Foundation model (FM) training and inference has led to a significant increase in computational needs across the industry. These models require massive amounts of accelerated compute to train and operate effectively, pushing the boundaries of traditional computing infrastructure. They require efficient systems for distributing workloads across multiple GPU accelerated servers, and optimizing developer velocity as well as performance.
Ray is an open source framework that makes it straightforward to create, deploy, and optimize distributed Python jobs. At its core, Ray offers a unified programming model that allows developers to seamlessly scale their applications from a single machine to a distributed cluster. It provides a set of high-level APIs for tasks, actors, and data that abstract away the complexities of distributed computing, enabling developers to focus on the core logic of their applications. Ray promotes the same coding patterns for both a simple machine learning (ML) experiment and a scalable, resilient production application. Ray’s key features include efficient task scheduling, fault tolerance, and automatic resource management, making it a powerful tool for building a wide range of distributed applications, from ML models to real-time data processing pipelines. With its growing ecosystem of libraries and tools, Ray has become a popular choice for organizations looking to use the power of distributed computing to tackle complex and data-intensive problems.
Amazon SageMaker HyperPod is a purpose-built infrastructure to develop and deploy large-scale FMs. SageMaker HyperPod not only provides the flexibility to create and use your own software stack, but also provides optimal performance through same spine placement of instances, as well as built-in resiliency. Combining the resiliency of SageMaker HyperPod and the efficiency of Ray provides a powerful framework to scale up your generative AI workloads.
In this post, we demonstrate the steps involved in running Ray jobs on SageMaker HyperPod.
Overview of Ray
This section provides a high-level overview of the Ray tools and frameworks for AI/ML workloads. We primarily focus on ML training use cases.
Ray is an open-source distributed computing framework designed to run highly scalable and parallel Python applications. Ray manages, executes, and optimizes compute needs across AI workloads. It unifies infrastructure through a single, flexible framework—enabling AI workloads from data processing, to model training, to model serving and beyond.
For distributed jobs, Ray provides intuitive tools for parallelizing and scaling ML workflows. It allows developers to focus on their training logic without the complexities of resource allocation, task scheduling, and inter-node communication.
At a high level, Ray is made up of three layers:
Ray Core: The foundation of Ray, providing primitives for parallel and distributed computing
Ray AI libraries:
Ray Train – A library that simplifies distributed training by offering built-in support for popular ML frameworks like PyTorch, TensorFlow, and Hugging Face
Ray Tune – A library for scalable hyperparameter tuning
Ray Serve – A library for distributed model deployment and serving
Ray clusters: A distributed computing platform where worker nodes run user code as Ray tasks and actors, generally in the cloud
In this post, we dive deep into running Ray clusters on SageMaker HyperPod. A Ray cluster consists of a single head node and a number of connected worker nodes. The head node orchestrates task scheduling, resource allocation, and communication between nodes. The ray worker nodes execute the distributed workloads using Ray tasks and actors, such as model training or data preprocessing.
Ray clusters and Kubernetes clusters pair well together. By running a Ray cluster on Kubernetes using the KubeRay operator, both Ray users and Kubernetes administrators benefit from the smooth path from development to production. For this use case, we use a SageMaker HyperPod cluster orchestrated through Amazon Elastic Kubernetes Service (Amazon EKS).
The KubeRay operator enables you to run a Ray cluster on a Kubernetes cluster. KubeRay creates the following custom resource definitions (CRDs):
RayCluster – The primary resource for managing Ray instances on Kubernetes. The nodes in a Ray cluster manifest as pods in the Kubernetes cluster.
RayJob – A single executable job designed to run on an ephemeral Ray cluster. It serves as a higher-level abstraction for submitting tasks or batches of tasks to be executed by the Ray cluster. A RayJob also manages the lifecycle of the Ray cluster, making it ephemeral by automatically spinning up the cluster when the job is submitted and shutting it down when the job is complete.
RayService – A Ray cluster and a Serve application that runs on top of it into a single Kubernetes manifest. It allows for the deployment of Ray applications that need to be exposed for external communication, typically through a service endpoint.
For the remainder of this post, we don’t focus on RayJob or RayService; we focus on creating a persistent Ray cluster to run distributed ML training jobs.
When Ray clusters are paired with SageMaker HyperPod clusters, Ray clusters unlock enhanced resiliency and auto-resume capabilities, which we will dive deeper into later in this post. This combination provides a solution for handling dynamic workloads, maintaining high availability, and providing seamless recovery from node failures, which is crucial for long-running jobs.
Overview of SageMaker HyperPod
In this section, we introduce SageMaker HyperPod and its built-in resiliency features to provide infrastructure stability.
Generative AI workloads such as training, inference, and fine-tuning involve building, maintaining, and optimizing large clusters of thousands of GPU accelerated instances. For distributed training, the goal is to efficiently parallelize workloads across these instances in order to maximize cluster utilization and minimize time to train. For large-scale inference, it’s important to minimize latency, maximize throughput, and seamlessly scale across those instances for the best user experience. SageMaker HyperPod is a purpose-built infrastructure to address these needs. It removes the undifferentiated heavy lifting involved in building, maintaining, and optimizing a large GPU accelerated cluster. It also provides flexibility to fully customize your training or inference environment and compose your own software stack. You can use either Slurm or Amazon EKS for orchestration with SageMaker HyperPod.
