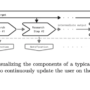
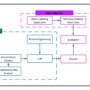
In this tutorial, we are walking through the process of building an advanced MCP (Model Context Protocol) Agent that runs smoothly inside Jupyter or Google Colab. We are designing the system with real-world practicality in mind, focusing on multi-agent coordination, context awareness, memory management, and dynamic tool usage. As we progress, we see how each agent specializes in its own role, whether it’s coordinating, researching, analyzing, or executing, and how together they form a swarm that can handle complex tasks. Check out the FULL CODES here.
Copy CodeCopiedUse a different Browserimport json
import logging
from typing import Dict, List, Any, Optional
from dataclasses import dataclass
from enum import Enum
from datetime import datetime
import time
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
try:
import google.generativeai as genai
GEMINI_AVAILABLE = True
except ImportError:
print(” google-generativeai not installed. Run: pip install google-generativeai”)
GEMINI_AVAILABLE = False
We start by importing essential Python libraries for data handling, logging, and agent structuring, while also setting up logging for better debugging. We then check for the availability of the Gemini API, so we can seamlessly integrate it if it is installed; otherwise, we run in demo mode. Check out the FULL CODES here.
Copy CodeCopiedUse a different Browserclass AgentRole(Enum):
COORDINATOR = “coordinator”
RESEARCHER = “researcher”
ANALYZER = “analyzer”
EXECUTOR = “executor”
@dataclass
class Message:
role: str
content: str
timestamp: datetime
metadata: Dict[str, Any] = None
@dataclass
class AgentContext:
agent_id: str
role: AgentRole
capabilities: List[str]
memory: List[Message]
tools: List[str]
We define the core building blocks of our agent system. We create AgentRole to assign clear responsibilities, use Message to store conversations with context, and build AgentContext to capture each agent’s identity, role, memory, and tools so we can manage interactions effectively. Check out the FULL CODES here.
Copy CodeCopiedUse a different Browserclass MCPAgent:
“””Advanced MCP Agent with evolved capabilities – Jupyter Compatible”””
def __init__(self, agent_id: str, role: AgentRole, api_key: str = None):
self.agent_id = agent_id
self.role = role
self.api_key = api_key
self.memory = []
self.context = AgentContext(
agent_id=agent_id,
role=role,
capabilities=self._init_capabilities(),
memory=[],
tools=self._init_tools()
)
self.model = None
if GEMINI_AVAILABLE and api_key:
try:
genai.configure(api_key=api_key)
self.model = genai.GenerativeModel(‘gemini-pro’)
print(f” Agent {agent_id} initialized with Gemini API”)
except Exception as e:
print(f” Gemini configuration failed: {e}”)
print(” Running in demo mode with simulated responses”)
else:
print(f” Agent {agent_id} running in demo mode”)
def _init_capabilities(self) -> List[str]:
“””Initialize role-specific capabilities”””
capabilities_map = {
AgentRole.COORDINATOR: [“task_decomposition”, “agent_orchestration”, “priority_management”],
AgentRole.RESEARCHER: [“data_gathering”, “web_search”, “information_synthesis”],
AgentRole.ANALYZER: [“pattern_recognition”, “data_analysis”, “insight_generation”],
AgentRole.EXECUTOR: [“action_execution”, “result_validation”, “output_formatting”]
}
return capabilities_map.get(self.role, [])
def _init_tools(self) -> List[str]:
“””Initialize available tools based on role”””
tools_map = {
AgentRole.COORDINATOR: [“task_splitter”, “agent_selector”, “progress_tracker”],
AgentRole.RESEARCHER: [“search_engine”, “data_extractor”, “source_validator”],
AgentRole.ANALYZER: [“statistical_analyzer”, “pattern_detector”, “visualization_tool”],
AgentRole.EXECUTOR: [“code_executor”, “file_handler”, “api_caller”]
}
return tools_map.get(self.role, [])
