In this advanced tutorial, we aim to build a multi-agent task automation system using the PrimisAI Nexus framework, which is fully integrated with the OpenAI API. Our primary objective is to demonstrate how hierarchical supervision, intelligent tool utilization, and structured outputs can facilitate the coordination of multiple AI agents to perform complex tasks, ranging from planning and development to quality assurance and data analysis. As we walk through each phase, we don’t just build individual agents; we architect a collaborative ecosystem where each agent has a clear role, responsibilities, and smart tools to accomplish the task.
Copy CodeCopiedUse a different Browser!pip install primisai openai nest-asyncio
import os
import nest_asyncio
from primisai.nexus.core import AI, Agent, Supervisor
from primisai.nexus.utils.debugger import Debugger
import json
nest_asyncio.apply()
We begin by installing the core dependencies: Primisai for agent orchestration, OpenAI for LLM access, and nest_asyncio to handle Colab’s event loop quirks. After applying nest_asyncio, we ensure the notebook is ready to execute asynchronous tasks seamlessly, a key requirement for multi-agent execution.
Copy CodeCopiedUse a different Browserprint(” PrimisAI Nexus Advanced Tutorial with OpenAI API”)
print(“=” * 55)
os.environ[“OPENAI_API_KEY”] = “Use Your Own API Key Here5”
# llm_config = {
# “api_key”: os.environ[“OPENAI_API_KEY”],
# “model”: “gpt-4o-mini”,
# “base_url”: “https://api.openai.com/v1”,
# “temperature”: 0.7
# }
llm_config = {
“api_key”: os.environ[“OPENAI_API_KEY”],
“model”: “gpt-3.5-turbo”,
“base_url”: “https://api.openai.com/v1”,
“temperature”: 0.7
}
print(” API Configuration:”)
print(f”• Model: {llm_config[‘model’]}”)
print(f”• Base URL: {llm_config[‘base_url’]}”)
print(“• Note: OpenAI has limited free tokens through April 2025”)
print(“• Alternative: Consider Puter.js for unlimited free access”)
To power our agents, we connect to OpenAI’s models, starting with gpt-3.5-turbo for cost-efficient tasks. We store our API key in environment variables and construct a configuration dictionary specifying the model, temperature, and base URL. This section allows us to flexibly switch between models, such as gpt-4o-mini or gpt-4o, depending on task complexity and cost.
Copy CodeCopiedUse a different Browsercode_schema = {
“type”: “object”,
“properties”: {
“description”: {“type”: “string”, “description”: “Code explanation”},
“code”: {“type”: “string”, “description”: “Python code implementation”},
“language”: {“type”: “string”, “description”: “Programming language”},
“complexity”: {“type”: “string”, “enum”: [“beginner”, “intermediate”, “advanced”]},
“test_cases”: {“type”: “array”, “items”: {“type”: “string”}, “description”: “Example usage”}
},
“required”: [“description”, “code”, “language”]
}
analysis_schema = {
“type”: “object”,
“properties”: {
“summary”: {“type”: “string”, “description”: “Brief analysis summary”},
“insights”: {“type”: “array”, “items”: {“type”: “string”}, “description”: “Key insights”},
“recommendations”: {“type”: “array”, “items”: {“type”: “string”}, “description”: “Action items”},
“confidence”: {“type”: “number”, “minimum”: 0, “maximum”: 1},
“methodology”: {“type”: “string”, “description”: “Analysis approach used”}
},
“required”: [“summary”, “insights”, “confidence”]
}
planning_schema = {
“type”: “object”,
“properties”: {
“tasks”: {“type”: “array”, “items”: {“type”: “string”}, “description”: “List of tasks to complete”},
“priority”: {“type”: “string”, “enum”: [“low”, “medium”, “high”]},
“estimated_time”: {“type”: “string”, “description”: “Time estimate”},
“dependencies”: {“type”: “array”, “items”: {“type”: “string”}, “description”: “Task dependencies”}
},
“required”: [“tasks”, “priority”]
}
We define JSON schemas for three agent types: CodeWriter, Data Analyst, and Project Planner. These schemas enforce structure in the agent’s responses, making the output machine-readable and predictable. It helps us ensure that the system returns consistent data, such as code blocks, insights, or project timelines, even when different LLMs are behind the scenes.
