As AI agents are adopted at scale, developer teams can create dozens to hundreds of specialized Model Context Protocol (MCP) servers, tailored for specific agent use case and domain, organization functions or teams. Organizations also need to integrate their own existing MCP servers or open source MCP servers for their AI workflows. There is a need for a way to efficiently combine these existing MCP servers–whether custom-built, publicly available, or open source–into a unified interface that AI agents can readily consume and teams can seamlessly share across the organization.
Earlier this year, we introduced Amazon Bedrock AgentCore Gateway, a fully managed service that serves as a centralized MCP tool server, providing a unified interface where agents can discover, access, and invoke tools. Today, we’re extending support for existing MCP servers as a new target type in AgentCore Gateway. With this capability, you can group multiple task-specific MCP servers aligned to agent goals behind a single, manageable MCP gateway interface. This reduces the operational complexity of maintaining separate gateways, while providing the same centralized tool and authentication management that existed for REST APIs and AWS Lambda functions.
Without a centralized approach, customers face significant challenges: discovering and sharing tools across organizations becomes fragmented, managing authentication across multiple MCP servers grows increasingly complex, and maintaining separate gateway instances for each server quickly becomes unmanageable. Amazon Bedrock AgentCore Gateway helps solves these challenges by treating existing MCP servers as native targets, giving customers a single point of control for routing, authentication, and tool management—making it as simple to integrate MCP servers as it is to add other targets to the gateway.
Breaking down MCP silos: Why enterprise teams need a unified Gateway
Let’s explore this through a real-world example of an e-commerce ordering system, where different teams maintain specialized MCP servers for their specific domains. Consider an enterprise e-commerce system where different teams have developed specialized MCP servers:
The Shopping Cart team maintains an MCP server with cart management tools
The Product Catalog team runs their MCP server for product browsing and search
The Promotions team operates an MCP server handling promotional logic
Previously, an ordering agent would need to interact with each of these MCP servers separately, managing multiple connections and authentication contexts. With the new MCP server target support in AgentCore Gateway, these specialized servers can now be unified under a single gateway while maintaining their team-specific ownership and access controls. The power of this approach lies in its organizational flexibility. Teams can group their MCP servers based on multiple logical criteria:
Business unit alignment: Organize the MCP servers by business unit
Product feature boundaries: Each product team owns their MCP server with domain-specific tools allowing them to maintain clear ownership while providing a unified interface for their agents
Security and access control: Different MCP servers require different authentication mechanisms. The gateway handles the authentication complexity, making it simple for authorized agents to access the tools they need
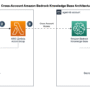
The following diagram illustrates how an ordering agent interacts with multiple MCP servers through AgentCore Gateway. The agent connects to the gateway and discovers the available tools. Each team maintains control over their domain-specific tools while contributing to a cohesive agent experience. The gateway handles tool naming collisions, authentication, and provides unified semantic search across the tools.
The AgentCore Gateway serves as an integration hub in modern agentic architectures, offering a unified interface for connecting diverse agent implementations with a wide array of tool providers. The architecture, as illustrated in the diagram, demonstrates how the gateway bridges the gap between agent and tool implementation approaches, now enhanced with the ability to directly integrate MCP server targets.
AgentCore Gateway integration architecture
In AgentCore Gateway, a target defines the APIs, Lambda functions, or other MCP servers that a gateway will provide as tools to an agent. Targets can be Lambda functions, OpenAPI specifications, Smithy models, MCP servers, or other tool definitions.
The target integration side of the architecture showcases the gateway’s versatility in tool integration. With the new MCP server target support, the gateway can directly incorporate tools from public MCP servers, treating them as first-class citizens alongside other target types. This capability extends to federation scenarios where one AgentCore Gateway instance can serve as a target for another, for hierarchical tool organization across organizational boundaries. The gateway can seamlessly integrate with AgentCore Runtime instances that expose agents as tools, private MCP servers maintained by customers, traditional AWS Lambda functions, and both Smithy and AWS service APIs.
