The education sector needs efficient, high-quality course material development that can keep pace with rapidly evolving knowledge domains. Faculty invest days to create content and quizzes for topics to be taught in weeks. Increased faculty engagement in manual content creation creates a time deficit for innovation in teaching, inconsistent course material, and a poor experience for both faculty and students.
Generative AI–powered systems can significantly reduce the time and effort faculty spend on course material development while improving educational quality. Automating content creation tasks gives educators more time for interactive teaching and creative classroom strategies.
The solution in this post addresses this challenge by using large language models (LLMs), specifically Anthropic’s Claude 3.5 through Amazon Bedrock, for educational content creation. This AI-powered approach supports the automated generation of structured course outlines and detailed content, reducing development cycles from days to hours while ensuring materials remain current and comprehensive. This technical exploration demonstrates how institutions can use advanced AI capabilities to transform their educational content development process, making it more efficient, scalable, and responsive to modern learning needs.
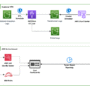
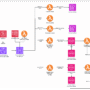
The solution uses Amazon Simple Queue Service (Amazon SQS), AWS Lambda, Amazon Bedrock, Amazon API Gateway WebSocket APIs, Amazon Simple Storage Service (Amazon S3), Amazon CloudFront, Amazon DynamoDB, Amazon Cognito and AWS WAF. The architecture is designed following the AWS Well-Architected Framework, facilitating robustness, scalability, cost-optimization, high performance, and enhanced security.
In this post, we explore each component in detail, along with the technical implementation of the two core modules: course outline generation and course content generation. Course outline generates course structure for a subject with module and submodules by week. Primary and secondary outcomes are generated in a hierarchical structure by week and by semester. Content generation is content generated for the module and submodule generated in content outline. Content generated includes text and video scripts with corresponding multiple-choice questions.
Solution overview
The solution architecture integrates the two core modules through WebSocket APIs. This design is underpinned by using AWS Lambda function for serverless compute, Amazon Bedrock for AI model integration, and Amazon SQS for reliable message queuing.
The system’s security uses multilayered approach, combining Amazon Cognito for user authentication, AWS WAF for threat mitigation, and a Lambda authorizers function for fine-grained access control. To optimize performance and enhance user experience, AWS WAF is deployed to filter out malicious traffic and help protect against common web vulnerabilities. Furthermore, Amazon CloudFront is implemented as a WebSocket distribution layer, to significantly improve content delivery speeds and reduce latency for end users. This comprehensive architecture creates a secure, scalable, and high-performance system for generating and delivering educational content.
WebSocket API and authentication mechanisms
Course WebSocket API manages real-time interactions for course outline and content generation. WebSockets enable streaming AI responses and real-time interactions, reducing latency and improving user responsiveness compared to traditional REST APIs. They also support scalable concurrency, allowing parallel processing of multiple requests without overwhelming system resources. AWS WAF provides rule-based filtering to help protect against web-based threats before traffic reaches API Gateway. Amazon CloudFront enhances performance and security by distributing WebSocket traffic globally. Amazon Cognito and JWT Lambda authorizer function handles authentication, validation of user identity before allowing access.
Each WebSocket implements three primary routes:
$connect – Triggers a Lambda function to log the connection_id in DynamoDB. This enables tracking of active connections, targeted messaging, and efficient connection management, supporting real-time communication and scalability across multiple server instances.
$disconnect – Logs the disconnection in DynamoDB to remove the connection_id record from DynamoDB table. This facilitates proper cleanup of inactive connections, helps prevent resource waste, maintains an accurate list of active clients, and helps optimize system performance and resource allocation.
$default – Handles unexpected or invalid traffic.
WebSocket authentication using Amazon Cognito
The WebSocket API integrates Amazon Cognito for authentication and uses a JWT-based Lambda authorizer function for token validation. The authentication flow follows these steps:
User authentication
The course designer signs in using Amazon Cognito, which issues a JWT access token upon successful authentication.
