For an AI model to perform effectively in specialized domains, it requires access to relevant background knowledge. A customer support chat assistant, for instance, needs detailed information about the business it serves, and a legal analysis tool must draw upon a comprehensive database of past cases.
To equip large language models (LLMs) with this knowledge, developers often use Retrieval Augmented Generation (RAG). This technique retrieves pertinent information from a knowledge base and incorporates it into the user’s prompt, significantly improving the model’s responses. However, a key limitation of traditional RAG systems is that they often lose contextual nuances when encoding data, leading to irrelevant or incomplete retrievals from the knowledge base.
Challenges in traditional RAG
In traditional RAG, documents are often divided into smaller chunks to optimize retrieval efficiency. Although this method performs well in many cases, it can introduce challenges when individual chunks lack the necessary context. For example, if a policy states that remote work requires “6 months of tenure” (chunk 1) and “HR approval for exceptions” (chunk 3), but omits the middle chunk linking exceptions to manager approval, a user asking about eligibility for a 3-month tenure employee might receive a misleading “No” instead of the correct “Only with HR approval.” This occurs because isolated chunks fail to preserve dependencies between clauses, highlighting a key limitation of basic chunking strategies in RAG systems.
Contextual retrieval enhances traditional RAG by adding chunk-specific explanatory context to each chunk before generating embeddings. This approach enriches the vector representation with relevant contextual information, enabling more accurate retrieval of semantically related content when responding to user queries. For instance, when asked about remote work eligibility, it fetches both the tenure requirement and the HR exception clause, enabling the LLM to provide an accurate response such as “Normally no, but HR may approve exceptions.” By intelligently stitching fragmented information, contextual retrieval mitigates the pitfalls of rigid chunking, delivering more reliable and nuanced answers.
In this post, we demonstrate how to use contextual retrieval with Anthropic and Amazon Bedrock Knowledge Bases.
Solution overview
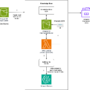
This solution uses Amazon Bedrock Knowledge Bases, incorporating a custom Lambda function to transform data during the knowledge base ingestion process. This Lambda function processes documents from Amazon Simple Storage Service (Amazon S3), chunks them into smaller pieces, enriches each chunk with contextual information using Anthropic’s Claude in Amazon Bedrock, and then saves the results back to an intermediate S3 bucket. Here’s a step-by-step explanation:
Read input files from an S3 bucket specified in the event.
Chunk input data into smaller chunks.
Generate contextual information for each chunk using Anthropic’s Claude 3 Haiku
Write processed chunks with their metadata back to intermediate S3 bucket
The following diagram is the solution architecture.
Prerequisites
To implement the solution, complete the following prerequisite steps:
Have an active AWS account.
Create an AWS Identity and Access Management (IAM) role for the Lambda function to access Amazon Bedrock and documents from Amazon S3. For instructions, refer to Create a role to delegate permissions to an AWS service.
Add policy permissions to the IAM role.
Request access to Amazon Titan and Anthropic’s Claude 3 Haiku models in Amazon Bedrock.
Before you begin, you can deploy this solution by downloading the required files and following the instructions in its corresponding GitHub repository. This architecture is built around using the proposed chunking solution to implement contextual retrieval using Amazon Bedrock Knowledge Bases.
Implement contextual retrieval in Amazon Bedrock
In this section, we demonstrate how to use the proposed custom chunking solution to implement contextual retrieval using Amazon Bedrock Knowledge Bases. Developers can use custom chunking strategies in Amazon Bedrock to optimize how large documents or datasets are divided into smaller, more manageable pieces for processing by foundation models (FMs). This approach enables more efficient and effective handling of long-form content, improving the quality of responses. By tailoring the chunking method to the specific characteristics of the data and the requirements of the task at hand, developers can enhance the performance of natural language processing applications built on Amazon Bedrock. Custom chunking can involve techniques such as semantic segmentation, sliding windows with overlap, or using document structure to create logical divisions in the text.
To implement contextual retrieval in Amazon Bedrock, complete the following steps, which can be found in the notebook in the GitHub repository.