Due to their massive size and the need to train on large amounts of data, FMs are often trained and deployed on large compute clusters composed of thousands of AI accelerators such as GPUs and AWS Trainium. A single failure in one of these thousand accelerators can interrupt the entire training process, requiring manual intervention to identify, isolate, debug, repair, and recover the faulty node in the cluster. This workflow can take several hours for each failure and as the scale of the cluster grows, it’s common to see a failure every few days or even every few hours. SageMaker HyperPod provides resiliency against infrastructure failures by applying agents that continuously run health checks on cluster instances, fix the bad instances, reload the last valid checkpoint, and resume the training—without user intervention. As a result, you can train your models up to 40% faster. You can also SSH into an instance in the cluster for debugging and gather insights on hardware-level optimization during multi-node training. Orchestrators like Slurm or Amazon EKS facilitate efficient allocation and management of resources, provide optimal job scheduling, monitor resource utilization, and automate fault tolerance.
Solution overview
This section provides an overview of how to run Ray jobs for multi-node distributed training on SageMaker HyperPod. We go over the architecture and the process of creating a SageMaker HyperPod cluster, installing the KubeRay operator, and deploying a Ray training job.
Although this post provides a step-by-step guide to manually create the cluster, feel free to check out the aws-do-ray project, which aims to simplify the deployment and scaling of distributed Python application using Ray on Amazon EKS or SageMaker HyperPod. It uses Docker to containerize the tools necessary to deploy and manage Ray clusters, jobs, and services. In addition to the aws-do-ray project, we’d like to highlight the Amazon SageMaker Hyperpod EKS workshop, which offers an end-to-end experience for running various workloads on SageMaker Hyperpod clusters. There are multiple examples of training and inference workloads from the GitHub repository awsome-distributed-training.
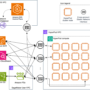
As introduced earlier in this post, KubeRay simplifies the deployment and management of Ray applications on Kubernetes. The following diagram illustrates the solution architecture.
Create a SageMaker HyperPod cluster
Prerequisites
Before deploying Ray on SageMaker HyperPod, you need a HyperPod cluster:
This is a one click deployment to set up your EKS SageMaker HyperPod cluster using CloudFormation. Please deploy this stack. Source is from Amazon EKS Support in SageMaker HyperPod Workshop. Now, you can proceed directly to section Create an FSx for Lustre Shared File System.
If you prefer to deploy HyperPod on an existing EKS cluster, please follow the instructions here which include:
EKS cluster – You can associate SageMaker HyperPod compute to an existing EKS cluster that satisfies the set of prerequisites. Alternatively and recommended, you can deploy a ready-made EKS cluster with a single AWS CloudFormation template. Refer to the GitHub repo for instructions on setting up an EKS cluster.
Custom resources – Running multi-node distributed training requires various resources, such as device plugins, Container Storage Interface (CSI) drivers, and training operators, to be pre-deployed on the EKS cluster. You also need to deploy additional resources for the health monitoring agent and deep health check. HyperPodHelmCharts simplify the process using Helm, one of most commonly used package mangers for Kubernetes. Refer to Install packages on the Amazon EKS cluster using Helm for installation instructions.
The following provide an example workflow for creating a HyperPod cluster on an existing EKS Cluster after deploying prerequisites. This is for reference only and not required for the quick deploy option.