Amazon Cognito supports multiple authentication methods, including username-password login, social identity providers (such as Google or Facebook), and SAML-based federation.
WebSocket connection request
When a user attempts to connect to the WebSocket API, the client includes the JWT access token in the WebSocket request headers.
JWT token validation (Lambda authorizer function)
The JWT token authorizer Lambda function extracts and verifies the token against the Amazon Cognito public key.
If the token is valid, the request proceeds. If the token isn’t valid, the connection is rejected.
Maintaining user sessions
Upon successful authentication, the $connect route Lambda function stores the connection_id and user details in DynamoDB, allowing targeted messaging.
When the user disconnects, the $disconnect Lambda function removes the connection_id to maintain an accurate session record.
The following is a sample AWS CDK code to set up the WebSocket API with Amazon Cognito. AWS CDK is an open source software development framework to define cloud infrastructure in code and provision it through AWS CloudFormation. The following code is written in Python. For more information, refer to Working with the AWS CDK in Python:
from aws_cdk import (
aws_apigatewayv2 as apigwv2,
aws_lambda as _lambda,
aws_lambda_python_alpha as _alambda,
aws_cognito as cognito,
aws_dynamodb as dynamodb,
aws_apigatewayv2_integrations as integrationsv2,
aws_apigatewayv2_authorizers as authorizersv2,
)
class CourseStack(Stack):
def __init__(self, scope: core.Construct, id: str, **kwargs) -> None:
super().__init__(scope, id, **kwargs)
….
# Previous code …
….
# DynamoDB table to track connections
course_connections_ddb_table = dynamodb.Table(self, “CourseConnectionsTable”,
partition_key=dynamodb.Attribute(name=”connectionId”, type=dynamodb.AttributeType.STRING),
time_to_live_attribute=”ttl”,
billing_mode=dynamodb.BillingMode.PAY_PER_REQUEST,
encryption=dynamodb.TableEncryption.AWS_MANAGED,
point_in_time_recovery=True,
removal_policy=RemovalPolicy.DESTROY
)
# Create userpool for Amazon Cognito
user_pool = cognito.UserPool(
self, “CourseUserPool”,
user_pool_name=”CourseUserPool”,
self_sign_up_enabled=True,
account_recovery=cognito.AccountRecovery.EMAIL_ONLY,
user_verification=cognito.UserVerificationConfig(
email_subject=”Verify your email for outline and content generation App”,
email_body=”Hello {username}, Thanks for signing up to Course outline and content generation App! Your verification code is {####}”,
email_style=cognito.VerificationEmailStyle.CODE,
),
standard_attributes={“fullname”: cognito.StandardAttribute(required=True, mutable=True)},
removal_policy=RemovalPolicy.DESTROY,
)
# Create a new Amazon Cognito User Pool Client
user_pool_client = user_pool.add_client(“CourseUserPoolAppClient”,
user_pool_client_name=”CourseUserPoolAppClient”,
id_token_validity=Duration.days(1),
access_token_validity=Duration.days(1),
auth_flows=cognito.AuthFlow(user_password=True)
)
# WebSocket Connect, disconnect, default Lambda functions
course_ws_connect_lambda = _lambda.Function(
self, “CourseWSConnect”,
code=_lambda.Code.from_asset(“./lambda/connect”),
runtime=_lambda.Runtime.PYTHON_3_12,
handler=”index.lambda_handler”,
timeout=Duration.seconds(30),
environment={“CONNECTIONS_TABLE”: course_connections_ddb_table.table_name},
)
course_connections_ddb_table.grant_read_write_data(course_ws_connect_lambda)
course_ws_disconnect_lambda = _lambda.Function(…)
course_ws_default_lambda = _lambda.Function(…)
jwt_auth_course_lambda = _lambda.Function(…)
course_outline_ws_lambda = _lambda.Function(…)
course_content_ws_lambda = _lambda.Function(…)
# Course Web Socket API
course_ws_authorizer = authorizersv2.WebSocketLambdaAuthorizer(“CourseWSAuthorizer”, jwt_auth_course_lambda, identity_source=[“route.request.header.Authorization”,]) # “route.request.querystring.Authorization”,
