This post was co-written with Julio P. Roque Hexagon ALI.
Recognizing the transformative benefits of generative AI for enterprises, we at Hexagon’s Asset Lifecycle Intelligence division sought to enhance how users interact with our Enterprise Asset Management (EAM) products. Understanding these advantages, we partnered with AWS to embark on a journey to develop HxGN Alix, an AI-powered digital worker using AWS generative AI services. This blog post explores the strategy, development, and implementation of HxGN Alix, demonstrating how a tailored AI solution can drive efficiency and enhance user satisfaction.
Forming a generative AI strategy: Security, accuracy, and sustainability
Our journey to build HxGN Alix was guided by a strategic approach focused on customer needs, business requirements, and technological considerations. In this section, we describe the key components of our strategy.
Understanding consumer generative AI and enterprise generative AI
Generative AI serves diverse purposes, with consumer and enterprise applications differing in scope and focus. Consumer generative AI tools are designed for broad accessibility, enabling users to perform everyday tasks such as drafting content, generating images, or answering general inquiries. In contrast, enterprise generative AI is tailored to address specific business challenges, including scalability, security, and seamless integration with existing workflows. These systems often integrate with enterprise infrastructures, prioritize data privacy, and use proprietary datasets to provide relevance and accuracy. This customization allows businesses to optimize operations, enhance decision-making, and maintain control over their intellectual property.
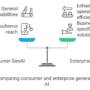
Commercial compared to open source LLMs
We used multiple evaluation criteria, as illustrated in the following figure, to determine whether to use a commercial or open source large language model (LLM).
The evaluation criteria are as follows:
Cost management – Help avoid unpredictable expenses associated with LLMs.
Customization – Tailor the model to understand domain-specific terminology and context.
Intellectual property and licensing – Maintain control over data usage and compliance.
Data privacy – Uphold strict confidentiality and adherence to security requirements.
Control over the model lifecycle – By using open source LLMs, we’re able to control the lifecycle of model customizations based on business needs. This control makes sure updates, enhancements, and maintenance of the model are aligned with evolving business objectives without dependency on third-party providers.
The path to the enterprise generative AI: Crawl, walk, run
By adopting a phased approach (as shown in the following figure), we were able to manage development effectively. Because the technology is new, it was paramount to carefully build the right foundation for adoption of generative AI across different business units.
The phases of the approach are:
Crawl – Establish foundational infrastructure with a focus on data privacy and security. This phase focused on establishing a secure and compliant foundation to enable the responsible adoption of generative AI. Key priorities included implementing guardrails around security, compliance, and data privacy, making sure that customer and enterprise data remained protected within well-defined access controls. Additionally, we focused on capacity management and cost governance, making sure that AI workloads operated efficiently while maintaining financial predictability. This phase was critical in setting up the necessary policies, monitoring mechanisms, and architectural patterns to support long-term scalability.
Walk – Integrate customer-specific data to enhance relevance while maintaining tenant-level security. With a solid foundation in place, we transitioned from proof of concept to production-grade implementations. This phase was characterized by deepening our technical expertise, refining operational processes, and gaining real-world experience with generative AI models. As we integrated domain-specific data to improve relevance and usability, we continued to reinforce tenant-level security to provide proper data segregation. The goal of this phase was to validate AI-driven solutions in real-world scenarios, iterating on workflows, accuracy, and optimizing performance for production deployment.
Run – Develop high-value use cases tailored to customer needs, enhancing productivity and decision-making. Using the foundations established in the walk phase, we moved toward scaling development across multiple teams in a structured and repeatable manner. By standardizing best practices and development frameworks, we enabled different products to adopt AI capabilities efficiently. At this stage, we focused on delivering high-value use cases that directly enhanced customer productivity, decision-making, and operational efficiency.
Identifying the right use case: Digital worker
A critical part of our strategy was identifying a use case that would offer the best return on investment (ROI), depicted in the following figure. We pinpointed the development of a digital worker as an optimal use case because of its potential to:
Enhance productivity – Recognizing that the productivity of any AI solution lies in a digital worker capable of handling advanced and nuanced domain-specific tasks
Improve efficiency – Automate routine tasks and streamline workflows
Enhance user experience – Provide immediate, accurate responses to user inquiries
Support high security environments – Operate within stringent security parameters required by clients
By focusing on a digital worker, we aimed to deliver significant value to both internal teams and end-users.
