This post was written with Mohamed Hossam of Brightskies.
Research universities engaged in large-scale AI and high-performance computing (HPC) often face significant infrastructure challenges that impede innovation and delay research outcomes. Traditional on-premises HPC clusters come with long GPU procurement cycles, rigid scaling limits, and complex maintenance requirements. These obstacles restrict researchers’ ability to iterate quickly on AI workloads such as natural language processing (NLP), computer vision, and foundation model (FM) training. Amazon SageMaker HyperPod alleviates the undifferentiated heavy lifting involved in building AI models. It helps quickly scale model development tasks such as training, fine-tuning, or inference across a cluster of hundreds or thousands of AI accelerators (NVIDIA GPUs H100, A100, and others) integrated with preconfigured HPC tools and automated scaling.
In this post, we demonstrate how a research university implemented SageMaker HyperPod to accelerate AI research by using dynamic SLURM partitions, fine-grained GPU resource management, budget-aware compute cost tracking, and multi-login node load balancing—all integrated seamlessly into the SageMaker HyperPod environment.
Solution overview
Amazon SageMaker HyperPod is designed to support large-scale machine learning operations for researchers and ML scientists. The service is fully managed by AWS, removing operational overhead while maintaining enterprise-grade security and performance.
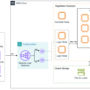
The following architecture diagram illustrates how to access SageMaker HyperPod to submit jobs. End users can use AWS Site-to-Site VPN, AWS Client VPN, or AWS Direct Connect to securely access the SageMaker HyperPod cluster. These connections terminate on the Network Load Balancer that efficiently distributes SSH traffic to login nodes, which are the primary entry points for job submission and cluster interaction. At the core of the architecture is SageMaker HyperPod compute, a controller node that orchestrates cluster operations, and multiple compute nodes arranged in a grid configuration. This setup supports efficient distributed training workloads with high-speed interconnects between nodes, all contained within a private subnet for enhanced security.
The storage infrastructure is built around two main components: Amazon FSx for Lustre provides high-performance file system capabilities, and Amazon S3 for dedicated storage for datasets and checkpoints. This dual-storage approach provides both fast data access for training workloads and secure persistence of valuable training artifacts.
The implementation consisted of several stages. In the following steps, we demonstrate how to deploy and configure the solution.
Prerequisites
Before deploying Amazon SageMaker HyperPod, make sure the following prerequisites are in place:
AWS configuration:
The AWS Command Line Interface (AWS CLI) configured with appropriate permissions
Cluster configuration files prepared: cluster-config.json and provisioning-parameters.json
Network setup:
A virtual private cloud (VPC) configured for cluster resources.
Security groups with Elastic Fabric Adapter (EFA) communication enabled.
An Amazon FSx for Lustre file system for shared, high-performance storage
An AWS Identity and Management (IAM) role with permissions for the following:
Amazon Elastic Compute Cloud (Amazon EC2) instance and Amazon SageMaker cluster management
FSx for Lustre and Amazon Simple Storage Service (Amazon S3) access
Amazon CloudWatch Logs and AWS Systems Manager integration
EFA network configuration
Launch the CloudFormation stack
We launched an AWS CloudFormation stack to provision the necessary infrastructure components, including a VPC and subnet, FSx for Lustre file system, S3 bucket for lifecycle scripts and training data, and IAM roles with scoped permissions for cluster operation. Refer to the Amazon SageMaker HyperPod workshop for CloudFormation templates and automation scripts.
Customize SLURM cluster configuration
To align compute resources with departmental research needs, we created SLURM partitions to reflect the organizational structure, for example NLP, computer vision, and deep learning teams. We used the SLURM partition configuration to define slurm.conf with custom partitions. SLURM accounting was enabled by configuring slurmdbd and linking usage to departmental accounts and supervisors.
To support fractional GPU sharing and efficient utilization, we enabled Generic Resource (GRES) configuration. With GPU stripping, multiple users can access GPUs on the same node without contention. The GRES setup followed the guidelines from the Amazon SageMaker HyperPod workshop.