course_ws_connect_integration = integrationsv2.WebSocketLambdaIntegration(“CourseWSConnectIntegration”, course_ws_connect_lambda)
course_ws_disconnect_integration = integrationsv2.WebSocketLambdaIntegration(“CourseWSDisconnectIntegration”, course_ws_disconnect_lambda)
course_ws_default_integration = integrationsv2.WebSocketLambdaIntegration(“CourseWSDefaultIntegration”, course_ws_default_lambda)
course_outline_ws_integration = integrationsv2.WebSocketLambdaIntegration(“CourseOutlineIntegration”, course_outline_ws_lambda)
course_content_ws_integration = integrationsv2.WebSocketLambdaIntegration(“CourseContentIntegration”, course_content_ws_lambda)
course_ws_api=apigwv2.WebSocketApi(self, “CourseWSApi”,
api_name=”CourseWSApi”,
description=”WebSocket API for Course Outline and Content Generation”,
connect_route_options=apigwv2.WebSocketRouteOptions(
integration=course_ws_connect_integration,
authorizer=course_ws_authorizer
),
disconnect_route_options=apigwv2.WebSocketRouteOptions(
integration=course_ws_disconnect_integration,
),
default_route_options=apigwv2.WebSocketRouteOptions(
integration=course_ws_default_integration,
)
)
# Add a custom message route, to generate course outline
course_ws_api.add_route(“courseOutline”, integration=course_outline_ws_integration)
# Add a custom message route, to generate course content
course_ws_api.add_route(“courseContent”, integration=course_content_ws_integration)
# Create a WebSocket API stage (usually, “dev” or “prod”)
course_ws_stage = apigwv2.WebSocketStage(
self, “CourseWSApiStage”,
web_socket_api=course_ws_api,
stage_name=”dev”, # Change this based on the environment (e.g., “prod”)
auto_deploy=True,
)
# Grant permissions for Lambda to manage the WebSocket connection (for sending messages back to clients)
course_ws_api.grant_manage_connections(course_ws_connect_lambda)
course_ws_api.grant_manage_connections(course_ws_disconnect_lambda)
course_ws_api.grant_manage_connections(course_ws_default_lambda)
course_ws_api.grant_manage_connections(course_outline_ws_lambda)
course_ws_api.grant_manage_connections(course_content_ws_lambda)
Course outline generation
The course outline generation module helps course designers create a structured course outline. For this proof of concept, the default structure spans 4 weeks, with each week containing three main learning outcomes and supporting secondary outcomes, but it can be changed according to each course or institution’s reality. The module follows this workflow:
The course designer submits a prompt using the course WebSocket (courseOutline route).
CourseOutlineWSLambda sends the request to an SQS queue for asynchronous processing.
The SQS queue triggers CourseOutlineLLMLambda, which invokes Anthropic’s Claude 3.5 Sonnet in Amazon Bedrock to generate the outline.
The response is structured using Pydantic models and returned as JSON.
The structured outline is stored in an S3 OutputBucket, with a finalized version stored in a portal bucket for faculty review.
The following code sample is a sample payload for the courseOutline route, which can be customized to meet institutional requirements. The fields are defined as follows:
action – Specifies the operation to be performed (courseOutline).
is_streaming – Indicates whether the response should be streamed (yes for real-time streaming and no for single output at one time).
s3_input_uri_list – A list of S3 URIs containing reference materials (which can be left empty if not available).
course_title – The title of the course for which the outline is being generated.
course_duration – The total number of weeks for the course.
user_prompt – A structured prompt guiding the AI to generate a detailed course outline based on syllabus information, providing a well-organized weekly learning structure. If using a different LLM, optimize the user_prompt for that model to achieve the best results.
