Creative teams and product developers are constantly seeking ways to streamline their workflows and reduce time to market while maintaining quality and brand consistency. This post demonstrates how to use AWS services, particularly Amazon Bedrock, to transform your creative processes through generative AI. You can implement a secure, scalable solution that accelerates your creative workflow, such as managing product launches, creating marketing campaigns, or developing multimedia content.
This post examines how product teams can deploy a generative AI application that enables rapid content iteration across formats. The solution addresses comprehensive needs—from product descriptions and marketing copy to visual concepts and video content for social media. By integrating with brand guidelines and compliance requirements, teams can significantly reduce time to market while maintaining creative quality and consistency.
Solution overview
Consider a product development team at an ecommerce company creating multimedia marketing campaigns for their seasonal product launches. Their traditional workflow has bottlenecks due to lengthy revisions, manual compliance reviews, and complex coordination across creative teams. The team is exploring solutions to rapidly iterate through creative concepts, generate multiple variations of marketing materials.
By using Amazon Bedrock and Amazon Nova models, the team can transform its creative process. Amazon Nova models enable the generation of product descriptions and marketing copy. The team creates concept visuals and product mockups with Amazon Nova Canvas, and uses Amazon Nova Reel to produce engaging video content for social media presence. Amazon Bedrock Guardrails can help the team maintain consistent brand guidelines with configurable safeguards and governance for its generative AI applications at scale.
The team can further enhance its brand consistency with Amazon Bedrock Knowledge Bases, which can serve as a centralized repository for brand style guides, visual identity documentation, and successful campaign materials. This comprehensive knowledge base makes sure generated content is informed by the organization’s historical success and established brand standards. Product specifications, market research, and approved messaging are seamlessly integrated into the creative process, enabling more relevant and effective content generation.
With this solution, the team can simultaneously develop materials for multiple channels while maintaining consistent brand voice across their content. Creative professionals can now focus their energy on strategic decisions rather than repetitive tasks, leading to higher-quality outputs and improved team satisfaction.
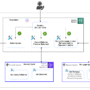
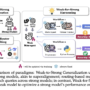
The following sample application creates a scalable environment that streamlines the creative workflow. It helps product teams move seamlessly from initial concept to market-ready materials with automated systems handling compliance and consistency checks throughout the journey.
The solution’s workflow begins with the application engineer’s setup:
Creative assets and brand guidelines are securely stored in encrypted Amazon Simple Storage Service (Amazon S3) buckets. This content is then indexed in Amazon OpenSearch Service to create a comprehensive knowledge base.
Guardrails are configured to enforce brand standards and compliance requirements.
The user experience flows from authentication to content delivery:
Creative team members access the interface through a secure portal hosted in Amazon S3.
Authentication is managed through Amazon Cognito.
Team members’ submitted creative briefs or requirements are routed to Amazon API Gateway.
An AWS Lambda function queries relevant brand guidelines and assets from the knowledge base.
The Lambda function sends the contextual information from the knowledge base to Amazon Bedrock, along with the user’s creative briefs.
The prompt and generated response are filtered through Amazon Bedrock Guardrails.
Amazon Polly converts text into lifelike speech, generating audio streams that can be played immediately and stored in S3 buckets for later use.
The models’ generated content is delivered to the user.
Chat history stored in Amazon DynamoDB.
Prerequisites
The following prerequisites are required before continuing:
An AWS account
An AWS Identity and Access Management (IAM) role with permission to manage AWS Marketplace subscriptions and AWS services
AWS services:
AWS CloudFormation
Amazon API Gateway
AWS CloudFormation
Amazon Cognito
Amazon DynamoDB
Amazon Polly
Amazon S3
Amazon Virtual Private Cloud (Amazon VPC) with two public subnets
Amazon Bedrock models enabled:
Amazon Nova Canvas
Amazon Nova Reels
Amazon Nova Pro
Amazon Nova Lite
Anthropic models (optional):
Anthropic’s Claude 3 Sonnet
Select the Models to Use in Amazon Bedrock
When working with Amazon Bedrock for generative AI applications, one of the first steps is selecting which foundation models you want to access. Amazon Bedrock offers a variety of models from different providers, and you’ll need to explicitly enable the ones we plan to use in this blog.
In the Amazon Bedrock console, find and select Model access from the navigation menu on the left.
Click the Modify model access button to begin selecting your models.
Select the following Amazon models:
Nova Canvas
Nova Premier Cross-region inference Nova Pro
Titan Embeddings G1 – Text
Titan Text Embeddings V2
Select the Anthropic Claude 3.7 Sonnet model.
Choose Next.
Review your selections carefully on the summary page, then choose Submit to confirm your choices.
