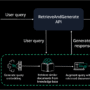
Released on August 5, 2025, OpenAI’s GPT-OSS models, gpt-oss-20b and gpt-oss-120b, are now available on AWS through Amazon SageMaker AI and Amazon Bedrock. These pre-trained, text-only Transformer models are built on a Mixture-of-Experts (MoE) architecture that activates only a subset of parameters per token, delivering high reasoning performance while reducing compute costs. They specialize in coding, scientific analysis, and mathematical reasoning, and support a 128,000 context length, adjustable reasoning levels (low/medium/high), chain-of-thought (CoT) reasoning with audit-friendly traces, structured outputs, and tool use to support agentic-AI workflows. As discussed in OpenAI’s documentation, both models have undergone safety-focused training and adversarial fine-tuning evaluations to assess and strengthen robustness against misuse. The following table summarizes the model specifications.
Model
Layers
Total Parameters
Active Parameters Per Token
Total Experts
Active Experts Per Token
Context Length
openai/gpt-oss-120b
36
117 billion
5.1 billion
128
4
128,000
openai/gpt-oss-20b
24
21 billion
3.6 billion
32
4
128,000
The GPT-OSS models are deployable using Amazon SageMaker JumpStart and also accessible through Amazon Bedrock APIs. Both options provide developers the flexibility to deploy and integrate GPT-OSS models into your production-grade AI workflows. Beyond out-of-the-box deployment, these models can be fine-tuned to align with specific domains and use cases, using open source tools from the Hugging Face ecosystem and running on the fully managed infrastructure of SageMaker AI.
Fine-tuning large language models (LLMs) is the process of adjusting a pre-trained model’s weights using a smaller, task-specific dataset to tailor its behavior to a particular domain or application. Fine-tuning large models like GPT-OSS transforms them from a broad generalist into a domain-specific expert without the cost of training from scratch. Adapting the model to your data and terminology can deliver more accurate, context-aware outputs, improves reliability, and reduces hallucinations. The result is a specialized GPT-OSS that excels at targeted tasks while retaining the scalability, flexibility, and open-weight benefits ideal for secure, enterprise-grade deployment.
In this post, we walk through the process of fine-tuning a GPT-OSS model in a fully managed training environment using SageMaker AI training jobs. The workflow uses the Hugging Face TRL library for fine-tuning, the Hugging Face Accelerate library to simplify distributed training across multiple GPUs and nodes, and the DeepSpeed ZeRO-3 optimization technique to reduce memory usage by partitioning model states across devices for efficient training of billion-parameter models. We then apply this setup to fine-tune the GPT-OSS model on a multilingual reasoning dataset, HuggingFaceH4/Multilingual-Thinking, enabling GPT-OSS to handle structured, CoT reasoning across multiple languages.
Solution overview
SageMaker AI is a managed machine learning (ML) service that streamlines the entire foundation model (FM) lifecycle. It provides hosted, interactive notebooks for rapid exploration, fully managed ephemeral training jobs for large-scale and distributed fine-tuning, and Amazon SageMaker HyperPod clusters that offer granular control over persistent training infrastructure for large-scale model training and fine-tuning workloads. By using managed hosting in SageMaker, you can serve models reliably in production, and the suite of AIOps-ready tools, such as reusable pipelines and fully managed MLflow, support experiment tracking, model registration, and seamless deployment. With built-in governance and enterprise-grade security, SageMaker AI provides data engineers, data scientists, and ML engineers with a unified, fully managed platform to build, train, deploy, and govern FMs end-to-end.
GPT-OSS can be fine-tuned on SageMaker using the latest Hugging Face TRL library, which can be written as recipes for fine-tuning LLMs using Hugging Face SFTTrainer. These recipes can also be adapted to fine-tune other open-weight language or vision models such as Qwen, Mistral, Meta, and many more. In this post, we show how to fine-tune GPT-OSS in a distributed setup either on a single node multi-GPU setup or across multi-node multi-GPU setup, using Hugging Face Accelerate to manage multi-device training and DeepSpeed ZeRO-3 to train large models more efficiently. Together, they help you fine-tune faster and scale to larger datasets.
