Climate tech startups are companies that use technology and innovation to address the climate crisis, with a primary focus on either reducing greenhouse gas emissions or helping society adapt to climate change impacts. Their unifying mission is to create scalable solutions that accelerate the transition to a sustainable, low-carbon future. Solutions to the climate crisis are ever more important as climate-driven extreme weather disasters increase globally. In 2024, climate disasters caused more than $417B in damages globally, and there’s no slowing down in 2025 with LA wildfires that destroyed more than $135B in the first month of the year alone. Climate tech startups are at the forefront of building impactful solutions to the climate crisis, and they’re using generative AI to build as quickly as possible.
In this post, we show how climate tech startups are developing foundation models (FMs) that use extensive environmental datasets to tackle issues such as carbon capture, carbon-negative fuels, new materials design for microplastics destruction, and ecosystem preservation. These specialized models require advanced computational capabilities to process and analyze vast amounts of data effectively.
Amazon Web Services (AWS) provides the essential compute infrastructure to support these endeavors, offering scalable and powerful resources through Amazon SageMaker HyperPod. SageMaker HyperPod is a purpose-built infrastructure service that automates the management of large-scale AI training clusters so developers can efficiently build and train complex models such as large language models (LLMs) by automatically handling cluster provisioning, monitoring, and fault tolerance across thousands of GPUs. With SageMaker HyperPod, startups can train complex AI models on diverse environmental datasets, including satellite imagery and atmospheric measurements, with enhanced speed and efficiency. This computational backbone is vital for startups striving to create solutions that are not only innovative but also scalable and impactful.
The increasing complexity of environmental data demands robust data infrastructure and sophisticated model architectures. Integrating multimodal data, employing specialized attention mechanisms for spatial-temporal data, and using reinforcement learning are crucial for building effective climate-focused models. SageMaker HyperPod optimized GPU clustering and scalable resources help startups save time and money while meeting advanced technical requirements, which means they can focus on innovation. As climate technology demands grow, these capabilities allow startups to develop transformative environmental solutions using Amazon SageMaker HyperPod.
Trends among climate tech startups building with generative AI
Climate tech startups’ adoption of generative AI is evolving rapidly. Starting in early 2023, we saw the first wave of climate tech startups adopting generative AI to optimize operations. For example, startups such as BrainBox AI and Pendulum used Amazon Bedrock and fine-tuned existing LLMs on AWS Trainium using Amazon SageMaker to more rapidly onboard new customers through automated document ingestion and data extraction. Midway through 2023, we saw the next wave of climate tech startups building sophisticated intelligent assistants by fine-tuning existing LLMs for specific use cases. For example, NET2GRID used Amazon SageMaker for fine-tuning and deploying scale-based LLMs based on Llama 7B to build EnergyAI, an assistant that provides quick, personalized responses to utility customers’ energy-related questions.
Over the last 6 months, we’ve seen a flurry of climate tech startups building FMs that address specific climate and environmental challenges. Unlike language-based models, these startups are building models based on real-world data, like weather or geospatial earth data. Whereas LLMs such as Anthropic’s Claude or Amazon Nova have hundreds of billions of parameters, climate tech startups are building smaller models with just a few billion parameters. This means these models are faster and less expensive to train. We’re seeing some emerging trends in use cases or climate challenges that startups are addressing by building FMs. Here are the top use cases, in order of popularity:
Weather – Trained on historic weather data, these models offer short-term and long-term, hyperaccurate, hyperlocal weather and climate predictions, some focusing on specific weather elements like wind, heat, or sun.
Sustainable material discovery – Trained on scientific data, these models invent new sustainable material that solve specific problems, like more efficient direct air capture sorbents to reduce the cost of carbon removal or molecules to destroy microplastics from the environment.
Natural ecosystems – Trained on a mix of data from satellites, lidar, and on-the ground sensors, these models offer insights into natural ecosystems, biodiversity, and wildfire predictions.
Geological modeling – Trained on geological data, these models help determine the best locations for geothermal or mining operations to reduce waste and save money.
To offer a more concrete look at these trends, the following is a deep dive into how climate tech startups are building FMs on AWS.