Provision and validate the cluster
We validated the cluster-config.json and provisioning-parameters.json files using the AWS CLI and a SageMaker HyperPod validation script:
$curl -O https://raw.githubusercontent.com/aws-samples/awsome-distributed-training/main/1.architectures/5.sagemaker-hyperpod/validate-config.py
$pip3 install boto3
$python3 validate-config.py –cluster-config cluster-config.json –provisioning-parameters provisioning-parameters.json
Then we created the cluster:
$aws sagemaker create-cluster
–cli-input-json file://cluster-config.json
–region us-west-2
Implement cost tracking and budget enforcement
To monitor usage and control costs, each SageMaker HyperPod resource (for example, Amazon EC2, FSx for Lustre, and others) was tagged with a unique ClusterName tag. AWS Budgets and AWS Cost Explorer reports were configured to track monthly spending per cluster. Additionally, alerts were set up to notify researchers if they approached their quota or budget thresholds.
This integration helped facilitate efficient utilization and predictable research spending.
Enable load balancing for login nodes
As the number of concurrent users increased, the university adopted a multi-login node architecture. Two login nodes were deployed in EC2 Auto Scaling groups. A Network Load Balancer was configured with target groups to route SSH and Systems Manager traffic. Lastly, AWS Lambda functions enforced session limits per user using Run-As tags with Session Manager, a capability of Systems Manager.
For details about the full implementation, see Implementing login node load balancing in SageMaker HyperPod for enhanced multi-user experience.
Configure federated access and user mapping
To facilitate secure and seamless access for researchers, the institution integrated AWS IAM Identity Center with their on-premises Active Directory (AD) using AWS Directory Service. This allowed for unified control and administration of user identities and access privileges across SageMaker HyperPod accounts. The implementation consisted of the following key components:
Federated user integration – We mapped AD users to POSIX user names using Session Manager run-as tags, allowing fine-grained control over compute node access
Secure session management – We configured Systems Manager to make sure users access compute nodes using their own accounts, not the default ssm-user
Identity-based tagging – Federated user names were automatically mapped to user directories, workloads, and budgets through resource tags
For full step-by-step guidance, refer to the Amazon SageMaker HyperPod workshop.
This approach streamlined user provisioning and access control while maintaining strong alignment with institutional policies and compliance requirements.
Post-deployment optimizations
To help prevent unnecessary consumption of compute resources by idle sessions, the university configured SLURM with Pluggable Authentication Modules (PAM). This setup enforces automatic logout for users after their SLURM jobs are complete or canceled, supporting prompt availability of compute nodes for queued jobs.
The configuration improved job scheduling throughput by freeing idle nodes immediately and reduced administrative overhead in managing inactive sessions.
Additionally, QoS policies were configured to control resource consumption, limit job durations, and enforce fair GPU access across users and departments. For example:
MaxTRESPerUser – Makes sure GPU or CPU usage per user stays within defined limits
MaxWallDurationPerJob – Helps prevent excessively long jobs from monopolizing nodes
Priority weights – Aligns priority scheduling based on research group or project
These enhancements facilitated an optimized, balanced HPC environment that aligns with the shared infrastructure model of academic research institutions.
Clean up
To delete the resources and avoid incurring ongoing charges, complete the following steps:
Delete the SageMaker HyperPod cluster:
$aws sagemaker delete-cluster –cluster-name <name>
Delete the CloudFormation stack used for the SageMaker HyperPod infrastructure:
$aws cloudformation delete-stack –stack-name <stack-name> –region <region>
This will automatically remove associated resources, such as the VPC and subnets, FSx for Lustre file system, S3 bucket, and IAM roles. If you created these resources outside of CloudFormation, you must delete them manually.
Conclusion
SageMaker HyperPod provides research universities with a powerful, fully managed HPC solution tailored for the unique demands of AI workloads. By automating infrastructure provisioning, scaling, and resource optimization, institutions can accelerate innovation while maintaining budget control and operational efficiency. Through customized SLURM configurations, GPU sharing using GRES, federated access, and robust login node balancing, this solution highlights the potential of SageMaker HyperPod to transform research computing, so researchers can focus on science, not infrastructure.
For more details on making the most of SageMaker HyperPod, check out the SageMaker HyperPod workshop and explore further blog posts about SageMaker HyperPod.
About the authors
Tasneem Fathima is Senior Solutions Architect at AWS. She supports Higher Education and Research customers in the United Arab Emirates to adopt cloud technologies, improve their time to science, and innovate on AWS.
Mohamed Hossam is a Senior HPC Cloud Solutions Architect at Brightskies, specializing in high-performance computing (HPC) and AI infrastructure on AWS. He supports universities and research institutions across the Gulf and Middle East in harnessing GPU clusters, accelerating AI adoption, and migrating HPC/AI/ML workloads to the AWS Cloud. In his free time, Mohamed enjoys playing video games.