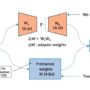
We also highlight MXFP4 (Microscaling FP4), a 4-bit floating-point quantization format from the Open Compute Project. It groups tensors into small blocks, each sharing a scaling factor, which reduces memory and compute needs while helping preserve model accuracy—making it well-suited for efficient model training. Complementing quantization, we explore Parameter-Efficient Fine-Tuning (PEFT) methods like LoRA, for the adaptation of large models by learning a small set of additional parameters instead of modifying all weights. This approach is memory- and compute-efficient, highly compatible with quantized models, and supports fine-tuning even on constrained hardware environments.
The following diagram illustrates this configuration (source).
By using MXFP4 quantization, PEFT fine-tuning methods like LoRA, and distributed training with Hugging Face Accelerate and DeepSpeed ZeRO-3 together, we can efficiently and scalably fine-tune large models like gpt-oss-120b and gpt-oss-20b for high-performance customization while keeping infrastructure and compute costs manageable.
Prerequisites
To fine-tune GPT-OSS models on SageMaker AI, you must have the following prerequisites:
An AWS account that will contain your AWS resources.
An AWS Identity and Access Management (IAM) role to access SageMaker AI. To learn more about how IAM works with SageMaker AI, see AWS Identity and Access Management for Amazon SageMaker AI.
You can run the notebook provided in this post from your preferred development environment, including interactive development environments (IDEs) such as PyCharm or Visual Studio Code, provided your AWS credentials are properly set up and configured to access your AWS account. To set up your local environment, refer to Configuring settings for the AWS CLI. Optionally, we recommend using Amazon SageMaker Studio for straightforward development process on SageMaker AI.
If you’re following along with this post, we use the ml.p5en.48xlarge instance for fine-tuning the 120B model and the ml.p4de.24xlarge instance for the 20B model. You will need access to these SageMaker compute instances to run the example notebook presented in this post. If you’re unsure, you can review the AWS service quotas on the AWS Management Console:
Choose Amazon SageMaker as the AWS service under Manage Quotas.
Select ml.p4de.24xlarge for training job usage or ml.p5en.48xlarge for training job usage based on the model you’re interested in fine-tuning and request an increase at account level.
Access to the GitHub repo.
Business outcomes for fine-tuning GPT-OSS
Global enterprises increasingly need AI tools that support complex reasoning across multiple languages—whether for multilingual virtual assistants, cross-location support desks, or international knowledge systems. Although FMs offer a powerful starting point, their effectiveness in diverse linguistic contexts hinges on structured reasoning inputs—datasets that surface logic steps explicitly and across languages. That’s why testing with a multilingual, CoT-style dataset is a valuable first step. It lets you verify how well a model holds reasoning coherence when switching between languages and reasoning patterns, laying a robust foundation before scaling to larger, domain-specific multilingual datasets. GPT-OSS is particularly well-suited for this task, with its native CoT capabilities, long 128,000 context window, and adjustable reasoning levels, making it ideal for evaluating and refining multilingual reasoning performance before production deployment.
Fine-tune GPT-OSS models for multi-lingual reasoning on SageMaker AI
In this section, we walk through how to fine-tune OpenAI’s GPT-OSS models on SageMaker AI using training jobs. SageMaker training jobs support distributed multi-GPU and multi-node configurations, so you can spin up high-performance clusters on demand, train billion-parameter models faster, and automatically shut down resources when the job finishes.
Set up your environment
In the following sections, we run the code from SageMaker Studio JupyterLab notebook instances. You can also use your preferred IDE, such as VS Code or PyCharm, but make sure your local environment is configured to work with AWS, as discussed in the prerequisites.
Complete the following steps:
On the SageMaker AI console, choose Domains in the navigation pane, then open your domain.
In the navigation pane under Applications and IDEs, choose Studio.
On the User profiles tab, locate your user profile, then choose Launch and Studio.
In SageMaker Studio, launch an ml.t3.medium JupyterLab notebook instance with at least 50 GB of storage.
