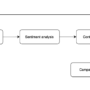
This article demonstrates how to build an intelligent routing system powered by Anthropic’s Claude models. This system improves response efficiency and quality by automatically classifying user requests and directing them to specialised handlers. The workflow analyses incoming queries, determines their intent, and routes them to appropriate processing pipelines—whether for customer support, technical assistance, or other domain-specific responses.
Step 1: Install the required Python packages
Copy CodeCopiedUse a different Browser!pip install anthropic pandas scikit-learn
Step 2: Import the necessary libraries for the project
Copy CodeCopiedUse a different Browserimport os
import json
import time
import pandas as pd
import numpy as np
from anthropic import Anthropic
from IPython.display import display, Markdown
from sklearn.metrics import classification_report
Step 3: Set up the Anthropic API authentication by defining your API key and initialising the Anthropic client
Copy CodeCopiedUse a different BrowserANTHROPIC_API_KEY = “{Your API KEY}”
client = Anthropic(api_key=ANTHROPIC_API_KEY)
Step 4: Create a sample dataset of customer queries with associated categories for training and testing the routing system.
Copy CodeCopiedUse a different Browsercustomer_queries = [
{“id”: 1, “query”: “What are your business hours?”, “category”: “General Question”},
{“id”: 2, “query”: “How do I reset my password?”, “category”: “Technical Support”},
{“id”: 3, “query”: “I want a refund for my purchase.”, “category”: “Refund Request”},
{“id”: 4, “query”: “Where can I find your privacy policy?”, “category”: “General Question”},
{“id”: 5, “query”: “The app keeps crashing when I try to upload photos.”, “category”: “Technical Support”},
{“id”: 6, “query”: “I ordered the wrong size, can I get my money back?”, “category”: “Refund Request”},
{“id”: 7, “query”: “Do you ship internationally?”, “category”: “General Question”},
{“id”: 8, “query”: “My account is showing incorrect information.”, “category”: “Technical Support”},
{“id”: 9, “query”: “I was charged twice for my order.”, “category”: “Refund Request”},
{“id”: 10, “query”: “What payment methods do you accept?”, “category”: “General Question”}
]
Step 5: Convert the customer queries list into a pandas DataFrame for easier manipulation and analysis. Then, display the DataFrame in the notebook to visualise the training dataset structure.
Copy CodeCopiedUse a different Browserdf = pd.DataFrame(customer_queries)
display(df)
Step 6: Define the core routing function that uses Claude 3.7 Sonnet to classify customer queries into predefined categories.
Copy CodeCopiedUse a different Browserdef route_query(query, client):
“””
Route a customer query to the appropriate category using Claude 3.5 Haiku.
Args:
query (str): The customer query to classify
client: Anthropic client
Returns:
str: The classified category
“””
system_prompt = “””
You are a query classifier for a customer service system.
Your job is to categorize customer queries into exactly one of these categories:
1. General Question – Basic inquiries about the company, products, policies, etc.
2. Refund Request – Any query related to refunds, returns, or billing issues
3. Technical Support – Questions about technical problems, bugs, or how to use products
Respond with ONLY the category name, nothing else.
“””
try:
response = client.messages.create(
model=”claude-3-7-sonnet-20250219″,
max_tokens=1024,
system=system_prompt,
messages=[{“role”: “user”, “content”: query}]
)
category = response.content[0].text.strip()
valid_categories = [“General Question”, “Refund Request”, “Technical Support”]
for valid_cat in valid_categories:
if valid_cat.lower() in category.lower():
return valid_cat
return “General Question”
except Exception as e:
print(f”Error in routing: {e}”)
return “General Question”
Step 7: Define three specialised handler functions for each query category, each using Claude 3.5 Sonnet with a category-specific system prompt.
Copy CodeCopiedUse a different Browserdef handle_general_question(query, client):
“””Handle general inquiries using Claude 3.5 Haiku.”””
system_prompt = “””
You are a customer service representative answering general questions about our company.
Be helpful, concise, and friendly. Provide direct answers to customer queries.
