We are excited to announce the availability of Gemma 3 27B Instruct models through Amazon Bedrock Marketplace and Amazon SageMaker JumpStart. With this launch, developers and data scientists can now deploy Gemma 3, a 27-billion-parameter language model, along with its specialized instruction-following versions, to help accelerate building, experimentation, and scalable deployment of generative AI solutions on AWS.
In this post, we show you how to get started with Gemma 3 27B Instruct on both Amazon Bedrock Marketplace and SageMaker JumpStart, and how to use the model’s powerful instruction-following capabilities in your applications.
Overview of Gemma 3 27B
Gemma 3 27B is a high-performance, open-weight, multimodal language model by Google designed to handle both text and image inputs with efficiency and contextual understanding. It introduces a redesigned attention architecture, enhanced multilingual support, and extended context capabilities. With its optimized memory usage and support for large input sequences, it is well-suited for complex reasoning tasks, long-form interactions, and vision-language applications. With 27 billion parameters and training on up to 6 trillion tokens of text, these models are optimized for tasks requiring advanced reasoning, multilingual capabilities, and instruction following. According to Google, Gemma3 27B Instruct models are ideal for developers, researchers, and businesses looking to build generative AI applications such as chatbots, virtual assistants, and automated content generation tools. The following are its key features:
Multimodal input – Processes text, images, and short videos for unified reasoning across modalities
Long context support – Handles up to 128,000 tokens, enabling seamless processing of long documents, conversations, and multimedia transcripts
Multilingual support – Offers out-of-the-box support for over 35 languages, with pre-training exposure to more than 140 languages in total
Function calling – Facilitates building agentic workflows by using natural‐language interfaces to APIs
Memory-efficient inference – Offers architectural updates that reduce KV-cache usage and introduce QK-norm for faster and more accurate outputs
Key use cases for Gemma3, as described by Google, include:
Q&A and summarization – Processing and condensing long documents or articles
Visual understanding – Image captioning, object identification, visual Q&A, and document understanding
Multilingual applications – Building AI assistants and tools across over 140 languages
Document processing – Analyzing multi-page articles or extracting information from large texts
Automated workflows – Using function calling to create AI agents that can interact with other systems
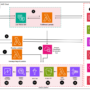
There are two primary methods for deploying Gemma 3 27B in AWS: The first approach involves using Amazon Bedrock Marketplace, which offers a streamlined way of accessing Amazon Bedrock APIs (Invoke and Converse) and tools such as Amazon Bedrock Knowledge Bases, Amazon Bedrock Agents, Amazon Bedrock Flows, Amazon Bedrock Guardrails, and model evaluation. The second approach is using SageMaker JumpStart, a machine learning (ML) hub, with foundation models (FMs), built-in algorithms, and pre-built ML solutions. You can deploy pre-trained models using either the Amazon SageMaker console or SDK.
Deploy Gemma 3 27B Instruct on Amazon Bedrock Marketplace
Amazon Bedrock Marketplace offers access to over 150 specialized FMs, including Gemma 3 27B Instruct.
Prerequisites
To try the Gemma 3 27B Instruct model using Amazon Bedrock Marketplace, you need the following:
An AWS account that will contain all your AWS resources
Access to accelerated instances (GPUs) for hosting the large language models (LLMs)
Deploy the model
To deploy the model using Amazon Bedrock Marketplace, complete the following steps:
On the Amazon Bedrock console, under Foundation models in the navigation pane, select Model catalog.
Filter for Gemma as the provider and choose Gemma 3 27B Instruct.
Information about Gemma3’s features, costs, and setup instructions can be found on its model overview page. This resource includes integration examples, API documentation, and programming samples. The model excels at a variety of text generation and image understanding tasks, including question answering, summarization, and reasoning. You can also access deployment guidelines and license details to begin implementing Gemma3 into your projects.
Review the model details, pricing, and deployment guidelines, and choose Deploy to start the deployment process.
For Endpoint name, enter an endpoint name (between 1–50 alphanumeric characters) or leave it as the default name that is pre-populated.
For Number of instances, enter a number of instances (between 1–100).
Select your preferred instance type, with GPU-powered options like ml.g5.48xlarge being particularly well-suited for running Gemma 3 efficiently.
Although default configurations are typically sufficient for basic needs, you have the option to customize security features such as virtual private cloud (VPC) networking, role-based permissions, and data encryption. These advanced settings might require adjustment for production environments to maintain compliance with your organization’s security protocols.
Prior to deploying Gemma 3, verify that your AWS account has sufficient quota allocation for ml.g5.48xlarge instances. A quota set to 0 will trigger deployment failures, as shown in the following screenshot.
To request a quota increase, open the AWS Service Quotas console and search for SageMaker. Locate ml.g5.48xlarge for endpoint usage and choose Request quota increase, then specify your required limit value.
While the deployment is in progress, you can choose Managed deployments in the navigation pane to monitor the deployment status.