A large notebook instance isn’t required, because the fine-tuning job will run on a separate ephemeral training job instance with NVIDIA accelerators.
To begin fine-tuning, start by cloning the GitHub repo and navigating to 3_distributed_training/models/openai–gpt-oss directory, then launch the finetune_gpt_oss.ipynb notebook with a Python 3.12 or higher version kernel:
# clone github repo
git clone https://github.com/aws-samples/amazon-sagemaker-generativeai.git
Dataset for fine-tuning
Selecting and curating the right dataset is a critical first step in fine-tuning any LLM. In this post, we use the Hugging FaceH4/Multilingual-Thinking dataset, which is a multilingual reasoning dataset containing CoT examples translated into languages such as French, Spanish, and German. Its combination of diverse languages, varied reasoning tasks, and explicit step-by-step thought processes makes it well-suited for evaluating how a model handles structured reasoning, adapts to multilingual inputs, and maintains logical consistency across different linguistic contexts. With around 1,000 examples, it’s small enough for quick experimentation yet sufficient to demonstrate fine-tuning and evaluation of large pre-trained models like GPT-OSS. The dataset can be loaded in just a few lines of code using the Hugging Face Datasets library:
# load datasets in memory
dataset_name = ‘HuggingFaceH4/Multilingual-Thinking’
dataset = load_dataset(dataset_name, split=”train”)
The following code is some sample data:
{
“reasoning_language”: “French”,
“developer”: “You are a recipe suggestion bot, …”,
“user”: “Can you provide me with a step-by-step …”,
“analysis”: “D’accord, l’utilisateur souhaite une recette …”,
“final”: “Certainly! Here’s a classic homemade chocolate …”,
“messages”: [
{
“content”: “reasoning language: FrenchnnYou are a …”,
“role”: “system”,
“thinking”: null
},
{
“content”: “Can you provide me with a step-by-step …”,
“role”: “user”,
“thinking”: null
},
{
“content”: “Certainly! Here’s a classic homemade chocolate …”,
“role”: “assistant”,
“thinking”: “D’accord, l’utilisateur souhaite une recette …“
}
]
}
For supervised fine-tuning, we use only the data in the messages key to train our GPT-OSS model. Because TRL’s SFTTrainer natively supports this format, it can be used as-is. We extract all rows containing only the messages key, save them in JSONL format, and upload the file to Amazon Simple Storage Service (Amazon S3). This makes sure the dataset is readily accessible to SageMaker training jobs at runtime.
# preserve only messages key
dataset = dataset.remove_columns(
[col for col in dataset.column_names if col != “messages”]
)
# save as JSONL format
dataset_filename = os.path.join(dataset_parent_path, f”{dataset_name.replace(‘/’, ‘–‘).replace(‘.’, ‘-‘)}.jsonl”)
dataset.to_json(dataset_filename, lines=True)
…
from sagemaker.s3 import S3Uploader
# select a data destination bucket
data_s3_uri = f”s3://{sess.default_bucket()}/dataset”
# upload to S3
uploaded_s3_uri = S3Uploader.upload(
local_path=dataset_filename,
desired_s3_uri=data_s3_uri
)
print(f”Uploaded {dataset_filename} to > {uploaded_s3_uri}”)
Experimentation tracking with MLflow (Optional)
SageMaker AI offers the fully managed MLflow capability, so you can track multiple training runs within experiments, compare results with visualizations, evaluate models, and register the best ones in the model registry. MLflow also supports integration with agentic workflows.
TRL’s SFTTrainer natively integrates with experimentation tracking tools such as MLflow, TensorBoard, Weights & Biases, and more. With SFTTrainer, you can log training parameters, hyperparameters, loss metrics, system metrics, and more to a centralized location, providing you with audit trails, governance, and streamlined experiment tracking. This step is optional; if you choose not to use SageMaker managed MLflow, you can set the SFTTrainer parameter reports_to to tensorboard, which will log all metrics locally to disk for visualization using a local or remote TensorBoard service.
