This post is co-written with Ranjit Rajan, Abdullahi Olaoye, and Abhishek Sawarkar from NVIDIA.
AI’s next frontier isn’t merely smarter chat-based assistants, it’s autonomous agents that reason, plan, and execute across entire systems. But to accomplish this, enterprise developers need to move from prototypes to production-ready AI agents that scale securely. This challenge grows as enterprise problems become more complex, requiring architectures where multiple specialized agents collaborate to accomplish sophisticated tasks.
Building AI agents in development differs fundamentally from deploying them at scale. Developers face a chasm between prototype and production, struggling with performance optimization, resource scaling, security implementation, and operational monitoring. Typical approaches leave teams juggling multiple disconnected tools and frameworks, making it difficult to maintain consistency from development through deployment with optimal performance. That’s where the powerful combination of Strands Agents, Amazon Bedrock AgentCore, and NVIDIA NeMo Agent Toolkit shine. You can use these tools together to design sophisticated multi-agent systems, orchestrate them, and scale them securely in production with built-in observability, agent evaluation, profiling, and performance optimization. This post demonstrates how to use this integrated solution to build, evaluate, optimize, and deploy AI agents on Amazon Web Services (AWS) from initial development through production deployment.
Foundation for enterprise-ready agents
The open source Strands Agents framework simplifies AI agent development through its model-driven approach. Developers create agents using three components:
Foundation models (FMs) such as Amazon Nova, Claude by Anthropic, and Meta’s Llama
Tools (over 20 built-in, plus custom tools using Python decorators)
Prompts that guide agent behavior.
The framework includes built-in integrations with AWS services such as Amazon Bedrock and Amazon Simple Storage Service (Amazon S3), local testing support, continuous integration and continuous development (CI/CD) workflows, multiple deployment options, and OpenTelemetry observability.
Amazon Bedrock AgentCore is an agentic platform for building, deploying, and operating effective agents securely at scale. It has composable, fully managed services:
Runtime for secure, serverless agent deployment
Memory for short-term and long-term context retention
Gateway for secure tool access by transforming APIs and AWS Lambda functions into agent-compatible tools and connecting to existing Model Context Protocol (MCP) servers
Identity for secure agent identity and access management
Code Interpreter for secure code execution in sandbox environments
Browser for fast, secure web interactions
Observability for comprehensive operational insights to trace, debug, and monitor agent performance
Evaluations for continuously inspecting agent quality based on real-world behavior
Policy to keep agents within defined boundaries
These services, designed to work independently or together, abstract the complexity of building, deploying, and operating sophisticated agents while working with open source frameworks or models delivering enterprise-grade security and reliability.
Agent evaluation, profiling, and optimization with NeMo Agent Toolkit
NVIDIA NeMo Agent Toolkit is an open source framework designed to help developers build, profile, and optimize AI agents regardless of their underlying framework. Its framework-agnostic approach means it works seamlessly with Strands Agents, LangChain, LlamaIndex, CrewAI, and custom enterprise frameworks. In addition, different frameworks can interoperate when they’re connected in the NeMo Agent Toolkit.
The toolkit’s profiler provides complete agent workflow analysis that tracks token usage, timing, workflow-specific latency, throughput, and run times for individual agents and tools, enabling targeted performance improvements. Built on the toolkit’s evaluation harness, it includes Retrieval Augmented Generation (RAG)-specific evaluators (such as answer accuracy, context relevance, response groundedness, and agent trajectory) and supports custom evaluators for specialized use cases, enabling targeted performance optimization. The automated hyperparameter optimizer profiles and systematically discovers optimal settings for parameters such as temperature, top_p, and max_tokens while maximizing accuracy, groundedness, context relevance, and minimizing token usage, latency, and optimizing for other custom metrics as well. This automated approach profiles your complete agent workflows, identified bottlenecks, and uncovers optimal parameter combinations that manual tuning might miss. The toolkit’s intelligent GPU sizing calculator alleviates guesswork by simulating agent latency and concurrency scenarios and predicting precise GPU infrastructure requirements for production deployment.
The toolkit’s observability integration connects with popular monitoring services including Arize Phoenix, Weights & Biases Weave, Langfuse, and OpenTelemetry supported systems, like Amazon Bedrock AgentCore Observability, creating a continuous feedback loop for ongoing optimization and maintenance.