“””
try:
response = client.messages.create(
model=”claude-3-7-sonnet-20250219″,
max_tokens=1024,
system=system_prompt,
messages=[{“role”: “user”, “content”: query}]
)
return response.content[0].text.strip()
except Exception as e:
print(f”Error in general question handler: {e}”)
return “I apologize, but I’m having trouble processing your request. Please try again later.”
Copy CodeCopiedUse a different Browserdef handle_refund_request(query, client):
“””Handle refund requests using Claude 3.5 Sonnet for more nuanced responses.”””
system_prompt = “””
You are a customer service representative specializing in refunds and billing issues.
Respond to refund requests professionally and helpfully.
For any refund request, explain the refund policy clearly and provide next steps.
Be empathetic but follow company policy.
“””
try:
response = client.messages.create(
model=”claude-3-7-sonnet-20250219″,
max_tokens=1024,
system=system_prompt,
messages=[{“role”: “user”, “content”: query}]
)
return response.content[0].text.strip()
except Exception as e:
print(f”Error in refund request handler: {e}”)
return “I apologize, but I’m having trouble processing your refund request. Please contact our support team directly.”
Copy CodeCopiedUse a different Browserdef handle_technical_support(query, client):
“””Handle technical support queries using Claude 3.5 Sonnet for more detailed technical responses.”””
system_prompt = “””
You are a technical support specialist.
Provide clear, step-by-step solutions to technical problems.
If you need more information to resolve an issue, specify what information you need.
Prioritize simple solutions first before suggesting complex troubleshooting.
“””
try:
response = client.messages.create(
model=”claude-3-7-sonnet-20250219″,
max_tokens=1024,
system=system_prompt,
messages=[{“role”: “user”, “content”: query}]
)
return response.content[0].text.strip()
except Exception as e:
print(f”Error in technical support handler: {e}”)
return “I apologize, but I’m having trouble processing your technical support request. Please try our knowledge base or contact our support team.”
Step 8: Create the main workflow function that orchestrates the entire routing process. This function first classifies a query, tracks timing metrics, directs it to the appropriate specialised handler based on category, and returns a comprehensive results dictionary with performance statistics.
Copy CodeCopiedUse a different Browserdef process_customer_query(query, client):
“””
Process a customer query through the complete routing workflow.
Args:
query (str): The customer query
client: Anthropic client
Returns:
dict: Information about the query processing, including category and response
“””
start_time = time.time()
category = route_query(query, client)
routing_time = time.time() – start_time
start_time = time.time()
if category == “General Question”:
response = handle_general_question(query, client)
model_used = “claude-3-5-haiku-20240307”
elif category == “Refund Request”:
response = handle_refund_request(query, client)
model_used = “claude-3-5-sonnet-20240620”
elif category == “Technical Support”:
response = handle_technical_support(query, client)
model_used = “claude-3-5-sonnet-20240620”
else:
response = handle_general_question(query, client)
model_used = “claude-3-5-haiku-20240307”
handling_time = time.time() – start_time
total_time = routing_time + handling_time
return {
“query”: query,
“routed_category”: category,
“response”: response,
“model_used”: model_used,
“routing_time”: routing_time,
“handling_time”: handling_time,
“total_time”: total_time
}
Step 9: Process each query in the sample dataset through the routing workflow, collect the results with actual vs. predicted categories, and evaluate the system’s performance.
Copy CodeCopiedUse a different Browserresults = []
for _, row in df.iterrows():
query = row[‘query’]
result = process_customer_query(query, client)
result[“actual_category”] = row[‘category’]
results.append(result)
results_df = pd.DataFrame(results)
display(results_df[[“query”, “actual_category”, “routed_category”, “model_used”, “total_time”]])
accuracy = (results_df[“actual_category”] == results_df[“routed_category”]).mean()
print(f”Routing Accuracy: {accuracy:.2%}”)
from sklearn.metrics import classification_report
print(classification_report(results_df[“actual_category”], results_df[“routed_category”]))
Step 10: Simulated results.
