Organizations have used geospatial machine learning (ML) for property risk assessment, disaster response, and infrastructure planning. These systems worked well but couldn’t scale beyond specialized use cases. Each question required multiple geospatial datasets, each with its own model and often its own workflow, limiting these capabilities to a handful of high-value use cases at the largest enterprises that could afford the investment. In this post, you’ll learn how to deploy geospatial AI agents that can answer complex spatial questions in minutes instead of months. By combining Foursquare Spatial H3 Hub’s analysis-ready geospatial data with reasoning models deployed on Amazon SageMaker AI, you can build agents that enable nontechnical domain experts to perform sophisticated spatial analysis through natural language queries—without requiring geographic information system (GIS) expertise or custom data engineering pipelines.
Geospatial intelligence adoption barriers
Two technical barriers have prevented these specialized geospatial systems from achieving broader adoption. First, geospatial data arrives in a bewildering array of formats—satellite imagery stored as GeoTIFF rasters, administrative boundaries stored as shapefile vectors, weather models stored as NetCDF grids, and property records in proprietary cadastral formats—each requiring different parsing libraries and custom data pipelines. Second, joining datasets across spatial granularities is nontrivial: property insurance data geocoded to individual addresses must combine with climate risk data at 1 km grid cells and census demographics aggregated to block groups, requiring organizations to spend months building custom processing pipelines before answering their first business question. In short, there is no universal join key to combine these datasets. This means organizations can’t experiment with geospatial intelligence without first building data engineering pipelines to normalize diverse formats, implement spatial processing for coordinate transformations and resolution resampling, and deploy specialized computing infrastructure.
Solving technical barriers alone wasn’t sufficient. Earlier systems still required 6–12 month implementations with specialized GIS teams. Five enterprise requirements remained unaddressed: making geospatial analysis accessible to nontechnical domain experts, showing how AI reaches conclusions, supporting flexible analysis, delivering interactive response times, and offering cost predictability at scale.
Three technologies converging to address adoption challenges
Addressing these technical and enterprise barriers requires a fundamentally different approach. This architecture combines three technologies to address those gaps:
Foursquare Spatial H3 Hub for analysis-ready data – This service transforms inaccessible raster and vector geospatial data into analysis-ready features, indexed to the H3 hierarchical grid system, in tabular format that data scientists can query using familiar tools such as Spark, Python, and DuckDB. Datasets containing latitude and longitude coordinates, city names, or zip codes can be easily enriched by joining on a common H3 cell, eliminating months of data preparation and specialized GIS expertise.
Reasoning models and agentic AI for adaptive workflows – Models such as DeepSeek-R1 and Llama 3 break down complex problems, reason through multistep workflows, and orchestrate actions across data sources. They dynamically determine which datasets to combine and plan analytical sequences that previously required GIS expertise—transforming static, preconfigured workflows into adaptive reasoning systems.
Amazon SageMaker AI for cost-effective generative AI inference – This Amazon SageMaker AI capability provides managed infrastructure for deploying open source models with optimized inference runtimes, auto scaling, and operational tooling. Teams can focus on building geospatial intelligence capabilities rather than managing underlying infrastructure.
Together, these technologies enable organizations to access analysis-ready geospatial data, deploy adaptive reasoning agents, and run production inference without building specialized infrastructure. In this post, we demonstrate a production geospatial agent that combines Foursquare Spatial H3 Hub with reasoning models deployed on Amazon SageMaker AI.
Analysis-ready geospatial data with Foursquare Spatial H3 Hub
Foursquare’s Spatial H3 Hub eliminates traditional geospatial adoption barriers through a proprietary H3 indexing engine. This engine has transformed dozens of disparate geospatial datasets into an Iceberg catalog ready for immediate analysis, replacing months of data engineering with instant access to analysis-ready geospatial features.