Real-world implementation
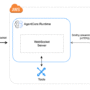
This example demonstrates a knowledge-based agent that retrieves and synthesizes information from web URLs to answer user queries. Built using Strands Agents with integrated NeMo Agent Toolkit, the solution is containerized for quick deployment in Amazon Bedrock AgentCore Runtime and takes advantage of Bedrock AgentCore services, such as AgentCore Observability. Additionally, developers have the flexibility to integrate with fully managed models in Amazon Bedrock, models hosted in Amazon SageMaker AI, containerized models in Amazon Elastic Kubernetes Service (Amazon EKS) or other model API endpoints. The overall architecture is designed for a streamlined workflow, moving from agent definition and optimization to containerization and scalable deployment.
The following architecture diagram illustrates an agent built with Strands Agents integrating NeMo Agent Toolkit deployed in Amazon Bedrock AgentCore.
Agent development and evaluation
Start by defining your agent and workflows in Strands Agents, then wrap it with NeMo Agent Toolkit to configure components such as a large language model (LLM) for inference and tools. Refer to the Strands Agents and NeMo Agent Toolkit integration example in GitHub for a detailed setup guide. After configuring your environment, validate your agent logic by running a single workflow from the command line with an example prompt:
nat run –config_file examples/frameworks/strands_demo/configs/config.yml –input “How do I use the Strands Agents API?”
The following is the truncated terminal output:
Workflow Result:
[‘The Strands Agents API is a flexible system for managing prompts, including both
system prompts and user messages. System prompts provide high-level instructions to
the model about its role, capabilities, and constraints, while user messages are your
queries or requests to the agent. The API supports multiple techniques for prompting,
including text prompts, multi-modal prompts, and direct tool calls. For guidance on
how to write safe and responsible prompts, please refer to the Safety & Security –
Prompt Engineering documentation.’]
Instead of executing a single workflow and exiting, to simulate a real-world scenario, you can spin up a long-running API server capable of handling concurrent requests with the serve command:
nat serve –config_file examples/frameworks/strands_demo/configs/config.yml
The following is the truncated terminal output:
INFO: Application startup complete.
INFO: Uvicorn running on http://localhost:8000 (Press CTRL+C to quit)
The agent is now running locally on port 8000. To interact with the agent, open a new terminal and execute the following cURL command. This will generate output similar to the previous nat run step but the agent runs continuously as a persistent service rather than executing one time and exiting. This simulates the production environment where Amazon Bedrock AgentCore will run the agent as a containerized service:
curl -X ‘POST’ ‘http://localhost:8080/invocations’ -H ‘accept: application/json’ -H ‘Content-Type: application/json’ -d ‘{“inputs” : “How do I use the Strands Agents API?”}’curl -X ‘POST’ ‘http://localhost:8000/generate’ -H ‘accept: application/json’ -H ‘Content-Type: application/json’ -d ‘{“inputs” : “How do I use the Strands Agents API?”}’
The following is the truncated terminal output:
{“value”:”The Strands Agents API provides a flexible system for managing prompts,
including both system prompts and user messages. System prompts provide high-level
instructions to the model about its role, capabilities, and constraints, while user
messages are your queries or requests to the agent. The SDK supports multiple techniques
for prompting, including text prompts, multi-modal prompts, and direct tool calls.