cat > cluster-config.json << EOL
{
“ClusterName”: “ml-cluster”,
“Orchestrator”: {
“Eks”: {
“ClusterArn”: “${EKS_CLUSTER_ARN}”
}
},
“InstanceGroups”: [
{
“InstanceGroupName”: “worker-group-1”,
“InstanceType”: “ml.p5.48xlarge”,
“InstanceCount”: 4,
“LifeCycleConfig”: {
“SourceS3Uri”: “s3://amzn-s3-demo-bucket”,
“OnCreate”: “on_create.sh”
},
“ExecutionRole”: “${EXECUTION_ROLE}”,
“ThreadsPerCore”: 1,
“OnStartDeepHealthChecks”: [
“InstanceStress”,
“InstanceConnectivity”
]
},
{
“InstanceGroupName”: “head-group”,
“InstanceType”: “ml.m5.2xlarge”,
“InstanceCount”: 1,
“LifeCycleConfig”: {
“SourceS3Uri”: “s3://amzn-s3-demo-bucket”,
“OnCreate”: “on_create.sh”
},
“ExecutionRole”: “${EXECUTION_ROLE}”,
“ThreadsPerCore”: 1,
}
],
“VpcConfig”: {
“SecurityGroupIds”: [
“${SECURITY_GROUP_ID}”
],
“Subnets”: [
“${SUBNET_ID}”
]
},
“NodeRecovery”: “Automatic”
}
EOL
The provided configuration file contains two key highlights:
“OnStartDeepHealthChecks”: [“InstanceStress”, “InstanceConnectivity”] – Instructs SageMaker HyperPod to conduct a deep health check whenever new GPU or Trainium instances are added
“NodeRecovery”: “Automatic” – Enables SageMaker HyperPod automated node recovery
You can create a SageMaker HyperPod compute with the following AWS Command Line Interface (AWS CLI) command (AWS CLI version 2.17.47 or newer is required):
aws sagemaker create-cluster
–cli-input-json file://cluster-config.json
{
“ClusterArn”: “arn:aws:sagemaker:us-east-2:xxxxxxxxxx:cluster/wccy5z4n4m49”
}
To verify the cluster status, you can use the following command:
aws sagemaker list-clusters –output table
This command displays the cluster details, including the cluster name, status, and creation time:
——————————————————————————————————————————————————
| ListClusters |
+—————————————————————————————————————————————————-+
|| ClusterSummaries ||
|+—————————————————————-+—————————+—————-+————————————+|
|| ClusterArn | ClusterName | ClusterStatus | CreationTime ||
|+—————————————————————-+—————————+—————-+————————————+|
|| arn:aws:sagemaker:us-west-2:xxxxxxxxxxxx:cluster/zsmyi57puczf | ml-cluster | InService | 2025-03-03T16:45:05.320000+00:00 ||
|+—————————————————————-+—————————+—————-+————————————+|
Alternatively, you can verify the cluster status on the SageMaker console. After a brief period, you can observe that the status for the nodes transitions to Running.
Create an FSx for Lustre shared file system
For us to deploy the Ray cluster, we need the SageMaker HyperPod cluster to be up and running, and additionally we need a shared storage volume (for example, an Amazon FSx for Lustre file system). This is a shared file system that the SageMaker HyperPod nodes can access. This file system can be provisioned statically before launching your SageMaker HyperPod cluster or dynamically afterwards.
Specifying a shared storage location (such as cloud storage or NFS) is optional for single-node clusters, but it is required for multi-node clusters. Using a local path will raise an error during checkpointing for multi-node clusters.
The Amazon FSx for Lustre CSI driver uses IAM roles for service accounts (IRSA) to authenticate AWS API calls. To use IRSA, an IAM OpenID Connect (OIDC) provider needs to be associated with the OIDC issuer URL that comes provisioned your EKS cluster.
Create an IAM OIDC identity provider for your cluster with the following command:
eksctl utils associate-iam-oidc-provider –cluster $EKS_CLUSTER_NAME –approve
Deploy the FSx for Lustre CSI driver:
helm repo add aws-fsx-csi-driver https://kubernetes-sigs.github.io/aws-fsx-csi-driver
helm repo update
helm upgrade –install aws-fsx-csi-driver aws-fsx-csi-driver/aws-fsx-csi-driver
–namespace kube-system
This Helm chart includes a service account named fsx-csi-controller-sa that gets deployed in the kube-system namespace.
Use the eksctl CLI to create an AWS Identity and Access Management (IAM) role bound to the service account used by the driver, attaching the AmazonFSxFullAccess AWS managed policy:
eksctl create iamserviceaccount
–name fsx-csi-controller-sa
–override-existing-serviceaccounts
–namespace kube-system
–cluster $EKS_CLUSTER_NAME
–attach-policy-arn arn:aws:iam::aws:policy/AmazonFSxFullAccess
–approve
–role-name AmazonEKSFSxLustreCSIDriverFullAccess
–region $AWS_REGION
The –override-existing-serviceaccounts flag lets eksctl know that the fsx-csi-controller-sa service account already exists on the EKS cluster, so it skips creating a new one and updates the metadata of the current service account instead.
Annotate the driver’s service account with the Amazon Resource Name (ARN) of the AmazonEKSFSxLustreCSIDriverFullAccess IAM role that was created:
SA_ROLE_ARN=$(aws iam get-role –role-name AmazonEKSFSxLustreCSIDriverFullAccess –query ‘Role.Arn’ –output text)
kubectl annotate serviceaccount -n kube-system fsx-csi-controller-sa
eks.amazonaws.com/role-arn=${SA_ROLE_ARN} –overwrite=true
This annotation lets the driver know what IAM role it should use to interact with the FSx for Lustre service on your behalf.
Verify that the service account has been properly annotated:
kubectl get serviceaccount -n kube-system fsx-csi-controller-sa -o yaml
Restart the fsx-csi-controller deployment for the changes to take effect:
kubectl rollout restart deployment fsx-csi-controller -n kube-system
The FSx for Lustre CSI driver presents you with two options for provisioning a file system:
Dynamic provisioning – This option uses Persistent Volume Claims (PVCs) in Kubernetes. You define a PVC with desired storage specifications. The CSI driver automatically provisions the FSx for Lustre file system for you based on the PVC request. This allows for straightforward scaling and eliminates the need to manually create file systems.
