In this tutorial, we build an advanced computer-use agent from scratch that can reason, plan, and perform virtual actions using a local open-weight model. We create a miniature simulated desktop, equip it with a tool interface, and design an intelligent agent that can analyze its environment, decide on actions like clicking or typing, and execute them step by step. By the end, we see how the agent interprets goals such as opening emails or taking notes, demonstrating how a local language model can mimic interactive reasoning and task execution. Check out the FULL CODES here.
Copy CodeCopiedUse a different Browser!pip install -q transformers accelerate sentencepiece nest_asyncio
import torch, asyncio, uuid
from transformers import pipeline
import nest_asyncio
nest_asyncio.apply()
We set up our environment by installing essential libraries such as Transformers, Accelerate, and Nest Asyncio, which enable us to run local models and asynchronous tasks seamlessly in Colab. We prepare the runtime so that the upcoming components of our agent can work efficiently without external dependencies. Check out the FULL CODES here.
Copy CodeCopiedUse a different Browserclass LocalLLM:
def __init__(self, model_name=”google/flan-t5-small”, max_new_tokens=128):
self.pipe = pipeline(“text2text-generation”, model=model_name, device=0 if torch.cuda.is_available() else -1)
self.max_new_tokens = max_new_tokens
def generate(self, prompt: str) -> str:
out = self.pipe(prompt, max_new_tokens=self.max_new_tokens, temperature=0.0)[0][“generated_text”]
return out.strip()
class VirtualComputer:
def __init__(self):
self.apps = {“browser”: “https://example.com”, “notes”: “”, “mail”: [“Welcome to CUA”, “Invoice #221”, “Weekly Report”]}
self.focus = “browser”
self.screen = “Browser open at https://example.comnSearch bar focused.”
self.action_log = []
def screenshot(self):
return f”FOCUS:{self.focus}nSCREEN:n{self.screen}nAPPS:{list(self.apps.keys())}”
def click(self, target:str):
if target in self.apps:
self.focus = target
if target==”browser”:
self.screen = f”Browser tab: {self.apps[‘browser’]}nAddress bar focused.”
elif target==”notes”:
self.screen = f”Notes AppnCurrent notes:n{self.apps[‘notes’]}”
elif target==”mail”:
inbox = “n”.join(f”- {s}” for s in self.apps[‘mail’])
self.screen = f”Mail App Inbox:n{inbox}n(Read-only preview)”
else:
self.screen += f”nClicked ‘{target}’.”
self.action_log.append({“type”:”click”,”target”:target})
def type(self, text:str):
if self.focus==”browser”:
self.apps[“browser”] = text
self.screen = f”Browser tab now at {text}nPage headline: Example Domain”
elif self.focus==”notes”:
self.apps[“notes”] += (“n”+text)
self.screen = f”Notes AppnCurrent notes:n{self.apps[‘notes’]}”
else:
self.screen += f”nTyped ‘{text}’ but no editable field.”
self.action_log.append({“type”:”type”,”text”:text})
We define the core components, a lightweight local model, and a virtual computer. We use Flan-T5 as our reasoning engine and create a simulated desktop that can open apps, display screens, and respond to typing and clicking actions. Check out the FULL CODES here.
Copy CodeCopiedUse a different Browserclass ComputerTool:
def __init__(self, computer:VirtualComputer):
self.computer = computer
def run(self, command:str, argument:str=””):
if command==”click”:
self.computer.click(argument)
return {“status”:”completed”,”result”:f”clicked {argument}”}
if command==”type”:
self.computer.type(argument)
return {“status”:”completed”,”result”:f”typed {argument}”}
if command==”screenshot”:
snap = self.computer.screenshot()
return {“status”:”completed”,”result”:snap}
return {“status”:”error”,”result”:f”unknown command {command}”}
We introduce the ComputerTool interface, which acts as the communication bridge between the agent’s reasoning and the virtual desktop. We define high-level operations such as click, type, and screenshot, enabling the agent to interact with the environment in a structured way. Check out the FULL CODES here.