Beyond target diversity, the gateway’s authentication architecture provides additional operational benefits. The gateway decouples its inbound authentication from target systems, letting agents access tools that use multiple identity providers through a single interface. This centralized approach simplifies development, deployment, and maintenance of AI agents. Now, the same approach can be used for MCP server targets, where the gateway manages the complexity of interfacing with the server using the configured identity provider for the target.
With this authentication foundation you get sophisticated tool management capabilities through a unified architecture. When an agent requests tool discovery, the gateway provides a consistent view across the integrated targets, with tools from MCP servers appearing alongside Lambda functions and traditional APIs. The semantic search capability operates uniformly across the tool types, so agents can discover relevant tools regardless of their implementation. During tool invocation, the gateway handles the necessary protocol translations, authentication flows, and data transformations, presenting a clean, consistent interface to agents while managing the complexity of different target systems behind the scenes.
The addition of MCP server target support represents a significant evolution in the gateway’s capabilities. Organizations can now directly integrate MCP-native tools while maintaining their investments in traditional APIs and Lambda functions. This flexibility allows for gradual migration strategies where teams can adopt MCP-native implementations at their own pace while facilitating continuous operation of existing integrations. The gateway’s synchronization mechanisms make sure that tool definitions remain current across the different target types, while its authentication and authorization systems provide consistent security controls regardless of the underlying tool implementation.
The gateway combines MCP servers, traditional APIs, and serverless functions into a coherent tool environment. This capability, along with enterprise-grade security and performance, makes it a beneficial infrastructure for agentic computing.
Solution Walkthrough
In this post, we’ll guide you through the steps to set up an MCP server target in AgentCore Gateway, which is as simple as adding a new MCP server type target to a new or existing MCP Gateway. Adding an MCP server to an AgentCore Gateway will allow you to centralize your tool management, security authentication, and operational best practices with managing MCP servers at scale.
Get started with adding MCP Server into AgentCore Gateway
To get started, you will create an AgentCore Gateway and add your MCP Server as a target.
Prerequisites
Verify you have the following prerequisites:
AWS account with Amazon Bedrock AgentCore access. For more information review Permissions for AgentCore Runtime documentation.
Python 3.12 or later
Basic understanding of OAuth 2.0
You can create gateways and add targets through multiple interfaces:
AWS SDK for Python (Boto3)
AWS Management Console
AWS Command Line Interface (AWS CLI)
AgentCore starter toolkit for fast and straightforward setup
The following practical examples and code snippets demonstrate how to set up and use Amazon Bedrock AgentCore Gateway. For an interactive walkthrough, you can use these Jupyter Notebook samples on GitHub.
Create a gateway
To create a gateway, you can use the AgentCore starter toolkit to create a default authorization configuration with Amazon Cognito for JWT-based inbound authorization. You can also use another OAuth 2.0-compliant authentication provider instead of Cognito.
import time
import boto3
gateway_client = boto3.client(“bedrock-agentcore-control”)
# Create an authorization configuration, that specifies what client is authorized to access this Gateway
auth_config = {
“customJWTAuthorizer”: {
“allowedClients”: [‘<cognito_client_id>’], # Client MUST match with the ClientId configured in Cognito.
“discoveryUrl”: ‘<cognito_oauth_discovery_url>’,
}
}
# Call the create_gateway API
# This operation is asynchronous so may take time for Gateway creation
# This Gateway will leverage a CUSTOM_JWT authorizer, the Cognito User Pool we reference in auth_config
def deploy_gateway(poll_interval=5):
create_response = gateway_client.create_gateway(
name=”DemoGateway”,
roleArn=”<IAM Role>”, # The IAM Role must have permissions to create/list/get/delete Gateway
protocolType=”MCP”,
authorizerType=”CUSTOM_JWT”,
authorizerConfiguration=auth_config,
description=”AgentCore Gateway with MCP Server Target”,
)
gatewayID = create_response[“gatewayId”]
gatewayURL = create_response[“gatewayUrl”]
# Wait for deployment
while True:
status_response = gateway_client.get_gateway(gatewayIdentifier=gatewayID)
status = status_response[“status”]
if status == “READY”:
print(“✅ AgentCore Gateway is READY!”)
