In the benefits administration industry, claims processing is a vital operational pillar that makes sure employees and beneficiaries receive timely benefits, such as health, dental, or disability payments, while controlling costs and adhering to regulations like HIPAA and ERISA. Businesses aim to optimize the workflow—covering claim submission, validation, adjudication, payment, and appeals—to enhance employee satisfaction, strengthen provider relationships, and mitigate financial risks. The process includes specific steps like claim submission (through portals or paper), data validation (verifying eligibility and accuracy), adjudication (assessing coverage against plan rules), payment or denial (including check processing for reimbursements), and appeal handling. Efficient claims processing supports competitive benefits offerings, which is crucial for talent retention and employer branding, but requires balancing speed, accuracy, and cost in a highly regulated environment.
Despite its importance, claims processing faces significant challenges in many organizations. Most notably, the reliance on legacy systems and manual processes results in frustratingly slow resolution times, high error rates, and increased administrative costs. Incomplete or inaccurate claim submissions—such as those with missing diagnosis codes or eligibility mismatches—frequently lead to denials and rework, creating frustration for both employees and healthcare providers. Additionally, fraud, waste, and abuse continue to inflate costs, yet detecting these issues without delaying legitimate claims remains challenging. Complex regulatory requirements demand constant system updates, and poor integration between systems—such as Human Resource Information Systems (HRIS) and other downstream systems—severely limits scalability. These issues drive up operational expenses, erode trust in benefits programs, and overburden customer service teams, particularly during appeals processes or peak claims periods.
Generative AI can help address these challenges. With Amazon Bedrock Data Automation, you can automate generation of useful insights from unstructured multimodal content such as documents, images, audio, and video. Amazon Bedrock Data Automation can be used in benefits claims process to automate document processing by extracting and classifying documents from claims packets, policy applications, and supporting documents with industry-leading accuracy, reducing manual errors and accelerating resolution times. Amazon Bedrock Data Automation natural language processing capabilities interpret unstructured data, such as provider notes, supporting compliance with plan rules and regulations. By automating repetitive tasks and providing insights, Amazon Bedrock Data Automation helps reduce administrative burdens, enhance experiences for both employees and providers, and support compliance in a cost-effective manner. Furthermore, its scalable architecture enables seamless integration with existing systems, improving data flow across HRIS, claims systems, and provider networks, and advanced analytics help detect fraud patterns to optimize cost control.
In this post, we examine the typical benefit claims processing workflow and identify where generative AI-powered automation can deliver the greatest impact.
Benefit claims processing
When an employee or beneficiary pays out of pocket for an expense covered under their health benefits, they submit a claim for reimbursement. This process requires several supporting documents, including doctor’s prescriptions and proof of payment, which might include check images, receipts, or electronic payment confirmations.
The claims processing workflow involves several critical steps:
Document intake and processing – The system receives and categorizes submitted documentation, including:
Medical records and prescriptions
Proof of payment documentation
Supporting forms and eligibility verification
Payment verification processing – For check-based reimbursements, the system must complete the following steps:
Extract information from check images, including the account number and routing number contained in the MICR line
Verify payee and payer names against the information provided during the claim submission process
Confirm payment amounts match the claimed expenses
Flag discrepancies for human review
Adjudication and reimbursement – When verification is complete, the system performs several actions:
Determine eligibility based on plan rules and coverage limits
Calculate appropriate reimbursement amounts
Initiate payment processing through direct deposit or check issuance
Provide notification to the claimant regarding the status of their reimbursement
In this post, we walk through a real-world scenario to make the complexity of this multi-step process clearer. The following example demonstrates how Amazon Bedrock Data Automation can streamline the claims processing workflow, from initial submission to final reimbursement.
Solution overview
Let’s consider a scenario where a benefit plan participant seeks treatment and pays out of pocket for the doctor’s fee using a check. They then buy the medications prescribed by the doctor at the pharmacy store. Later, they log in to their benefit provider’s portal and submit a claim along with the image of the check and payment receipt for the medications.