Orbital Materials: Foundation models for sustainable material discovery
Orbital Materials has built a proprietary AI platform to design, synthesize, and test new sustainable materials. Developing new advanced materials has traditionally been a slow process of trial and error in the lab. Orbital replaces this with generative AI design, radically speeding up materials discovery and new technology commercialization. They’ve released a generative AI model called “Orb” that suggests new material design, which the team then tests and perfects in the lab.
Orb is a diffusion model that Orbital Materials trained from scratch using SageMaker HyperPod. The first product the startup designed with Orb is a sorbent for carbon capture in direct air capture facilities. Since establishing its lab in the first quarter of 2024, Orbital has achieved a tenfold improvement in its material’s performance using its AI platform—an order of magnitude faster than traditional development and breaking new ground in carbon removal efficacy. By improving the performance of the materials, the company can help drive down the costs of carbon removal, which can enable rapid scale-up. They chose to use SageMaker HyperPod because they “like the one-stop shop for control and monitoring,” explained Jonathan Godwin, CEO of Orbital Material. Orbital was able to reduce their total cost of ownership (TCO) for their GPU cluster with Amazon SageMaker HyperPod deep health checks for stress testing their GPU instances to swap out faulty nodes. Moreover, Orbital can use SageMaker HyperPod to automatically swap out failing nodes and restart model training from the last saved checkpoint, freeing up time for the Orbital Materials team. The SageMaker HyperPod monitoring agent continually monitors and detects potential issues, including memory exhaustion, disk failures, GPU anomalies, kernel deadlocks, container runtime issues, and out-of-memory (OOM) crashes. Based on the underlying issue the monitoring agent either replaces or reboots the node.
With the launch of SageMaker HyperPod on Amazon Elastic Kubernetes Service (Amazon EKS), Orbital can set up a unified control plane consisting of both CPU-based workloads and GPU-accelerated tasks within the same Kubernetes cluster. This architectural approach eliminates the traditional complexity of managing separate clusters for different compute resources, significantly reducing operational overhead. Orbital can also monitor the health status of SageMaker HyperPod nodes through Amazon CloudWatch Container Insights with enhanced observability for Amazon EKS. Amazon CloudWatch Container Insights collects, aggregates, and summarizes metrics and logs from containerized applications and microservices, providing detailed insights into performance, health, and status metrics for CPU, GPU, Trainium, or Elastic Fabric Adapter (EFA) and file system up to the container level.
AWS and Orbital Materials have established a deep partnership that enables fly-wheel growth. The companies have entered a multiyear partnership, in which Orbital Material builds its FMs with SageMaker HyperPod and other AWS services. In return, Orbital Materials is using AI to develop new data center decarbonization and efficiency technologies. To further spin the fly-wheel, Orbital will be making its market-leading open source AI model for simulating advanced materials, Orb, generally available for AWS customers by using Amazon SageMaker JumpStart and AWS Marketplace. This marks the first AI-for-materials model to be on AWS platforms. With Orb, AWS customers working on advanced materials and technologies such as semiconductors, batteries, and electronics can access market-leading accelerated research and development (R&D) within a secure and unified cloud environment.
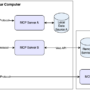
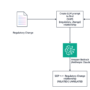
The architectural advantages of SageMaker HyperPod on Amazon EKS are demonstrated in the following diagram. The diagram illustrates how Orbital can establish a unified control plane that manages both CPU-based workloads and GPU-accelerated tasks within a single Kubernetes cluster. This streamlined architecture eliminates the traditional complexity of managing separate clusters for different compute resources, providing a more efficient and integrated approach to resource management. The visualization shows how this consolidated infrastructure enables Orbital to seamlessly orchestrate their diverse computational needs through a single control interface.
Hum.AI: Foundation models for earth observation
Hum.AI is building generative AI FMs that provide general intelligence of the natural world. Customers can use the platform to track and predict ecosystems and biodiversity to understand business impact and better protect the environment. For example, they work with coastal communities who use the platform and insights to restore coastal ecosystems and improve biodiversity.
