advanced skills. CrewAI’s emphasis on team collaboration, through its modular design and simplicity principles, aims to transcend traditional automation, achieving a higher level of decision simplification, creativity enhancement, and addressing complex challenges.
CrewAI key concepts
CrewAI’s architecture is built on a modular framework comprising several key components that facilitate collaboration, delegation, and adaptive decision-making in multi-agent environments. Let’s explore each component in detail to understand how they enable multi-agent interactions.
At a high level, CrewAI creates two main ways to create agentic automations: flows and crews.
Flows
CrewAI Flows provide a structured, event-driven framework to orchestrate complex, multi-step AI automations seamlessly. Flows empower users to define sophisticated workflows that combine regular code, single LLM calls, and potentially multiple crews, through conditional logic, loops, and real-time state management. This flexibility allows businesses to build dynamic, intelligent automation pipelines that adapt to changing conditions and evolving business needs. The following figure illustrates the difference between Crews and Flows:
When integrated with Amazon Bedrock, CrewAI Flows unlock even greater potential. Amazon Bedrock provides a robust foundation by enabling access to powerful foundation models (FMs).
For example, in a customer support scenario, a CrewAI Flow orchestrated through Amazon Bedrock could automatically route customer queries to specialized AI agent crews. These crews collaboratively diagnose customer issues, interact with backend systems for data retrieval, generate personalized responses, and dynamically escalate complex problems to human agents only when necessary.
Similarly, in financial services, a CrewAI Flow could monitor industry conditions, triggering agent-based analysis to proactively manage investment portfolios based on industry volatility and investor preferences.
Together, CrewAI Flows and Amazon Bedrock create a powerful synergy, enabling enterprises to implement adaptive, intelligent automation that addresses real-world complexities efficiently and at scale.
Crews
Crews in CrewAI are composed of several key components, which we discuss in this section.
Agents
Agents in CrewAI serve as autonomous entities designed to perform specific roles within a multi-agent system. These agents are equipped with various capabilities, including reasoning, memory, and the ability to interact dynamically with their environment. Each agent is defined by four main elements:
Role – Determines the agent’s function and responsibilities within the system
Backstory – Provides contextual information that guides the agent’s decision-making processes
Goals – Specifies the objectives the agent aims to accomplish
Tools – Extends the capabilities of agents to access more information and take actions
Agents in CrewAI are designed to work collaboratively, making autonomous decisions, delegating tasks, and using tools to execute complex workflows efficiently. They can communicate with each other, use external resources, and refine their strategies based on observed outcomes.
Tasks
Tasks in CrewAI are the fundamental building blocks that define specific actions an agent needs to perform to achieve its objectives. Tasks can be structured as standalone assignments or interdependent workflows that require multiple agents to collaborate. Each task includes key parameters, such as:
Description – Clearly defines what the task entails
Agent assignment – Specifies which agent is responsible for executing the task
Tools
Tools in CrewAI provide agents with extended capabilities, enabling them to perform actions beyond their intrinsic reasoning abilities. These tools allow agents to interact with APIs, access databases, execute scripts, analyze data, and even communicate with other external systems. CrewAI supports a modular tool integration system where tools can be defined and assigned to specific agents, providing efficient and context-aware decision-making.
Process
The process layer in CrewAI governs how agents interact, coordinate, and delegate tasks. It makes sure that multi-agent workflows operate seamlessly by managing task execution, communication, and synchronization among agents.
More details on CrewAI concepts can be found in the CrewAI documentation.
CrewAI enterprise suite
For businesses looking for tailored AI agent solutions, CrewAI provides an enterprise offering that includes dedicated support, advanced customization, and integration with enterprise-grade systems like Amazon Bedrock. This enables organizations to deploy AI agents at scale while maintaining security and compliance requirements.
Enterprise customers get access to comprehensive monitoring tools that provide deep visibility into agent operations. This includes detailed logging of agent interactions, performance metrics, and system health indicators. The monitoring dashboard enables teams to track agent behavior, identify bottlenecks, and optimize multi-agent workflows in real time.