When deployment is complete, you can test Gemma 3’s capabilities directly in the Amazon Bedrock playground by selecting the managed deployment and choosing Open in playground.
You can now use the playground to interact with Gemma 3.
For detailed steps and example code for invoking the model using Amazon Bedrock APIs, refer to Submit prompts and generate response using the API and the following code:
import boto3
bedrock_runtime = boto3.client(“bedrock-runtime”)
endpoint_arn = “arn:aws:sagemaker:us-east-2:061519324070:endpoint/endpoint-quick-start-3t7kp”
response = bedrock_runtime.converse(
modelId=endpoint_arn,
messages=[
{
“role”: “user”,
“content”: [{“text”: “What is Amazon doing in the field of generative AI?”}]
}
],
inferenceConfig={
“maxTokens”: 256,
“temperature”: 0.1,
“topP”: 0.999
}
)
print(response[“output”][“message”][“content”][0][“text”])
Deploy Gemma 3 27B Instruct with SageMaker JumpStart
SageMaker JumpStart offers access to a broad selection of publicly available FMs. These pre-trained models serve as powerful starting points that can be deeply customized to address specific use cases. You can use state-of-the-art model architectures—such as language models, computer vision models, and more—without having to build them from scratch.
With SageMaker JumpStart, you can deploy models in a secure environment. The models can be provisioned on dedicated SageMaker inference instances and can be isolated within your VPC. After deploying an FM, you can further customize and fine-tune it using the extensive capabilities of Amazon SageMaker AI, including SageMaker inference for deploying models and container logs for improved observability. With SageMaker AI, you can streamline the entire model deployment process.
There are two ways to deploy the Gemma 3 model using SageMaker JumpStart:
Through the user-friendly SageMaker JumpStart interface
Using the SageMaker Python SDK for programmatic deployment
We examine both deployment methods to help you determine which approach aligns best with your requirements.
Prerequisites
To try the Gemma 3 27B Instruct model in SageMaker JumpStart, you need the following prerequisites:
An AWS account that will contain your AWS resources.
An AWS Identity and Access Management (IAM) role to access SageMaker AI. To learn more about how IAM works with SageMaker AI, see Identity and Access Management for Amazon SageMaker AI.
Access to Amazon SageMaker Studio and a SageMaker AI notebook instance or an interactive development environment (IDE) such as PyCharm or Visual Studio Code. We recommend using SageMaker Studio for straightforward deployment and inference.
Access to accelerated instances (GPUs) for hosting the LLMs.
Deploy the model through the SageMaker JumpStart UI
SageMaker JumpStart provides a user-friendly interface for deploying pre-built ML models with just a few clicks. Through the SageMaker JumpStart UI, you can select, customize, and deploy a wide range of models for various tasks such as image classification, object detection, and natural language processing, without the need for extensive coding or ML expertise.
On the SageMaker AI console, choose Studio in the navigation pane.
First-time users will be prompted to create a domain.
On the SageMaker Studio console, choose JumpStart in the navigation pane.
The model browser displays available models, with details like the provider name and model capabilities.
Search for Gemma 3 to view the Gemma 3 model card. Each model card shows key information, including:
Model name
Provider name
Task category (for example, Text Generation)
The Bedrock Ready badge (if applicable), indicating that this model can be registered with Amazon Bedrock, so you can use Amazon Bedrock APIs to invoke the model
Choose the model card to view the model details page.
The model details page includes the following information:
The model name and provider information
The Deploy button to deploy the model
About and Notebooks tabs with detailed information. The About tab includes important details, such as:
Model description
License information
Technical specifications
Usage guidelines
Before you deploy the model, we recommended you review the model details and license terms to confirm compatibility with your use case.
Choose Deploy to proceed with deployment.
For Endpoint name, enter an endpoint name (between 1–50 alphanumeric characters) or leave it as default.
For Instance type, choose an instance type (default: ml.g5.48xlarge).
For Initial instance count, enter the number of instances (default: 1).
Selecting appropriate instance types and counts is crucial for cost and performance optimization. Monitor your deployment to adjust these settings as needed. Under Inference type, Real-time inference is selected by default. This is optimized for sustained traffic and low latency.
Review all configurations for accuracy. For this model, we strongly recommend adhering to SageMaker JumpStart default settings and making sure that network isolation remains in place.
Choose Deploy to deploy the model.
The deployment process can take several minutes to complete.