Set up the CloudFormation template
We use a use a CloudFormation template to deploy all necessary solution resources. Follow these steps to prepare your installation files:
Clone the GitHub repository:
git clone https://github.com/aws-samples/aws-service-catalog-reference-architectures.git
Navigate to the solution directory:
cd aws-service-catalog-reference-architectures/blog_content/bedrock_genai
(Make note of this location as you’ll need it in the following steps)
Sign in to your AWS account with administrator privileges to ensure you can create all required AWS resources.
Create an S3 bucket in the AWS Region where you plan to deploy this solution. Remember the bucket name for later steps.
Upload the entire content folder to your newly created S3 bucket.
Navigate to the content/genairacer/src folder in your S3 bucket.
Copy the URL for the content/genairacer/src/genairacer_setup.json file. You’ll need this URL for the deployment phase.
Deploy the CloudFormation template
Complete the following steps to use the provided CloudFormation template to automatically create and configure the application components within your AWS account:
On the CloudFormation console, choose Stacks in navigation pane.
Choose Create stack and select with new resources (standard).
On the Create stack page, under Specify template, for Object URL, enter the URL copied from the previous step, then choose Next.
On the Specify stack details page, enter a stack name.
Under Parameters, choose Next.
On the Configure stack options page, choose Next.
On the Review page, select the acknowledgement check boxes and choose Submit.
Sign in to the Amazon Bedrock generative AI application
Accessing your newly deployed application is simple and straightforward. Follow these steps to log in for the first time and start exploring the Amazon Bedrock generative AI interface.
On the CloudFormation console, select the stack you deployed and select the Outputs tab.
Find the FrontendURL value and open the provided link.
When the sign-in screen displays, enter the username you specified during the CloudFormation deployment process.
Enter the temporary password that was sent to the email address you provided during setup.
After you sign in, follow the prompts to change your password.
Choose Send to confirm your new credentials.
Once authenticated, you’ll be directed to the main Amazon Bedrock generative AI dashboard, where you can begin exploring all the features and capabilities of your new application.
Using the application
Now that the application has been deployed, you can use it for text, image, and audio management. In the following sections, we explore some sample use cases.
Text generation
The creative team at the ecommerce company wants to draft compelling product descriptions. By inputting the basic product features and desired tone, the LLM generates engaging and persuasive text that highlights the unique selling points of each item, making sure the online store’s product pages are both informative and captivating for potential customers.
To use the text generation feature and perform actions with the supported text models using Amazon Bedrock, follow these steps:
On the AWS CloudFormation console, go to the stack you created.
Choose the Outputs tab.
Choose the link for FrontendURL.
Log in using the credentials sent to the email you provided during the stack deployment process.
On the Text tab, enter your desired prompt in the input field.
Choose the specific model ID you want Amazon Bedrock to use from the available options.
Choose Run.
Repeat this process for any additional prompts you want to process.
Image generation
The creative team can now conceptualize and produce stunning product images. By describing the desired scene, style, and product placement, they can enhance the online shopping experience and increase the likelihood of customer engagement and purchase.To use the image generation feature, follow these steps:
In the UI, choose the Images tab.
Enter your desired text-to-image prompt in the input field.
Choose the specific model ID you want Amazon Bedrock to utilize from the available options.
Optionally, choose the desired style of the image from the provided style options.
Choose Generate Image.
Repeat this process for any additional prompts you want to process.
Audio generation
The ecommerce company’s creative team wants to develop audio content for marketing campaigns. By specifying the message, brand voice, target demographic, and audio components, they can compose scripts and generate voiceovers for promotional videos and audio ads, resulting in consistent and professional audio materials that effectively convey the brand’s message and values.To use the audio generation feature, follow these steps:
In the UI, choose the Audio tab.
Enter your desired prompt in the input field.
Choose Run. An audio file will appear and start to play.
Choose the file (right-click) and choose Save Audio As to save the file.
Amazon Bedrock Knowledge Bases
With Amazon Bedrock Knowledge Bases, you can provide foundation models (FMs) and agents with contextual information from your organization’s private data sources, to deliver more relevant, accurate, and tailored responses. It is a powerful and user-friendly implementation of the Retrieval Augmented Generation (RAG) approach. The application showcased in this post uses the Amazon Bedrock components in the backend, simplifying the process to merely uploading a document using the application’s GUI, and then entering a prompt that will query the documents you upload.
For our example use case, the creative team now needs to research information about internal processes and customer data, which are typically stored in documentation. When this documentation is stored in the knowledge base, they can query it on the KnowledgeBase tab. The queries executed on this tab will search the documents for the specific information they are looking for.