Copy CodeCopiedUse a different Browserclass ComputerAgent:
def __init__(self, llm:LocalLLM, tool:ComputerTool, max_trajectory_budget:float=5.0):
self.llm = llm
self.tool = tool
self.max_trajectory_budget = max_trajectory_budget
async def run(self, messages):
user_goal = messages[-1][“content”]
steps_remaining = int(self.max_trajectory_budget)
output_events = []
total_prompt_tokens = 0
total_completion_tokens = 0
while steps_remaining>0:
screen = self.tool.computer.screenshot()
prompt = (
“You are a computer-use agent.n”
f”User goal: {user_goal}n”
f”Current screen:n{screen}nn”
“Think step-by-step.n”
“Reply with: ACTION <click/type/screenshot> ARG <target or text> THEN <assistant message>.n”
)
thought = self.llm.generate(prompt)
total_prompt_tokens += len(prompt.split())
total_completion_tokens += len(thought.split())
action=”screenshot”; arg=””; assistant_msg=”Working…”
for line in thought.splitlines():
if line.strip().startswith(“ACTION “):
after = line.split(“ACTION “,1)[1]
action = after.split()[0].strip()
if “ARG ” in line:
part = line.split(“ARG “,1)[1]
if ” THEN ” in part:
arg = part.split(” THEN “)[0].strip()
else:
arg = part.strip()
if “THEN ” in line:
assistant_msg = line.split(“THEN “,1)[1].strip()
output_events.append({“summary”:[{“text”:assistant_msg,”type”:”summary_text”}],”type”:”reasoning”})
call_id = “call_”+uuid.uuid4().hex[:16]
tool_res = self.tool.run(action, arg)
output_events.append({“action”:{“type”:action,”text”:arg},”call_id”:call_id,”status”:tool_res[“status”],”type”:”computer_call”})
snap = self.tool.computer.screenshot()
output_events.append({“type”:”computer_call_output”,”call_id”:call_id,”output”:{“type”:”input_image”,”image_url”:snap}})
output_events.append({“type”:”message”,”role”:”assistant”,”content”:[{“type”:”output_text”,”text”:assistant_msg}]})
if “done” in assistant_msg.lower() or “here is” in assistant_msg.lower():
break
steps_remaining -= 1
usage = {“prompt_tokens”: total_prompt_tokens,”completion_tokens”: total_completion_tokens,”total_tokens”: total_prompt_tokens + total_completion_tokens,”response_cost”: 0.0}
yield {“output”: output_events, “usage”: usage}
We construct the ComputerAgent, which serves as the system’s intelligent controller. We program it to reason about goals, decide which actions to take, execute those through the tool interface, and record each interaction as a step in its decision-making process. Check out the FULL CODES here.
Copy CodeCopiedUse a different Browserasync def main_demo():
computer = VirtualComputer()
tool = ComputerTool(computer)
llm = LocalLLM()
agent = ComputerAgent(llm, tool, max_trajectory_budget=4)
messages=[{“role”:”user”,”content”:”Open mail, read inbox subjects, and summarize.”}]
async for result in agent.run(messages):
print(“==== STREAM RESULT ====”)
for event in result[“output”]:
if event[“type”]==”computer_call”:
a = event.get(“action”,{})
print(f”[TOOL CALL] {a.get(‘type’)} -> {a.get(‘text’)} [{event.get(‘status’)}]”)
if event[“type”]==”computer_call_output”:
snap = event[“output”][“image_url”]
print(“SCREEN AFTER ACTION:n”, snap[:400],”…n”)
if event[“type”]==”message”:
print(“ASSISTANT:”, event[“content”][0][“text”], “n”)
print(“USAGE:”, result[“usage”])
loop = asyncio.get_event_loop()
loop.run_until_complete(main_demo())
We bring everything together by running the demo, where the agent interprets a user’s request and performs tasks on the virtual computer. We observe it generating reasoning, executing commands, updating the virtual screen, and achieving its goal in a clear, step-by-step manner.
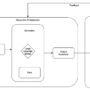
In conclusion, we implemented the essence of a computer-use agent capable of autonomous reasoning and interaction. We witness how local language models like Flan-T5 can powerfully simulate desktop-level automation within a safe, text-based sandbox. This project helps us understand the architecture behind intelligent agents such as those in computer-use agents, bridging natural language reasoning with virtual tool control. It lays a strong foundation for extending these capabilities toward real-world, multimodal, and secure automation systems.
Check out the FULL CODES here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
The post How to Build a Fully Functional Computer-Use Agent that Thinks, Plans, and Executes Virtual Actions Using Local AI Models appeared first on MarkTechPost.