Real-world enterprise impact
CrewAI customers are already seeing significant returns by adopting agentic workflows in production. In this section, we provide a few real customer examples.
Legacy code modernization
A large enterprise customer needed to modernize their legacy ABAP and APEX code base, a typically time-consuming process requiring extensive manual effort for code updates and testing.
Multiple CrewAI agents work in parallel to:
Analyze existing code base components
Generate modernized code in real time
Execute tests in production environment
Provide immediate feedback for iterations
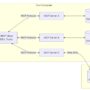
The customer achieved approximately 70% improvement in code generation speed while maintaining quality through automated testing and feedback loops. The solution was containerized using Docker for consistent deployment and scalability. The following diagram illustrates the solution architecture.
Back office automation at global CPG company
A leading CPG company automated their back-office operations by connecting their existing applications and data stores to CrewAI agents that:
Research industry conditions
Analyze pricing data
Summarize findings
Execute decisions
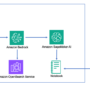
The implementation resulted in a 75% reduction in processing time by automating the entire workflow from data analysis to action execution. The following diagram illustrates the solution architecture.
Get started with CrewAI and Amazon Bedrock
Amazon Bedrock integration with CrewAI enables the creation of production-grade AI agents powered by state-of-the-art language models.
The following is a code snippet on how to set up this integration:
from crewai import Agent, Crew, Process, Task, LLM
from crewai_tools import SerperDevTool, ScrapeWebsiteTool
import os
# Configure Bedrock LLM
llm = LLM(
model=”bedrock/anthropic. anthropic.claude-3-5-sonnet-20241022-v2:0″,
aws_access_key_id=os.getenv(‘AWS_ACCESS_KEY_ID’),
aws_secret_access_key=os.getenv(‘AWS_SECRET_ACCESS_KEY’),
aws_region_name=os.getenv(‘AWS_REGION_NAME’)
)
# Create an agent with Bedrock as the LLM provider
security_analyst = Agent(
config=agents_config[‘security_analyst’],
tools=[SerperDevTool(), ScrapeWebsiteTool()],
llm=llm
)
Check out the CrewAI LLM documentation for detailed instructions on how to configure LLMs with your AI agents.
Amazon Bedrock provides several key advantages for CrewAI applications:
Access to state-of-the-art language models such as Anthropic’s Claude and Amazon Nova – These models provide the cognitive capabilities that power agent decision-making. The models enable agents to understand complex instructions, generate human-like responses, and make nuanced decisions based on context.
Enterprise-grade security and compliance features – This is crucial for organizations that need to maintain strict control over their data and enforce compliance with various regulations.
Scalability and reliability backed by AWS infrastructure – This means your agent systems can handle increasing workloads while maintaining consistent performance.
Amazon Bedrock Agents and Amazon Bedrock Knowledge Bases as native CrewAI Tools
Amazon Bedrock Agents offers you the ability to build and configure autonomous agents in a fully managed and serverless manner on Amazon Bedrock. You don’t have to provision capacity, manage infrastructure, or write custom code. Amazon Bedrock manages prompt engineering, memory, monitoring, encryption, user permissions, and API invocation. BedrockInvokeAgentTool enables CrewAI agents to invoke Amazon Bedrock agents and use their capabilities within your workflows.
With Amazon Bedrock Knowledge Bases, you can securely connect FMs and agents to your company data to deliver more relevant, accurate, and customized responses. BedrockKBRetrieverTool enables CrewAI agents to retrieve information from Amazon Bedrock Knowledge Bases using natural language queries.