The H3 indexing engine addresses the root cause of geospatial complexity: the vast array of formats and coordinate systems that have historically limited access to geographic information. The engine converts spatial data, raster imagery, or vector datasets by indexing it into the H3 hierarchical spatial grid at global scale. H3 divides the entire Earth into nested hexagonal cells, creating a universal grid system where every location has a standardized identifier. The engine extracts data from raster images or diverse vector shapes such as census tract polygons and converts them into features attached to H3 cell IDs in tabular format, where the cell ID becomes a universal join key that abstracts away format complexity and coordinate systems. An insurance company’s property data, National Oceanic and Atmospheric Administration (NOAA) climate projections, census demographics, and infrastructure networks can all be combined because they share this common spatial index.
The engine also handles the methodological complexities that traditionally required GIS expertise. It can index data to H3 cells at any precision from resolution 0 (about 1,000 km hexagons covering continents) down to resolution 15 (about 1 meter hexagons covering individual buildings). You can choose the appropriate resolution for each use case—coarser resolutions for regional climate analysis, finer resolutions for property-level assessment. When boundaries don’t align perfectly—like a census tract overlapping multiple H3 hexagons—the engine intelligently handles partial overlaps through either fast centroid-based approximation or exact proportional allocation based on intersection areas. It also automatically aggregates or disaggregates data when combining datasets at different scales, eliminating the manual preprocessing that traditionally consumed months of GIS specialist time.
Built on this indexing foundation, Foursquare Spatial H3 Hub delivers an Iceberg catalog containing datasets spanning energy infrastructure, environmental conditions, and natural hazards all originally in diverse raster and vector formats, now pre-indexed to H3 cells at resolution 8 (with additional resolutions available on demand). You can query this data with familiar tools such as SQL, Python, Spark, Snowflake, and Databricks without proprietary GIS software. H3 cell identifiers become straightforward column values that join like any other attribute, so you can rapidly validate geospatial hypotheses by joining their proprietary data with Foursquare’s H3 catalog.
Reasoning models for spatial Intelligence
Reasoning models such as DeepSeek-R1 change how AI handles geospatial intelligence. Traditional geospatial systems operated as collections of static, purpose-built models, with separate models for flood risk, wildfire exposure, and earthquake vulnerability. Each model was trained on specific datasets and incapable of answering questions outside its narrow domain. When requirements shifted or new data emerged, organizations faced months of retraining. Reasoning models change this paradigm by decomposing complex problems, planning multistep workflows, and orchestrating actions across data sources dynamically. Rather than requiring pre-trained models for every question, these systems reason through novel scenarios by combining available data in ways never explicitly programmed. Asked “which neighborhoods face compounding climate and economic risks?”, a reasoning agent determines it needs flood exposure data, household income, property density, and neighborhood boundaries and then executes that analytical pipeline by calling appropriate tools and data sources. The agent understands spatial relationships conceptually: point data aggregates to polygons, grid cells map to administrative boundaries, proximity requires appropriate distance metrics. At each step, it reasons about what information comes next and adjusts when data reveals unexpected patterns, transforming geospatial analysis from pre-scripted queries into adaptive investigation.
Deploying agents on Amazon SageMaker AI
Analysis-ready geospatial data and reasoning-capable models solve critical parts of the puzzle, but production deployment creates new challenges. Geospatial agents need sustained inference capacity to process queries, execute reasoning chains, retrieve data, and generate visualizations. Organizations face a choice: build custom inference infrastructure with GPU clusters, load balancers, and auto scaling policies, or rely on commercial large language model (LLM) APIs where costs scale unpredictably with usage and data governance becomes complex.
Amazon SageMaker AI provides managed infrastructure for deploying and operating open source generative AI models in production. You can deploy models from Hugging Face or Amazon SageMaker AI JumpStart—including reasoning models such as DeepSeek-R1, Llama 3, or Qwen—to SageMaker AI real-time or asynchronous inference endpoints without managing underlying infrastructure. Amazon SageMaker AI Inference handles instance provisioning, supports optimized serving runtimes like vLLM and SGLang, and provides auto scaling based on traffic patterns.