For guidance on how to write safe and responsible prompts, please refer to the
Safety & Security – Prompt Engineering documentation.”}
Agent profiling and workflow performance monitoring
With the agent running, the next step is to establish a performance baseline. To illustrate the depth of insights available, in this example, we use a self-managed Llama 3.3 70B Instruct NIM on an Amazon Elastic Compute Cloud (Amazon EC2) P4de.24xlarge instance powered by NVIDIA A100 Tensor Core GPUs (8xA100 80 GB GPU) running on Amazon EKS. We use the nat eval command to evaluate the agent and generate the analysis:
nat eval –config_file examples/frameworks/strands_demo/configs/eval_config.yml
The following is the truncated terminal output:
Evaluating Trajectory: 100%|████████████████████████████████████████████████████████████████████| 10/10 [00:10<00:00, 1.00s/it]
2025-11-24 16:59:18 – INFO – nat.profiler.profile_runner:127 – Wrote combined data to: .tmp/nat/examples/frameworks/strands_demo/eval/all_requests_profiler_traces.json
2025-11-24 16:59:18 – INFO – nat.profiler.profile_runner:146 – Wrote merged standardized DataFrame to .tmp/nat/examples/frameworks/strands_demo/eval/standardized_data_all.csv
2025-11-24 16:59:18 – INFO – nat.profiler.profile_runner:200 – Wrote inference optimization results to: .tmp/nat/examples/frameworks/strands_demo/eval/inference_optimization.json
2025-11-24 16:59:28 – INFO – nat.profiler.profile_runner:224 – Nested stack analysis complete
2025-11-24 16:59:28 – INFO – nat.profiler.profile_runner:235 – Concurrency spike analysis complete
2025-11-24 16:59:28 – INFO – nat.profiler.profile_runner:264 – Wrote workflow profiling report to: .tmp/nat/examples/frameworks/strands_demo/eval/workflow_profiling_report.txt
2025-11-24 16:59:28 – INFO – nat.profiler.profile_runner:271 – Wrote workflow profiling metrics to: .tmp/nat/examples/frameworks/strands_demo/eval/workflow_profiling_metrics.json
2025-11-24 16:59:28 – INFO – nat.eval.evaluate:345 – Workflow output written to .tmp/nat/examples/frameworks/strands_demo/eval/workflow_output.json
2025-11-24 16:59:28 – INFO – nat.eval.evaluate:356 – Evaluation results written to .tmp/nat/examples/frameworks/strands_demo/eval/rag_relevance_output.json
2025-11-24 16:59:28 – INFO – nat.eval.evaluate:356 – Evaluation results written to .tmp/nat/examples/frameworks/strands_demo/eval/rag_groundedness_output.json
2025-11-24 16:59:28 – INFO – nat.eval.evaluate:356 – Evaluation results written to .tmp/nat/examples/frameworks/strands_demo/eval/rag_accuracy_output.json
2025-11-24 16:59:28 – INFO – nat.eval.evaluate:356 – Evaluation results written to .tmp/nat/examples/frameworks/strands_demo/eval/trajectory_accuracy_output.json
2025-11-24 16:59:28 – INFO – nat.eval.utils.output_uploader:62 – No S3 config provided; skipping upload.
The command generates detailed artifacts that include JSON files per evaluation metric (such as accuracy, groundedness, relevance, and Trajectory accuracy) showing scores from 0–1, reasoning traces, retrieved contexts, and aggregated averages. Additional information in the artifacts generated include workflow outputs, standardized tables, profile traces, and compact summaries for latency and token efficiency. This multi-metric sweep provides a holistic view of agent quality and behavior. The evaluation highlights that while the agent achieved consistent groundedness scores—meaning answers were reliably supported by sources—there is still an opportunity to improve retrieval relevance. The profile trace output contains workflow-specific latency, throughput, and runtime at 90%, 95%, and 99% confidence intervals. The command generates a Gantt chart of the agent flow and nested stack analysis to pinpoint exactly where bottlenecks exist, as seen in the following figure. It also reports concurrency spikes and token efficiency so you can understand precisely how scaling impacts prompt and completion usage.
During the profiling, nat spawns eight concurrent agent workflows (shown in orange bars in the chart), which is the default concurrency configuration during evaluation. The p90 latency for the workflow shown is approximately 58.9 seconds. Crucially, the data confirmed that response generation was the primary bottleneck, with the longest LLM segments taking roughly 61.4 seconds. Meanwhile, non-LLM overhead remained minimal. HTTP requests averaged only 0.7–1.2 seconds, and knowledge base access was negligible. Using this level of granularity, you can now identify and optimize specific bottlenecks in the agent workflows.