Hum.AI’s foundation model looks at natural world data and learns to represent it visually. They’re training on 50 years of historic data collected by satellites, which amounts to thousands of petabytes of data. To accommodate processing this massive dataset, they chose SageMaker HyperPod for its scalable infrastructure. Through their innovative model architecture, the company achieved the ability to see underwater from space for the very first time, overcoming the historical challenges posed by water reflections
Hum.AI’s FM architecture employs a variational autoencoder (VAE) and generative adversarial network (GAN) hybrid design, specifically optimized for satellite imagery analysis. It’s an encoder-decoder model, where the encoder transforms satellite data into a learned latent space, while the decoder reconstructs the imagery (after being processed in the latent space), maintaining consistency across different satellite sources. The discriminator network provides both adversarial training signals and learned feature-wise reconstruction metrics. This approach helps preserve important ecosystem details that would otherwise be lost with traditional pixel-based comparisons, particularly for underwater environments, where water reflections typically interfere with visibility.
Using SageMaker HyperPod to train such a complex model enables Hum.AI to efficiently process their personally curated SeeFar dataset through distributed training across multiple GPU-based instances. The model simultaneously optimizes both VAE and GAN objectives across GPUs. This, paired with the SageMaker HyperPod auto-resume feature that automatically resumes a training run from the latest checkpoint, provides training continuity, even through node failures.
Hum.AI also used the SageMaker HyperPod out-of-the-box comprehensive observability features through Amazon Managed Service for Prometheus and Amazon Managed Service for Grafana for metric tracking. For their distributed training needs, they used dashboards to monitor cluster performance, GPU metrics, network traffic, and storage operations. This extensive monitoring infrastructure enabled Hum.AI to optimize their training process and maintain high resource utilization throughout their model development.
“Our decision to use SageMaker HyperPod was simple; it was the only service out there where you can continue training through failure. We were able to train larger models faster by taking advantage of the large-scale clusters and redundancy offered by SageMaker HyperPod. We were able to execute experiments faster and iterate models at speeds that were impossible prior to SageMaker HyperPod. SageMaker HyperPod took all of the worry out of large-scale training failures. They’ve built the infrastructure to hot swap GPUs if anything goes wrong, and it saves thousands in lost progress between checkpoints. The SageMaker HyperPod team personally helped us set up and execute large training rapidly and easily.”
– Kelly Zheng, CEO of Hum.AI.
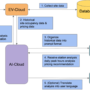
Hum.AI’s innovative approach to model training is illustrated in the following figure. The diagram showcases how their model simultaneously optimizes both VAE and GAN objectives across multiple GPUs. This distributed training strategy is complemented by the SageMaker HyperPod auto-resume feature, which automatically restarts training runs from the latest checkpoint. Together, these capabilities provide continual and efficient training, even in the face of potential node failures. The image provides a visual representation of this robust training process, highlighting the seamless integration between Hum.AI’s model architecture and SageMaker HyperPod infrastructure support.
How to save time and money building with Amazon SageMaker HyperPod
Amazon SageMaker HyperPod removes the undifferentiated heavy lifting for climate tech startups building FMs, saving them time and money. For more information on how SageMaker HyperPod’s resiliency helps save costs while training, check out Reduce ML training costs with Amazon SageMaker HyperPod.
At its core is deep infrastructure control optimized for processing complex environmental data, featuring secure access to Amazon Elastic Compute Cloud (Amazon EC2) instances and seamless integration with orchestration tools such as Slurm and Amazon EKS. This infrastructure excels at handling multimodal environmental inputs, from satellite imagery to sensor network data, through distributed training across thousands of accelerators.
The intelligent resource management available in SageMaker HyperPod is particularly valuable for climate modeling, automatically governing task priorities and resource allocation while reducing operational overhead by up to 40%. This efficiency is crucial for climate tech startups processing vast environmental datasets because the system maintains progress through checkpointing while making sure that critical climate modeling workloads receive necessary resources.
For climate tech innovators, the SageMaker HyperPod library of over 30 curated model training recipes accelerates development, allowing teams to begin training environmental models in minutes rather than weeks. The platform’s integration with Amazon EKS provides robust fault tolerance and high availability, essential for maintaining continual environmental monitoring and analysis.
SageMaker HyperPod flexible training plans are particularly beneficial for climate tech projects, allowing organizations to specify completion dates and resource requirements while automatically optimizing capacity for complex environmental data processing. The system’s ability to suggest alternative plans provides optimal resource utilization for computationally intensive climate modeling tasks.With support for next-generation AI accelerators such as the AWS Trainium chips and comprehensive monitoring tools, SageMaker HyperPod provides climate tech startups with a sustainable and efficient foundation for developing sophisticated environmental solutions. This infrastructure enables organizations to focus on their core mission of addressing climate challenges while maintaining operational efficiency and environmental responsibility.
