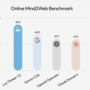
How do you turn slow, manual click work across browsers and desktops into a reliable, automated system that can actually use a computer for you at scale? Lux is the latest example of computer use agents moving from research demo to infrastructure. OpenAGI Foundation team has released Lux, a foundation model that operates real desktops and browsers and reports a score of 83.6 on the Online Mind2Web benchmark, which covers more than 300 real world computer use tasks. This is ahead of Google Gemini CUA at 69.0, OpenAI Operator at 61.3 and Anthropic Claude Sonnet 4 at 61.0.
https://agiopen.org/blog
What Lux Actually Does?
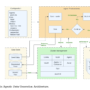
Lux is a computer use model, not a chat model with a browser plugin. It takes a natural language goal, views the screen, and outputs low level actions such as clicks, key presses and scroll events. It can drive browsers, editors, spreadsheets, email clients and other desktop applications because it works on rendered UI, not on application specific APIs.
From a developer point of view, Lux is available through the OpenAGI SDK and API console. The research team describes target workloads that include software QA flows, deep research runs, social media management, online store operations and bulk data entry. In all of these settings the agent needs to sequence dozens or hundreds of UI actions while staying aligned with a natural language task description.
https://agiopen.org/blog
Three Execution Modes For Different Control Levels
Lux ships with three execution modes that expose different tradeoffs between speed, autonomy and control.
Actor mode is the fast path. It runs around 1 second per step and is aimed at clearly specified tasks such as filling a form, pulling a report from a dashboard or extracting a small set of fields from a page. Think of it as a low latency macro engine that still understands natural language.
Thinker mode handles vague or multi step goals. It decomposes the high level instruction into smaller sub tasks and then executes them. Example workloads include multi page research, triage of long email queues or navigation of analytics interfaces where the exact click path is not specified in advance.
Tasker mode gives maximum determinism. The caller supplies an explicit Python list of steps that Lux executes one by one and it retries until the sequence completes or hits a hard failure. This allows teams to keep task graphs, guardrails and failure policies in their own code while delegating UI control to the model.
Tasker, Actor and Thinker are the three primary modes for procedural workflows, fast execution and complex goal solving.
Benchmarks, Latency And Cost
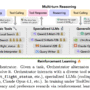
On Online Mind2Web, Lux reaches a success rate of 83.6 percent. The same benchmark reports 69.0 percent for Gemini CUA, 61.3 percent for OpenAI Operator and 61.0 percent for Claude Sonnet 4. The benchmark contains more than 300 web based tasks collected from real services, so it is a useful proxy for practical agents that drive browsers and web apps.
Latency and cost are where the numbers become important for engineering teams. OpenAGI team reports that Lux completes each step in about 1 second, while OpenAI Operator is around 3 seconds per step in the same evaluation setting. The research team also states that Lux is about 10 times cheaper per token than Operator. For any agent that can easily run hundreds of steps in a session, these constant factors determine whether a workload is viable in production.
Agentic Active Pre-training and Why OSGym Matters?
Lux is trained with a method that OpenAGI research team calls Agentic Active Pre-training. The team contrasts this with standard language model pre-training that passively ingests text from the internet. The idea is that Lux learns by acting in digital environments and refining its behavior through large scale interaction, rather than only minimizing token prediction loss on static logs. The optimization objective differs from classical reinforcement learning, and is set up to favor self driven exploration and understanding instead of a manually shaped reward.
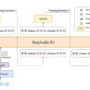
This training setup depends on a data engine that can expose many operating system environments in parallel. OpenAGI team has already open sourced that engine as OSGym, under an MIT license that allows both research and commercial use. OSGym runs full operating system replicas, not only browser sandboxes, and supports tasks that span office software, browsers, development tools and multi application workflows.
Key Takeaways
Lux is a foundation computer use model that operates full desktops and browsers and reaches 83.6 percent success on the Online Mind2Web benchmark, ahead of Gemini CUA, OpenAI Operator and Claude Sonnet-4.
Lux exposes 3 modes, Actor, Thinker and Tasker, which cover low latency UI macros, multi step goal decomposition and deterministic scripted execution for production workflows.
Lux is reported to run around 1 second per step and to be about 10 times cheaper per token than OpenAI Operator, which matters for long horizon agents that run hundreds of actions per task.
Lux is trained with Agentic Active Pre-training, where the model learns by acting in environments, rather than only consuming static web text, which targets robust screen to action behavior instead of pure language modeling.
OSGym, the open source data engine behind Lux, can run more than 1,000 OS replicas and generate more than 1,400 multi turn trajectories per minute at low per replica cost, which gives teams a practical way to train and evaluate their own computer use agents.
Check out the Official Announcement, Project and Repo. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
The post OpenAGI Foundation Launches Lux: A Foundation Computer Use Model that Tops Online Mind2Web with OSGym At Scale appeared first on MarkTechPost.