Agent performance optimization
After profiling, refine the agent’s parameters to balance quality, performance, and cost. Manual tuning of LLM settings like temperature and top_p is often a game of guesswork. The NeMo Agent Toolkit turns this into a data-driven science. You can use the built-in optimizer to perform a systematic sweep across your parameter search space:
nat optimize –config_file examples/frameworks/strands_demo/configs/optimizer_config.yml
The following is the truncated terminal output:
Evaluating Trajectory: 100%|██████████████████████████████████████████████████████████████| 10/10 [00:10<00:00, 1.00it/s]
2025-10-31 16:50:41 – INFO – nat.profiler.profile_runner:127 – Wrote combined data to: ./tmp/nat/strands_demo/eval/all_requests_profiler_traces.json
2025-10-31 16:50:41 – INFO – nat.profiler.profile_runner:146 – Wrote merged standardized DataFrame to: ./tmp/nat/strands_demo/eval/standardized_data_all.csv
2025-10-31 16:50:41 – INFO – nat.profiler.profile_runner:208 – Wrote inference optimization results to: ./tmp/nat/strands_demo/eval/inference_optimization.json
2025-10-31 16:50:41 – INFO – nat.eval.evaluate:337 – Workflow output written to ./tmp/nat/strands_demo/eval/workflow_output.json
2025-10-31 16:50:41 – INFO – nat.eval.evaluate:348 – Evaluation results written to ./tmp/nat/strands_demo/eval/token_efficiency_output.json
2025-10-31 16:50:41 – INFO – nat.eval.evaluate:348 – Evaluation results written to ./tmp/nat/strands_demo/eval/llm_latency_output.json
2025-10-31 16:50:41 – INFO – nat.eval.evaluate:348 – Evaluation results written to ./tmp/nat/strands_demo/eval/rag_relevance_output.json
2025-10-31 16:50:41 – INFO – nat.eval.evaluate:348 – Evaluation results written to ./tmp/nat/strands_demo/eval/rag_groundedness_output.json
2025-10-31 16:50:41 – INFO – nat.eval.evaluate:348 – Evaluation results written to ./tmp/nat/strands_demo/eval/rag_accuracy_output.json
2025-10-31 16:50:41 – INFO – nat.eval.evaluate:348 – Evaluation results written to ./tmp/nat/strands_demo/eval/trajectory_accuracy_output.json
2025-10-31 16:50:41 – INFO – nat.eval.utils.output_uploader:61 – No S3 config provided; skipping upload.
Evaluating Regex-Ex_Accuracy: 100%|████████████████████████████████████████████████████████| 10/10 [00:21<00:00, 2.15s/it]
2025-10-31 16:50:44 – INFO – nat.profiler.profile_runner:127 – Wrote combined data to: ./tmp/nat/strands_demo/eval/all_requests_profiler_traces.json
2025-10-31 16:50:44 – INFO – nat.profiler.profile_runner:146 – Wrote merged standardized DataFrame to: ./tmp/nat/strands_demo/eval/standardized_data_all.csv
2025-10-31 16:50:45 – INFO – nat.profiler.profile_runner:208 – Wrote inference optimization results to: ./tmp/nat/strands_demo/eval/inference_optimization.json
2025-10-31 16:50:46 – INFO – nat.eval.evaluate:337 – Workflow output written to ./tmp/nat/strands_demo/eval/workflow_output.json
2025-10-31 16:50:47 – INFO – nat.eval.evaluate:348 – Evaluation results written to ./tmp/nat/strands_demo/eval/token_efficiency_output.json
2025-10-31 16:50:48 – INFO – nat.eval.evaluate:348 – Evaluation results written to ./tmp/nat/strands_demo/eval/llm_latency_output.json
2025-10-31 16:50:49 – INFO – nat.eval.evaluate:348 – Evaluation results written to ./tmp/nat/strands_demo/eval/rag_relevance_output.json
2025-10-31 16:50:50 – INFO – nat.eval.evaluate:348 – Evaluation results written to ./tmp/nat/strands_demo/eval/rag_groundedness_output.json
2025-10-31 16:50:51 – INFO – nat.eval.evaluate:348 – Evaluation results written to ./tmp/nat/strands_demo/eval/trajectory_accuracy_output.json
2025-10-31 16:50:52 – INFO – nat.eval.evaluate:348 – Evaluation results written to ./tmp/nat/strands_demo/eval/rag_accuracy_output.json
2025-10-31 16:50:53 – INFO – nat.eval.utils.output_uploader:61 – No S3 config provided; skipping upload.
[I 2025-10-31 16:50:53,361] Trial 19 finished with values: [0.6616666666666667, 1.0, 0.38000000000000007, 0.26800000000000006, 2.1433333333333333, 2578.222222222222] and parameters: {‘llm_sim_llm.top_p’: 0.8999999999999999, ‘llm_sim_llm.temperature’: 0.38000000000000006, ‘llm_sim_llm.max_tokens’: 5632}.