Copy CodeCopiedUse a different Browserdef calculate_metrics(data_str):
“””Calculate comprehensive statistics for numerical data”””
try:
data = json.loads(data_str) if isinstance(data_str, str) else data_str
if isinstance(data, list) and all(isinstance(x, (int, float)) for x in data):
import statistics
return {
“mean”: statistics.mean(data),
“median”: statistics.median(data),
“mode”: statistics.mode(data) if len(set(data)) < len(data) else “No mode”,
“std_dev”: statistics.stdev(data) if len(data) > 1 else 0,
“max”: max(data),
“min”: min(data),
“count”: len(data),
“sum”: sum(data)
}
return {“error”: “Invalid data format – expecting array of numbers”}
except Exception as e:
return {“error”: f”Could not parse data: {str(e)}”}
def validate_code(code):
“””Advanced code validation with syntax and basic security checks”””
try:
dangerous_imports = [‘os’, ‘subprocess’, ‘eval’, ‘exec’, ‘__import__’]
security_warnings = []
for danger in dangerous_imports:
if danger in code:
security_warnings.append(f”Potentially dangerous: {danger}”)
compile(code, ‘<string>’, ‘exec’)
return {
“valid”: True,
“message”: “Code syntax is valid”,
“security_warnings”: security_warnings,
“lines”: len(code.split(‘n’))
}
except SyntaxError as e:
return {
“valid”: False,
“message”: f”Syntax error: {e}”,
“line”: getattr(e, ‘lineno’, ‘unknown’),
“security_warnings”: []
}
def search_documentation(query):
“””Simulate searching documentation (placeholder function)”””
docs = {
“python”: “Python is a high-level programming language”,
“list”: “Lists are ordered, mutable collections in Python”,
“function”: “Functions are reusable blocks of code”,
“class”: “Classes define objects with attributes and methods”
}
results = []
for key, value in docs.items():
if query.lower() in key.lower():
results.append(f”{key}: {value}”)
return {
“query”: query,
“results”: results if results else [“No documentation found”],
“total_results”: len(results)
}
Next, we add custom tools that agents could call, such as calculate_metrics for statistical summaries, validate_code for syntax and security checks, and search_documentation for simulated programming help. These tools extend the agents’ abilities, turning them from simple chatbots into interactive, utility-driven workers capable of autonomous reasoning and validation.
Copy CodeCopiedUse a different Browserprint(“n Setting up Multi-Agent Hierarchy with OpenAI”)
main_supervisor = Supervisor(
name=”ProjectManager”,
llm_config=llm_config,
system_message=”You are a senior project manager coordinating development and analysis tasks. Delegate appropriately, provide clear summaries, and ensure quality delivery. Always consider time estimates and dependencies.”
)
dev_supervisor = Supervisor(
name=”DevManager”,
llm_config=llm_config,
is_assistant=True,
system_message=”You manage development tasks. Coordinate between coding, testing, and code review. Ensure best practices and security.”
)
analysis_supervisor = Supervisor(
name=”AnalysisManager”,
llm_config=llm_config,
is_assistant=True,
system_message=”You manage data analysis and research tasks. Ensure thorough analysis, statistical rigor, and actionable insights.”
)
qa_supervisor = Supervisor(
name=”QAManager”,
llm_config=llm_config,
is_assistant=True,
system_message=”You manage quality assurance and testing. Ensure thorough validation and documentation.”