Static provisioning – In this method, you manually create the FSx for Lustre file system before using the CSI driver. You will need to configure details like subnet ID and security groups for the file system. Then, you can use the driver to mount this pre-created file system within your container as a volume.
For this example, we use dynamic provisioning. Start by creating a storage class that uses the fsx.csi.aws.com provisioner:
cat <<EOF > storageclass.yaml
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: fsx-sc
provisioner: fsx.csi.aws.com
parameters:
subnetId: ${SUBNET_ID}
securityGroupIds: ${SECURITYGROUP_ID}
deploymentType: PERSISTENT_2
automaticBackupRetentionDays: “0”
copyTagsToBackups: “true”
perUnitStorageThroughput: “250”
dataCompressionType: “LZ4”
fileSystemTypeVersion: “2.12”
mountOptions:
– flock
EOF
kubectl apply -f storageclass.yaml
SUBNET_ID: The subnet ID that the FSx for Lustre filesystem. Should be the same private subnet that was used for HyperPod creation.
SECURITYGROUP_ID: The security group IDs that will be attached to the file system. Should be the same Security Group ID that is used in HyperPod and EKS.
Next, create a PVC that uses the fsx-claim storage claim:
cat <<EOF > pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: fsx-claim
spec:
accessModes:
– ReadWriteMany
storageClassName: fsx-sc
resources:
requests:
storage: 1200Gi
EOF
kubectl apply -f pvc.yaml
This PVC will start the dynamic provisioning of an FSx for Lustre file system based on the specifications provided in the storage class.
Create the Ray cluster
Now that we have both the SageMaker HyperPod cluster and the FSx for Lustre file system created, we can set up the Ray cluster:
Set up dependencies. We will create a new namespace in our Kubernetes cluster and install the KubeRay operator using a Helm chart.
We recommend using KubeRay operator version 1.2.0 or higher, which supports automatic Ray Pod eviction and replacement in case of failures (for example, hardware issues on EKS or SageMaker HyperPod nodes).
# Create KubeRay namespace
kubectl create namespace kuberay
# Deploy the KubeRay operator with the Helm chart repository
helm repo add kuberay https://ray-project.github.io/kuberay-helm/
helm repo update
#Install both CRDs and Kuberay operator v1.2.0
helm install kuberay-operator kuberay/kuberay-operator –version 1.2.0 –namespace kuberay
# Kuberay operator pod will be deployed onto head pod
kubectl get pods –namespace kuberay
Create a Ray Container Image for the Ray Cluster manifest. With the recent deprecation of the `rayproject/ray-ml` images starting from Ray version 2.31.0, it’s necessary to create a custom container image for our Ray cluster. Therefore, we will build on top of the `rayproject/ray:2.42.1-py310-gpu` image, which has all necessary Ray dependencies, and include our training dependencies to build our own custom image. Please feel free to modify this Dockerfile as you wish.
First, create a Dockerfile that builds upon the base Ray GPU image and includes only the necessary dependencies:
cat <<EOF > Dockerfile
FROM rayproject/ray:2.42.1-py310-gpu
# Install Python dependencies for PyTorch, Ray, Hugging Face, and more
RUN pip install –no-cache-dir
torch torchvision torchaudio
numpy
pytorch-lightning
transformers datasets evaluate tqdm click
ray[train] ray[air]
ray[train-torch] ray[train-lightning]
torchdata
torchmetrics
torch_optimizer
accelerate
scikit-learn
Pillow==9.5.0
protobuf==3.20.3
RUN pip install –upgrade datasets transformers
# Set the user
USER ray
WORKDIR /home/ray
# Verify ray installation
RUN which ray &&
ray –-version
# Default command
CMD [ “/bin/bash” ]
EOF
Then, build and push the image to your container registry (Amazon ECR) using the provided script:
export AWS_REGION=$(aws configure get region)
export ACCOUNT=$(aws sts get-caller-identity –query Account –output text)
export REGISTRY=${ACCOUNT}.dkr.ecr.${AWS_REGION}.amazonaws.com/
echo “This process may take 10-15 minutes to complete…”
echo “Building image…”
docker build –platform linux/amd64 -t ${REGISTRY}aws-ray-custom:latest .
# Create registry if needed
REGISTRY_COUNT=$(aws ecr describe-repositories | grep “aws-ray-custom” | wc -l)
if [ “$REGISTRY_COUNT” == “0” ]; then
aws ecr create-repository –repository-name aws-ray-custom
fi
# Login to registry
echo “Logging in to $REGISTRY …”
aws ecr get-login-password –region $AWS_REGION| docker login –username AWS –password-stdin $REGISTRY
echo “Pushing image to $REGISTRY …”
# Push image to registry
docker image push ${REGISTRY}aws-ray-custom:latest
Now, our Ray container image is in Amazon ECR with all necessary Ray dependencies, as well as code library dependencies.