2025-10-31 16:50:53 – INFO – nat.profiler.parameter_optimization.parameter_optimizer:120 – Numeric optimization finished
2025-10-31 16:50:53 – INFO – nat.profiler.parameter_optimization.parameter_optimizer:162 – Generating Pareto front visualizations…
2025-10-31 16:50:53 – INFO – nat.profiler.parameter_optimization.pareto_visualizer:320 – Creating Pareto front visualizations…
2025-10-31 16:50:53 – INFO – nat.profiler.parameter_optimization.pareto_visualizer:330 – Total trials: 20
2025-10-31 16:50:53 – INFO – nat.profiler.parameter_optimization.pareto_visualizer:331 – Pareto optimal trials: 14
2025-10-31 16:50:54 – INFO – nat.profiler.parameter_optimization.pareto_visualizer:345 – Parallel coordinates plot saved to: ./tmp/nat/strands_demo/optimizer/plots/pareto_parallel_coordinates.png
2025-10-31 16:50:56 – INFO – nat.profiler.parameter_optimization.pareto_visualizer:374 – Pairwise matrix plot saved to: ./tmp/nat/strands_demo/optimizer/plots/pareto_pairwise_matrix.png
2025-10-31 16:50:56 – INFO – nat.profiler.parameter_optimization.pareto_visualizer:387 – Visualization complete!
2025-10-31 16:50:56 – INFO – nat.profiler.parameter_optimization.pareto_visualizer:389 – Plots saved to: ./tmp/nat/strands_demo/optimizer/plots
2025-10-31 16:50:56 – INFO – nat.profiler.parameter_optimization.parameter_optimizer:171 – Pareto visualizations saved to: ./tmp/nat/strands_demo/optimizer/plots
2025-10-31 16:50:56 – INFO – nat.profiler.parameter_optimization.optimizer_runtime:88 – All optimization phases complete.
This command launches an automated sweep across key LLM parameters, such as temperature, top_p, and max_tokens, as defined in the config (in this case optimizer_config.yml) search space. The optimizer runs 20 trials with three repetitions each, using weighted evaluation metrics to automatically discover optimal model settings. It might take up to 15–20 minutes for the optimizer to run 20 trials.
The toolkit evaluates each parameter set against a weighted multi-objective score, aiming to maximize quality (for example, accuracy, groundedness, or tool use) while minimizing token cost and latency. Upon completion, it generates detailed performance artifacts and summary tables so you can quickly identify and select the optimal configuration for production. The following is the hyperparameter optimizer configuration:
llms:
nim_llm:
_type: nim
model_name: meta/llama-3.3-70b-instruct
temperature: 0.5
top_p: 0.9
max_tokens: 4096
# Enable optimization for these parameters
optimizable_params:
– temperature
– top_p
– max_tokens
# Define search spaces
search_space:
temperature:
low: 0.1
high: 0.7
step: 0.2 # Tests: 0.1, 0.3, 0.5, 0.7
top_p:
low: 0.7
high: 1.0
step: 0.1 # Tests: 0.7, 0.8, 0.9, 1.0
max_tokens:
low: 4096
high: 8192
step: 512 # Tests: 4096, 4608, 5120, 5632, 6144, 6656, 7168, 7680, 8192
In this example, NeMo Agent Toolkit Optimize systematically evaluated parameter configurations and identified temperature ≈ 0.7, top_p ≈ 1.0, and max_tokens ≈ 6k (6144) as optimal configuration yielding the highest accuracy across 20 trials. This configuration delivered a 35% accuracy improvement over baseline while simultaneously achieving 20% token efficiency gains compared to the 8192 max_tokens setting—maximizing both performance and cost efficiency for these production deployments.
The optimizer plots pairwise pareto curves, as shown in the following pairwise matrix comparison charts, to analyze trade-offs between different parameters. The parallel coordinates plot, that follows the matrix comparison chart, shows optimal trials (red lines) achieving high quality scores (0.8–1.0) across accuracy, groundedness, and relevance while trading off some efficiency as token usage and latency drop to 0.6–0.8 on the normalized scale. The pairwise matrix confirms strong correlations between quality metrics and reveals actual token consumption clustered tightly around 2,500–3,100 tokens across all trials. These results indicate that further gains in accuracy and token efficiency might be possible through prompt engineering. This is something that development teams can achieve using NeMo Agent Toolkit’s prompt optimization capabilities, helping reduce costs while maximizing performance.