{
“action”: “courseOutline”,
“is_streaming”: “yes”,
“s3_input_uri_list”: [],
“course_title”: “Fundamental of Machine Learning”,
“course_duration”: 2,
“user_prompt”: “I need help developing a {course_duration}-week course content for a {course_title} course. Please use the following syllabus to:nn1. If provided, refer to the syllabus text from <syllabus> tags to extract the course learning outcomes.n2. Design each week to focus on 3 main learning outcomes.n3. For each main learning outcome, provide 3 supporting sub-learning outcomes.nn<syllabus>nn{syllabus_text}nn</syllabus>nnEnsure that each week has 3 main learning outcomes and each of those has 3 supporting sub-learning outcomes.”
}
When interacting with the courseOutline route of the WebSocket API, the response follows a structured format that details the course outline and structure. The following is an example of a WebSocket response for a course. This format is designed for straightforward parsing and seamless integration into your applications:
{
“course_title”: “Sample Course”,
“course_duration”: “4”,
“weekly_outline”: [
{
“week”: 1,
“main_outcomes”: [
{
“outcome”: “Learning Outcome 1”,
“sub_outcomes”: [“Sub-outcome 1”, “Sub-outcome 2”, “Sub-outcome 3”]
},
{… similar for Learning outcome 2},
{… similar for Learning outcome 3}
]
},
{… similar for week 2},
{… similar for week 3},
{… similar for week 4},
]
}
Here’s a snippet of the Lambda function for processing the outline request:
event = json.loads(event[‘Records’][0][‘body’])
route_key = event[‘requestContext’][‘routeKey’]
connection_id = event[‘requestContext’][‘connectionId’]
body = json.loads(event[“body”])
s3_input_uri_list = body[“s3_input_uri_list”]
user_prompt = body[“user_prompt”]
course_title = body[“course_title”]
course_duration = body[“course_duration”]
model_id = os.getenv(“MODEL_ID”, “”)
is_streaming = body[“is_streaming”]
websocket_endpoint_url = os.getenv(“WEBSOCKET_ENDPOINT_URL”,””)
output_bucket = os.getenv(“OUTPUT_BUCKET”, “”)
# Send message to api that message received
apigatewaymanagementapi_client = boto3.client(‘apigatewaymanagementapi’, endpoint_url=websocket_endpoint_url)
# Read the syllabus text from uploaded doc
syllabus_text = “”
for s3_input_uri in s3_input_uri_list:
bucket, key = get_s3_bucket_and_key(s3_input_uri)
if key.endswith(‘.pdf’):
pdf_text = extract_text_from_pdf(bucket, key)
syllabus_text = syllabus_text + pdf_text
# Initialize the Pydantic model
pydantic_classes = [CourseOutline]
course_outline = {}
system_prompt = f”””You are an AI assistant tasked with helping an instructor develop a course outline for a {course_title} course.
You have expertise in curriculum design. Your role is to analyze the provided syllabus, extract learning outcomes,
and structure a {course_duration}-week course with specific learning objectives for each week.
Format your response in valid JSON for easy parsing and integration.
Respond only with the requested content, without any preamble or explanation.”””
user_msg_prompt = PromptTemplate.from_template(user_prompt)
user_msg = user_msg_prompt.format(course_title=course_title, course_duration=course_duration, syllabus_text=syllabus_text)
messages = [{“role”: “user”,”content”: [{“text”: user_msg}]}]
tools = []
for class_ in pydantic_classes:
tools.append(convert_pydantic_to_bedrock_converse_function(class_))
tool_config = { “tools”: tools }
inference_config = {“temperature”: 0.5 }
converse_response = bedrock_runtime_client.converse(
system=[{ “text”: system_prompt}],
modelId=model_id,
messages=messages,
inferenceConfig=inference_config,
toolConfig=tool_config,
)
# Parse the LLM response into JSON format
course_outline = parse_bedrock_tool_response(converse_response)
send_message_to_ws_client(apigatewaymanagementapi_client, connection_id, response=course_outline)
return {‘statusCode’: 200,
‘body’: json.dumps({‘course_outline’: course_outline})
}
Course content generation
The course content generation module creates detailed week-by-week content based on the course outline. Although the default configuration generates the following for each main learning outcome, these outputs are fully customizable to meet specific course needs and institutional preferences:
One set of reading materials
Three video scripts (3 minutes each)
A quiz with a multiple-choice question for each video
The module follows this workflow:
The course designer submits learning outcomes using the courseContent route.