To set up the environment, follow these steps:
Install the required dependencies:
%pip install –upgrade pip –quiet %pip install -r requirements.txt –no-deps
Import the required libraries and set up AWS clients:
import os
import sys
import time
import boto3
import logging
import pprint
import json
from pathlib import Path
# AWS Clients Setup
s3_client = boto3.client(‘s3’)
sts_client = boto3.client(‘sts’)
session = boto3.session.Session()
region = session.region_name
account_id = sts_client.get_caller_identity()[“Account”]
bedrock_agent_client = boto3.client(‘bedrock-agent’)
bedrock_agent_runtime_client = boto3.client(‘bedrock-agent-runtime’)
# Configure logging
logging.basicConfig(
format='[%(asctime)s] p%(process)s {%(filename)s:%(lineno)d} %(levelname)s – %(message)s’,
level=logging.INFO
)
logger = logging.getLogger(__name__)
Define knowledge base parameters:
# Generate unique suffix for resource names
timestamp_str = time.strftime(“%Y%m%d%H%M%S”, time.localtime(time.time()))[-7:]
suffix = f”{timestamp_str}”
# Resource names
knowledge_base_name_standard = ‘standard-kb’
knowledge_base_name_custom = ‘custom-chunking-kb’
knowledge_base_description = “Knowledge Base containing complex PDF.”
bucket_name = f'{knowledge_base_name_standard}-{suffix}’
intermediate_bucket_name = f'{knowledge_base_name_standard}-intermediate-{suffix}’
lambda_function_name = f'{knowledge_base_name_custom}-lambda-{suffix}’
foundation_model = “anthropic.claude-3-sonnet-20240229-v1:0”
# Define data sources
data_source=[{“type”: “S3”, “bucket_name”: bucket_name}]
Create knowledge bases with different chunking strategies
To create knowledge bases with different chunking strategies, use the following code.
Standard fixed chunking:
# Create knowledge base with fixed chunking
knowledge_base_standard = BedrockKnowledgeBase(
kb_name=f'{knowledge_base_name_standard}-{suffix}’,
kb_description=knowledge_base_description,
data_sources=data_source,
chunking_strategy=”FIXED_SIZE”,
suffix=f'{suffix}-f’
)
# Upload data to S3
def upload_directory(path, bucket_name):
for root, dirs, files in os.walk(path):
for file in files:
file_to_upload = os.path.join(root, file)
if file not in [“LICENSE”, “NOTICE”, “README.md”]:
print(f”uploading file {file_to_upload} to {bucket_name}”)
s3_client.upload_file(file_to_upload, bucket_name, file)
else:
print(f”Skipping file {file_to_upload}”)
upload_directory(“../synthetic_dataset”, bucket_name)
# Start ingestion job
time.sleep(30) # ensure KB is available
knowledge_base_standard.start_ingestion_job()
kb_id_standard = knowledge_base_standard.get_knowledge_base_id()
Custom chunking with Lambda function
# Create Lambda function for custom chunking
def create_lambda_function():
with open(‘lambda_function.py’, ‘r’) as file:
lambda_code = file.read()
response = lambda_client.create_function(
FunctionName=lambda_function_name,
Runtime=’python3.9′,
Role=lambda_role_arn,
Handler=’lambda_function.lambda_handler’,
Code={‘ZipFile’: lambda_code.encode()},
Timeout=900,
MemorySize=256
)
return response[‘FunctionArn’]
# Create knowledge base with custom chunking
knowledge_base_custom = BedrockKnowledgeBase(
kb_name=f'{knowledge_base_name_custom}-{suffix}’,
kb_description=knowledge_base_description,
data_sources=data_source,
lambda_function_name=lambda_function_name,
intermediate_bucket_name=intermediate_bucket_name,
chunking_strategy=”CUSTOM”,
suffix=f'{suffix}-c’
)
# Start ingestion job
time.sleep(30)
knowledge_base_custom.start_ingestion_job()
kb_id_custom = knowledge_base_custom.get_knowledge_base_id()
Evaluate performance using RAGAS framework
To evaluate performance using the RAGAS framework, follow these steps:
Set up RAGAS evaluation:
from ragas import SingleTurnSample, EvaluationDataset
from ragas import evaluate
from ragas.metrics import (
context_recall,
context_precision,
answer_correctness
)
# Initialize Bedrock models for evaluation
TEXT_GENERATION_MODEL_ID = “anthropic.claude-3-haiku-20240307-v1:0”
EVALUATION_MODEL_ID = “anthropic.claude-3-sonnet-20240229-v1:0″
llm_for_evaluation = ChatBedrock(model_id=EVALUATION_MODEL_ID, client=bedrock_client)
bedrock_embeddings = BedrockEmbeddings(
model_id=”amazon.titan-embed-text-v2:0”,
client=bedrock_client
)
Prepare evaluation dataset:
# Define test questions and ground truths
questions = [
“What was the primary reason for the increase in net cash provided by operating activities for Octank Financial in 2021?”,
“In which year did Octank Financial have the highest net cash used in investing activities, and what was the primary reason for this?”,
# Add more questions…
]
ground_truths = [
“The increase in net cash provided by operating activities was primarily due to an increase in net income and favorable changes in operating assets and liabilities.”,