Amazon SageMaker AI Inference capabilities address several operational challenges specific to agent architectures. Geospatial agents handling variable query loads throughout the day benefit from automatic scaling on GPU instances such as G5, P4d, and P5 based on request volume or custom metrics. Long-running spatial analyses that exceed typical API timeouts can route to asynchronous inference endpoints where SageMaker AI queues request, process them, and deliver results to Amazon Simple Storage Service (Amazon S3), enabling complex multi-dataset analyses without client-side timeout issues. For architectures employing multiple models, multi-container endpoints host different models on shared infrastructure with independent scaling policies and traffic routing. Built-in integration with Amazon CloudWatch for monitoring, AWS Identity and Access Management (IAM) for access control, and Amazon Virtual Private Cloud (Amazon VPC) for network isolation simplifies operational requirements.
Foursquare Spatial H3 Hub and Amazon SageMaker AI together reduce operational complexity. Data scientists can focus on building agent capabilities, defining which H3 Hub datasets to query for specific questions, refining prompting strategies for spatial reasoning, and optimizing tool-calling patterns rather than managing underlying infrastructure. Organizations can also experiment with different open source models. Such initiatives, which previously required separate teams for data engineering, model development, and platform operations, have now become accessible to smaller teams without specialized infrastructure expertise.
Designing the Foursquare Spatial Agent
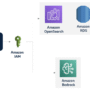
The Foursquare Spatial Agent architecture combines reasoning models deployed on SageMaker AI with tool-calling capabilities that query Foursquare Spatial H3 Hub directly. The agent orchestrates the complete workflow from natural language question to visualization without manual intervention.
Agent workflow
When a user poses a natural language question about spatial relationships—such as “Which neighborhoods in Los Angeles face both high flood risk and economic vulnerability?”—the agent executes a multistep reasoning process. The reasoning model first analyzes the question and identifies required information: flood risk scores, economic indicators like income and employment, and neighborhood boundaries. It then determines which H3 Hub datasets contain relevant information by reasoning over dataset descriptions. With datasets selected, the model calls H3 Hub query tools, constructing SQL queries that join datasets on H3 cell IDs. After executing these queries, the model analyzes results to identify spatial patterns and statistical relationships. Finally, it generates Vega specifications for charts and Kepler.gl specifications for maps that visualize the findings.
This workflow uses the reasoning model’s ability to plan, adapt, and recover from errors. If initial queries return unexpected results, the model can refine its approach, select additional datasets, or adjust spatial operations—capabilities of that static, preprogrammed workflow.
Design decisions addressing enterprise requirements
Building a production geospatial agent required addressing the five enterprise requirements identified through deployment analysis. Three key design decisions illustrate how the architecture balances accessibility, transparency, and flexibility.
Insurance underwriters understand flood risk and property exposure but don’t write SQL or Python. The agent architecture makes geospatial analysis accessible by accepting natural language questions and translating them into appropriate H3 Hub queries. The reasoning model interprets domain-specific terminology like “vulnerable neighborhoods” or “high-risk areas” and maps these concepts to relevant datasets and analytical operations. This eliminates the bottleneck where domain experts must submit analysis requests to data teams, enabling self-service exploration.
Domain experts also need to understand how the agent arrived at conclusions, especially when analyses inform business decisions. The agent can log its reasoning process at each step: which datasets were considered and why, what spatial operations were planned, which queries were executed, and how results were interpreted. Every visualization includes metadata showing which H3 cells and source datasets contributed to the analysis. This transparency means users can validate the agent’s analytical approach and understand the data sources behind conclusions. If an insurance underwriter sees a high-risk assessment for a property, they can trace back through the reasoning chain to see it combined flood exposure data from Federal Emergency Management Agency (FEMA), wildfire risk from state forestry data, and property characteristics from local assessor records—building confidence in AI-generated insights. Implementation uses structured logging to capture reasoning steps, making the agent’s decision-making process inspectable and debuggable rather than a black box.
Pre-built dashboards serve known questions but fail when analysts need to explore variations. The agent architecture provides flexibility by using tool-calling to dynamically compose analyses. Rather than predefining workflows for every scenario, the reasoning model determines which H3 Hub datasets to query and how to combine them based on the specific question. This enables the agent to handle unforeseen analytical questions without requiring new engineering work for each variation. The agent uses function calling APIs supported by models such as Llama 3 and DeepSeek-R1 to interact with H3 Hub. The model receives tool descriptions specifying available datasets, query parameters, and return formats, then constructs appropriate tool calls during reasoning. SageMaker AI endpoints handle the inference, while custom application logic manages tool execution and result assembly.