break
elif status in [“FAILED”]:
print(f”❌ Deployment failed: {status}”)
return None
print(f”Status: {status} – waiting…”)
time.sleep(poll_interval)
if __name__ == “__main__”:
deploy_gateway()
# Values with < > needs to be replaced with real values
Create a sample MCP Server
As an example, let’s create a sample MCP server with three simple tools that return static responses. The server uses FastMCP with stateless_http=True which is required for AgentCore Runtime compatibility.
from mcp.server.fastmcp import FastMCP
mcp = FastMCP(host=”0.0.0.0″, stateless_http=True)
@mcp.tool()
def getOrder() -> int:
“””Get an order”””
return 123
@mcp.tool()
def updateOrder(orderId: int) -> int:
“””Update existing order”””
return 456
@mcp.tool()
def cancelOrder(orderId: int) -> int:
“””cancel existing order”””
return 789
if __name__ == “__main__”:
mcp.run(transport=”streamable-http”)
Configure AgentCore Runtime deployment
Next, we will use the starter toolkit to configure the AgentCore Runtime deployment. The toolkit can create the Amazon ECR repository on launch and generate a Dockerfile for deployment on AgentCore Runtime. You can use your own existing MCP server, we’re using the following only as an example. In a real-world environment, the inbound authorization for your MCP server will likely differ from the gateway configuration. Refer to this GitHub code example to create an Amazon Cognito user pool for Runtime authorization.
from bedrock_agentcore_starter_toolkit import Runtime
from boto3.session import Session
boto_session = Session()
region = boto_session.region_name
print(f”Using AWS region: {region}”)
required_files = [‘mcp_server.py’, ‘requirements.txt’]
for file in required_files:
if not os.path.exists(file):
raise FileNotFoundError(f”Required file {file} not found”)
print(“All required files found ✓”)
agentcore_runtime = Runtime()
auth_config = {
“customJWTAuthorizer”: {
“allowedClients”: [
‘<runtime_cognito_client_id>’ # Client MUST match with the ClientId configured in Cognito, and can be separate from the Gateway Cognito provider.
],
“discoveryUrl”: ‘<cognito_oauth_discovery_url>’,
}
}
print(“Configuring AgentCore Runtime…”)
response = agentcore_runtime.configure(
entrypoint=”mcp_server.py”,
auto_create_execution_role=True,
auto_create_ecr=True,
requirements_file=”requirements.txt”,
region=region,
authorizer_configuration=auth_config,
protocol=”MCP”,
agent_name=”mcp_server_agentcore”
)
print(“Configuration completed ✓”)
# Values with < > needs to be replaced with real values
Launch MCP server to AgentCore Runtime
Now that we have the Dockerfile, let’s launch the MCP server to AgentCore Runtime:
print(“Launching MCP server to AgentCore Runtime…”)
print(“This may take several minutes…”)
launch_result = agentcore_runtime.launch()
agent_arn = launch_result.agent_arn
agent_id = launch_result.agent_id
print(“Launch completed ✓”)
encoded_arn = agent_arn.replace(‘:’, ‘%3A’).replace(‘/’, ‘%2F’)
mcp_url = f”https://bedrock-agentcore.{region}.amazonaws.com/runtimes/{encoded_arn}/invocations?qualifier=DEFAULT”
print(f”Agent ARN: {launch_result.agent_arn}”)
print(f”Agent ID: {launch_result.agent_id}”)
Create MCP server as target for AgentCore Gateway
Create an AgentCore Identity Resource Credential Provider for the AgentCore Gateway to use as outbound auth to the MCP server agent in AgentCore Runtime:
identity_client = boto3.client(‘bedrock-agentcore-control’, region_name=region)
cognito_provider = identity_client.create_oauth2_credential_provider(
name=”gateway-mcp-server-identity”,
credentialProviderVendor=”CustomOauth2″,
oauth2ProviderConfigInput={
‘customOauth2ProviderConfig’: {
‘oauthDiscovery’: {
‘discoveryUrl’: ‘<cognito_oauth_discovery_url>’,
},
‘clientId’: ‘<runtime_cognito_client_id>’, # Client MUST match with the ClientId configured in Cognito for the Runtime authorizer
‘clientSecret’: ‘<cognito_client_secret>’
}
}
)
cognito_provider_arn = cognito_provider[‘credentialProviderArn’]
print(cognito_provider_arn)
# Values with < > needs to be replaced with real values
Create a gateway target pointing to the MCP server:
gateway_client = boto3.client(“bedrock-agentcore-control”, region_name=region)