# set none to log to local disk
MLFLOW_TRACKING_SERVER_ARN = None # or “arn:aws:sagemaker:us-west-2:<account-id>:mlflow-tracking-server/<server-name>”
if MLFLOW_TRACKING_SERVER_ARN:
reports_to = “mlflow”
else:
reports_to = “tensorboard”
print(“reports to:”, reports_to)
Experiments logged from TRL’s SFTTrainer to an MLflow tracking server in SageMaker automatically capture key metrics and parameters. The SageMaker managed MLflow service renders real-time visualizations, profiles training hardware with minimal setup, enables side-by-side run comparisons, and provides built-in evaluation tools to track, train, and assess your fine-tuning jobs end-to-end.
Fine-tune GPT-OSS on training jobs
The following example demonstrates how to fine-tune the gpt-oss-20b model. To switch to gpt-oss-120b, simply update the model_name. The model-to-instance mapping shown in this section has been tested as part of this notebook workflow. You can adjust the instance type and instance count to fit your specific use case.
The following table summarizes the different model specifications.
GPT‑OSS Model
SageMaker Instance
GPU Specifications
openai/gpt-oss-120b
ml.p5en.48xlarge
8× NVIDIA H200 GPUs, 96 GB HBM3 each
openai/gpt-oss-20b
ml.p4de.24xlarge
8× NVIDIA A100 GPUs, 80 GB HBM2e each
# User-defined variables
model_name = “openai/gpt-oss-20b”
tokenizer_name = “openai/gpt-oss-20b”
# dataset path inside a sagemaker container
dataset_path = “/opt/ml/input/data/training/HuggingFaceH4–Multilingual-Thinking.jsonl”
output_path = “/opt/ml/model/openai-gpt-oss-20b-HuggingFaceH4-Multilingual-Thinking/”
# support only for Ampere, Hopper and Grace Blackwell
bf16_flag = “true”
SageMaker training jobs automatically download datasets from the specified S3 prefix or file into the training container, mapping them to /opt/ml/input. Training artifacts and logs are stored in /opt/ml/output, and the final trained or fine-tuned model is saved to /opt/ml/model. Saving the model to this path allows SageMaker to automatically detect it for downstream workflows such as model registration, deployment, and other automation. You can set or unset the bf16_flag to choose between float16 and bfloat16. float16 uses less memory but has a smaller numeric range, whereas bfloat16 provides a wider range with similar memory savings, making it more stable for training large models. bfloat16 is supported on newer GPU architectures such as NVIDIA Ampere, Hopper, and Grace Blackwell.
Fine-tuning with open source Hugging Face recipes
With Hugging Face’s TRL library, you can define Supervised Fine-Tuning (SFT) recipes, which are essentially preconfigured training workflows that streamline fine-tuning FMs like Meta, Qwen, Mistral, and now OpenAI GPT‑OSS with minimal setup. These recipes simplify the process of adapting models to new datasets using TRL’s SFTTrainer and configuration tools.
yaml_template = “””# Model arguments
model_name_or_path: {{ model_name }}
tokenizer_name_or_path: {{ tokenizer_name }}
model_revision: main
torch_dtype: bfloat16
attn_implementation: kernels-community/vllm-flash-attn3
bf16: {{ bf16_flag }}
tf32: false
output_dir: {{ output_dir }}
# Dataset arguments
dataset_id_or_path: {{ dataset_path }}
max_seq_length: 2048
packing: true
packing_strategy: wrapped
# LoRA arguments
use_peft: true
lora_target_modules: “all-linear”
### Specific to GPT-OSS
lora_modules_to_save: [“7.mlp.experts.gate_up_proj”, “7.mlp.experts.down_proj”, “15.mlp.experts.gate_up_proj”, “15.mlp.experts.down_proj”, “23.mlp.experts.gate_up_proj”, “23.mlp.experts.down_proj”]
lora_r: 8
lora_alpha: 16
# Training arguments
num_train_epochs: 1.