The following code shows an example for Amazon Bedrock Agents integration:
from crewai import Agent, Task, Crew
from crewai_tools.aws.bedrock.agents.invoke_agent_tool import BedrockInvokeAgentTool
# Initialize the Bedrock Agents Tool
agent_tool = BedrockInvokeAgentTool(
agent_id=”your-agent-id”,
agent_alias_id=”your-agent-alias-id”
)
# Create an CrewAI agent that uses the Bedrock Agents Tool
aws_expert = Agent(
role=’AWS Service Expert’,
goal=’Help users understand AWS services and quotas’,
backstory=’I am an expert in AWS services and can provide detailed information about them.’,
tools=[agent_tool],
verbose=True
)
The following code shows an example for Amazon Bedrock Knowledge Bases integration:
# Create and configure the BedrockKB tool
kb_tool = BedrockKBRetrieverTool(
knowledge_base_id=”your-kb-id”,
number_of_results=5
)
# Create an CrewAI agent that uses the Bedrock Agents Tool
researcher = Agent(
role=’Knowledge Base Researcher’,
goal=’Find information about company policies’,
backstory=’I am a researcher specialized in retrieving and analyzing company documentation.’,
tools=[kb_tool],
verbose=True
)
Operational excellence through monitoring, tracing, and observability with CrewAI on AWS
As with any software application, achieving operational excellence is crucial when deploying agentic applications in production environments. These applications are complex systems comprising both deterministic and probabilistic components that interact either sequentially or in parallel. Therefore, comprehensive monitoring, traceability, and observability are essential factors for achieving operational excellence. This includes three key dimensions:
Application-level observability – Provides smooth operation of the entire system, including the agent orchestration framework CrewAI and potentially additional application components (such as a frontend)
Model-level observability – Provides reliable model performance (including metrics like accuracy, latency, throughput, and more)
Agent-level observability – Maintains efficient operations within single-agent or multi-agent systems
When running agent-based applications with CrewAI and Amazon Bedrock on AWS, you gain access to a comprehensive set of built-in capabilities across these dimensions:
Application-level logs – Amazon CloudWatch automatically collects application-level logs and metrics from your application code running on your chosen AWS compute platform, such as AWS Lambda, Amazon Elastic Container Service (Amazon ECS), or Amazon Elastic Compute Cloud (Amazon EC2). The CrewAI framework provides application-level logging, configured at a minimal level by default. For more detailed insights, verbose logging can be enabled at the agent or crew level by setting verbose=True during initialization.
Model-level invocation logs – Furthermore, CloudWatch automatically collects model-level invocation logs and metrics from Amazon Bedrock. This includes essential performance metrics.
Agent-level observability – CrewAI seamlessly integrates with popular third-party monitoring and observability frameworks such as AgentOps, Arize, MLFlow, LangFuse, and others. These frameworks enable comprehensive tracing, debugging, monitoring, and optimization of the agent system’s performance.
Solution overview
Each AWS service has its own configuration nuances, and missing just one detail can lead to serious vulnerabilities. Traditional security assessments often demand multiple experts, coordinated schedules, and countless manual checks. With CrewAI Agents, you can streamline the entire process, automatically mapping your resources, analyzing configurations, and generating clear, prioritized remediation steps.
The following diagram illustrates the solution architecture.
Our use case demo implements a specialized team of three agents, each with distinct responsibilities that mirror roles you might find in a professional security consulting firm:
Infrastructure mapper – Acts as our system architect, methodically documenting AWS resources and their configurations. Like an experienced cloud architect, it creates a detailed inventory that serves as the foundation for our security analysis.
Security analyst – Serves as our cybersecurity expert, examining the infrastructure map for potential vulnerabilities and researching current best practices. It brings deep knowledge of security threats and mitigation strategies.
Report writer – Functions as our technical documentation specialist, synthesizing complex findings into clear, actionable recommendations. It makes sure that technical insights are communicated effectively to both technical and non-technical stakeholders.
Implement the solution
In this section, we walk through the implementation of a security assessment multi-agent system. The code for this example is located on GitHub. Note that not all code artifacts of the solution are explicitly covered in this post.