Practices for sustainable computing
Climate tech companies are especially aware of the importance of sustainable computing practices. One key approach is the meticulous monitoring and optimization of energy consumption during computational processes. By adopting efficient training strategies, such as reducing the number of unnecessary training iterations and employing energy-efficient algorithms, startups can significantly lower their carbon footprint.
Additionally, the integration of renewable energy sources to power data centers plays a crucial role in minimizing environmental impact. AWS is determined to make the cloud the cleanest and the most energy-efficient way to run all our customers’ infrastructure and business. We have made significant progress over the years. For example, Amazon is the largest corporate purchaser of renewable energy in the world, every year since 2020. We’ve achieved our renewable energy goal to match all the electricity consumed across our operations—including our data centers—with 100% renewable energy, and we did this 7 years ahead of our original 2030 timeline.
Companies are also turning to carbon-aware computing principles, which involve scheduling computational tasks to coincide with periods of low carbon intensity on the grid. This practice means that the energy used for computing has a lower environmental impact. Implementing these strategies not only aligns with broader sustainability goals but also promotes cost efficiency and resource conservation. As the demand for advanced computational capabilities grows, climate tech startups are becoming vigilant in their commitment to sustainable practices so that their innovations contribute positively to both technological progress and environmental stewardship.
Conclusion
Amazon SageMaker HyperPod is emerging as a crucial tool for climate tech startups in their quest to develop innovative solutions to pressing environmental challenges. By providing scalable, efficient, and cost-effective infrastructure for training complex multimodal and multi- model architectures, SageMaker HyperPod enables these companies to process vast amounts of environmental data and create sophisticated predictive models. From Orbital Materials’ sustainable material discovery to Hum.AI’s advanced earth observation capabilities, SageMaker HyperPod is powering breakthroughs that were previously out of reach. As climate change continues to pose urgent global challenges, SageMaker HyperPod automated management of large-scale AI training clusters, coupled with its fault-tolerance and cost-optimization features, allows climate tech innovators to focus on their core mission rather than infrastructure management. By using SageMaker HyperPod, climate tech startups are not only building more efficient models—they’re accelerating the development of powerful new tools in our collective effort to address the global climate crisis.
About the authors
Ilan Gleiser is a Principal GenAI Specialist at Amazon Web Services (AWS) on the WWSO Frameworks team, focusing on developing scalable artificial general intelligence architectures and optimizing foundation model training and inference. With a rich background in AI and machine learning, Ilan has published over 30 blog posts and delivered more than 100 prototypes globally over the last 5 years. Ilan holds a master’s degree in mathematical economics.
Lisbeth Kaufman is the Head of Climate Tech BD, Startups and Venture Capital at Amazon Web Services (AWS). Her mission is to help the best climate tech startups succeed and reverse the global climate crisis. Her team has technical resources, go-to-market support, and connections to help climate tech startups overcome obstacles and scale. Lisbeth worked on climate policy as an energy/environment/agriculture policy advisor in the U.S. Senate. She has a BA from Yale and an MBA from NYU Stern, where she was a Dean’s Scholar. Lisbeth helps climate tech founders with product, growth, fundraising, and making strategic connections to teams at AWS and Amazon.
Aman Shanbhag is an Associate Specialist Solutions Architect on the ML Frameworks team at Amazon Web Services (AWS), where he helps customers and partners with deploying ML training and inference solutions at scale. Before joining AWS, Aman graduated from Rice University with degrees in computer science, mathematics, and entrepreneurship.
Rohit Talluri is a Generative AI GTM Specialist at Amazon Web Services (AWS). He is partnering with top generative AI model builders, strategic customers, key AI/ML partners, and AWS Service Teams to enable the next generation of artificial intelligence, machine learning, and accelerated computing on AWS. He was previously an Enterprise Solutions Architect and the Global Solutions Lead for AWS Mergers & Acquisitions Advisory.
Ankit Anand is a Senior Foundation Models Go-To-Market (GTM) Specialist at AWS. He partners with top generative AI model builders, strategic customers, and AWS Service Teams to enable the next generation of AI/ML workloads on AWS. Ankit’s experience includes product management expertise within the financial services industry for high-frequency/low-latency trading and business development for Amazon Alexa.