per_device_train_batch_size: 6
per_device_eval_batch_size: 6
gradient_accumulation_steps: 3
gradient_checkpointing: true
optim: adamw_torch_fused
gradient_checkpointing_kwargs:
use_reentrant: true
learning_rate: 1.0e-4
lr_scheduler_type: cosine
warmup_ratio: 0.1
max_grad_norm: 0.3
bf16: {{ bf16_flag }}
bf16_full_eval: {{ bf16_flag }}
tf32: false
# Logging arguments
logging_strategy: steps
logging_steps: 2
report_to:
– {{ reports_to }}
save_strategy: “epoch”
seed: 42
“””
config_filename = “openai-gpt-oss-20b-qlora.yaml”
The recipe.yaml file contains the following key parameters:
Model arguments:
model_name_or_path or tokenizer_name_or_path – Path or identifier for the base model and tokenizer to fine-tune. Models can be loaded locally from disk or the Hugging Face Hub.
torch_dtype – Sets training precision. bfloat16 offers float16-level memory savings with a wider numeric range for better stability, and is supported on NVIDIA Ampere, Hopper, and Grace Blackwell GPUs. Alternatively, set to float16 for older versions of NVIDIA GPUs.
attn_implementation – Uses vLLM FlashAttention 3 (kernels-community/vllm-flash-attn3) kernels for faster attention computation, supported for newer Hopper GPUs. Alternatively, set eager for older NVIDIA GPUs.
Dataset arguments:
dataset_id_or_path – Local dataset location as JSONL file or Hugging Face Hub ID for the dataset.
max_seq_length – Maximum token length per sequence (for example, 2048). Provide longer sequence lengths for datasets that require longer reasoning output tokens. Longer sequence lengths consume more GPU memory.
LoRA arguments:
use_peft – Enables PEFT using LoRA. Set to true for PEFT or false for full fine-tuning.
lora_target_modules – Target layers for LoRA adaptation (for example, all-linear layers is default for most dense and MoEs).
lora_modules_to_save – GPT-OSS-specific layers to keep in full precision during LoRA training.
lora_r or lora_alpha – Rank and scaling factor for LoRA updates.
Logging and saving arguments:
report_to – Experiment tracking integration (such as MLflow or TensorBoard).
After a recipe is defined and tested, you can seamlessly swap configurations such as the model name, dataset, number of epochs, or PEFT settings and run or rerun the fine-tuning workflow with minimal or no code changes.
SageMaker estimators
As a next step, we use a SageMaker training job estimator to spin up a training cluster and run the model fine-tuning. The SageMaker AI estimators API provide a high-level API to define and run training jobs on fully managed infrastructure, handling environment setup, scaling, and artifact management. You can specify training scripts, input data, and compute resources without manually provisioning servers. SageMaker also offers prebuilt Hugging Face and PyTorch estimators, which come optimized for their respective frameworks, making it straightforward to train and fine-tune models with minimal setup.
It’s recommended to use Python 3.12 and higher to fine-tune GPT-OSS with the following packages installed. Add or update the requirements.txt file in your script’s root directory with the following packages. SageMaker estimators will automatically detect this file and install the listed dependencies at runtime.
%%writefile code/requirements.txt
transformers>=4.55.0
kernels>=0.9.0
datasets==4.0.0
bitsandbytes==0.46.1
trl>=0.20.0
peft>=0.17.0
lighteval==0.10.0
hf-transfer==0.1.8
hf_xet
tensorboard
liger-kernel==0.6.1
deepspeed==0.17.4
lm-eval[api]==0.4.9
Pillow
mlflow
sagemaker-mlflow==0.1.0
triton
git+https://github.com/triton-lang/triton.git@main#subdirectory=python/triton_kernels
Define a SageMaker estimator and point it to your local training script directory. SageMaker will package the contents and place them in /opt/ml/code inside the training container. This includes your training script, additional modules in the directory, and if a requirements.txt file is present, SageMaker will automatically install the listed packages at runtime.