Create a Ray cluster manifest. We use a Ray cluster to host our training jobs. The Ray cluster is the primary resource for managing Ray instances on Kubernetes. It represents a cluster of Ray nodes, including a head node and multiple worker nodes. The Ray cluster CRD determines how the Ray nodes are set up, how they communicate, and how resources are allocated among them. The nodes in a Ray cluster manifest as pods in the EKS or SageMaker HyperPod cluster.
Note that there are two distinct sections in the cluster manifest. While the `headGroupSpec` defines the head node of the Ray Cluster, the `workerGroupSpecs` define the worker nodes of the Ray Cluster. While a job could technically run on the Head node as well, it is common to separate the head node from the actual worker nodes where jobs are executed. Therefore, the instance for the head node can typically be a smaller instance (i.e. we chose a m5.2xlarge). Since the head node also manages cluster-level metadata, it can be beneficial to have it run on a non-GPU node to minimize the risk of node failure (as GPU can be a potential source of node failure).
cat <<‘EOF’ > raycluster.yaml
apiVersion: ray.io/v1alpha1
kind: RayCluster
metadata:
name: rayml
labels:
controller-tools.k8s.io: “1.0”
spec:
# Ray head pod template
headGroupSpec:
# The `rayStartParams` are used to configure the `ray start` command.
# See https://github.com/ray-project/kuberay/blob/master/docs/guidance/rayStartParams.md for the default settings of `rayStartParams` in KubeRay.
# See https://docs.ray.io/en/latest/cluster/cli.html#ray-start for all available options in `rayStartParams`.
rayStartParams:
dashboard-host: ‘0.0.0.0’
#pod template
template:
spec:
# nodeSelector:
#node.kubernetes.io/instance-type: “ml.m5.2xlarge”
securityContext:
runAsUser: 0
runAsGroup: 0
fsGroup: 0
containers:
– name: ray-head
image: ${REGISTRY}aws-ray-custom:latest ## IMAGE: Here you may choose which image your head pod will run
env: ## ENV: Here is where you can send stuff to the head pod
– name: RAY_GRAFANA_IFRAME_HOST ## PROMETHEUS AND GRAFANA
value: http://localhost:3000
– name: RAY_GRAFANA_HOST
value: http://prometheus-grafana.prometheus-system.svc:80
– name: RAY_PROMETHEUS_HOST
value: http://prometheus-kube-prometheus-prometheus.prometheus-system.svc:9090
lifecycle:
preStop:
exec:
command: [“/bin/sh”,”-c”,”ray stop”]
resources:
limits: ## LIMITS: Set resource limits for your head pod
cpu: 1
memory: 8Gi
requests: ## REQUESTS: Set resource requests for your head pod
cpu: 1
memory: 8Gi
ports:
– containerPort: 6379
name: gcs-server
– containerPort: 8265 # Ray dashboard
name: dashboard
– containerPort: 10001
name: client
– containerPort: 8000
name: serve
volumeMounts: ## VOLUMEMOUNTS
– name: fsx-storage
mountPath: /fsx
– name: ray-logs
mountPath: /tmp/ray
volumes:
– name: ray-logs
emptyDir: {}
– name: fsx-storage
persistentVolumeClaim:
claimName: fsx-claim
workerGroupSpecs:
# the pod replicas in this group typed worker
– replicas: 4 ## REPLICAS: How many worker pods you want
minReplicas: 1
maxReplicas: 10
# logical group name, for this called small-group, also can be functional
groupName: gpu-group
rayStartParams:
num-gpus: “8”
#pod template
template:
spec:
#nodeSelector:
# node.kubernetes.io/instance-type: “ml.p5.48xlarge”
securityContext:
runAsUser: 0
runAsGroup: 0
fsGroup: 0
containers:
– name: ray-worker
image: ${REGISTRY}aws-ray-custom:latest ## IMAGE: Here you may choose which image your head node will run
env:
lifecycle:
preStop:
exec:
command: [“/bin/sh”,”-c”,”ray stop”]
resources:
limits: ## LIMITS: Set resource limits for your worker pods
nvidia.com/gpu: 8
#vpc.amazonaws.com/efa: 32
requests: ## REQUESTS: Set resource requests for your worker pods
nvidia.com/gpu: 8
#vpc.amazonaws.com/efa: 32
volumeMounts: ## VOLUMEMOUNTS
– name: ray-logs
mountPath: /tmp/ray
– name: fsx-storage
mountPath: /fsx
volumes:
– name: fsx-storage
persistentVolumeClaim:
claimName: fsx-claim
– name: ray-logs
emptyDir: {}
EOF
Deploy the Ray cluster:
envsubst < raycluster.yaml | kubectl apply -f –
Optionally, expose the Ray dashboard using port forwarding:
# Gets name of kubectl service that runs the head pod
export SERVICEHEAD=$(kubectl get service | grep head-svc | awk ‘{print $1}’ | head -n 1)
# Port forwards the dashboard from the head pod service
kubectl port-forward –address 0.0.0.0 service/${SERVICEHEAD} 8265:8265 > /dev/null 2>&1 &
Now, you can visit http://localhost:8265/ to visit the Ray Dashboard.