Introducing Alix: A digital worker for asset lifecycle intelligence
HxGN Alix is our AI-powered chat assistant designed to act as a digital worker to revolutionize user interaction with EAM products. Developed to operate securely within high-security environments, HxGN Alix serves multiple functions:
Streamline information access – Provide users with quick, accurate answers, alleviating the need to navigate extensive PDF manuals
Enhance internal workflows – Assist Customer Success managers and Customer Support teams with efficient information retrieval
Improve customer satisfaction – Offer EAM end-users an intuitive tool to engage with, thereby elevating their overall experience
By delivering a tailored, AI-driven approach, HxGN Alix addresses specific challenges faced by our clients, transforming the user experience while upholding stringent security standards.
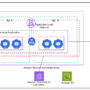
Understanding system needs to guide technology selection
Before selecting the appropriate technology stack for HxGN Alix, we first identified the high-level system components and expectations of our AI assistant infrastructure. Through this process, we made sure that we understood the core components required to build a robust and scalable solution. The following figure illustrates the core components that we identified.
The non-functional requirements are:
Regional failover – Maintain system resilience by providing the ability to fail over seamlessly in case of Regional outages, maintaining service availability.
Model lifecycle management – Establish a reliable mechanism for customizing and deploying machine learning models.
LLM hosting – Host the AI models in an environment that provides stability, scalability, and adheres to our high-security requirements.
Multilingual capabilities – Make sure that the assistant can communicate effectively in multiple languages to cater to our diverse user base.
Safety tools – Incorporate safeguards to promote safe and responsible AI use, particularly with regard to data protection and user interactions.
Data storage – Provide secure storage solutions for managing product documentation and user data, adhering to industry security standards.
Retrieval Augmented Generation (RAG) – Enhance the assistant’s ability to retrieve relevant information from stored documents, thereby improving response accuracy and providing grounded answers.
Text embeddings – Use text embeddings to represent and retrieve relevant data, making sure that high-accuracy retrieval tasks are efficiently managed.
Choosing the right technology stack
To develop HxGN Alix, we selected a combination of AWS generative AI services and complementary technologies, focusing on scalability, customization, and security. We finalized the following architecture to serve our technical needs.
The AWS services include:
Amazon Elastic Kubernetes Service (Amazon EKS) – We used Amazon EKS for compute and model deployment. It facilitates efficient deployment and management of Alix’s models, providing high availability and scalability. We were able to use our existing EKS cluster, which already had the required safety, manageability, and integration with our DevOps environment. This allowed for seamless integration and used existing investments in infrastructure and tooling.
Amazon Elastic Compute Cloud (Amazon EC2) G6e instances – AWS provides comprehensive, secure, and cost-effective AI infrastructure. We selected G6e.48xlarge instances powered by NVIDIA L40S GPUs—the most cost-efficient GPU instances for deploying generative AI models under 12 billion parameters.
Mistral NeMo – We chose Mistral NeMo, a 12-billion parameter open source LLM built in collaboration with NVIDIA and released under the Apache 2.0 license. Mistral NeMo offers a large context window of up to 128,000 tokens and is designed for global, multilingual applications. It’s optimized for function calling and performs strongly in multiple languages, including English, French, German, Spanish, Italian, Portuguese, Chinese, Japanese, Korean, Arabic, and Hindi. The model’s multilingual capabilities and optimization for function calling aligned well with our needs.
Amazon Bedrock Guardrails – Amazon Bedrock Guardrails provides a comprehensive framework for enforcing safety and compliance within AI applications. It enables the customization of filtering policies, making sure that AI-generated responses align with organizational standards and regulatory requirements. With built-in capabilities to detect and mitigate harmful content, Amazon Bedrock Guardrails enhances user trust and safety while maintaining high performance in AI deployments. This service allows us to define content moderation rules, restrict sensitive topics, and establish enterprise-level security for generative AI interactions.