Copy CodeCopiedUse a different Browsersimulated_results = []
for _, row in df.iterrows():
query = row[‘query’]
actual_category = row[‘category’]
if “hours” in query.lower() or “policy” in query.lower() or “ship” in query.lower() or “payment” in query.lower():
routed_category = “General Question”
model_used = “claude-3-5-haiku-20240307”
elif “refund” in query.lower() or “money back” in query.lower() or “charged” in query.lower():
routed_category = “Refund Request”
model_used = “claude-3-5-sonnet-20240620”
else:
routed_category = “Technical Support”
model_used = “claude-3-5-sonnet-20240620”
simulated_results.append({
“query”: query,
“actual_category”: actual_category,
“routed_category”: routed_category,
“model_used”: model_used,
“routing_time”: np.random.uniform(0.2, 0.5),
“handling_time”: np.random.uniform(0.5, 2.0)
})
simulated_df = pd.DataFrame(simulated_results)
simulated_df[“total_time”] = simulated_df[“routing_time”] + simulated_df[“handling_time”]
display(simulated_df[[“query”, “actual_category”, “routed_category”, “model_used”, “total_time”]])
Output
Step 11: Calculate and display the accuracy of the simulated routing system by comparing predicted categories with actual categories.
Copy CodeCopiedUse a different Browseraccuracy = (simulated_df[“actual_category”] == simulated_df[“routed_category”]).mean()
print(f”Simulated Routing Accuracy: {accuracy:.2%}”)
print(classification_report(simulated_df[“actual_category”], simulated_df[“routed_category”]))
Step 12: Create an interactive demo interface using IPython widgets.
Copy CodeCopiedUse a different Browserfrom IPython.display import HTML, display, clear_output
from ipywidgets import widgets
def create_demo_interface():
query_input = widgets.Textarea(
value=”,
placeholder=’Enter your customer service query here…’,
description=’Query:’,
disabled=False,
layout=widgets.Layout(width=’80%’, height=’100px’)
)
output = widgets.Output()
button = widgets.Button(
description=’Process Query’,
disabled=False,
button_style=’primary’,
tooltip=’Click to process the query’,
icon=’check’
)
def on_button_clicked(b):
with output:
clear_output()
query = query_input.value
if not query.strip():
print(“Please enter a query.”)
return
if “hours” in query.lower() or “policy” in query.lower() or “ship” in query.lower() or “payment” in query.lower():
category = “General Question”
model = “claude-3-5-haiku-20240307”
response = “Our standard business hours are Monday through Friday, 9 AM to 6 PM Eastern Time. Our customer service team is available during these hours to assist you.”
elif “refund” in query.lower() or “money back” in query.lower() or “charged” in query.lower():
category = “Refund Request”
model = “claude-3-5-sonnet-20240620”
response = “I understand you’re looking for a refund. Our refund policy allows returns within 30 days of purchase with a valid receipt. To initiate your refund, please provide your order number and the reason for the return.”
else:
category = “Technical Support”
model = “claude-3-5-sonnet-20240620”
response = “I’m sorry to hear you’re experiencing technical issues. Let’s troubleshoot this step by step. First, try restarting the application. If that doesn’t work, please check if the app is updated to the latest version.”
print(f”Routed to: {category}”)
print(f”Using model: {model}”)
print(“nResponse:”)
print(response)
button.on_click(on_button_clicked)
return widgets.VBox([query_input, button, output])
Output
Step 13: Implement an advanced routing function that not only classifies queries but also provides confidence scores and reasoning for each classification.
Copy CodeCopiedUse a different Browserdef advanced_route_query(query, client):
“””
An advanced routing function that includes confidence scores and fallback mechanisms.
Args:
query (str): The customer query to classify
client: Anthropic client
Returns:
dict: Classification result with category and confidence
“””
system_prompt = “””
You are a query classifier for a customer service system.