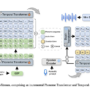
This solution uses Amazon Bedrock Data Automation to automate the two most critical and time-consuming aspects of this workflow: document intake and payment verification processing. The following diagram illustrates the benefits claims processing architecture.
The end-to-end process works through four integrated stages: ingestion, extraction, validation, and integration.
Ingestion
When a beneficiary uploads supporting documents (check image and pharmacy receipt) through the company’s benefit claims portal, these documents are securely saved in an Amazon Simple Storage Service (Amazon S3) bucket, triggering the automated claims processing pipeline.
Extraction
After documents are ingested, the system immediately begins with intelligent data extraction:
The S3 object upload triggers an AWS Lambda function, which invokes the Amazon Bedrock Data Automation project.
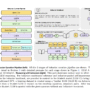
Amazon Bedrock Data Automation uses blueprints for file processing and extraction. Blueprints are artifacts used to configure file processing business logic by specifying a list of field names for data extraction, along with their desired data formats (string, number, or Boolean) and natural language context for data normalization and validation rules. Amazon Bedrock Data Automation provides a catalog of sample blueprints out of the box. You can create a custom blueprint for your unique document types that aren’t predefined in the catalog. This solution uses two blueprints designed for different document types, as shown in the following screenshot:
The catalog blueprint US-Bank-Check for check processing.
The custom blueprint benefit-claims-pharmacy-receipt-blueprint for pharmacy-specific receipts.
US-Bank-Check is a catalog blueprint provided out of the box by Amazon Bedrock Data Automation. The custom blueprint benefit-claims-pharmacy-receipt-blueprint is created using an AWS CloudFormation template to handle pharmacy receipt processing, addressing a specific document type that wasn’t available in the standard blueprint catalog. The benefit administrator wants to look for vendor-specific information such as name, address, and phone details for benefits claims processing. The custom blueprint schema contains natural language explanation of those fields, such as VendorName, VendorAddress, VendorPhone, and additional fields, explaining what the field represents, expected data types, and inference type for each extracted field (explained in Creating Blueprints for Extraction), as shown in the following screenshot.
3. The two blueprints are added to the Amazon Bedrock Data Automation project. An Amazon Bedrock Data Automation project is a grouping of both standard and custom blueprints that you can use to process different types of files (like documents, audio, and images) using specific configuration settings, where you can control what kind of information you want to extract from each file type. When the project is invoked asynchronously, it automatically applies the appropriate blueprint, extracts information such as confidence scores and bounding box details for each field, and saves results in a separate S3 bucket. This intelligent classification alleviates the need for you to write complex document classification logic.
The following screenshot illustrates the document classification by the standard catalog blueprint US-Bank-Check.
The following screenshot shows the document classification by the custom blueprint benefit-claims-pharmacy-receipt-blueprint.
Validation
With the data extracted, the system moves to the validation and decision-making process using the business rules specific to each document type.
The business rules are documented in standard operating procedure documents (AnyCompany Benefit Checks Standard Operating procedure.docx and AnyCompany Benefit Claims Standard Operating procedure.docx) and uploaded to an S3 bucket. Then the system creates a knowledge base for Amazon Bedrock with the S3 bucket as the source, as shown in the following screenshot.
When the extracted Amazon Bedrock Data Automation results are saved to the configured S3 bucket, a Lambda function is triggered automatically. Based on the business rules retrieved from the knowledge base for the specific document type and the extracted Amazon Bedrock Data Automation output, an Amazon Nova Lite large langue model (LLM) makes the automated approve/deny decision for claims.
The following screenshot shows the benefit claim adjudication automated decision for US-Bank-Check.
The following screenshot shows the benefit claim adjudication automated decision for benefit-claims-pharmacy-receipt-blueprint.
Integration
The system seamlessly integrates with existing business processes.
When validation is complete, an event is pushed to Amazon EventBridge, which triggers a Lambda function for downstream integration. In this implementation, we use an Amazon DynamoDB table and Amazon Simple Notification Service (Amazon SNS) email for downstream integration. A DynamoDB table is created as part of the deployment stack, which is used to populate details including document classification, extracted data, and automated decision. An email notification is sent for both check and receipts after the final decision is made by the system. The following screenshot shows an example email for pharmacy receipt approval.
