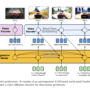
Agentic AI browsers are moving the model from ‘answering about the web’ to operating on the web. In 2025, four AI browsers define this space: OpenAI’s ChatGPT Atlas, Microsoft Edge with Copilot Mode, The Browser Company’s Dia, and Perplexity’s Comet. Each makes different design choices around autonomy, memory, and privacy. This article compares their architectures, capabilities, and risk profiles so various type of users can decide which browser aligns with their workflows.
What are Agentic Browsers?
Agentic browsers are not just ‘chat over a page’. They expose the browser’s DOM (Document Object Model), tab graph, and history to an AI model and allow it to:
Read and reason over multiple tabs
Maintain task context across time
Take actions such as navigating, filling forms, and completing workflows
OpenAI ChatGPT Atlas, Microsoft Edge Copilot Mode, The Browser Company’s Dia, and Perplexity’s Comet all do this, but with different tradeoffs in autonomy, memory, and security.
High-level comparison
Atlas is the most fully agentic: deep ChatGPT integration, rich browser control, strong but complex memory and privacy story.
Copilot Mode is an incremental but significant extension to Edge: unified Copilot, cross-tab reasoning, early ‘Actions’ for automation, still conservative compared with Atlas and Comet.
Dia is an AI-first browser built on Chromium, optimized for reading, writing, and structured workflows with privacy-first defaults and intentionally limited autonomy.
Comet is a highly agentic personal assistant browser with deep workflow automation, a local-data narrative, and currently the most aggressive legal and security risk profile.
The rest of the article unpacks these differences in a more technical way.
1. ChatGPT Atlas (OpenAI): AI-native browser with full agent mode
1.1 Architecture
Atlas is a dedicated AI browser built around ChatGPT rather than a standard Chromium shell with an extension. It runs on Chromium but wraps it in OpenAI’s OWL process architecture, which separates the rendering engine from the Atlas application and agent layer.
Key characteristics:
macOS only at launch, with Windows, iOS, and Android ‘coming soon’.
ChatGPT is exposed everywhere: omnibox, main panel, and a ChatGPT sidebar that can see the current page and tabs.
This gives Atlas a first-class API into:
Current tab DOM and visible content
Tab list and navigation history
User queries and previous conversation state
1.2 Agent mode: real browser control
Agent Mode is the key differentiator. For Plus / Pro / Business users, Atlas can execute multi-step workflows:
Open and close tabs, follow links, and switch sites
Fill out forms and online applications
Book reservations such as hotels and restaurants
Compare products across multiple sites and return structured summaries
Constraints:
Agent mode cannot access local files or the OS, and cannot download or execute local programs. It is sandboxed inside the browser.
Actions require explicit user consent; Atlas surfaces prompts like ‘Should I start clicking and filling these forms’ before executing workflows.
1.3 Memory and privacy
Atlas introduces browser memories:
It stores filtered summaries of visited pages and inferred user intent, not full page captures. Summaries are retained for about 30 days, enabling queries like ‘reopen the reports I read yesterday’ or ‘continue the Athens itinerary plan’.
Memories are opt-in and can be viewed, edited, or deleted. Memory can be disabled globally or on specific sites, and Atlas supports incognito.
OpenAI also added parental controls that let guardians disable both browser memories and agent mode for child accounts.
Critical points:
Atlas still needs to transmit page snippets and metadata to OpenAI’s servers for summarization, which means sensitive content can be exposed if protections fail.
Security researchers have already demonstrated prompt-injection attacks that exploit Atlas’s omnibox and agent context, confirming that highly agentic browsing increases the attack surface.
1.4 Pricing and fit
Atlas is free to install for ChatGPT users on macOS.
Agent Mode is only available on paid ChatGPT tiers (Plus, Pro, Business, Enterprise).
Fit:
Best for users who want maximum in-browser automation and are comfortable with cloud-centric data handling and a still-evolving security posture.
2. Copilot Mode in Microsoft Edge: tab-reasoning with controlled autonomy
2.1 Architecture
Copilot Mode is Microsoft’s AI layer inside Edge, not a separate browser. It exposes:
A unified Copilot box on new tabs for chat, search, and navigation
Deep integration with Edge context (open tabs, history, and some browser settings) when users opt in.
Microsoft also ties Copilot Mode into:
Journeys: topic-centric clusters over browsing history, which Copilot can summarize and re-open.
Copilot Actions: an early agentic layer capable of actions like clearing cache, unsubscribing from mailing lists, and booking reservations in preview.
2.2 Agentic behavior
Compared with Atlas:
Copilot Mode can reason across multiple tabs, summarize and compare them, and assist with structured tasks like trip planning or multi-site research.