Your job is to categorize customer queries into exactly one of these categories:
1. General Question – Basic inquiries about the company, products, policies, etc.
2. Refund Request – Any query related to refunds, returns, or billing issues
3. Technical Support – Questions about technical problems, bugs, or how to use products
Respond in JSON format with:
1. “category”: The most likely category
2. “confidence”: A confidence score between 0 and 1
3. “reasoning”: A brief explanation of your classification
Example response:
{
“category”: “General Question”,
“confidence”: 0.85,
“reasoning”: “The query asks about business hours, which is basic company information.”
}
“””
try:
response = client.messages.create(
model=”claude-3-5-sonnet-20240620″,
max_tokens=150,
system=system_prompt,
messages=[{“role”: “user”, “content”: query}]
)
response_text = response.content[0].text.strip()
try:
result = json.loads(response_text)
if “category” not in result or “confidence” not in result:
raise ValueError(“Incomplete classification result”)
return result
except json.JSONDecodeError:
print(“Failed to parse JSON response. Using simple classification.”)
if “general” in response_text.lower():
return {“category”: “General Question”, “confidence”: 0.6, “reasoning”: “Fallback classification”}
elif “refund” in response_text.lower():
return {“category”: “Refund Request”, “confidence”: 0.6, “reasoning”: “Fallback classification”}
else:
return {“category”: “Technical Support”, “confidence”: 0.6, “reasoning”: “Fallback classification”}
except Exception as e:
print(f”Error in advanced routing: {e}”)
return {“category”: “General Question”, “confidence”: 0.3, “reasoning”: “Error fallback”}
Step 14: Create an enhanced query processing workflow with confidence-based routing that escalates low-confidence queries to specialised handling, incorporating simulated classification for demonstration purposes.
Copy CodeCopiedUse a different Browserdef advanced_process_customer_query(query, client, confidence_threshold=0.7):
“””
Process a customer query with confidence-based routing.
Args:
query (str): The customer query
client: Anthropic client
confidence_threshold (float): Minimum confidence score for automated routing
Returns:
dict: Information about the query processing
“””
start_time = time.time()
if “hours” in query.lower() or “policy” in query.lower() or “ship” in query.lower() or “payment” in query.lower():
classification = {
“category”: “General Question”,
“confidence”: np.random.uniform(0.7, 0.95),
“reasoning”: “Query related to business information”
}
elif “refund” in query.lower() or “money back” in query.lower() or “charged” in query.lower():
classification = {
“category”: “Refund Request”,
“confidence”: np.random.uniform(0.7, 0.95),
“reasoning”: “Query mentions refunds or billing issues”
}
elif “password” in query.lower() or “crash” in query.lower() or “account” in query.lower():
classification = {
“category”: “Technical Support”,
“confidence”: np.random.uniform(0.7, 0.95),
“reasoning”: “Query mentions technical problems”
}
else:
categories = [“General Question”, “Refund Request”, “Technical Support”]
classification = {
“category”: np.random.choice(categories),
“confidence”: np.random.uniform(0.4, 0.65),
“reasoning”: “Uncertain classification”
}
routing_time = time.time() – start_time
start_time = time.time()
if classification[“confidence”] >= confidence_threshold:
category = classification[“category”]
if category == “General Question”:
response = “SIMULATED GENERAL QUESTION RESPONSE: I’d be happy to help with your question about our business.”
model_used = “claude-3-5-haiku-20240307”
elif category == “Refund Request”:
response = “SIMULATED REFUND REQUEST RESPONSE: I understand you’re looking for a refund. Let me help you with that process.”
model_used = “claude-3-5-sonnet-20240620”
elif category == “Technical Support”:
response = “SIMULATED TECHNICAL SUPPORT RESPONSE: I see you’re having a technical issue. Let’s troubleshoot this together.”
model_used = “claude-3-5-sonnet-20240620”
else:
response = “I apologize, but I’m not sure how to categorize your request.”
model_used = “claude-3-5-sonnet-20240620”
else:
response = “SIMULATED ESCALATION RESPONSE: Your query requires special attention. I’ll have our advanced support system help you with this complex request.”
model_used = “claude-3-5-sonnet-20240620”
category = “Escalated (Low Confidence)”
handling_time = time.time() – start_time
total_time = routing_time + handling_time
return {
“query”: query,
“routed_category”: classification[“category”],
“confidence”: classification[“confidence”],
“reasoning”: classification[“reasoning”],
“final_category”: category,
“response”: response,
“model_used”: model_used,
“routing_time”: routing_time,
“handling_time”: handling_time,
“total_time”: total_time
}
Step 15: Test the advanced routing system with diverse sample queries.
