Can large language models collaborate without sending a single token of text? a team of researchers from Tsinghua University, Infinigence AI, The Chinese University of Hong Kong, Shanghai AI Laboratory, and Shanghai Jiao Tong University say yes. Cache-to-Cache (C2C) is a new communication paradigm where large language models exchange information through their KV-Cache rather than through generated text.
https://arxiv.org/pdf/2510.03215
Text communication is the bottleneck in multi LLM systems
Current multi LLM systems mostly use text to communicate. One model writes an explanation, another model reads it as context.
This design has three practical costs:
Internal activations are compressed into short natural language messages. Much of the semantic signal in the KV-Cache never crosses the interface.
Natural language is ambiguous. Even with structured protocols, a coder model may encode structural signals, such as the role of an HTML <p> tag, that do not survive a vague textual description.
Every communication step requires token by token decoding, which dominates latency in long analytical exchanges.
The C2C work asks a direct question, can we treat KV-Cache as the communication channel instead.
Oracle experiments, can KV-Cache carry communication
The research team first run two oracle style experiments to test whether KV-Cache is a useful medium.
Cache enrichment oracle
They compare three setups on multiple choice benchmarks:
Direct, prefill on the question only.
Few shot, prefill on exemplars plus question, longer cache.
Oracle, prefill on exemplars plus question, then discard the exemplar segment and keep only the question aligned slice of the cache, so cache length is the same as Direct.
https://arxiv.org/pdf/2510.03215
Oracle improves accuracy from 58.42 percent to 62.34 percent at the same cache length, while Few shot reaches 63.39 percent. This demonstrates that enriching the question KV-Cache itself, even without more tokens, improves performance. Layer wise analysis shows that enriching only selected layers is better than enriching all layers, which later motivates a gating mechanism.
Cache transformation oracle
Next, they test whether KV-Cache from one model can be transformed into the space of another model. A three layer MLP is trained to map KV-Cache from Qwen3 4B to Qwen3 0.6B. t SNE plots show that the transformed cache lies inside the target cache manifold, but only in a sub region.
https://arxiv.org/pdf/2510.03215
C2C, direct semantic communication through KV-Cache
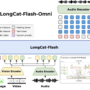
Based on these oracles, the research team defines Cache-to-Cache communication between a Sharer and a Receiver model.
During prefill, both models read the same input and produce layer wise KV-Cache. For each Receiver layer, C2C selects a mapped Sharer layer and applies a C2C Fuser to produce a fused cache. During decoding, the Receiver predicts tokens conditioned on this fused cache instead of its original cache.
The C2C Fuser follows a residual integration principle and has three modules:
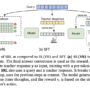
Projection module concatenates Sharer and Receiver KV-Cache vectors, applies a projection layer, then a feature fusion layer.
Dynamic weighting module modulates heads based on the input so that some attention heads rely more on Sharer information.
Learnable gate adds a per layer gate that decides whether to inject Sharer context into that layer. The gate uses a Gumbel sigmoid during training and becomes binary at inference.
Sharer and Receiver can come from different families and sizes, so C2C also defines:
Token alignment by decoding Receiver tokens to strings and re encoding them with the Sharer tokenizer, then choosing Sharer tokens with maximal string coverage.
Layer alignment using a terminal strategy that pairs top layers first and walks backward until the shallower model is fully covered.
https://arxiv.org/pdf/2510.03215
During training, both LLMs are frozen. Only the C2C module is trained, using a next token prediction loss on Receiver outputs. The main C2C fusers are trained on the first 500k samples of the OpenHermes2.5 dataset, and evaluated on OpenBookQA, ARC Challenge, MMLU Redux and C Eval.
Accuracy and latency, C2C versus text communication
Across many Sharer Receiver combinations built from Qwen2.5, Qwen3, Llama3.2 and Gemma3, C2C consistently improves Receiver accuracy and reduces latency. For results:
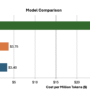
C2C achieves about 8.5 to 10.5 percent higher average accuracy than individual models.
C2C outperforms text communication by about 3.0 to 5.0 percent on average.
C2C delivers around 2x average speedup in latency compared with text based collaboration, and in some configurations the speedup is larger.
A concrete example uses Qwen3 0.6B as Receiver and Qwen2.5 0.5B as Sharer. On MMLU Redux, the Receiver alone reaches 35.53 percent, text to text reaches 41.03 percent, and C2C reaches 42.92 percent. Average time per query for text to text is 1.52 units, while C2C stays close to the single model at 0.40. Similar patterns appear on OpenBookQA, ARC Challenge and C Eval.
On LongBenchV1, with the same pair, C2C outperforms text communication across all sequence length buckets. For sequences of 0 to 4k tokens, text communication reaches 29.47 while C2C reaches 36.64. Gains remain for 4k to 8k and for longer contexts.
https://arxiv.org/pdf/2510.03215
Key Takeaways
Cache-to-Cache communication lets a Sharer model send information to a Receiver model directly via KV-Cache, so collaboration does not need intermediate text messages, which removes the token bottleneck and reduces semantic loss in multi model systems.
Two oracle studies show that enriching only the question aligned slice of the cache improves accuracy at constant sequence length, and that KV-Cache from a larger model can be mapped into a smaller model’s cache space through a learned projector, confirming cache as a viable communication medium.
C2C Fuser architecture combines Sharer and Receiver caches with a projection module, dynamic head weighting and a learnable per layer gate, and integrates everything in a residual way, which allows the Receiver to selectively absorb Sharer semantics without destabilizing its own representation.
Consistent accuracy and latency gains are observed across Qwen2.5, Qwen3, Llama3.2 and Gemma3 model pairs, with about 8.5 to 10.5 percent average accuracy improvement over a single model, 3 to 5 percent gains over text to text communication, and around 2x faster responses because unnecessary decoding is removed.
Editorial Comments
Cache-to-Cache reframes multi LLM communication as a direct semantic transfer problem, not a prompt engineering problem. By projecting and fusing KV-Cache between Sharer and Receiver with a neural fuser and learnable gating, C2C uses the deep specialized semantics of both models while avoiding explicit intermediate text generation, which is an information bottleneck and a latency cost. With 8.5 to 10.5 percent higher accuracy and about 2x lower latency than text communication, C2C is a strong systems level step toward KV native collaboration between models.
Check out the Paper and Codes. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
The post Cache-to-Cache(C2C): Direct Semantic Communication Between Large Language Models via KV-Cache Fusion appeared first on MarkTechPost.