def process_message(self, message: str, context: Optional[Dict] = None) -> Dict[str, Any]:
“””Process incoming message with context awareness – Synchronous version”””
msg = Message(
role=”user”,
content=message,
timestamp=datetime.now(),
metadata=context
)
self.memory.append(msg)
prompt = self._generate_contextual_prompt(message, context)
try:
if self.model:
response = self._generate_response_gemini(prompt)
else:
response = self._generate_demo_response(message)
response_msg = Message(
role=”assistant”,
content=response,
timestamp=datetime.now(),
metadata={“agent_id”: self.agent_id, “role”: self.role.value}
)
self.memory.append(response_msg)
return {
“agent_id”: self.agent_id,
“role”: self.role.value,
“response”: response,
“capabilities_used”: self._analyze_capabilities_used(message),
“next_actions”: self._suggest_next_actions(response),
“timestamp”: datetime.now().isoformat()
}
except Exception as e:
logger.error(f”Error processing message: {e}”)
return {“error”: str(e)}
def _generate_response_gemini(self, prompt: str) -> str:
“””Generate response using Gemini API – Synchronous”””
try:
response = self.model.generate_content(prompt)
return response.text
except Exception as e:
logger.error(f”Gemini API error: {e}”)
return self._generate_demo_response(prompt)
def _generate_demo_response(self, message: str) -> str:
“””Generate simulated response for demo purposes”””
role_responses = {
AgentRole.COORDINATOR: f”As coordinator, I’ll break down the task: ‘{message[:50]}…’ into manageable components and assign them to specialized agents.”,
AgentRole.RESEARCHER: f”I’ll research information about: ‘{message[:50]}…’ using my data gathering and synthesis capabilities.”,
AgentRole.ANALYZER: f”Analyzing the patterns and insights from: ‘{message[:50]}…’ to provide data-driven recommendations.”,
AgentRole.EXECUTOR: f”I’ll execute the necessary actions for: ‘{message[:50]}…’ and validate the results.”
}
base_response = role_responses.get(self.role, f”Processing: {message[:50]}…”)
time.sleep(0.5)
additional_context = {
AgentRole.COORDINATOR: ” I’ve identified 3 key subtasks and will coordinate their execution across the agent team.”,
AgentRole.RESEARCHER: ” My research indicates several relevant sources and current trends in this area.”,
AgentRole.ANALYZER: ” The data shows interesting correlations and actionable insights for decision making.”,
AgentRole.EXECUTOR: ” I’ve completed the requested actions and verified the outputs meet quality standards.”
}
return base_response + additional_context.get(self.role, “”)
def _generate_contextual_prompt(self, message: str, context: Optional[Dict]) -> str:
“””Generate context-aware prompt based on agent role”””
base_prompt = f”””
You are an advanced AI agent with the role: {self.role.value}
Your capabilities: {‘, ‘.join(self.context.capabilities)}
Available tools: {‘, ‘.join(self.context.tools)}
Recent conversation context:
{self._get_recent_context()}
Current request: {message}
“””
role_instructions = {
AgentRole.COORDINATOR: “””
Focus on breaking down complex tasks, coordinating with other agents,
and maintaining overall project coherence. Consider dependencies and priorities.
Provide clear task decomposition and agent assignments.
“””,
AgentRole.RESEARCHER: “””
Prioritize accurate information gathering, source verification,
and comprehensive data collection. Synthesize findings clearly.
Focus on current trends and reliable sources.
“””,
AgentRole.ANALYZER: “””
Focus on pattern recognition, data interpretation, and insight generation.
Provide evidence-based conclusions and actionable recommendations.
Highlight key correlations and implications.
“””,
AgentRole.EXECUTOR: “””
Concentrate on practical implementation, result validation,
and clear output delivery. Ensure actions are completed effectively.
Focus on quality and completeness of execution.