To launch a training job, there are a few options:
Use the Ray jobs submission SDK, where you can submit jobs to the Ray cluster through the Ray dashboard port (8265 by default) where Ray listens for job requests. To learn more, see Quickstart using the Ray Jobs CLI.
Execute a Ray job in the head pod where you exec directly into the head pod and then submit your job. To learn more, see RayCluster Quickstart.
For this example, we use the first method and submit the job through the SDK. Therefore, we simply run from a local environment where the training code is available in –working-dir. Relative to this path, we specify the main training Python script located at –train.py Within the working-dir folder, we can also include additional scripts we might need to run the training.
The fsdp-ray.py example is located in aws-do-ray/Container-Root/ray/raycluster/jobs/fsdp-ray/fsdp-ray.py in the aws-do-ray GitHub repo.
# Within jobs/ folder
ray job submit –address http://localhost:8265 –working-dir “fsdp-ray” — python3 fsdp-ray.py
For our Python training script to run, we need to make sure our training scripts are correctly set up to use Ray. This includes the following steps:
Configure a model to run distributed and on the correct CPU/GPU device
Configure a data loader to shard data across the workers and place data on the correct CPU or GPU device
Configure a training function to report metrics and save checkpoints
Configure scaling and CPU or GPU resource requirements for a training job
Launch a distributed training job with a TorchTrainer class
For further details on how to adjust your existing training script to get the most out of Ray, refer to the Ray documentation.
The following diagram illustrates the complete architecture you have built after completing these steps.
Implement training job resiliency with the job auto resume functionality
Ray is designed with robust fault tolerance mechanisms to provide resilience in distributed systems where failures are inevitable. These failures generally fall into two categories: application-level failures, which stem from bugs in user code or external system issues, and system-level failures, caused by node crashes, network disruptions, or internal bugs in Ray. To address these challenges, Ray provides tools and strategies that enable applications to detect, recover, and adapt seamlessly, providing reliability and performance in distributed environments. In this section, we look at two of the most common types of failures, and how to implement fault tolerance in them that SageMaker HyperPod compliments: Ray Train worker failures and Ray worker node failures.
Ray Train worker – This is a worker process specifically used for training tasks within Ray Train, Ray’s distributed training library. These workers handle individual tasks or shards of a distributed training job. Each worker is responsible for processing a portion of the data, training a subset of the model, or performing computation during distributed training. They are coordinated by the Ray Train orchestration logic to collectively train a model.
Ray worker node – At the Ray level, this is a Ray node in a Ray cluster. It’s part of the Ray cluster infrastructure and is responsible for running tasks, actors, and other processes as orchestrated by the Ray head node. Each worker node can host multiple Ray processes that execute tasks or manage distributed objects. At the Kubernetes level, a Ray worker node is a Kubernetes pod that is managed by a KubeRay operator. For this post, we will be talking about the Ray worker nodes at the Kubernetes level, so we will refer to them as pods.
At the time of writing, there are no official updates regarding head pod fault tolerance and auto resume capabilities. Though head pod failures are rare, in the unlikely event of such a failure, you will need to manually restart your training job. However, you can still resume progress from the last saved checkpoint. To minimize the risk of hardware-related head pod failures, it’s advised to place the head pod on a dedicated, CPU-only SageMaker HyperPod node, because GPU failures are a common training job failure point.
Ray Train worker failures
Ray Train is designed with fault tolerance to handle worker failures, such as RayActorErrors. When a failure occurs, the affected workers are stopped, and new ones are automatically started to maintain operations. However, for training progress to continue seamlessly after a failure, saving and loading checkpoints is essential. Without proper checkpointing, the training script will restart, but all progress will be lost. Checkpointing is therefore a critical component of Ray Train’s fault tolerance mechanism and needs to be implemented in your code.
Automatic recovery
When a failure is detected, Ray shuts down failed workers and provisions new ones. Although this happens, we can tell the training function to always keep retrying until training can continue. Each instance of recovery from a worker failure is considered a retry. We can set the number of retries through the max_failures attribute of the FailureConfig, which is set in the RunConfig passed to the Trainer (for example, TorchTrainer). See the following code:
from ray.train import RunConfig, FailureConfig
# Tries to recover a run up to this many times.
run_config = RunConfig(failure_config=FailureConfig(max_failures=2))
# No limit on the number of retries.
run_config = RunConfig(failure_config=FailureConfig(max_failures=-1))
For more information, see Handling Failures and Node Preemption.
Checkpoints
A checkpoint in Ray Train is a lightweight interface representing a directory stored either locally or remotely. For example, a cloud-based checkpoint might point to s3://my-bucket/checkpoint-dir, and a local checkpoint might point to /tmp/checkpoint-dir. To learn more, see Saving checkpoints during training.
To save a checkpoint in the training loop, you first need to write your checkpoint to a local directory, which can be temporary. When saving, you can use checkpoint utilities from other frameworks like torch.save, pl.Trainer.save_checkpoint, accelerator.save_model, save_pretrained, tf.keras.Model.save, and more. Then you create a checkpoint from the directory using Checkpoint.from_directory. Finally, report the checkpoint to Ray Train using ray.train.report(metrics, checkpoint=…). The metrics reported alongside the checkpoint are used to keep track of the best-performing checkpoints. Reporting will upload the checkpoint to persistent storage.
