Table of contentsOverviewWhat MCP standardizes?Normative authorization controlsWhere MCP supports security engineering in practice ?Case study: the first malicious MCP serverUsing MCP to structure red-team exercisesImplementation-Focused Security Hardening ChecklistGovernance alignmentCurrent adoption you can test againstSummaryResources used in the article
Overview
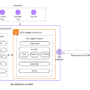
Model Context Protocol (MCP) is an open, JSON-RPC–based standard that formalizes how AI clients (assistants, IDEs, web apps) connect to servers exposing three primitives—tools, resources, and prompts—over defined transports (primarily stdio for local and Streamable HTTP for remote). MCP’s value for security work is that it renders agent/tool interactions explicit and auditable, with normative requirements around authorization that teams can verify in code and in tests. In practice, this enables tight blast-radius control for tool use, repeatable red-team scenarios at clear trust boundaries, and measurable policy enforcement—provided organizations treat MCP servers as privileged connectors subject to supply-chain scrutiny.
What MCP standardizes?
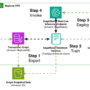
An MCP server publishes: (1) tools (schema-typed actions callable by the model), (2) resources (readable data objects the client can fetch and inject as context), and (3) prompts (reusable, parameterized message templates, typically user-initiated). Distinguishing these surfaces clarifies who is “in control” at each edge: model-driven for tools, application-driven for resources, and user-driven for prompts. Those roles matter in threat modeling, e.g., prompt injection often targets model-controlled paths, while unsafe output handling often occurs at application-controlled joins.
Transports. The spec defines two standard transports—stdio (Standard Input/Output) and Streamable HTTP—and leaves room for pluggable alternatives. Local stdio reduces network exposure; Streamable HTTP fits multi-client or web deployments and supports resumable streams. Treat the transport choice as a security control: constrain network egress for local servers, and apply standard web authN/Z and logging for remote ones.
Client/server lifecycle and discovery. MCP formalizes how clients discover server capabilities (tools/resources/prompts), negotiate sessions, and exchange messages. That uniformity is what lets security teams instrument call flows, capture structured logs, and assert pre/postconditions without bespoke adapters per integration.
Normative authorization controls
The Authorization approach is unusually prescriptive for an integration protocol and should be enforced as follows:
No token passthrough. “The MCP server MUST NOT pass through the token it received from the MCP client.” Servers are OAuth 2.1 resource servers; clients obtain tokens from an authorization server using RFC 8707 resource indicators so tokens are audience-bound to the intended server. This prevents confused-deputy paths and preserves upstream audit/limit controls.
Audience binding and validation. Servers MUST validate that the access token’s audience matches themselves (resource binding) before serving a request. Operationally, this stops a client-minted token for “Service A” from being replayed to “Service B.” Red teams should include explicit probes for this failure mode.
This is the core of MCP’s security structure: model-side capabilities are powerful, but the protocol insists that servers be first-class principals with their own credentials, scopes, and logs—rather than opaque pass-throughs for a user’s global token.
Where MCP supports security engineering in practice?
Clear trust boundaries. The clientserver edge is an explicit, inspectable boundary. You can attach consent UIs, scope prompts, and structured logging at that edge. Many client implementations present permission prompts that enumerate a server’s tools/resources before enabling them—useful for least-privilege and audit—even though UX is not specified by the standard.
Containment and least privilege. Because a server is a separate principal, you can enforce minimal upstream scopes. For example, a secrets-broker server can mint short-lived credentials and expose only constrained tools (e.g., “fetch secret by policy label”), rather than handing broad vault tokens to the model. Public MCP servers from security vendors illustrate this model.
Deterministic attack surfaces for red teaming. With typed tool schemas and replayable transports, red teams can build fixtures that simulate adversarial inputs at tool boundaries and verify post-conditions across models/clients. This yields reproducible tests for classes of failures like prompt injection, insecure output handling, and supply-chain abuse. Pair those tests with recognized taxonomies.
Case study: the first malicious MCP server
In late September 2025, researchers disclosed a trojanized postmark-mcp npm package that impersonated a Postmark email MCP server. Beginning with v1.0.16, the malicious build silently BCC-exfiltrated every email sent through it to an attacker-controlled address/domain. The package was subsequently removed, but guidance urged uninstalling the affected version and rotating credentials. This appears to be the first publicly documented malicious MCP server in the wild, and it underscores that MCP servers often run with high trust and should be vetted and version-pinned like any privileged connector.
Operational takeaways:
Maintain an allowlist of approved servers and pin versions/hashes.
Require code provenance (signed releases, SBOMs) for production servers.
Monitor for anomalous egress patterns consistent with BCC exfiltration.
Practice credential rotation and “bulk disconnect” drills for MCP integrations.
These are not theoretical controls; the incident impact flowed directly from over-trusted server code in a routine developer workflow.
Using MCP to structure red-team exercises
1) Prompt-injection and unsafe-output drills at the tool boundary. Build adversarial corpora that enter via resources (application-controlled context) and attempt to coerce calls to dangerous tools. Assert that the client sanitizes injected outputs and that server post-conditions (e.g., allowed hostnames, file paths) hold. Map findings to LLM01 (Prompt Injection) and LLM02 (Insecure Output Handling).
2) Confused-deputy probes for token misuse. Craft tasks that try to induce a server to use a client-issued token or to call an unintended upstream audience. A compliant server must reject foreign-audience tokens per the authorization spec; clients must request audience-correct tokens with RFC 8707 resource. Treat any success here as a P1.