“””
}
return base_prompt + role_instructions.get(self.role, “”)
def _get_recent_context(self, limit: int = 3) -> str:
“””Get recent conversation context”””
if not self.memory:
return “No previous context”
recent = self.memory[-limit:]
context_str = “”
for msg in recent:
context_str += f”{msg.role}: {msg.content[:100]}…n”
return context_str
def _analyze_capabilities_used(self, message: str) -> List[str]:
“””Analyze which capabilities were likely used”””
used_capabilities = []
message_lower = message.lower()
capability_keywords = {
“task_decomposition”: [“break down”, “divide”, “split”, “decompose”],
“data_gathering”: [“research”, “find”, “collect”, “gather”],
“pattern_recognition”: [“analyze”, “pattern”, “trend”, “correlation”],
“action_execution”: [“execute”, “run”, “implement”, “perform”],
“agent_orchestration”: [“coordinate”, “manage”, “organize”, “assign”],
“information_synthesis”: [“synthesize”, “combine”, “merge”, “integrate”]
}
for capability, keywords in capability_keywords.items():
if capability in self.context.capabilities:
if any(keyword in message_lower for keyword in keywords):
used_capabilities.append(capability)
return used_capabilities
def _suggest_next_actions(self, response: str) -> List[str]:
“””Suggest logical next actions based on response”””
suggestions = []
response_lower = response.lower()
if “need more information” in response_lower or “research” in response_lower:
suggestions.append(“delegate_to_researcher”)
if “analyze” in response_lower or “pattern” in response_lower:
suggestions.append(“delegate_to_analyzer”)
if “implement” in response_lower or “execute” in response_lower:
suggestions.append(“delegate_to_executor”)
if “coordinate” in response_lower or “manage” in response_lower:
suggestions.append(“initiate_multi_agent_collaboration”)
if “subtask” in response_lower or “break down” in response_lower:
suggestions.append(“task_decomposition_required”)
return suggestions if suggestions else [“continue_conversation”]
We implement the MCPAgent as a notebook-friendly, role-aware agent that initializes capabilities and tools based on its assigned role, keeps a memory of messages, and generates context-aware responses. We seamlessly use Gemini when available (falling back to a demo response otherwise) and wrap everything with structured outputs like capabilities used and suggested next actions. We also provide utilities to craft role-specific prompts, surface recent context, detect implied capabilities, and propose the next step in a multi-agent workflow. Check out the FULL CODES here.
Copy CodeCopiedUse a different Browserclass MCPAgentSwarm:
“””Multi-agent coordination system – Jupyter Compatible”””
def __init__(self, api_key: str = None):
self.api_key = api_key
self.agents = {}
self.task_history = []
self.results = {}
def create_agent(self, agent_id: str, role: AgentRole) -> MCPAgent:
“””Create and register a new agent”””
agent = MCPAgent(agent_id, role, self.api_key)
self.agents[agent_id] = agent
print(f” Created agent: {agent_id} with role: {role.value}”)
return agent
def coordinate_task(self, task: str) -> Dict[str, Any]:
“””Coordinate complex task across multiple agents – Synchronous”””
print(f”n Coordinating task: {task}”)
print(“=” * 60)
if “coordinator” not in self.agents:
self.create_agent(“coordinator”, AgentRole.COORDINATOR)
coordinator = self.agents[“coordinator”]
print(“n Step 1: Task Decomposition”)
decomposition = coordinator.process_message(
f”Decompose this complex task into subtasks and identify which specialized agents are needed: {task}”
)
print(f”Coordinator: {decomposition[‘response’]}”)
self._ensure_required_agents()
print(“n Step 2: Agent Collaboration”)
results = {}
for agent_id, agent in self.agents.items():
if agent_id != “coordinator”:
print(f”n {agent_id.upper()} working…”)
result = agent.process_message(
f”Handle your specialized part of this task: {task}n”
f”Coordinator’s guidance: {decomposition[‘response’][:200]}…”
)
results[agent_id] = result
print(f” {agent_id}: {result[‘response’][:150]}…”)
print(“n Step 3: Final Synthesis”)
final_result = coordinator.process_message(
f”Synthesize these agent results into a comprehensive final output for the task ‘{task}’:n”
f”Results summary: {[f'{k}: {v[‘response’][:100]}…’ for k, v in results.items()]}”
)
print(f”Final Result: {final_result[‘response’]}”)
task_record = {
“task”: task,
“timestamp”: datetime.now().isoformat(),
“decomposition”: decomposition,
“agent_results”: results,
“final_synthesis”: final_result,
“agents_involved”: list(self.agents.keys())
}
self.task_history.append(task_record)
return task_record
def _ensure_required_agents(self):
“””Ensure all required agent types exist”””
required_roles = [AgentRole.RESEARCHER, AgentRole.ANALYZER, AgentRole.EXECUTOR]
for role in required_roles:
agent_id = role.value
if agent_id not in self.agents:
self.create_agent(agent_id, role)
def get_swarm_status(self) -> Dict[str, Any]:
“””Get current status of the agent swarm”””
return {
“total_agents”: len(self.agents),
“agent_roles”: {aid: agent.role.value for aid, agent in self.agents.items()},
“tasks_completed”: len(self.task_history),
“last_task”: self.task_history[-1][“task”] if self.task_history else “None”
}
We manage a swarm of role-specific agents, create them on demand, and coordinate complex tasks through decomposition, collaboration, and final synthesis. We track results and history, ensure required agents exist, and provide a quick status view of the whole system at any time. Check out the FULL CODES here.