“Octank Financial had the highest net cash used in investing activities in 2021, at $360 million…”,
# Add corresponding ground truths…
]
def prepare_eval_dataset(kb_id, questions, ground_truths):
samples = []
for question, ground_truth in zip(questions, ground_truths):
# Get response and context
response = retrieve_and_generate(question, kb_id)
answer = response[“output”][“text”]
# Process contexts
contexts = []
for citation in response[“citations”]:
context_texts = [
ref[“content”][“text”]
for ref in citation[“retrievedReferences”]
if “content” in ref and “text” in ref[“content”]
]
contexts.extend(context_texts)
# Create sample
sample = SingleTurnSample(
user_input=question,
retrieved_contexts=contexts,
response=answer,
reference=ground_truth
)
samples.append(sample)
return EvaluationDataset(samples=samples)
Run evaluation and compare results:
# Evaluate both approaches
contextual_chunking_dataset = prepare_eval_dataset(kb_id_custom, questions, ground_truths)
default_chunking_dataset = prepare_eval_dataset(kb_id_standard, questions, ground_truths)
# Define metrics
metrics = [context_recall, context_precision, answer_correctness]
# Run evaluation
contextual_chunking_result = evaluate(
dataset=contextual_chunking_dataset,
metrics=metrics,
llm=llm_for_evaluation,
embeddings=bedrock_embeddings,
)
default_chunking_result = evaluate(
dataset=default_chunking_dataset,
metrics=metrics,
llm=llm_for_evaluation,
embeddings=bedrock_embeddings,
)
# Compare results
comparison_df = pd.DataFrame({
‘Default Chunking’: default_chunking_result.to_pandas().mean(),
‘Contextual Chunking’: contextual_chunking_result.to_pandas().mean()
})
# Visualize results
def highlight_max(s):
is_max = s == s.max()
return [‘background-color: #90EE90’ if v else ” for v in is_max]
comparison_df.style.apply(
highlight_max,
axis=1,
subset=[‘Default Chunking’, ‘Contextual Chunking’]
Performance benchmarks
To evaluate the performance of the proposed contextual retrieval approach, we used the AWS Decision Guide: Choosing a generative AI service as the document for RAG testing. We set up two Amazon Bedrock knowledge bases for the evaluation:
One knowledge base with the default chunking strategy, which uses 300 tokens per chunk with a 20% overlap
Another knowledge base with the custom contextual retrieval chunking approach, which has a custom contextual retrieval Lambda transformer in addition to the fixed chunking strategy that also uses 300 tokens per chunk with a 20% overlap
We used the RAGAS framework to assess the performance of these two approaches using small datasets. Specifically, we looked at the following metrics:
context_recall – Context recall measures how many of the relevant documents (or pieces of information) were successfully retrieved
context_precision – Context precision is a metric that measures the proportion of relevant chunks in the retrieved_contexts
answer_correctness – The assessment of answer correctness involves gauging the accuracy of the generated answer when compared to the ground truth
from ragas import SingleTurnSample, EvaluationDataset
from ragas import evaluate
from ragas.metrics import (
context_recall,
context_precision,
answer_correctness
)
#specify the metrics here
metrics = [
context_recall,
context_precision,
answer_correctness
]
questions = [
“What are the main AWS generative AI services covered in this guide?”,
“How does Amazon Bedrock differ from the other generative AI services?”,
“What are some key factors to consider when choosing a foundation model for your use case?”,
“What infrastructure services does AWS offer to support training and inference of large AI models?”,
“Where can I find more resources and information related to the AWS generative AI services?”
]
ground_truths = [
“The main AWS generative AI services covered in this guide are Amazon Q Business, Amazon Q Developer, Amazon Bedrock, and Amazon SageMaker AI.”,
“Amazon Bedrock is a fully managed service that allows you to build custom generative AI applications with a choice of foundation models, including the ability to fine-tune and customize the models with your own data.”,
“Key factors to consider when choosing a foundation model include the modality (text, image, etc.), model size, inference latency, context window, pricing, fine-tuning capabilities, data quality and quantity, and overall quality of responses.”,
“AWS offers specialized hardware like AWS Trainium and AWS Inferentia to maximize the performance and cost-efficiency of training and inference for large AI models.”,
“You can find more resources like architecture diagrams, whitepapers, and solution guides on the AWS website. The document also provides links to relevant blog posts and documentation for the various AWS generative AI services.”