The following image shows the pairwise matrix comparison:
The following image shows the parallel coordinates plot:
Right-sizing production GPU infrastructure
After your agent is optimized and you’ve finalized the runtime or inference configuration, you can shift your focus to assessing your model deployment infrastructure. If you’re self-managing your model deployment on a fleet of EC2 GPU-powered instances, then one of the most difficult aspects of moving agents to production is predicting exactly what compute resources are necessary to support a target use case and concurrent users without overrunning the budget or causing timeouts. The NeMo Agent Toolkit GPU sizing calculator addresses this challenge by using your agent’s actual performance profile to determine the optimal cluster size for specific service level objectives (SLOs), enabling right-sizing that alleviates the trade-off between performance and cost. To generate a sizing profile, you run the sizing calculator across a range of concurrency levels (for example, 1–32 simultaneous users):
nat sizing calc –config_file examples/frameworks/strands_demo/configs/sizing_config.yml –calc_output_dir /tmp/strands_demo/sizing_calc_run1/ –concurrencies 1,2,4,8,12,20,24,28,32 –num_passes 2
Executing this on our reference EC2 P4de.24xlarge instance powered by NVIDIA A100 Tensor Core GPUs running on Amazon EKS for a Llama 3.3 70B Instruct NIM produced the following capacity analysis:
Per concurrency results:
Alerts!: W = Workflow interrupted, L = LLM latency outlier, R = Workflow runtime outlier
| Alerts | Concurrency | p95 LLM Latency | p95 WF Runtime | Total Runtime |
|——–|————–|—————–|—————-|—————|
| | 1 | 11.8317 | 21.3647 | 33.2416 |
| | 2 | 19.3583 | 26.2694 | 36.931 |
| | 4 | 25.728 | 32.4711 | 61.13 |
| | 8 | 38.314 | 57.1838 | 89.8716 |
| | 12 | 55.1766 | 72.0581 | 130.691 |
| | 20 | 103.68 | 131.003 | 202.791 |
| !R | 24 | 135.785 | 189.656 | 221.721 |
| !R | 28 | 125.729 | 146.322 | 245.654 |
| | 32 | 169.057 | 233.785 | 293.562 |
As shown in the following chart, calculated concurrency scales almost linearly with both latency and end‑to‑end runtime, with P95 LLM latency and workflow runtime demonstrating near-perfect trend fits (R² ≈ 0.977/0.983). Each additional concurrent request introduces a predictable latency penalty, suggesting the system operates within a linear capacity zone where throughput can be optimized by adjusting latency tolerance.
With the sizing metrics captured, you can estimate the GPU cluster size for a specific concurrency and latency. For example, to support 25 concurrent users with a target workflow runtime of 50 seconds, you can run the calculator:
nat sizing calc –offline_mode –calc_output_dir /tmp/strands_demo/sizing_calc_run1/ –test_gpu_count 8 –target_workflow_runtime 50 –target_users 25
This workflow analyzes current performance metrics and generates a resource recommendation. In our example scenario, the tool calculates that to meet strict latency requirements for 25 simultaneous users, approximately 30 GPUs are required based on the following formula:
gpu_estimate = (target_users / calculated_concurrency) * test_gpu_count
calculated_concurrency = (target_time_metric – intercept) / slope
The following is the output from the sizing estimation:
Targets: LLM Latency ≤ 0.0s, Workflow Runtime ≤ 50.0s, Users = 25
Test parameters: GPUs = 8
Per concurrency results:
Alerts!: W = Workflow interrupted, L = LLM latency outlier, R = Workflow runtime outlier
| Alerts | Concurrency | p95 LLM Latency | p95 WF Runtime | Total Runtime | GPUs (WF Runtime, Rough) |
|——–|————-|—————–|—————-|—————|————————–|
| | 1 | 11.8317 | 21.3647 | 33.2416 | 85.4587 |
| | 2 | 19.3583 | 26.2694 | 36.931 | 52.5388 |
| | 4 | 25.728 | 32.4711 | 61.13 | 32.4711 |
| | 8 | 38.314 | 57.1838 | 89.8716 | |
| | 12 | 55.1766 | 72.0581 | 130.691 | |
| | 20 | 103.68 | 131.003 | 202.791 | |
| !R | 24 | 135.785 | 189.656 | 221.721 | |
| !R | 28 | 125.729 | 146.322 | 245.654 | |
| | 32 | 169.057 | 233.785 | 293.562 | |
=== GPU ESTIMATES ===
Estimated GPU count (Workflow Runtime): 30.5
Production agent deployment to Amazon Bedrock AgentCore
After evaluating, profiling, and optimizing your agent, deploy it to production. Although running the agent locally is sufficient for testing, enterprise deployment requires an agent runtime that helps provide security, scalability, and robust memory management without the overhead of managing infrastructure. This is where Amazon Bedrock AgentCore Runtime shines—providing enterprise-grade serverless agent runtime without the infrastructure overhead. Refer to the step-by-step deployment guide in the NeMo Agent Toolkit Repository. By packaging your optimized agent in a container and deploying it to the serverless Bedrock AgentCore Runtime, you elevate your prototype agent to a resilient application for long-running tasks and concurrent user requests. After you deploy the agent, visibility becomes critical. This integration creates a unified observability experience, transforming opaque black-box execution into deep visibility. You gain exact traces, spans, and latency breakdowns for every interaction in production, integrated into Bedrock AgentCore Observability using OpenTelemetry.