Amazon Simple Storage Service (Amazon S3) – Amazon S3 provides secure storage for managing product documentation and user data, adhering to industry security standards.
Amazon Bedrock Knowledge Bases – Amazon Bedrock Knowledge Bases enhances Alix’s ability to retrieve relevant information from stored documents, improving response accuracy. This service stood out as a managed RAG solution, handling the heavy lifting and enabling us to experiment with different strategies and solve complex challenges efficiently. More on this is discussed in the development journey.
Amazon Bedrock – We used Amazon Bedrock as a fallback solution to handle Regional failures. In the event of zonal or outages, the system can fall back to the Mistral 7B model using Amazon Bedrock multi- Region endpoints, maintaining uninterrupted service.
Amazon Bedrock Prompt Management – This feature of Amazon Bedrock simplifies the creation, evaluation, versioning, and sharing of prompts within the engineering team to get the best responses from foundation models (FMs) for our use cases.
The development journey
We embarked on the development of HxGN Alix through a structured, phased approach.
The proof of concept
We initiated the project by creating a proof of concept to validate the feasibility of an AI assistant tailored for secure environments. Although the industry has seen various AI assistants, the primary goal of the proof of concept was to make sure that we could develop a solution while adhering to our high security standards, which required full control over the manageability of the solution.
During the proof of concept, we scoped the project to use an off-the-shelf NeMo model deployed on our existing EKS cluster without integrating internal knowledge bases. This approach helped us verify the ability to integrate the solution with existing products, control costs, provide scalability, and maintain security—minimizing the risk of late-stage discoveries.
After releasing the proof of concept to a small set of internal users, we identified a healthy backlog of work items that needed to go live, including enhancements in security, architectural improvements, network topology adjustments, prompt management, and product integration.
Security enhancements
To adhere to the stringent security requirements of our customers, we used the secure infrastructure provided by AWS. With models deployed in our existing production EKS environment, we were able to use existing tooling for security and monitoring. Additionally, we used isolated private subnets to make sure that code interacting with models wasn’t connected to the internet, further enhancing information protection for users.
Because user interactions are in free-text format and users might input content including personally identifiable information (PII), it was critical not to store any user interactions in any format. This approach provided complete confidentiality of AI use, adhering to strict data privacy standards.
Adjusting response accuracy
During the proof of concept, it became clear that integrating the digital worker with our products was essential. Base models had limited knowledge of our products and often produced hallucinations. We had to choose between pretraining the model with internal documentation or implementing RAG. RAG became the obvious choice for the following reasons:
We were in the early stages of development and didn’t have enough data to pre-train our models
RAG helps ground the model’s responses in accurate context by retrieving relevant information, reducing hallucinations
Implementing a RAG system presented its own challenges and required experimentation. Key challenges are depicted in the following figure.
These challenges include:
Destruction of context when chunking documents – The first step in RAG is to chunk documents to transform them into vectors for meaningful text representation. However, applying this method to tables or complex structures risks losing relational data, which can result in critical information not being retrieved, causing the LLM to provide inaccurate answers. We evaluated various strategies to preserve context during chunking, verifying that important relationships within the data were maintained. To address this, we used the hierarchical chunking capability of Amazon Bedrock Knowledge Bases, which helped us preserve the context in the final chunk.
Handling documents in different formats – Our product documentation, accumulated over decades, varied greatly in format. The presence of non-textual elements, such as tables, posed significant challenges. Tables can be difficult to interpret when directly queried from PDFs or Word documents. To address this, we normalized and converted these documents into consistent formats suitable for the RAG system, enhancing the model’s ability to retrieve and interpret information accurately. We used the FM parsing capability of Amazon Bedrock Knowledge Bases, which processed the raw document with an LLM before creating a final chunk, verifying that data from non-textual elements was also correctly interpreted.