CourseContentWSLambda function sends the request to an SQS queue.
The SQS queue triggers CourseContentLLMLambda function, which calls Amazon Bedrock to generate the content.
The generated content is structured and stored in Amazon S3.
The following is a sample payload for the courseContent route, which can be customized to align with institutional requirements. The fields are defined as follows:
action – Specifies the operation to be performed (courseContent).
is_streaming – Determines the response mode (yes for real-time streaming and no for a single output at one time).
s3_input_uri_list – An array of S3 URIs containing additional course materials which will be used to generate course content (optional).
week_number – Indicates the week number for which content is being generated.
course_title – The title of the course.
main_learning_outcome – The primary learning objective for the specified week.
sub_learning_outcome_list – A list of supporting learning outcomes to be covered.
user_prompt – A structured instruction guiding the LLM to generate week-specific course content, facilitating comprehensive coverage. If switching to a different LLM, optimize the user_prompt for optimal performance.
{
“action”:”courseContent”,
“is_streaming”: “yes”,
“s3_input_uri_list”: [“s3://coursestack-inputbucket3bf8630a-v0xovtepdtey/dinesh_testing_folder/Fundamentals Of Machine Learning/Machine Learning Basics.pdf”],
“week_number”:1,
“course_title”: “Fundamental of Machine Learning”,
“main_learning_outcome” : “Understand the basics of machine learning and its applications”,
“sub_learning_outcome_list” : [
“Define machine learning and its relationship to artificial intelligence”,
“Identify real-world applications of machine learning”,
“Distinguish between supervised, unsupervised, and reinforcement learning”
],
“user_prompt”:”For the course {course_title}, ngenerate Week {week_number} content for the main learning outcome:n{main_learning_outcome}nnInclude the following sub-learning outcomes:n{sub_learning_outcome_list}nnFor each sub-learning outcome, provide:n- 3 video scripts, each 3 minutes longn- 1 set of reading materials, atleast one page longn- 1 multiple-choice question per video with correct answernnIf provided, refer to the information within the <additional_context> tags for any supplementary details or guidelines.nn<additional_context>n{additional_context}n</additional_context>nnGenerate the content without any introductory text or explanations.”
}
When interacting with the courseContent route of the WebSocket API, the response follows a structured format that details the course content. The following is an example of a WebSocket response for a course content. This format is designed for easy parsing and seamless integration into your applications:
{
“CourseContent”:{
“week_number”:1,
“main_learning_outcome”:”Learning Outcome 1″,
“reading_material”:{
“title”:”xxx title of the reading material”,
“content”:”xxx reading material content”
},
“sub_learning_outcomes_content”:[
{
“sub_learning_outcome”:”Sub-outcome 1″,
“video_script”:{
“script”:”xxx video script”
},
“multiple_choice_question”:{
“question”:”xxx MCQ question”,
“options”:[“option 1″,”option 2″,”option 3″,”option 4”],
“correct_answer”:”option 1″
}
},
{… similar for sub_learning_outcome 2},
{… similar for sub_learning_outcome 3},
]
}
}
Here’s a Lambda function code snippet for content generation:
event = json.loads(event[‘Records’][0][‘body’])
connection_id = event[‘requestContext’][‘connectionId’]
body = json.loads(event[“body”])
s3_input_uri_list = body[“s3_input_uri_list”]
user_prompt = body[“user_prompt”]
week_number = body[“week_number”]
course_title = body[“course_title”]
main_learning_outcome = body[“main_learning_outcome”]
sub_learning_outcome_list = body[“sub_learning_outcome_list”]
is_streaming = body[“is_streaming”]
model_id = os.getenv(“MODEL_ID”,””)
websocket_endpoint_url = os.environ[“WEBSOCKET_ENDPOINT_URL”]
output_bucket = os.environ[“OUTPUT_BUCKET”]
# Send message to api that message received
apigatewaymanagementapi_client = boto3.client(‘apigatewaymanagementapi’, endpoint_url=websocket_endpoint_url)
# Read the additional_context text from uploaded doc
additional_context = “”
for s3_input_uri in s3_input_uri_list:
bucket, key = get_s3_bucket_and_key(s3_input_uri)
if key.endswith(‘.pdf’):
pdf_text = extract_text_from_pdf(bucket, key)
additional_context = additional_context + pdf_text
# Initialize the Pydantic model
pydantic_classes = [CourseContent]
course_content={}
system_prompt =f”””You are an AI assistant specialized in educational content creation.