]
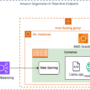
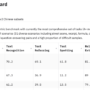
The results obtained using the default chunking strategy are presented in the following table.
The results obtained using the contextual retrieval chunking strategy are presented in the following table. It demonstrates improved performance across the key metrics evaluated, including context recall, context precision, and answer correctness.
By aggregating the results, we can observe that the contextual chunking approach outperformed the default chunking strategy across the context_recall, context_precision, and answer_correctness metrics. This indicates the benefits of the more sophisticated contextual retrieval techniques implemented.
Implementation considerations
When implementing contextual retrieval using Amazon Bedrock, several factors need careful consideration. First, the custom chunking strategy must be optimized for both performance and accuracy, requiring thorough testing across different document types and sizes. The Lambda function’s memory allocation and timeout settings should be calibrated based on the expected document complexity and processing requirements, with initial recommendations of 1024 MB memory and 900-second timeout serving as baseline configurations. Organizations must also configure IAM roles with the principle of least privilege while maintaining sufficient permissions for Lambda to interact with Amazon S3 and Amazon Bedrock services. Additionally, the vectorization process and knowledge base configuration should be fine-tuned to balance between retrieval accuracy and computational efficiency, particularly when scaling to larger datasets.
Infrastructure scalability and monitoring considerations are equally crucial for successful implementation. Organizations should implement robust error-handling mechanisms within the Lambda function to manage various document formats and potential processing failures gracefully. Monitoring systems should be established to track key metrics such as chunking performance, retrieval accuracy, and system latency, enabling proactive optimization and maintenance.
Using Langfuse with Amazon Bedrock is a good option to introduce observability to this solution. The S3 bucket structure for both source and intermediate storage should be designed with clear lifecycle policies and access controls and consider Regional availability and data residency requirements. Furthermore, implementing a staged deployment approach, starting with a subset of data before scaling to full production workloads, can help identify and address potential bottlenecks or optimization opportunities early in the implementation process.
Cleanup
When you’re done experimenting with the solution, clean up the resources you created to avoid incurring future charges.
Conclusion
By combining Anthropic’s sophisticated language models with the robust infrastructure of Amazon Bedrock, organizations can now implement intelligent systems for information retrieval that deliver deeply contextualized, nuanced responses. The implementation steps outlined in this post provide a clear pathway for organizations to use contextual retrieval capabilities through Amazon Bedrock. By following the detailed configuration process, from setting up IAM permissions to deploying custom chunking strategies, developers and organizations can unlock the full potential of context-aware AI systems.
By leveraging Anthropic’s language models, organizations can deliver more accurate and meaningful results to their users while staying at the forefront of AI innovation. You can get started today with contextual retrieval using Anthropic’s language models through Amazon Bedrock and transform how your AI processes information with a small-scale proof of concept using your existing data. For personalized guidance on implementation, contact your AWS account team.
About the Authors
Suheel Farooq is a Principal Engineer in AWS Support Engineering, specializing in Generative AI, Artificial Intelligence, and Machine Learning. As a Subject Matter Expert in Amazon Bedrock and SageMaker, he helps enterprise customers design, build, modernize, and scale their AI/ML and Generative AI workloads on AWS. In his free time, Suheel enjoys working out and hiking.
Qingwei Li is a Machine Learning Specialist at Amazon Web Services. He received his Ph.D. in Operations Research after he broke his advisor’s research grant account and failed to deliver the Nobel Prize he promised. Currently he helps customers in the financial service and insurance industry build machine learning solutions on AWS. In his spare time, he likes reading and teaching.
Vinita is a Senior Serverless Specialist Solutions Architect at AWS. She combines AWS knowledge with strong business acumen to architect innovative solutions that drive quantifiable value for customers and has been exceptional at navigating complex challenges. Vinita’s technical expertise on application modernization, GenAI, cloud computing and ability to drive measurable business impact make her show great impact in customer’s journey with AWS.
Sharon Li is an AI/ML Specialist Solutions Architect at Amazon Web Services (AWS) based in Boston, Massachusetts. With a passion for leveraging cutting-edge technology, Sharon is at the forefront of developing and deploying innovative generative AI solutions on the AWS cloud platform.
Venkata Moparthi is a Senior Solutions Architect, specializes in cloud migrations, generative AI, and secure architecture for financial services and other industries. He combines technical expertise with customer-focused strategies to accelerate digital transformation and drive business outcomes through optimized cloud solutions.