If you save checkpoints with ray.train.report(…, checkpoint=…) and run on a multi-node cluster, Ray Train will raise an error if NFS or cloud storage is not set up. This is because Ray Train expects all workers to be able to write the checkpoint to the same persistent storage location.
Finally, clean up the local temporary directory to free up disk space (for example, by exiting the tempfile.TemporaryDirectory context). We can save a checkpoint every epoch or every few iterations.
The following diagram illustrates this setup.
The following code is an example of saving checkpoints using native PyTorch:
import os
import tempfile
import numpy as np
import torch
import torch.nn as nn
from torch.optim import Adam
import ray.train.torch
from ray import train
from ray.train import Checkpoint, ScalingConfig
from ray.train.torch import TorchTrainer
def train_func(config):
n = 100
# create a toy dataset
# data : X – dim = (n, 4)
# target : Y – dim = (n, 1)
X = torch.Tensor(np.random.normal(0, 1, size=(n, 4)))
Y = torch.Tensor(np.random.uniform(0, 1, size=(n, 1)))
# toy neural network : 1-layer
# Wrap the model in DDP
model = ray.train.torch.prepare_model(nn.Linear(4, 1))
criterion = nn.MSELoss()
optimizer = Adam(model.parameters(), lr=3e-4)
for epoch in range(config[“num_epochs”]):
y = model.forward(X)
loss = criterion(y, Y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
metrics = {“loss”: loss.item()}
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
checkpoint = None
should_checkpoint = epoch % config.get(“checkpoint_freq”, 1) == 0
# In standard DDP training, where the model is the same across all ranks,
# only the global rank 0 worker needs to save and report the checkpoint
if train.get_context().get_world_rank() == 0 and should_checkpoint:
torch.save(
model.module.state_dict(), # NOTE: Unwrap the model.
os.path.join(temp_checkpoint_dir, “model.pt”),
)
checkpoint = Checkpoint.from_directory(temp_checkpoint_dir)
train.report(metrics, checkpoint=checkpoint)
trainer = TorchTrainer(
train_func,
train_loop_config={“num_epochs”: 5},
scaling_config=ScalingConfig(num_workers=2),
)
result = trainer.fit()
Ray Train also comes with CheckpointConfig, a way to configure checkpointing options:
from ray.train import RunConfig, CheckpointConfig
# Example 1: Only keep the 2 *most recent* checkpoints and delete the others.
run_config = RunConfig(checkpoint_config=CheckpointConfig(num_to_keep=2))
# Example 2: Only keep the 2 *best* checkpoints and delete the others.
run_config = RunConfig(
checkpoint_config=CheckpointConfig(
num_to_keep=2,
# *Best* checkpoints are determined by these params:
checkpoint_score_attribute=”mean_accuracy”,
checkpoint_score_order=”max”,
),
# This will store checkpoints on S3.
storage_path=”s3://remote-bucket/location”,
)
To restore training state from a checkpoint if your training job were to fail and retry, you should modify your training loop to auto resume and then restore a Ray Train job. By pointing to the path of your saved checkpoints, you can restore your trainer and continue training. Here’s a quick example:
from ray.train.torch import TorchTrainer
restored_trainer = TorchTrainer.restore(
path=”~/ray_results/dl_trainer_restore”, # Can also be a cloud storage path like S3
datasets=get_datasets(),
)
result = restored_trainer.fit()
To streamline restoration, you can add auto resume logic to your script. This checks if a valid experiment directory exists and restores the trainer if available. If not, it starts a new experiment:
experiment_path = “~/ray_results/dl_restore_autoresume”
if TorchTrainer.can_restore(experiment_path):
trainer = TorchTrainer.restore(experiment_path, datasets=get_datasets())
else:
trainer = TorchTrainer(
train_loop_per_worker=train_loop_per_worker,
datasets=get_datasets(),
scaling_config=train.ScalingConfig(num_workers=2),
run_config=train.RunConfig(
storage_path=”~/ray_results”,
name=”dl_restore_autoresume”,
),
)
result = trainer.fit()
To summarize, to provide fault tolerance and auto resume when using Ray Train libraries, set your max_failures parameter in the FailureConfig (we recommend setting it to -1 to make sure it will keep retrying until the SageMaker HyperPod node is rebooted or replaced), and make sure you have enabled checkpointing in your code.
Ray worker pod failures
In addition to the aforementioned mechanisms to recover from Ray Train worker failures, Ray also provides fault tolerance at the worker pod level. When a worker pod fails (this includes scenarios in which the raylet process fails), the running tasks and actors on it will fail and the objects owned by worker processes of this pod will be lost. In this case, the tasks, actors, and objects fault tolerance mechanisms will start and try to recover the failures using other worker pods.