create_gateway_target_response = gateway_client.create_gateway_target(
name=”mcp-server-target”,
gatewayIdentifier=gatewayID,
targetConfiguration={“mcp”: {“mcpServer”: {“endpoint”: mcp_url}}},
credentialProviderConfigurations=[
{
“credentialProviderType”: “OAUTH”,
“credentialProvider”: {
“oauthCredentialProvider”: {
“providerArn”: cognito_provider_arn,
“scopes”: [“<cognito_oauth_scopes>”],
}
},
},
],
) # Asynchronously create gateway target
gatewayTargetID = create_gateway_target_response[“targetId”]
# Values with < > needs to be replaced with real values
After creating a gateway target, implement a polling mechanism to check for the gateway target status using the get_gateway_target API call:
import time
def poll_for_status(interval=5):
# Poll for READY status
while True:
gateway_target_response = gateway_client.get_gateway_target(gatewayIdentifier=gatewayID, targetId=gatewayTargetID)
status = gateway_target_response[“status”]
if status == ‘READY’:
break
elif status in [‘FAILED’, ‘UPDATE_UNSUCCESSFUL’, ‘SYNCHRONIZE_UNSUCCESSFUL’]:
raise Exception(f”Gateway target failed with status: {status}”)
time.sleep(interval)
poll_for_status()
Test Gateway with Strands Agents framework
Let’s test the Gateway with the Strands Agents integration to list the tools from MCP server. You can also use other MCP-compatible agents built with different agentic frameworks.
from strands import Agent
from mcp.client.streamable_http import streamablehttp_client
from strands.tools.mcp.mcp_client import MCPClient
def create_streamable_http_transport():
return streamablehttp_client(gatewayURL,headers={“Authorization”: f”Bearer {token}”})
client = MCPClient(create_streamable_http_transport)
with client:
# Call the listTools
tools = client.list_tools_sync()
# Create an Agent with the model and tools
agent = Agent(model=yourmodel,tools=tools) ## you can replace with any model you like
# Invoke the agent with the sample prompt. This will only invoke MCP listTools and retrieve the list of tools the LLM has access to. The below does not actually call any tool.
agent(“Hi , can you list all tools available to you”)
# Invoke the agent with sample prompt, invoke the tool and display the response
agent(“Get the Order id”)
Refreshing tool definitions of your MCP servers in AgentCore Gateway
The SynchronizeGatewayTargets API is a new asynchronous operation that enables on-demand synchronization of tools from MCP server targets. MCP servers host tools which agents can discover and invoke. With time, these tools might need to be updated, or new tools may be introduced in an existing MCP server target. You can connect with external MCP servers through the SynchronizeGatewayTargets API that performs protocol handshakes and indexes available tools. This API provides customers with explicit control over when to refresh their tool definitions, particularly useful after making changes to their MCP server’s tool configurations.
When a target is configured with OAuth authentication, the API first interacts with the AgentCore Identity service to retrieve the necessary credentials from the specified credential provider. These credentials are validated for freshness and availability before communication with the MCP server begins. If the credential retrieval fails or returns expired tokens, the synchronization operation fails immediately with appropriate error details, transitioning the target to a FAILED state. For targets configured without authentication, the API proceeds directly to tool synchronization.
The tool processing workflow begins with an initialize call to the MCP server to establish a session. Following successful initialization, the API makes paginated calls to the MCP server’s tools/list capability, processing tools in batches of 100 to optimize performance and resource utilization. Each batch of tools undergoes normalization where the API adds target-specific prefixes to help prevent naming collisions with tools from other targets. During processing, tool definitions are normalized to facilitate consistency across different target types, while preserving the essential metadata from the original MCP server definitions.