SageMaker AI deployment architecture
The Foursquare Spatial Agent deploys on SageMaker AI real-time inference endpoints with configuration optimized for production geospatial workloads. The deployment uses G5 instances such as g5.2xlarge for development and g5.12xlarge for production, providing cost-effective GPU inference for models in the 7B–70B parameter range commonly used for agent reasoning. A target tracking scaling policy based on the InvocationsPerInstance metric maintains response times during variable load while minimizing costs during low-traffic periods. Spatial analyses involving large geographic extents or many datasets join route to asynchronous inference endpoints, allowing queries that can take 60 seconds or more to complete without exceeding typical API timeout limits while maintaining responsive behavior for more straightforward queries.
CloudWatch metrics track inference latency, error rates, and token throughput across the deployment. Custom metrics log reasoning chain depth, number of tool calls per query, and dataset access patterns, enabling continuous optimization of agent performance. This deployment architecture provides production-grade reliability while maintaining flexibility for experimentation with different models and prompting strategies.
Foursquare Spatial Agent in action
The following demonstrations show how organizations across insurance, banking, and urban planning can use this capability to answer complex spatial questions in minutes—collapsing timelines that previously stretched across quarters into interactive workflows accessible to domain experts without specialized technical skills. In insurance risk assessment, the agent predicts which areas in the Los Angeles region are likely to witness increased insurance rates by computing a composite risk score from flood risk, fire hazard severity, crime rates and the FEMA national risk index datasets at different spatial resolutions and formats, now queryable through common H3 cell IDs. An underwriter asks the question in natural language, and the agent handles dataset selection, spatial joins, risk aggregation, and map visualization without requiring GIS expertise.
For banking market analysis, the agent provides a 360-degree view of Los Angeles’s bank network planning. It combines demographic data including population, income, and age distribution with healthcare facility locations, crime statistics, and points of interest to identify under-served markets and expansion opportunities. This analysis informs data-driven decisions for branch placement, product targeting, and financial inclusion initiatives. Previously, assembling these datasets and performing spatial analysis required weeks of GIS specialist time. Now, the agent delivers results in minutes through conversational interaction.
For urban infrastructure planning, the agent helps the city of Chandler, Arizona, plan sustainable urban development over the next decade. It combines population growth projections, housing development patterns, median income trends, and infrastructure data including buildings, power lines, and cell towers—all indexed to H3 cells. Urban planners explore scenarios by asking questions like “which areas will experience population growth but lack adequate infrastructure?” The agent reasons through the analytical requirements, executes appropriate spatial queries, and generates visualizations showing infrastructure gaps that need investment.
The democratization of geospatial intelligence
Foursquare Spatial H3 Hub, reasoning models, and Amazon SageMaker AI together remove the barriers. Organizations can now access standardized geospatial data, deploy reasoning agents with tool-calling capabilities, and run production inference without building specialized infrastructure.
To deploy geospatial AI agents:
Access Foursquare Spatial H3 Hub for analysis-ready datasets.
Deploy reasoning models on Amazon SageMaker AI with SageMaker JumpStart or Hugging Face.
Build agent capabilities that connect models to H3 Hub datasets through tool-calling.
About the authors
Vikram Gundeti currently serves as the Chief Technology Officer (CTO) of Foursquare, where he leads the technical strategy, decision making, and research for the company’s Geospatial Platform. Before joining Foursquare, Vikram held the position of Principal Engineer at Amazon, where he made his mark as a founding engineer on the Amazon Alexa team.
Amit Modi is a Senior Manager of Product Management at Amazon SageMaker AI, where he focuses on ModelOps and Inference. His analysis of enterprise adoption patterns and design of the SageMaker deployment approach described in this post emerged from work with enterprise customers.
Aditya Badhwar is a Senior Solutions Architect at AWS based out of New York. He works with customers providing technical assistance and architectural guidance on various AWS services. Prior to AWS, Aditya worked for over 16 years in software engineering and architecture roles for various large-scale enterprises.