)
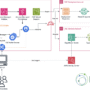
To simulate a real-world management structure, we create a multi-tiered hierarchy. A ProjectManager serves as the root supervisor, overseeing three assistant supervisors (DevManager, AnalysisManager, and QAManager), each in charge of domain-specific agents. This modular hierarchy allows tasks to flow down from high-level strategy to granular execution.
Copy CodeCopiedUse a different Browsercode_agent = Agent(
name=”CodeWriter”,
llm_config=llm_config,
system_message=”You are an expert Python developer. Write clean, efficient, well-documented code with proper error handling. Always include test cases and follow PEP 8 standards.”,
output_schema=code_schema,
tools=[{
“metadata”: {
“function”: {
“name”: “validate_code”,
“description”: “Validates Python code syntax and checks for security issues”,
“parameters”: {
“type”: “object”,
“properties”: {
“code”: {“type”: “string”, “description”: “Python code to validate”}
},
“required”: [“code”]
}
}
},
“tool”: validate_code
}, {
“metadata”: {
“function”: {
“name”: “search_documentation”,
“description”: “Search for programming documentation and examples”,
“parameters”: {
“type”: “object”,
“properties”: {
“query”: {“type”: “string”, “description”: “Documentation topic to search for”}
},
“required”: [“query”]
}
}
},
“tool”: search_documentation
}],
use_tools=True
)
review_agent = Agent(
name=”CodeReviewer”,
llm_config=llm_config,
system_message=”You are a senior code reviewer. Analyze code for best practices, efficiency, security, maintainability, and potential issues. Provide constructive feedback and suggestions.”,
keep_history=True,
tools=[{
“metadata”: {
“function”: {
“name”: “validate_code”,
“description”: “Validates code syntax and security”,
“parameters”: {
“type”: “object”,
“properties”: {
“code”: {“type”: “string”, “description”: “Code to validate”}
},
“required”: [“code”]
}
}
},
“tool”: validate_code
}],
use_tools=True
)
analyst_agent = Agent(
name=”DataAnalyst”,
llm_config=llm_config,
system_message=”You are a data scientist specializing in statistical analysis and insights generation. Provide thorough analysis with confidence metrics and actionable recommendations.”,
output_schema=analysis_schema,
tools=[{
“metadata”: {
“function”: {
“name”: “calculate_metrics”,
“description”: “Calculates comprehensive statistics for numerical data”,
“parameters”: {
“type”: “object”,
“properties”: {
“data_str”: {“type”: “string”, “description”: “JSON string of numerical data array”}
},
“required”: [“data_str”]
}
}
},
“tool”: calculate_metrics
}],
use_tools=True
)
planner_agent = Agent(
name=”ProjectPlanner”,
llm_config=llm_config,
system_message=”You are a project planning specialist. Break down complex projects into manageable tasks with realistic time estimates and clear dependencies.”,
output_schema=planning_schema
)
tester_agent = Agent(
name=”QATester”,
llm_config=llm_config,
system_message=”You are a QA specialist focused on comprehensive testing strategies, edge cases, and quality assurance.”,
tools=[{
“metadata”: {
“function”: {
“name”: “validate_code”,
“description”: “Validates code for testing”,
“parameters”: {
“type”: “object”,
“properties”: {
“code”: {“type”: “string”, “description”: “Code to test”}
},
“required”: [“code”]
}
}
},
“tool”: validate_code
}],
use_tools=True
)
We then build a diverse set of specialized agents: CodeWriter for generating Python code, CodeReviewer for reviewing logic and security, DataAnalyst for performing structured data analysis, ProjectPlanner for task breakdown, and QATester for quality checks. Each agent has domain-specific tools, output schemas, and system instructions tailored to their role.
Copy CodeCopiedUse a different Browserdev_supervisor.register_agent(code_agent)
dev_supervisor.register_agent(review_agent)
analysis_supervisor.register_agent(analyst_agent)
qa_supervisor.register_agent(tester_agent)
main_supervisor.register_agent(dev_supervisor)
main_supervisor.register_agent(analysis_supervisor)
main_supervisor.register_agent(qa_supervisor)
main_supervisor.register_agent(planner_agent)
All agents are registered under their respective supervisors, and the assistant supervisors are, in turn, registered with the main supervisor. This setup creates a fully linked agent ecosystem, where instructions could cascade from the top-level agent to any specialist agent in the network.