3) Session/stream resilience. For remote transports, exercise reconnection/resumption flows and multi-client concurrency for session fixation/hijack risks. Validate non-deterministic session IDs and rapid expiry/rotation in load-balanced deployments. (Streamable HTTP supports resumable connections; use it to stress your session model.)
4) Supply-chain kill-chain drills. In a lab, insert a trojaned server (with benign markers) and verify whether your allowlists, signature checks, and egress detection catch it—mirroring the Postmark incident TTPs. Measure time to detection and credential rotation MTTR.
5) Baseline with trusted public servers. Use vetted servers to construct deterministic tasks. Two practical examples: Google’s Data Commons MCP exposes public datasets under a stable schema (good for fact-based tasks/replays), and Delinea’s MCP demonstrates least-privilege secrets brokering for agent workflows. These are ideal substrates for repeatable jailbreak and policy-enforcement tests.
Implementation-Focused Security Hardening Checklist
Client side
Display the exact command or configuration used to start local servers; gate startup behind explicit user consent and enumerate the tools/resources being enabled. Persist approvals with scope granularity. (This is common practice in clients such as Claude Desktop.)
Maintain an allowlist of servers with pinned versions and checksums; deny unknown servers by default.
Log every tool call (name, arguments metadata, principal, decision) and resource fetch with identifiers so you can reconstruct attack paths post-hoc.
Server side
Implement OAuth 2.1 resource-server behavior; validate tokens and audiences; never forward client-issued tokens upstream.
Minimize scopes; prefer short-lived credentials and capabilities that encode policy (e.g., “fetch secret by label” instead of free-form read).
For local deployments, prefer stdio inside a container/sandbox and restrict filesystem/network capabilities; for remote, use Streamable HTTP with TLS, rate limits, and structured audit logs.
Detection & response
Alert on anomalous server egress (unexpected destinations, email BCC patterns) and sudden capability changes between versions.
Prepare break-glass automation to revoke client approvals and rotate upstream secrets quickly when a server is flagged (your “disconnect & rotate” runbook). The Postmark incident showed why time matters.
Governance alignment
MCP’s separation of concerns—clients as orchestrators, servers as scoped principals with typed capabilities—aligns directly with NIST’s AI RMF guidance for access control, logging, and red-team evaluation of generative systems, and with OWASP’s LLM Top-10 emphasis on mitigating prompt injection, unsafe output handling, and supply-chain vulnerabilities. Use those frameworks to justify controls in security reviews and to anchor acceptance criteria for MCP integrations.
Current adoption you can test against
Anthropic/Claude: product docs and ecosystem material position MCP as the way Claude connects to external tools and data; many community tutorials closely follow the spec’s three-primitive model. This provides ready-made client surfaces for permissioning and logging.
Google’s Data Commons MCP: released Sept 24, 2025, it standardizes access to public datasets; its announcement and follow-up posts include production usage notes (e.g., the ONE Data Agent). Useful as a stable “truth source” in red-team tasks.
Delinea MCP: open-source server integrating with Secret Server and Delinea Platform, emphasizing policy-mediated secret access and OAuth alignment with the MCP authorization spec. A practical example of least-privilege tool exposure.
Summary
MCP is not a silver-bullet “security product.” It is a protocol that gives security and red-team practitioners stable, enforceable levers: audience-bound tokens, explicit clientserver boundaries, typed tool schemas, and transports you can instrument. Use those levers to (1) constrain what agents can do, (2) observe what they actually did, and (3) replay adversarial scenarios reliably. Treat MCP servers as privileged connectors—vet, pin, and monitor them—because adversaries already do. With those practices in place, MCP becomes a practical foundation for secure agentic systems and a reliable substrate for red-team evaluation.
Resources used in the article
MCP specification & concepts
https://modelcontextprotocol.io/specification/2025-06-18/basic/authorization
https://modelcontextprotocol.io/specification/2025-03-26/basic/transports
https://modelcontextprotocol.io/docs/concepts/architecture
https://modelcontextprotocol.io/docs/concepts/prompts
MCP ecosystem (official)
https://www.anthropic.com/news/model-context-protocol
https://docs.claude.com/en/docs/mcp
https://docs.claude.com/en/docs/claude-code/mcp
https://modelcontextprotocol.io/quickstart/server
https://modelcontextprotocol.io/docs/develop/connect-local-servers
https://modelcontextprotocol.io/docs/develop/connect-remote-servers
Security frameworks
https://owasp.org/www-project-top-10-for-large-language-model-applications/
https://genai.owasp.org/llm-top-10/
https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.600-1.pdf
https://www.nist.gov/itl/ai-risk-management-framework
Incident: malicious postmark-mcp server
https://www.koi.security/blog/postmark-mcp-npm-malicious-backdoor-email-theft
https://thehackernews.com/2025/09/first-malicious-mcp-server-found.html
https://www.itpro.com/security/a-malicious-mcp-server-is-silently-stealing-user-emails
https://threatprotect.qualys.com/2025/09/30/malicious-mcp-server-on-npm-postmark-mcp-exploited-in-attack/
Example MCP servers referenced
https://developers.googleblog.com/en/datacommonsmcp/
https://blog.google/technology/developers/ai-agents-datacommons/
https://github.com/DelineaXPM/delinea-mcp
https://delinea.com/news/delinea-mcp-server-to-provide-secure-credential-access-for-ai-agents?hs_amp=true
https://delinea.com/blog/unlocking-ai-agents-mcp
The post The Role of Model Context Protocol (MCP) in Generative AI Security and Red Teaming appeared first on MarkTechPost.