Actions Preview extends this into partially agentic flows, such as booking a restaurant or filling forms, but current evaluations show inconsistent reliability and occasional ‘hallucinated’ completions of tasks that were not successfully executed.
Crucially, Copilot Mode remains more constrained than Atlas or Comet:
It does not expose an openly programmable DOM-level agent with free cursor control
Action templates are narrower and guarded, particularly for email and account-sensitive operations
2.3 Data, privacy, and enterprise posture
Edge with Copilot Mode is clearly aimed at enterprise adoption:
Copilot access to tab and history data is explicitly permissioned; users can disable history-based personalization, Copilot context, and Copilot Mode entirely.
Microsoft integrates Prompt Shields and Azure AI safety layers to mitigate prompt injection and jailbreak attempts.
Fit:
Appropriate where organizations want AI-assisted browsing and cross-tab reasoning while keeping automation scoped and more auditable than a fully agentic browser.
3. Dia (The Browser Company): AI-first, Chromium-based, privacy-forward
3.1 Architecture and UX
Dia is The Browser Company’s AI-centric successor to Arc, built on Chromium and currently available on macOS only.
Core design choices:
The canonical interaction is ‘chat with your tabs‘: Dia’s assistant can read open tabs, referenced tabs, and selections, and answer questions or transform content in place.
Dia includes a Skills system, where users define reusable prompt ‘scripts’ and workflows for tasks like note-taking or research templates.
Dia’s UX is optimized for:
Reading and understanding long-form content
Writing and editing in-page
Learning workflows (tutoring, flashcards, argument comparison)
3.2 Memory and ‘local-first’ privacy
Dia’s main differentiation is its privacy posture:
Browsing history, chats, bookmarks, and saved content are stored locally and encrypted, with data sent to servers only when required to answer a specific query.
The Memory feature stores summaries and learned preferences, but users can disable memory entirely in settings or control what contexts are shared.
The net effect is an AI browser that tries to behave more like a local knowledge layer with scoped cloud calls rather than a continuous telemetry stream.
3.3 Agentic scope and constraints
Dia is intentionally less agentic than Atlas or Comet:
The assistant can read and summarize pages, transform text, generate content, and run Skills over the current tab set.
Current public builds do not expose a general DOM automation agent capable of open-ended clicking and form submission across arbitrary sites.
In practice, Dia behaves as a high-context copilot rather than a fully autonomous web operator. This is aligned with the company’s positioning and with Atlassian’s stated intent after acquiring The Browser Company, which emphasizes individual knowledge worker workflows over transactional automation.
3.4 Pricing and availability
Dia now ships to all Mac users, no invite required, as of October 2025.
Free tier: Core AI chat, Skills, and Memory, with usage limits.
Dia Pro at $20/month unlocks effectively unlimited AI chat usage within terms of use.
Fit:
Strong for educational and writing-heavy workflows, for users who want AI-augmented browsing without handing an agent broad control over the web session.
4. Comet (Perplexity): highly agentic assistant browser with heavy risk surface
4.1 Architecture and capabilities
Comet is Perplexity’s AI browser built on Chromium, positioned as a personal AI assistant and ‘thinking partner‘ rather than a simple search UI.
The Comet Assistant can:
Summarize and explore any page
Execute multi-step workflows for research, coding, meeting prep, and e-commerce
Manage email and calendar via integrated connectors
Handle complex tasks like comparing products, reading reviews, and moving all the way to checkout.
Recent updates extend the agent to work longer and across larger jobs, emphasizing persistent, agentic behavior over many tabs and time periods.
4.2 Data model and privacy claims
Perplexity’s Comet Privacy Notice and product pages claim:
Browsing data, cookies, and saved credentials are stored locally on the device by default.
Users can delete browsing data and stored credentials from Comet settings, and manage cookie behavior.
Integration with 1Password keeps vaults end-to-end encrypted and opaque to Perplexity.
So the official architecture is a hybrid: local browser state with selective context uploads to Comet’s servers and Perplexity’s search models.
However, multiple independent reviews argue that despite these controls, the combination of: Deep integration with third-party services (Gmail, calendar, financial accounts) and high agent autonomy over those services produces a large effective privacy risk envelope, especially for corporate data.
4.3 Security incidents and legal pressure
Comet currently has the most visible security and legal issues among the four:
Indirect prompt-injection / ‘CometJacking‘: LayerX and other researchers showed that malicious URLs and embedded prompts could hijack Comet’s assistant, exfiltrating data from connected services and even performing fraudulent actions.
Although Perplexity has patched specific vulnerabilities, security audits from Brave, Guardio, and others still recommend extreme caution for sensitive workloads.