These mechanisms will be implicitly handled by the Ray Train library. To learn more about the underlying fault tolerance at the tasks, actors, objects (implemented at the Ray Core level), see Fault Tolerance.
In practice, this means that in case of a worker pod failure, the following occurs:
If there is a free worker pod in the Ray cluster, Ray will recover the failed worker pod by replacing it with the free worker pod.
If there is no free worker pod, but in the underlying SageMaker HyperPod cluster there are free SageMaker HyperPod nodes, Ray will schedule a new worker pod onto one of the free SageMaker HyperPod nodes. This pod will join the running Ray cluster and the failure will be recovered using this new worker pod.
In the context of KubeRay, Ray worker nodes are represented by Kubernetes pods, and failures at this level can include issues such as pod eviction or preemption caused by software-level factors.
However, another critical scenario to consider is hardware failures. If the underlying SageMaker HyperPod node becomes unavailable due to a hardware issue, such as a GPU error, it would inevitably cause the Ray worker pod running on that node to fail as well. Now the fault tolerance and auto-healing mechanisms of your SageMaker HyperPod cluster start and will reboot or replace the faulty node. After the new healthy node is added into the SageMaker HyperPod cluster, Ray will schedule a new worker pod onto the SageMaker HyperPod node and recover the interrupted training. In this case, both the Ray fault tolerance mechanism and the SageMaker HyperPod resiliency features work together seamlessly and make sure that even in case of a hardware failure, your ML training workload can auto resume and pick up from where it was interrupted.
As you have seen, there are various built-in resiliency and fault-tolerance mechanisms that allow your Ray Train workload on SageMaker HyperPod to recover and auto resume. Because these mechanisms will essentially recover by restarting the training job, it is crucial that checkpointing is implemented in the training script. It is also generally advised to save the checkpoints on a shared and persistent path, such as an Amazon Simple Storage Service (Amazon S3) bucket or FSx for Lustre file system.
Clean up
To delete your SageMaker HyperPod cluster created in this post, you can either use the SageMaker AI console or use the following AWS CLI command:
aws sagemaker delete-cluster –cluster-name <cluster_name>
Cluster deletion will take a few minutes. You can confirm successful deletion after you see no clusters on the SageMaker AI console.
If you used the CloudFormation stack to create resources, you can delete it using the following command:
aws cloudformation delete-stack –stack-name <stack_name>
Conclusion
This post demonstrated how to set up and deploy Ray clusters on SageMaker HyperPod, highlighting key considerations such as storage configuration and fault tolerance and auto resume mechanisms.
Running Ray jobs on SageMaker HyperPod offers a powerful solution for distributed AI/ML workloads, combining the flexibility of Ray with the robust infrastructure of SageMaker HyperPod. This integration provides enhanced resiliency and auto resume capabilities, which are crucial for long-running and resource-intensive tasks. By using Ray’s distributed computing framework and the built-in features of SageMaker HyperPod, you can efficiently manage complex ML workflows, specifically training workloads as covered in this post. As AI/ML workloads continue to grow in scale and complexity, the combination of Ray and SageMaker HyperPod offers a scalable, resilient, and efficient platform for tackling the most demanding computational challenges in machine learning.
To get started with SageMaker HyperPod, refer to the Amazon EKS Support in Amazon SageMaker HyperPod workshop and the Amazon SageMaker HyperPod Developer Guide. To learn more about the aws-do-ray framework, refer to the GitHub repo.
About the Authors
Mark Vinciguerra is an Associate Specialist Solutions Architect at Amazon Web Services (AWS) based in New York. He focuses on the Automotive and Manufacturing sector, specializing in helping organizations architect, optimize, and scale artificial intelligence and machine learning solutions, with particular expertise in autonomous vehicle technologies. Prior to AWS, he went to Boston University and graduated with a degree in Computer Engineering.
Florian Stahl is a Worldwide Specialist Solutions Architect at AWS, based in Hamburg, Germany. He specializes in Artificial Intelligence, Machine Learning, and Generative AI solutions, helping customers optimize and scale their AI/ML workloads on AWS. With a background as a Data Scientist, Florian focuses on working with customers in the Autonomous Vehicle space, bringing deep technical expertise to help organizations design and implement sophisticated machine learning solutions. He works closely with customers worldwide to transform their AI initiatives and maximize the value of their machine learning investments on AWS.
Anoop Saha is a Sr GTM Specialist at Amazon Web Services (AWS) focusing on Gen AI model training and inference. He is partnering with top foundation model builders, strategic customers, and AWS service teams to enable distributed training and inference at scale on AWS and lead joint GTM motions. Before AWS, Anoop has held several leadership roles at startups and large corporations, primarily focusing on silicon and system architecture of AI infrastructure.
Alex Iankoulski is a Principal Solutions Architect, ML/AI Frameworks, who focuses on helping customers orchestrate their AI workloads using containers and accelerated computing infrastructure on AWS. He is also the author of the open source do framework and a Docker captain who loves applying container technologies to accelerate the pace of innovation while solving the world’s biggest challenges.