Your task is to generate course materials based on given learning outcomes.
Produce concise, accurate, and engaging content suitable for college-level courses.
You may refer to additional context provided within <additional_context> tags if present.
Format your response in valid JSON for easy parsing and integration.
Respond only with the requested content, without any preamble or explanation.”””
user_msg_prompt = PromptTemplate.from_template(user_prompt)
user_msg = user_msg_prompt.format(course_title=course_title,
week_number=week_number,
main_learning_outcome=main_learning_outcome,
sub_learning_outcome_list=sub_learning_outcome_list,
additional_context=additional_context)
messages = [{“role”: “user”,”content”: [{“text”: user_msg}]}]
tools = []
for class_ in pydantic_classes:
tools.append(convert_pydantic_to_bedrock_converse_function(class_))
tool_config = { “tools”: tools }
converse_response = bedrock_runtime_client.converse(
system=[{ “text”: system_prompt}],
modelId=model_id,
messages=messages,
toolConfig=tool_config,
)
# Parse the LLM response into JSON format
course_content = parse_bedrock_tool_response(converse_response)
send_message_to_ws_client(apigatewaymanagementapi_client, connection_id, response=course_content)
return {‘statusCode’: 200,
‘body’: json.dumps({‘course_content’: json.dumps(course_content)})
}
Prerequisites
To implement the solution provided in this post, you should have the following:
An active AWS account and familiarity with foundation models (FMs) and Amazon Bedrock. Enable model access for Anthropic’s Claude 3.5v2 Sonnet and Anthropic’s Claude 3.5 Haiku
The AWS Cloud Development Kit (AWS CDK) already set up. For installation instructions, refer to the AWS CDK workshop.
When deploying the CDK stack, select a Region where Anthropic’s Claude models in Amazon Bedrock are available. Although this solution uses the US West (Oregon) us-west-2 Region, you can choose a different Region but you need to verify that it supports Anthropic’s Claude models in Amazon Bedrock before proceeding. The Region you use to access the model must match the Region where you deploy your stack.
Set up the solution
When the prerequisite steps are complete, you’re ready to set up the solution:
Clone the repository:
git clone https://github.com/aws-samples/educational-course-content-generator-with-qna-bot-using-bedrock.git
Navigate to the project directory:
cd educational-course-content-generator-with-qna-bot-using-bedrock/
Create and activate the virtual environment:
python3 -m venv .venv
source .venv/bin/activate
The activation of the virtual environment differs based on the operating system; refer to the AWS CDK workshop for activating in other environments.