Handling LLM boundaries – User queries sometimes exceed the system’s capabilities, such as when they request comprehensive information, like a complete list of product features. Because our documentation is split into multiple chunks, the retrieval system might not return all the necessary documents. To address this, we adjusted the system’s responses so the AI agent could provide coherent and complete answers despite limitations in the retrieved context. We created custom documents containing FAQs and special instructions for these cases and added them to the knowledge base. These acted as few-shot examples, helping the model produce more accurate and complete responses.
Grounding responses – By nature, an LLM completes sentences based on probability, predicting the next word or phrase by evaluating patterns from its extensive training data. However, sometimes the output isn’t accurate or factually correct, a phenomenon often referred to as hallucination. To address this, we use a combination of specialized prompts along with contextual grounding checks from Amazon Bedrock Guardrails.
Managing one-line conversation follow-ups – Users often engage in follow-up questions that are brief or context-dependent, such as “Can you elaborate?” or “Tell me more.” When processed in isolation by the RAG system, these queries might yield no results, making it challenging for the AI agent to respond effectively. To address this, we implemented mechanisms to maintain conversational context, enabling HxGN Alix to interpret and respond appropriately.
We tested two approaches:
Prompt-based search reformulation – The LLM first identifies the user’s intent and generates a more complete query for the knowledge base. Although this requires an additional LLM call, it yields highly relevant results, keeping the final prompt concise.
Context-based retrieval with chat history – We sent the last five messages from the chat history to the knowledge base, allowing broader results. This approach provided faster response times because it involved only one LLM round trip.
The first method worked better with large document sets by focusing on highly relevant results, whereas the second approach was more effective with a smaller, focused document set. Both methods have their pros and cons, and results vary based on the nature of the documents.
To address these challenges, we developed a pipeline of steps to receive accurate responses from our digital assistant.
The following figure summarizes our RAG implementation journey.
Adjusting the application development lifecycle
For generative AI systems, the traditional application development lifecycle requires adjustments. New processes are necessary to manage accuracy and system performance:
Testing challenges – Unlike traditional code, generative AI systems can’t rely solely on unit tests. Prompts can return different results each time, making verification more complex.
Performance variability – Responses from LLMs can vary significantly in latency, ranging from 1–60 seconds depending on the user’s query, unlike traditional APIs with predictable response times.
Quality assurance (QA) – We had to develop new testing and QA methodologies to make sure that Alix’s responses were consistent and reliable.
Monitoring and optimization – Continuous monitoring was implemented to track performance metrics and user interactions, allowing for ongoing optimization of the AI system.
Conclusion
The successful launch of HxGN Alix demonstrates the transformative potential of generative AI in enterprise asset management. By using AWS generative AI services and a carefully selected technology stack, we optimized internal workflows and elevated user satisfaction within secure environments. HxGN Alix exemplifies how a strategically designed AI solution can drive efficiency, enhance user experience, and meet the unique security needs of enterprise clients.
Our journey underscores the importance of a strategic approach to generative AI—balancing security, accuracy, and sustainability—while focusing on the right use case and technology stack. The success of HxGN Alix serves as a model for organizations seeking to use AI to solve complex information access challenges.
By using the right technology stack and strategic approach, you can unlock new efficiencies, improve user experience, and drive business success. Connect with AWS to learn more about how AI-driven solutions can transform your operations.
About the Authors
Julio P. Roque is an accomplished Cloud and Digital Transformation Executive and an expert at using technology to maximize shareholder value. He is a strategic leader who drives collaboration, alignment, and cohesiveness across teams and organizations worldwide. He is multilingual, with an expert command of English and Spanish, understanding of Portuguese, and cultural fluency of Japanese.
Manu Mishra is a Senior Solutions Architect at AWS, specializing in artificial intelligence, data and analytics, and security. His expertise spans strategic oversight and hands-on technical leadership, where he reviews and guides the work of both internal and external customers. Manu collaborates with AWS customers to shape technical strategies that drive impactful business outcomes, providing alignment between technology and organizational goals.
Veda Raman is a Senior Specialist Solutions Architect for generative AI and machine learning at AWS. Veda works with customers to help them architect efficient, secure, and scalable machine learning applications. Veda specializes in generative AI services like Amazon Bedrock and Amazon SageMaker.