Copy CodeCopiedUse a different Browserprint(“n Agent Hierarchy:”)
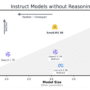
main_supervisor.display_agent_graph()
print(“n Testing Full Multi-Agent Communication”)
print(“-” * 45)
try:
test_response = main_supervisor.chat(“Hello! Please introduce your team and explain how you coordinate complex projects.”)
print(f” Supervisor communication test successful!”)
print(f”Response preview: {test_response[:200]}…”)
except Exception as e:
print(f” Supervisor test failed: {str(e)}”)
print(“Falling back to direct agent testing…”)
We visualize the entire hierarchy using display_agent_graph() to confirm our structure. It offers a clear view of how each agent is connected within the broader task management flow, a helpful diagnostic before deployment.
Copy CodeCopiedUse a different Browserprint(“n Complex Multi-Agent Task Execution”)
print(“-” * 40)
complex_task = “””Create a Python function that implements a binary search algorithm,
have it reviewed for optimization, tested thoroughly, and provide a project plan
for integrating it into a larger search system.”””
print(f”Complex Task: {complex_task}”)
try:
complex_response = main_supervisor.chat(complex_task)
print(f” Complex task completed”)
print(f”Response: {complex_response[:300]}…”)
except Exception as e:
print(f” Complex task failed: {str(e)}”)
We give the full system a real-world task: create a binary search function, review it, test it, and plan its integration into a larger project. The ProjectManager seamlessly coordinates agents across development, QA, and planning, demonstrating the true power of hierarchical, tool-driven agent orchestration.
Copy CodeCopiedUse a different Browserprint(“n Tool Integration & Structured Outputs”)
print(“-” * 43)
print(“Testing Code Agent with tools…”)
try:
code_response = code_agent.chat(“Create a function to calculate fibonacci numbers with memoization”)
print(f” Code Agent with tools: Working”)
print(f”Response type: {type(code_response)}”)
if isinstance(code_response, str) and code_response.strip().startswith(‘{‘):
code_data = json.loads(code_response)
print(f” – Description: {code_data.get(‘description’, ‘N/A’)[:50]}…”)
print(f” – Language: {code_data.get(‘language’, ‘N/A’)}”)
print(f” – Complexity: {code_data.get(‘complexity’, ‘N/A’)}”)
else:
print(f” – Raw response: {code_response[:100]}…”)
except Exception as e:
print(f” Code Agent error: {str(e)}”)
print(“nTesting Analyst Agent with tools…”)
try:
analysis_response = analyst_agent.chat(“Analyze this sales data: [100, 150, 120, 180, 200, 175, 160, 190, 220, 185]. What trends do you see?”)
print(f” Analyst Agent with tools: Working”)
if isinstance(analysis_response, str) and analysis_response.strip().startswith(‘{‘):
analysis_data = json.loads(analysis_response)
print(f” – Summary: {analysis_data.get(‘summary’, ‘N/A’)[:50]}…”)
print(f” – Confidence: {analysis_data.get(‘confidence’, ‘N/A’)}”)
print(f” – Insights count: {len(analysis_data.get(‘insights’, []))}”)
else:
print(f” – Raw response: {analysis_response[:100]}…”)
except Exception as e:
print(f” Analyst Agent error: {str(e)}”)
We directly test the capabilities of two specialized agents using real prompts. We first ask the CodeWriter agent to generate a Fibonacci function with memoization and validate that it returns structured output containing a code description, language, and complexity level. Then, we evaluate the DataAnalyst agent by feeding it sample sales data to extract trends.