Amazon lawsuit: Amazon is suing Perplexity over Comet’s ‘agentic shopping’ behavior, alleging that automated shopping sessions accessed customer accounts and impersonated human browsing, violating platform rules and harming personalization systems.
4.4 Pricing and availability
As of October–November 2025, Comet is free to download globally; earlier Max-only and Pro-only restrictions have been removed.
Perplexity monetizes via Pro / Max subscriptions for higher model tiers and via Comet Plus (~$5 / month), which grants access to curated news and publisher content and is bundled into Pro / Max.
Fit:
Very strong for users who want maximum automation across research, communications, and purchases, and who are comfortable operating at the bleeding edge of the security and platform-policy risk curve.
Comparison Table
DimensionChatGPT Atlas (OpenAI)Edge + Copilot Mode (Microsoft)Dia (The Browser Company)Comet (Perplexity)Engine / platformChromium-based; Atlas shell with OWL architecture; macOS now, Windows / mobile planned Edge (Chromium) on Windows and macOS with optional Copilot Mode Chromium-based AI browser; macOS only, GA, no invite; Windows not yet announced Chromium-based browser with integrated Perplexity search and assistant; desktop global, mobile rolling outAgentic autonomyHigh: Agent Mode can click, navigate, fill forms, book reservations, and chain multi-step workflows inside the browser Medium: cross-tab reasoning and Actions; can perform some transactional steps but with limited scope and reliabilityLow–medium: chat, Skills, and memory over tabs; no general agent that freely manipulates arbitrary sites; autonomy intentionally constrained High: Comet Assistant executes long-running workflows across browsing, email, calendar, and e-commerce, including end-to-end shopping and planning flows Memory / personalizationBrowser memories retain summarized context for ~30 days; persistent task context across sessions, opt-in and user-controllableJourneys over history, context sharing for Copilot is opt-in; personalization tied to Microsoft account and privacy controls Local encrypted storage of history, chats, bookmarks; Dia Memory for personalization with ability to limit shared contextLocal-first browsing data plus cloud-side models; settings allow deleting local data and tuning collectionBest-fit use casesComplex research, automation-heavy workflows, and agent experiments where strong autonomy outweighs riskEveryday browsing with AI summaries and research assistance in Microsoft-centric environmentsLearning, writing, and planning where privacy and structured Skills are more important than full automationPower users who want a personal operator for browsing, communication, and shopping, and who will actively manage security and policy risk
Which browser to choose in 2025?
Pick Atlas when you want to explore the frontier of in-browser agents. It offers the richest action surface and memory model, at the cost of greater complexity in safety and compliance design.
Pick Edge + Copilot Mode when you need incremental AI assistance in a browser that already fits Microsoft-centric enterprise governance, and you prefer scoped agents over unconstrained ones.
Pick Dia when your primary workload is reading, learning, and writing, and you want strong local-first guarantees and explicit control over what information the model sees, with minimal automation.
Pick Comet only if you explicitly want a high-autonomy personal operator in your browser and are willing to track security advisories and platform policies closely.
References:
OpenAI – Introducing ChatGPT Atlashttps://openai.com/index/introducing-chatgpt-atlas/
OpenAI – How we built OWL, the new architecture behind our browserhttps://openai.com/index/building-chatgpt-atlas/
Microsoft – AI browser innovation with Copilot Mode in Edgehttps://www.microsoft.com/en-us/microsoft-copilot/for-individuals/do-more-with-ai/ai-for-daily-life/ai-browser-innovation-with-copilot-in-edge
Microsoft – Copilot Mode | Microsoft Edgehttps://www.microsoft.com/en-us/edge/copilot-mode
Dia Browser – Official sitehttps://www.diabrowser.com/
Dia Browser – Skills Galleryhttps://www.diabrowser.com/skills
9to5Mac – Dia, The Browser Company’s AI-powered browser, is now generally available on macOShttps://9to5mac.com/2025/10/08/dia-the-browser-companys-ai-powered-browser-is-now-generally-available-on-macos/
Perplexity – Comet Browser: a Personal AI Assistanthttps://www.perplexity.ai/comet/
1Password – Secure credentials on Comet with 1Passwordhttps://1password.com/partners/perplexity
Reuters – Amazon sues Perplexity over “agentic” shopping toolhttps://www.reuters.com/business/retail-consumer/perplexity-receives-legal-threat-amazon-over-agentic-ai-shopping-tool-2025-11-04/
The post Comparing the Top 4 Agentic AI Browsers in 2025: Atlas vs Copilot Mode vs Dia vs Comet appeared first on MarkTechPost.