The following screenshot shows the Amazon CloudWatch dashboard displaying Amazon Bedrock AgentCore traces and spans, visualizing the execution path and latency of the deployed Strands agent.
Amazon Bedrock AgentCore services extend well beyond agent runtime management and observability. Your deployed agents can seamlessly use additional Bedrock AgentCore services, including Amazon Bedrock AgentCore Identity for authentication and authorization, Amazon Bedrock AgentCore Gateway for tools access, Amazon Bedrock AgentCore Memory for context-awareness, Amazon Bedrock AgentCore Code Interpreter for secure code execution, and Amazon Bedrock AgentCore Browser for web interactions, to create enterprise-ready agents.
Conclusion
Production AI agents need performance visibility, optimization, and reliable infrastructure. For the example use case, this integration delivered on all three fronts: achieving 20% token efficiency gains, 35% accuracy improvements for the example use case, and performance-tuned GPU infrastructure calibrated for target concurrency. By combining Strands Agents for foundational agent development and orchestration, the NVIDIA NeMo Agent Toolkit for deep agent profiling, optimization, and right-sizing production GPU infrastructure, and Amazon Bedrock AgentCore for secure, scalable agent infrastructure, developers can have an end-to-end solution that helps provide predictable outcomes. You can now build, evaluate, optimize, and deploy agents at scale on AWS with this integrated solution. To get started, check out the Strands Agents and NeMo Agent Toolkit integration example and deploying Strands Agents and NeMo Agent Toolkit to Amazon Bedrock AgentCore Runtime.
About the authors
Kosti Vasilakakis is a Principal PM at AWS on the Agentic AI team, where he has led the design and development of several Bedrock AgentCore services from the ground up, including Runtime, Browser, Code Interpreter, and Identity. He previously worked on Amazon SageMaker since its early days, launching AI/ML capabilities now used by thousands of companies worldwide. Earlier in his career, Kosti was a data scientist. Outside of work, he builds personal productivity automations, plays tennis, and enjoys life with his wife and kids.
Sagar Murthy is an agentic AI GTM leader at AWS, where he collaborates with frontier foundation model partners, agentic frameworks, startups, and enterprise customers to evangelize AI and data innovations, open-source solutions, and scale impactful partnerships. With collaboration experiences spanning data, cloud and AI, he brings a blend of technical solutions background and business outcomes focus to delight developers and customers.
Chris Smith is a Solutions Architect at AWS specializing in AI-powered automation and enterprise AI agent orchestration. With over a decade of experience architecting solutions at the intersection of generative AI, cloud computing, and systems integration, he helps organizations design and deploy agent systems that transform emerging technologies into measurable business outcomes. His work spans technical architecture, security-first implementation, and cross-functional team leadership.
Ranjit Rajan is a Senior Solutions Architect at NVIDIA, where he helps customers design and build solutions spanning generative AI, agentic AI, and accelerated multi-modal data processing pipelines for pre-training and fine-tuning foundation models.
Abdullahi Olaoye is a Senior AI Solutions Architect at NVIDIA, specializing in integrating NVIDIA AI libraries, frameworks, and products with cloud AI services and open-source tools to optimize AI model deployment, inference, and generative AI workflows. He collaborates with AWS to enhance AI workload performance and drive adoption of NVIDIA-powered AI and generative AI solutions.
Abhishek Sawarkar is a product manager in the NVIDIA AI Enterprise team working on Agentic AI. He focuses on product strategy and roadmap of integrating Agentic AI library in partner platforms & enhancing user experience on accelerated computing for AI Agents.