Copy CodeCopiedUse a different Browserdef demo_notebook_compatible():
“””Demonstrate advanced MCP agent capabilities – Notebook Compatible”””
print(” Starting Advanced MCP Agent Tutorial”)
print(” Jupyter/Colab Compatible Version”)
print(“=” * 60)
API_KEY = None # Set to your actual key
if not API_KEY:
print(” Running in DEMO MODE (simulated responses)”)
print(” Set API_KEY variable for real Gemini AI responses”)
print(“-” * 60)
swarm = MCPAgentSwarm(API_KEY)
print(“n Demo 1: Single Agent Interaction”)
researcher = swarm.create_agent(“research_agent”, AgentRole.RESEARCHER)
result = researcher.process_message(
“Research the latest trends in AI agent architectures and multi-agent systems”
)
print(f”n Researcher Response:”)
print(f” {result[‘response’]}”)
print(f” Capabilities Used: {result[‘capabilities_used’]}”)
print(f” Suggested Next Actions: {result[‘next_actions’]}”)
print(“nn Demo 2: Multi-Agent Coordination”)
complex_task = “””
Analyze the impact of AI agents on software development productivity.
Include research on current tools, performance metrics, future predictions,
and provide actionable recommendations for development teams.
“””
coordination_result = swarm.coordinate_task(complex_task)
print(“nn Demo 3: Swarm Status”)
status = swarm.get_swarm_status()
print(f” Total Agents: {status[‘total_agents’]}”)
print(f” Agent Roles: {status[‘agent_roles’]}”)
print(f” Tasks Completed: {status[‘tasks_completed’]}”)
print(“n Tutorial Completed Successfully!”)
return swarm
def run_demo():
“””Simple function to run the demo”””
return demo_notebook_compatible()
if __name__ == “__main__”:
print(” Running MCP Agent Demo…”)
swarm = run_demo()
else:
print(” MCP Agent Tutorial loaded!”)
print(” Run: swarm = run_demo() to start the demonstration”)
We wrap everything into a notebook-friendly demo that showcases the MCP agent system in action. We start by creating a researcher agent for single-agent interaction, then demonstrate multi-agent collaboration on a complex task, and finally check swarm status. We also ensure the code runs smoothly in both script mode and Jupyter/Colab mode, with a clear fallback to demo responses when no Gemini API key is set.
In conclusion, we have successfully demonstrated how our MCP agents can coordinate, decompose tasks, and synthesize results into actionable insights, all within a notebook-friendly, synchronous setup. We have seen how memory enables continuity of context, how role-based specialization ensures efficiency, and how the swarm can adapt to various challenges. With Gemini integration available for real AI responses and a fallback demo mode for simulation, we are leaving with a working foundation for advanced multi-agent systems.
Check out the FULL CODES here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.
The post Building Advanced MCP (Model Context Protocol) Agents with Multi-Agent Coordination, Context Awareness, and Gemini Integration appeared first on MarkTechPost.