The synchronization flow begins when:
An Ops Admin initiates the SynchronizeGatewayTargets API, triggering AgentCore Gateway to refresh the configured MCP target.
The gateway obtains an OAuth token from AgentCore Identity for secure access to the MCP target.
The gateway then initializes a secure session with the MCP server to retrieve version capabilities.
Finally, the gateway makes paginated calls to the MCP server tools/list endpoint to retrieve the tool definitions, making sure the gateway maintains a current and accurate list of tools.
The SynchronizeGatewayTargets API addresses a critical challenge in managing MCP targets within AgentCore Gateway: maintaining an accurate representation of available tools while optimizing system performance and resource utilization. Here’s why this explicit synchronization approach is valuable:
Schema consistency management: Without explicit synchronization, AgentCore Gateway would need to either make real-time calls to MCP servers during ListTools operations (impacting latency and reliability) or risk serving stale tool definitions. The SynchronizeGatewayTargets API provides a controlled mechanism where customers can refresh their tool schemas at strategic times, such as after deploying new tools or updating existing ones in their MCP server. This approach makes sure that tool definitions in the gateway accurately reflect the target MCP server’s capabilities without compromising performance.
Performance impact trade-offs: The API implements optimistic locking during synchronization to help prevent concurrent modifications that could lead to inconsistent states. While this means multiple synchronization requests might need to retry if there’s contention, this trade-off is acceptable because:
Tool schema changes are typically infrequent operational events rather than regular runtime occurrences
The performance cost of synchronization is incurred only when explicitly requested, not during regular tool invocations
The cached tool definitions facilitate consistent high performance for ListTools operations between synchronizations
Invoke the synchronize gateway API
Use the following example to invoke the synchronize gateway operation:
import requests
import json
def search_tools(gateway_url, access_token, query):
headers = {
“Content-Type”: “application/json”,
“Authorization”: f”Bearer {access_token}”
}
payload = {
“jsonrpc”: “2.0”,
“id”: “search-tools-request”,
“method”: “tools/call”,
“params”: {
“name”: “x_amz_bedrock_agentcore_search”,
“arguments”: {
“query”: query
}
}
}
response = requests.post(gateway_url, headers=headers, json=payload, timeout=5)
response.raise_for_status()
return response.json()
# Example usage
token_response = utils.get_token(user_pool_id, client_id, client_secret, scopeString, REGION)
access_token = token_response[‘access_token’]
results = search_tools(gatewayURL, access_token, “order operations”)
print(json.dumps(results, indent=2))
Implicit synchronization of tools schema
During CreateGatewayTarget and UpdateGatewayTarget operations, AgentCore Gateway performs an implicit synchronization that differs from the explicit SynchronizeGatewayTargets API. This implicit synchronization makes sure that MCP targets are created or updated with valid, current tool definitions, aligning with the assurance from AgentCore Gateway that targets in READY state are immediately usable. While this might make create/update operations take longer than with other target types, it helps prevent the complexity and potential issues of having targets without validated tool definitions.
The implicit synchronization flow begins when:
An Ops Admin creates or updates the MCP target using CreateGatewayTarget or UpdateGatewayTarget operations.
AgentCore Gateway configures the new or updated MCP target.
The gateway asynchronously triggers the synchronization process to update the tool definitions.
The gateway obtains an OAuth token from AgentCore Identity for secure access.
The gateway then initializes a secure session with the MCP server to retrieve version capabilities.
Finally, the gateway makes paginated calls to the MCP server’s tools/list endpoint to retrieve the tool definitions, making sure the gateway maintains a current and accurate list of tools.
ListTools behavior for MCP targets
The ListTools operation in AgentCore Gateway provides access to tool definitions previously synchronized from MCP targets, following a cache-first approach that prioritizes performance and reliability. Unlike traditional OpenAPI or Lambda targets where tool definitions are statically defined, MCP target tools are discovered and cached through synchronization operations. When a client calls ListTools, the gateway retrieves tool definitions from its persistent storage rather than making real-time calls to the MCP server. These definitions were previously populated either through implicit synchronization during target creation/update or through explicit SynchronizeGatewayTargets API calls. The operation returns a paginated list of normalized tool definitions.