Step 1: Configure the Amazon Bedrock LLM
We’ve saved our environment variables in an .env file in our root directory before we pass them to the LLM class:
from crewai import Agent, Crew, Process, Task, LLM
from crewai.project import CrewBase, agent, crew, task
from aws_infrastructure_security_audit_and_reporting.tools.aws_infrastructure_scanner_tool import AWSInfrastructureScannerTool
from crewai_tools import SerperDevTool, ScrapeWebsiteTool
import os
@CrewBase
class AwsInfrastructureSecurityAuditAndReportingCrew():
“””AwsInfrastructureSecurityAuditAndReporting crew”””
def __init__(self) -> None:
self.llm = LLM( model=os.getenv(‘MODEL’),
aws_access_key_id=os.getenv(‘AWS_ACCESS_KEY_ID’),
aws_secret_access_key=os.getenv(‘AWS_SECRET_ACCESS_KEY’),
aws_region_name=os.getenv(‘AWS_REGION_NAME’)
)
Step 2: Define agents
These agents are already defined in the agents.yaml file, and we’re importing them into each agent function in the crew.py file:
…
# Configure AI Agents
@agent
def infrastructure_mapper(self) -> Agent:
return Agent(
config=self.agents_config[‘infrastructure_mapper’],
tools=[AWSInfrastructureScannerTool()],
llm=self.llm
)
@agent
def security_analyst(self) -> Agent:
return Agent(
config=self.agents_config[‘security_analyst’],
tools=[SerperDevTool(), ScrapeWebsiteTool()],
llm=self.llm
)
@agent
def report_writer(self) -> Agent:
return Agent(
config=self.agents_config[‘report_writer’],
llm=self.llm
)
Step 3: Define tasks for the agents
Similar to our agents in the preceding code, we import tasks.yaml into our crew.py file:
…
# Configure Tasks for the agents
@task
def map_aws_infrastructure_task(self) -> Task:
return Task(
config=self.tasks_config[‘map_aws_infrastructure_task’]
)
@task
def exploratory_security_analysis_task(self) -> Task:
return Task(
config=self.tasks_config[‘exploratory_security_analysis_task’]
)
@task
def generate_report_task(self) -> Task:
return Task(
config=self.tasks_config[‘generate_report_task’]
)
Step 4: Create the AWS infrastructure scanner tool
This tool enables our agents to interact with AWS services and retrieve information they need to perform their analysis:
class AWSInfrastructureScannerTool(BaseTool):
name: str = “AWS Infrastructure Scanner”
description: str = (
“A tool for scanning and mapping AWS infrastructure components and their configurations. ”
“Can retrieve detailed information about EC2 instances, S3 buckets, IAM configurations, ”
“RDS instances, VPC settings, and security groups. Use this tool to gather information ”
“about specific AWS services or get a complete infrastructure overview.”
)
args_schema: Type[BaseModel] = AWSInfrastructureScannerInput
def _run(self, service: str, region: str) -> str:
try:
if service.lower() == ‘all’:
return json.dumps(self._scan_all_services(region), indent=2, cls=DateTimeEncoder)
return json.dumps(self._scan_service(service.lower(), region), indent=2, cls=DateTimeEncoder)
except Exception as e:
return f”Error scanning AWS infrastructure: {str(e)}”
def _scan_all_services(self, region: str) -> Dict:
return {
‘ec2’: self._scan_service(‘ec2’, region),
‘s3’: self._scan_service(‘s3’, region),
‘iam’: self._scan_service(‘iam’, region),
‘rds’: self._scan_service(‘rds’, region),
‘vpc’: self._scan_service(‘vpc’, region)
}
# More services can be added here
Step 5: Assemble the security audit crew
Bring the components together in a coordinated crew to execute on the tasks:
@crew
def crew(self) -> Crew:
“””Creates the AwsInfrastructureSecurityAuditAndReporting crew”””
return Crew(
agents=self.agents, # Automatically created by the @agent decorator
tasks=self.tasks, # Automatically created by the @task decorator
process=Process.sequential,
verbose=True,
)
Step 6: Run the crew
In our main.py file, we import our crew and pass in inputs to the crew to run:
def run():
“””
Run the crew.