Copy CodeCopiedUse a different Browsertest_queries = [
“What are your business hours?”,
“I need a refund for my order #12345”,
“My app keeps crashing when I try to save photos”,
“I received the wrong item in my shipment”,
“How do I change my shipping address?”,
“I’m not sure if my payment went through”,
“The product description was misleading”
]
advanced_results = []
for query in test_queries:
result = advanced_process_customer_query(query, None, 0.7)
advanced_results.append(result)
advanced_df = pd.DataFrame(advanced_results)
display(advanced_df[[“query”, “routed_category”, “confidence”, “final_category”, “model_used”]])
print(“nRouting Distribution:”)
print(advanced_df[“final_category”].value_counts())
print(f”nAverage Confidence: {advanced_df[‘confidence’].mean():.2f}”)
escalated = (advanced_df[“final_category”] == “Escalated (Low Confidence)”).sum()
print(f”Escalated Queries: {escalated} ({escalated/len(advanced_df):.1%})”)
Output
Step 16: Define a utility function to calculate key performance metrics for the routing system, including processing times, confidence levels, escalation rates, and category distribution statistics.
Copy CodeCopiedUse a different Browserdef calculate_routing_metrics(results_df):
“””
Calculate key metrics for routing performance.
Args:
results_df (DataFrame): Results of routing tests
Returns:
dict: Key performance metrics
“””
metrics = {
“total_queries”: len(results_df),
“avg_routing_time”: results_df[“routing_time”].mean(),
“avg_handling_time”: results_df[“handling_time”].mean(),
“avg_total_time”: results_df[“total_time”].mean(),
“avg_confidence”: results_df[“confidence”].mean(),
“escalation_rate”: (results_df[“final_category”] == “Escalated (Low Confidence)”).mean(),
}
category_distribution = results_df[“routed_category”].value_counts(normalize=True).to_dict()
metrics[“category_distribution”] = category_distribution
return metrics
Step 17: Generate and display a comprehensive performance report for the routing system.
Copy CodeCopiedUse a different Browsermetrics = calculate_routing_metrics(advanced_df)
print(“Routing System Performance Metrics:”)
print(f”Total Queries: {metrics[‘total_queries’]}”)
print(f”Average Routing Time: {metrics[‘avg_routing_time’]:.3f} seconds”)
print(f”Average Handling Time: {metrics[‘avg_handling_time’]:.3f} seconds”)
print(f”Average Total Time: {metrics[‘avg_total_time’]:.3f} seconds”)
print(f”Average Confidence: {metrics[‘avg_confidence’]:.2f}”)
print(f”Escalation Rate: {metrics[‘escalation_rate’]:.1%}”)
print(“nCategory Distribution:”)
for category, percentage in metrics[“category_distribution”].items():
print(f” {category}: {percentage:.1%}”)
Output
This intelligent request routing system demonstrates how Claude models can efficiently classify and handle diverse customer queries. By implementing category-specific handlers with appropriate model selection, the system delivers tailored responses while maintaining high accuracy. The confidence-based routing with escalation paths ensures complex queries receive specialised attention, creating a robust, scalable customer service solution.
Check out the Colab Notebook here. Also, don’t forget to follow us on Twitter.
Here’s a brief overview of what we’re building at Marktechpost:
ML News Community – r/machinelearningnews (92k+ members)
Newsletter– airesearchinsights.com/(30k+ subscribers)
miniCON AI Events – minicon.marktechpost.com
AI Reports & Magazines – magazine.marktechpost.com
AI Dev & Research News – marktechpost.com (1M+ monthly readers)
The post A Step-by-Step Guide to Implement Intelligent Request Routing with Claude appeared first on MarkTechPost.