InvokeTool (tools/call) Behavior for MCP Targets
The InvokeTool operation for MCP targets handles the actual execution of tools discovered through ListTools, managing real-time communication with the target MCP server. Unlike the cache-based ListTools operation, tools/call requires active communication with the MCP server, introducing specific authentication, session management, and error handling requirements. When a tools/call request arrives, AgentCore Gateway first validates the tool exists in its synchronized definitions. For MCP targets, AgentCore Gateway performs an initial initialize call to establish a session with the MCP server. If the target is configured with OAuth credentials, AgentCore Gateway retrieves fresh credentials from AgentCore Identity before making the initialize call. This makes sure that even if ListTools returned cached tools with expired credentials, the actual invocation uses valid authentication.
The inbound authorization flow begins when:
The MCP client initializes a request with MCP protocol version to AgentCore Gateway.
The client then sends the tools/call request to the gateway.
The gateway obtains an OAuth token from AgentCore Identity for secure access.
The gateway initializes a secure session with the MCP server to invoke and handle the actual execution of the tool.
Search tool behavior for MCP targets
The search capability in AgentCore Gateway enables semantic discovery of tools across the different target types, including MCP targets. For MCP targets, the search functionality operates on normalized tool definitions that were captured and indexed during synchronization operations, providing efficient semantic search without real-time MCP server communication.
When tool definitions are synchronized from an MCP target, AgentCore Gateway automatically generates embeddings for each tool’s name, description, and parameter descriptions. These embeddings are stored alongside the normalized tool definitions, enabling semantic search that understands the intent and context of search queries. Unlike traditional keyword matching, this allows agents to discover relevant tools even when exact terminology doesn’t match.
Search for MCP server tools through the gateway
Use the following example to search for tools through the gateway.
import requests
import json
def search_tools(gateway_url, access_token, query):
headers = {
“Content-Type”: “application/json”,
“Authorization”: f”Bearer {access_token}”
}
payload = {
“jsonrpc”: “2.0”,
“id”: “search-tools-request”,
“method”: “tools/call”,
“params”: {
“name”: “x_amz_bedrock_agentcore_search”,
“arguments”: {
“query”: query
}
}
}
response = requests.post(gateway_url, headers=headers, json=payload, timeout=5)
response.raise_for_status()
return response.json()
# Example usage
token_response = utils.get_token(user_pool_id, client_id, client_secret, scopeString, REGION)
access_token = token_response[‘access_token’]
results = search_tools(gatewayURL, access_token, “math operations”)
print(json.dumps(results, indent=2))
Conclusion
Today’s announcement of MCP server support as a target type in Amazon Bedrock AgentCore Gateway is an advancement in enterprise AI agent development. This new capability addresses critical challenges in scaling MCP server implementations while maintaining security and operational efficiency. By integrating existing MCP servers alongside REST APIs and Lambda functions, AgentCore Gateway provides a more unified, secure, and manageable solution for tool integration at scale. Organizations can now manage their tools through a single, centralized interface while benefiting from unified authentication, simplified tool discovery and reduced maintenance overhead.
For more detailed information and advanced configurations, refer to the code samples on GitHub, the Amazon Bedrock AgentCore Gateway Developer Guide and Amazon AgentCore Gateway pricing.
About the authors
Frank Dallezotte is a Senior Solutions Architect at AWS and is passionate about working with independent software vendors to design and build scalable applications on AWS. He has experience creating software, implementing build pipelines, and deploying these solutions in the cloud.
Ganesh Thiyagarajan is a Senior Solutions Architect at Amazon Web Services (AWS) with over 20 years of experience in software architecture, IT consulting, and solution delivery. He helps ISVs transform and modernize their applications on AWS. He is also part of the AI/ML Technical field community, helping customers build and scale Gen AI solutions.
Dhawal Patel is a Principal Generative AI Tech lead at Amazon Web Services (AWS). He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to Agentic AI, Deep learning, distributed computing.