This flexible architecture helps you integrate with your existing applications through internal APIs or events to update claim status or trigger additional workflows when validation fails.
Reducing manual effort through intelligent business rules management
Beyond automating document processing, this solution addresses a common operational challenge: Traditionally, customers must write and maintain code for handling business rules around claims adjudication and processing. Every business rule change requires development effort and code updates, slowing time-to-market and increasing maintenance overhead.
Our approach converts business rules and standard operating procedures (SOPs) into knowledge bases using Amazon Bedrock Knowledge Bases, which you can use for automated decision-making. This approach can dramatically reduce time-to-market when business rules change, because updates can be made through knowledge management rather than code deployment.
In the following sections, we walk you through the steps to deploy the solution to your own AWS account.
Prerequisites
To implement the solution provided in this post, you must have the following:
An AWS account
Access to Amazon Titan Text Embeddings V2 and Amazon Nova Lite foundation models (FMs) enabled in Amazon Bedrock
This solution uses Python 3.13 with Boto3 1.38. or later version, and the AWS Serverless Application Model Command Line Interface (AWS SAM CLI) version 1.138.0. We assume that you have installed these in your local machine already. If not, refer to the following instructions:
Python 3.13 installation
Install the AWS SAM CLI
Set up code in your local machine
To set up the code, clone the GitHub repository. After you have cloned the repository to your local machine, the project folder structure will look like the following code, as mentioned in the README file:
Deploy the solution in your account
The sample code comes with a CloudFormation template that creates necessary resources. To deploy the solution in your account, follow the deployment instructions in the README file.
Clean up
Deploying this solution in your account will incur costs. Follow the cleanup instructions in the README file to avoid charges when you are done.
Conclusion
Benefits administration companies can significantly enhance their operations by automating claims processing using the solution outlined in this post. This strategic approach directly addresses the industry’s core challenges and can deliver several key advantages:
Enhanced processing efficiency through accelerated claims resolution times, reduced manual error rates, and higher straight-through processing rates that minimize the frustrating delays and manual rework plaguing legacy systems
Streamlined document integration and fraud detection capabilities, where adding new supporting documents becomes seamless through new Amazon Bedrock Data Automation blueprints, while AI-powered analytics identify suspicious patterns without delaying legitimate claims, avoiding traditional months-long development cycles and reducing costly fraud, waste, and abuse
Agile business rule management that enables rapid adaptation to changing HIPAA and ERISA requirements and modification of business rules, significantly reducing administrative costs and time-to-market while improving scalability and integration with existing HRIS and claims, ultimately enhancing employee satisfaction, strengthening provider relationships, and supporting competitive benefits offerings that are crucial for talent retention and employer branding
To get started with this solution, refer to the GitHub repo. For more information about Amazon Bedrock Data Automation, refer to Transform unstructured data into meaningful insights using Amazon Bedrock Data Automation and try the Document Processing Using Amazon Bedrock Data Automation workshop.
About the authors
Saurabh Kumar is a Senior Solutions Architect at AWS based out of Raleigh, NC, with expertise in Resilience Engineering, Chaos Engineering, and Generative AI solutions. He advises customers on fault-tolerance strategies and generative AI-driven modernization approaches, helping organizations build robust architectures while leveraging generative AI technologies to drive innovation.
Kiran Lakkireddy is a Principal Solutions Architect at AWS with expertise in Financial Services, Benefits Management and HR Services industries. Kiran provides technology and architecture guidance to customers in their business transformation, with a specialized focus on GenAI security, compliance, and governance. He regularly speaks to customer security leadership on GenAI security, compliance, and governance topics, helping organizations navigate the complex landscape of AI implementation while maintaining robust security standards.
Tamilmanam Sambasivam is a Solutions Architect and AI/ML Specialist at AWS. She helps enterprise customers to solve their business problems by recommending the right AWS solutions. Her strong back ground in Information Technology (24+ years of experience) helps customers to strategize, develop and modernize their business problems in AWS cloud. In the spare time, Tamil like to travel and gardening.