“””
inputs = {}
AwsInfrastructureSecurityAuditAndReportingCrew().crew().kickoff(inputs=inputs)
The final report will look something like the following code:
“`markdown
### Executive Summary
In response to an urgent need for robust security within AWS infrastructure, this assessment identified several critical areas requiring immediate attention across EC2 Instances, S3 Buckets, and IAM Configurations. Our analysis revealed two high-priority issues that pose significant risks to the organization’s security posture.
### Risk Assessment Matrix
| Security Component | Risk Description | Impact | Likelihood | Priority |
|——————–|——————|———|————|———-|
| S3 Buckets | Unintended public access | High | High | Critical |
| EC2 Instances | SSRF through Metadata | High | Medium | High |
| IAM Configurations | Permission sprawl | Medium | High | Medium |
### Prioritized Remediation Roadmap
1. **Immediate (0-30 days):**
– Enforce IMDSv2 on all EC2 instances
– Conduct S3 bucket permission audit and rectify public access issues
– Adjust security group rules to eliminate broad access
2. **Short Term (30-60 days):**
– Conduct IAM policy audit to eliminate unused permissions
– Restrict RDS access to known IP ranges
“`
This implementation shows how CrewAI agents can work together to perform complex security assessments that would typically require multiple security professionals. The system is both scalable and customizable, allowing for adaptation to specific security requirements and compliance standards.
Conclusion
In this post, we demonstrated how to use CrewAI and Amazon Bedrock to build a sophisticated, automated security assessment system for AWS infrastructure. We explored how multiple AI agents can work together seamlessly to perform complex security audits, from infrastructure mapping to vulnerability analysis and report generation. Through our example implementation, we showcased how CrewAI’s framework enables the creation of specialized agents, each bringing unique capabilities to the security assessment process. By integrating with powerful language models using Amazon Bedrock, we created a system that can autonomously identify security risks, research solutions, and generate actionable recommendations.
The practical example we shared illustrates just one of many possible applications of CrewAI with Amazon Bedrock. The combination of CrewAI’s agent orchestration capabilities and advanced language models in Amazon Bedrock opens up numerous possibilities for building intelligent, autonomous systems that can tackle complex business challenges.
We encourage you to explore our code on GitHub and start building your own multi-agent systems using CrewAI and Amazon Bedrock. Whether you’re focused on security assessments, process automation, or other use cases, this powerful combination provides the tools you need to create sophisticated AI solutions that can scale with your needs.
About the Authors
Tony Kipkemboi is a Senior Developer Advocate and Partnerships Lead at CrewAI, where he empowers developers to build AI agents that drive business efficiency. A US Army veteran, Tony brings a diverse background in healthcare, data engineering, and AI. With a passion for innovation, he has spoken at events like PyCon US and contributes to the tech community through open source projects, tutorials, and thought leadership in AI agent development. Tony holds a Bachelor’s of Science in Health Sciences and is pursuing a Master’s in Computer Information Technology at the University of Pennsylvania.
João (Joe) Moura is the Founder and CEO of CrewAI, the leading agent orchestration platform powering multi-agent automations at scale. With deep expertise in generative AI and enterprise solutions, João partners with global leaders like AWS, NVIDIA, IBM, and Meta AI to drive innovative AI strategies. Under his leadership, CrewAI has rapidly become essential infrastructure for top-tier companies and developers worldwide and used by most of the F500 in the US.
Karan Singh is a Generative AI Specialist at AWS, where he works with top-tier third-party foundation model and agentic frameworks providers to develop and execute joint go-to-market strategies, enabling customers to effectively deploy and scale solutions to solve enterprise generative AI challenges. Karan holds a Bachelor’s of Science in Electrical Engineering from Manipal University, a Master’s in Science in Electrical Engineering from Northwestern University, and an MBA from the Haas School of Business at University of California, Berkeley.
Aris Tsakpinis is a Specialist Solutions Architect for Generative AI focusing on open source models on Amazon Bedrock and the broader generative AI open source ecosystem. Alongside his professional role, he is pursuing a PhD in Machine Learning Engineering at the University of Regensburg, where his research focuses on applied natural language processing in scientific domains.