Manage documents
The documents you have uploaded will be listed on the KnowledgeBase tab. To add more, complete the following steps:
In the UI, choose the KnowledgeBase tab.
Choose Manage Document.
Choose Browse, then choose a file.
Choose Upload.
You will see a message confirming that the file was uploaded successfully.The Amazon Bedrock Knowledge Bases syncing process is triggered when the file is uploaded. The application will be ready for queries against the new document within a minute.
Query the knowledge base
To query the knowledge base, complete the following steps:
In the UI, choose the KnowledgeBase tab.
Enter your query in the input field.
For Model, choose the model you want Amazon Bedrock to use for performing the query.
Choose Run.
The generated text response from Amazon Bedrock will appear.
Amazon Bedrock guardrails
You can use the Guardrails tab to manage your guardrails, and create and remove guardrails as needed. Guardrails are used on the Text tab when performing queries.
Create a guardrail
Complete the following steps to create a new guardrail:
In the UI, choose the Guardrails tab.
Enter the required fields or choose the appropriate options.
Choose the type of guardrail under Content Filter Type.
Choose Create Guardrail.
The newly created guardrail will appear in the right pane.
Delete a guardrail
Complete the following steps to delete a guardrail:
In the UI, choose the Guardrails tab.
Choose the guardrail you want to delete in the right pane.
Choose the X icon next to the guardrail.
By following these steps, you can effectively manage your guardrails, for a seamless and controlled experience when performing queries in the Text tab.
Use guardrails
The creative team requires access to information about internal processes and customer data, which are securely stored in documentation within the knowledge base. To enforce compliance with personally identifiable information (PII) guardrails, queries executed using the Text tab are designed to search documents for specific, non-sensitive information while preventing the exposure or inclusion of PII in both prompts and answers. This approach helps the team retrieve necessary data without compromising privacy or security standards.
To use the guardrails feature, complete the following steps:
In the UI, choose the Text tab.
Enter your prompt in the input field.
For Model ID, choose the specific model ID you want Amazon Bedrock to use.
Turn on Guardrails.
For Select Filter, choose the guardrail you want to use.
Choose Run.
The generated text from Amazon Bedrock will appear within a few seconds. Repeat this process for any additional prompts you want to process.
Clean up
To avoid incurring costs, delete resources that are no longer needed. If you no longer need the solution, complete the following steps to delete all resources you created from your AWS account:
On the AWS CloudFormation console, choose Stacks in the navigation pane.
Select the stack you deployed and choose Delete.
Conclusion
By combining Amazon Bedrock, Knowledge Bases, and Guardrails with Cognito, API Gateway, and Lambda, organizations can give employees powerful AI tools for text, image, and data work. This serverless approach integrates generative AI into daily workflows securely and scalably, boosting productivity and innovation across teams..
For more information about generative AI and Amazon Bedrock, refer to the Amazon Bedrock category in the AWS News Blog.
About the authors
Kenneth Walsh is a Senior AI Acceleration Architect based in New York who transforms AWS builder productivity through innovative generative AI automation tools. With a strategic focus on standardized frameworks, Kenneth accelerates partner adoption of generative AI technologies at scale. As a trusted advisor, he guides customers through their GenAI journeys with both technical expertise and genuine passion. Outside the world of artificial intelligence, Kenneth enjoys crafting culinary creations, immersing himself in audiobooks, and cherishing quality time with his family and dog.
Wanjiko Kahara is a New York–based Solutions Architect with a interest area in generative AI. Wanjiko is excited about learning new technology to help her customers be successful. Outside of work, Wanjiko loves to travel, explore the outdoors, and read.
Greg Medard is a Solutions Architect with AWS. Greg guides clients in architecting, designing, and developing cloud-optimized infrastructure solutions. His drive lies in fostering cultural shifts by embracing DevOps principles that overcome organizational hurdles. Beyond work, he cherishes quality time with loved ones, tinkering with the latest tech gadgets, or embarking on adventures to discover new destinations and culinary delights.
Bezuayehu Wate is a Specialist Solutions Architect at AWS, with a focus on big data analytics. Passionate about helping customers design, build, and modernize their cloud-based analytics solutions, she finds joy in learning and exploring new technologies. Outside of work, Bezuayehu enjoys quality time with family and traveling.
Nicole Murray is a generative AI Senior Solutions Architect at AWS, specializing in MLOps and Cloud Operations for AI startups. With 17 years of experience—including helping government agencies design secure, compliant applications on AWS—she now partners with startup founders to build and scale innovative AI/ML solutions. Nicole helps teams navigate secure cloud management, technical strategy, and regulatory best practices in the generative AI space, and is also a passionate speaker and educator known for making complex cloud and AI topics accessible.