Deploy the model programmatically using the SageMaker Python SDK
To use Gemma 3 with the SageMaker Python SDK, first make sure you have installed the SDK and set up your AWS permissions and environment correctly. The following is a code example showing how to programmatically deploy and run inference with Gemma 3:
import sagemaker
from sagemaker.jumpstart.model import JumpStartModel
from sagemaker import Session, image_uris
import boto3
# Initialize SageMaker session
session = sagemaker.Session()
role = sagemaker.get_execution_role()
# Specify model parameters
model_id = “huggingface-vlm-gemma-3-27b-instruct” # or “huggingface-llm-gemma-2b” for the smaller version
instance_type = “ml.g5.48xlarge” # Choose appropriate instance based on your needs
# Create and deploy the model
model = JumpStartModel(
model_id=model_id,
role=role,
instance_type=instance_type,
model_version=”*”, # Latest version
)
# Deploy the model
predictor = model.deploy(
initial_instance_count=1,
accept_eula=True # Required for deploying foundation models
)
Run inference using the SageMaker API
With your Gemma 3 model successfully deployed as a SageMaker endpoint, you’re now ready to start making predictions. The SageMaker SDK provides a straightforward way to interact with your model endpoint for inference tasks. The following code demonstrates how to format your input and make API calls to the endpoint. The code handles both sending requests to the model and processing its responses, making it straightforward to integrate Gemma 3 into your applications.
import json
import boto3
# Initialize AWS session (ensure your AWS credentials are configured)
session = boto3.Session()
sagemaker_runtime = session.client(“sagemaker-runtime”)
# Define the SageMaker endpoint name (replace with your deployed endpoint name)
endpoint_name = “hf-vlm-gemma-3-27b-instruct-2025-05-07-18-09-16-221”
payload = {
“inputs”: “What is Amazon doing in the field of generative AI?”,
“parameters”: {
“max_new_tokens”: 256,
“temperature”: 0.1,
“top_p”: 0.9,
“return_full_text”: False
}
}
# Run inference
try:
response = sagemaker_runtime.invoke_endpoint(
EndpointName=endpoint_name,
ContentType=”application/json”,
Body=json.dumps(payload)
)
# Parse the response
result = json.loads(response[“Body”].read().decode(“utf-8”))
generated_text = result[0][“generated_text”].strip()
print(“Generated Response:”)
print(generated_text)
except Exception as e:
print(f”Error during inference: {e}”)
Clean up
To avoid incurring ongoing charges for AWS resources used during exploration of Gemma3 27B Instruct models, it’s important to clean up deployed endpoints and associated resources. Complete the following steps:
Delete SageMaker endpoints:
On the SageMaker console, in the navigation pane, choose Endpoints under Inference.
Select the endpoint associated with the Gemma3 27B Instruct model (for example, gemma3-27b-instruct-endpoint).
Choose Delete and confirm the deletion. This stops the endpoint and prevents further compute charges.
Delete SageMaker models (if applicable):
On the SageMaker console, choose Models under Inference.
Select the model associated with your endpoint and choose Delete.
Verify Amazon Bedrock Marketplace resources:
On the Amazon Bedrock console, choose Model catalog in the navigation pane.
Make sure no additional endpoints are running for the Gemma3 27B Instruct model deployed through Amazon Bedrock Marketplace.
Always verify that all endpoints are deleted after experimentation to optimize costs. Refer to the Amazon SageMaker documentation for additional guidance on managing resources.
Conclusion
The availability of Gemma3 27B Instruct models in Amazon Bedrock Marketplace and SageMaker JumpStart empowers developers, researchers, and businesses to build cutting-edge generative AI applications with ease. With their high performance, multilingual capabilities and efficient deployment on AWS infrastructure, these models are well-suited for a wide range of use cases, from conversational AI to code generation and content automation. By using the seamless discovery and deployment capabilities of SageMaker JumpStart and Amazon Bedrock Marketplace, you can accelerate your AI innovation while benefiting from the secure, scalable, and cost-effective AWS Cloud infrastructure.
We encourage you to explore the Gemma3 27B Instruct models today by visiting the SageMaker JumpStart console or Amazon Bedrock Marketplace. Deploy the model and experiment with sample prompts to meet your specific needs. For further learning, explore the AWS Machine Learning Blog, the SageMaker JumpStart GitHub repository, and the Amazon Bedrock documentation. Start building your next generative AI solution with Gemma3 27B Instruct models and unlock new possibilities with AWS!
About the Authors
Santosh Vallurupalli is a Sr. Solutions Architect at AWS. Santosh specializes in networking, containers, and migrations, and enjoys helping customers in their journey of cloud adoption and building cloud-based solutions for challenging issues. In his spare time, he likes traveling, watching Formula1, and watching The Office on repeat.
Aravind Singirikonda is an AI/ML Solutions Architect at AWS. He works with AWS customers in the healthcare and life sciences domain to provide guidance and technical assistance, helping them improve the value of their AI/ML solutions when using AWS.
Pawan Matta is a Sr. Solutions Architect at AWS. He works with AWS customers in the gaming industry and guides them to deploy highly scalable, performant architectures. His area of focus is management and governance. In his free time, he likes to play FIFA and watch cricket.
Ajit Mahareddy is an experienced Product and Go-To-Market (GTM) leader with over 20 years of experience in product management, engineering, and GTM. Prior to his current role, Ajit led product management building AI/ML products at leading technology companies, including Uber, Turing, and eHealth. He is passionate about advancing generative AI technologies and driving real-world impact with generative AI.