After the virtual environment is activated, you can install the required dependencies:
pip install -r requirements.txt
Review and modify the project_config.json file to customize your deployment settings
In your terminal, export your AWS credentials for a role or user in ACCOUNT_ID. The role needs to have all necessary permissions for CDK deployment:
export AWS_REGION=”<region>” # Same region as ACCOUNT_REGION above export AWS_ACCESS_KEY_ID=”<access-key>” # Set to the access key of your role/user export AWS_SECRET_ACCESS_KEY=”<secret-key>” # Set to the secret key of your role/user
If you’re deploying the AWS CDK for the first time, invoke the following command:
cdk bootstrap
Deploy the stacks:
cdk deploy –all
Note the CloudFront endpoints, WebSocket API endpoints, and Amazon Cognito user pool details from deployment outputs.
Create a user in the Amazon Cognito user pool using the AWS Management Console or AWS Command Line Interface (AWS CLI). Alternatively, you can use the cognito-user-token-helper repository to quickly create a new Amazon Cognito user and generate JSON Web Tokens (JWTs) for testing.
Connect to the WebSocket endpoint using wscat.
wscat -c wss://xxxxxxxxxx.execute-api.us-west-2.amazonaws.com/dev
-H “Authorization: Bearer YOUR_JWT_TOKEN”
Scalability and security considerations
The solution is designed with scalability and security as core principles. Because Amazon API Gateway for WebSockets doesn’t inherently support AWS WAF, we’ve integrated Amazon CloudFront as a distribution layer and applied AWS WAF to enhance security.
By using Amazon SQS and AWS Lambda, the system enables asynchronous processing, supports high concurrency, and dynamically scales to handle varying workloads. AWS WAF helps to protects against malicious traffic and common web-based threats. Amazon CloudFront can improve global performance, reduce latency, and provide built-in DDoS protection. Amazon Cognito handles authentication so that only authorized users can access the WebSocket API. AWS IAM policies enforce strict access control to secure resources such as Amazon Bedrock, Amazon S3, AWS Lambda, and Amazon DynamoDB.
Clean up
To avoid incurring future charges on the AWS account, invoke the following command in the terminal to delete the CloudFormation stack provisioned using the AWS CDK:
cdk destroy –all
Conclusion
This innovative solution represents a significant leap forward in educational technology, demonstrating how AWS services can be used in course development. By integrating Amazon Bedrock, AWS Lambda, WebSockets, and a robust suite of AWS services, we’ve built a system that streamlines content creation, enhances real-time interactivity, and facilitates secure, scalable, and high-quality learning experiences.
By developing comprehensive course materials rapidly, course designers can focus more on personalized instruction and student mentoring. AI-assisted generation facilitates high-quality, standardized content across courses. The event-driven architecture scales effortlessly to meet institutional demands, and CloudFront, AWS WAF, and Amazon Cognito support secure and optimized content delivery. Institutions adopting this technology position themselves at the forefront of educational innovation, redefining modern learning environments.
This solution goes beyond simple automation—it means teachers and professors can shift their focus from manual content creation to high-impact teaching and mentoring. By using AWS AI and cloud technologies, institutions can enhance student engagement, optimize content quality, and scale seamlessly.
We invite you to explore how this solution can transform your institution’s approach to course creation and student engagement. To learn more about implementing this system or to discuss custom solutions for your specific needs, contact your AWS account team or an AWS education specialist.
Together, let’s build the future of education on the cloud.
About the authors
Dinesh Mane is a Senior ML Prototype Architect at AWS, specializing in machine learning, generative AI, and MLOps. In his current role, he helps customers address real-world, complex business problems by developing machine learning and generative AI solutions through rapid prototyping.
Tasneem Fathima is Senior Solutions Architect at AWS. She supports Higher Education and Research customers in the United Arab Emirates to adopt cloud technologies, improve their time to science, and innovate on AWS.
Amir Majlesi leads the EMEA prototyping team within AWS Worldwide Specialist Organization. Amir has extensive experiences in helping customers accelerate adoption of cloud technologies, expedite path to production and catalyze a culture of innovation. He enables customer teams to build cloud native applications using agile methodologies, with a focus on emerging technologies such as Generative AI, Machine Learning, Analytics, Serverless and IoT.