Copy CodeCopiedUse a different Browserprint(“n Manual Tool Usage”)
print(“-” * 22)
# Test all tools manually
sample_data = “[95, 87, 92, 88, 91, 89, 94, 90, 86, 93]”
metrics_result = calculate_metrics(sample_data)
print(f”Statistics for {sample_data}:”)
for key, value in metrics_result.items():
print(f” {key}: {value}”)
print(“nCode validation test:”)
test_code = “””
def binary_search(arr, target):
left, right = 0, len(arr) – 1
while left <= right:
mid = (left + right) // 2
if arr[mid] == target:
return mid
elif arr[mid] < target:
left = mid + 1
else:
right = mid – 1
return -1
“””
validation_result = validate_code(test_code)
print(f”Validation result: {validation_result}”)
print(“nDocumentation search test:”)
doc_result = search_documentation(“python function”)
print(f”Search results: {doc_result}”)
We step outside the agent framework to test each tool directly. First, we use the calculate_metrics tool on a dataset of ten numbers, confirming it correctly returned statistics such as mean, median, mode, and standard deviation. Next, we run the validate_code tool on a sample binary search function, which confirms both syntactic correctness and flags no security warnings. Finally, we test the search_documentation tool with the query “python function” and receive relevant documentation snippets, verifying its ability to efficiently simulate contextual lookup.
Copy CodeCopiedUse a different Browserprint(“n Advanced Multi-Agent Workflow”)
print(“-” * 35)
workflow_stages = [
(“Planning”, “Create a project plan for building a web scraper for news articles”),
(“Development”, “Implement the web scraper with error handling and rate limiting”),
(“Review”, “Review the web scraper code for security and efficiency”),
(“Testing”, “Create comprehensive test cases for the web scraper”),
(“Analysis”, “Analyze sample scraped data: [45, 67, 23, 89, 12, 56, 78, 34, 91, 43]”)
]
workflow_results = {}
for stage, task in workflow_stages:
print(f”n{stage} Stage: {task}”)
try:
if stage == “Planning”:
response = planner_agent.chat(task)
elif stage == “Development”:
response = code_agent.chat(task)
elif stage == “Review”:
response = review_agent.chat(task)
elif stage == “Testing”:
response = tester_agent.chat(task)
elif stage == “Analysis”:
response = analyst_agent.chat(task)
workflow_results[stage] = response
print(f” {stage} completed: {response[:80]}…”)
except Exception as e:
print(f” {stage} failed: {str(e)}”)
workflow_results[stage] = f”Error: {str(e)}”
We simulate a five-stage project lifecycle: planning, development, review, testing, and analysis. Each task is passed to the most relevant agent, and responses are collected to evaluate performance. This demonstrates the framework’s capability to manage end-to-end workflows without manual intervention.
Copy CodeCopiedUse a different Browserprint(“n System Monitoring & Performance”)
print(“-” * 37)
debugger = Debugger(name=”OpenAITutorialDebugger”)
debugger.log(“Advanced OpenAI tutorial execution completed successfully”)
print(f”Main Supervisor ID: {main_supervisor.workflow_id}”)
We activate the Debugger tool to track the performance of our session and log system events. We also print the main supervisor’s workflow_id as a traceable identifier, useful when managing multiple workflows in production.
In conclusion, we have successfully built a fully automated, OpenAI-compatible multi-agent system using PrimisAI Nexus. Each agent operates with clarity, precision, and autonomy, whether writing code, validating logic, analyzing data, or breaking down complex workflows. Our hierarchical structure allows for seamless task delegation and modular scalability. PrimisAI Nexus framework establishes a robust foundation for automating real-world tasks, whether in software development, research, planning, or data operations, through intelligent collaboration between specialized agents.
Check out the Codes. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter, Youtube and Spotify and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post Implementing a Tool-Enabled Multi-Agent Workflow with Python, OpenAI API, and PrimisAI Nexus appeared first on MarkTechPost.