pytorch_estimator = PyTorch(
image_uri=”763104351884.dkr.ecr.us-west-2.amazonaws.com/pytorch-training:2.7.1-gpu-py312-cu128-ubuntu22.04-sagemaker”,
entry_point=”accelerate_sagemaker_train.sh”, # Adapted bash script to train using accelerate on SageMaker – Multi-GPU
source_dir=”code”,
instance_type=training_instance_type,
instance_count=1, # multi-node training support
base_job_name=f”{job_name}-pytorch”,
role=role,
…
hyperparameters={
“num_process”: NUM_GPUS, # define the number of GPUs to run distributed training, per instance
“config”: f”recipes/{config_filename}”,
}
)
The following is the directory structure for fine-tuning GPT-OSS on SageMaker AI training jobs:
code/
├── accelerate/ # Accelerate configuration files
├── accelerate_sagemaker_train.sh # Launch script for distributed training with Accelerate on SageMaker training jobs
├── gpt_oss_sft.py # Main training script for supervised fine-tuning (SFT) of GPT-OSS
├── recipes/ # Predefined training configuration recipes (YAML)
└── requirements.txt # Python dependencies installed at runtime
To fine-tune across multiple GPUs, we use Hugging Face Accelerate and DeepSpeed ZeRO-3, which work together to train large models more efficiently. Hugging Face Accelerate simplifies launching distributed training by automatically handling device placement, process management, and mixed precision settings. DeepSpeed ZeRO-3 reduces memory usage by partitioning optimizer states, gradients, and parameters across devices—allowing billion-parameter models to fit and train faster.
You can run your SFTTrainer script with Hugging Face Accelerate using a simple command like the following:
accelerate launch
–config_file accelerate/zero3.yaml
–num_processes 8 gpt_oss_sft.py
–config recipes/openai-gpt-oss-20b-qlora.yaml
SageMaker executes this command inside the training container because we set entry_point=”accelerate_sagemaker_train.sh” when initializing the SageMaker estimator. The accelerate_sagemaker_train.sh script is defined as follows:
#!/bin/bash
set -e
…
# Launch fine-tuning with Accelerate + DeepSpeed (Zero3)
accelerate launch
–config_file accelerate/zero3.yaml
–num_processes “$NUM_GPUS”
gpt_oss_sft.py
–config “$CONFIG_PATH”
PEFT vs. full fine-tuning
The gpt_oss_sft.py script lets you choose between PEFT and full fine-tuning by setting use_peft to true or false. Full fine-tuning gives you greater control over the base model weights, enabling broader adaptability and expressiveness. However, it also carries the risk of catastrophic forgetting and higher resource consumption during the training process.
At the end of training, you will have the fully adapted model weights, which can be deployed to a SageMaker endpoint for inference. You can then run predictions against the deployed endpoint using the SageMaker Predictor.
Conclusion
In this post, we demonstrated how to fine-tune OpenAI’s GPT-OSS models (gpt-oss-120b and gpt-oss-20b) on SageMaker AI using SageMaker training jobs, the Hugging Face TRL library, and distributed training with Hugging Face Accelerate and DeepSpeed ZeRO-3. By combining the fully managed, ephemeral infrastructure of SageMaker with TRL’s streamlined fine-tuning recipes, you can adapt GPT-OSS to your domain quickly and efficiently, using either PEFT for cost-effective customization or full fine-tuning for maximum model control. With the resulting model artifacts, you can deploy to SageMaker endpoints for secure, scalable inference and bring advanced reasoning capabilities directly into your enterprise workflows.
If you’re interested in exploring further, the GitHub repo contains all the resources used in this walkthrough. It’s a great starting point for experimenting with fine-tuning GPT-OSS on your own datasets and deploying the resulting models to SageMaker for real-world applications. You can get set up with a notebook in minutes using the SageMaker Studio domain quick setup and start experimenting right away.
About the authors
Pranav Murthy is a Senior Generative AI Data Scientist at AWS, specializing in helping organizations innovate with Generative AI, Deep Learning, and Machine Learning on Amazon SageMaker AI. Over the past 10+ years, he has developed and scaled advanced computer vision (CV) and natural language processing (NLP) models to tackle high-impact problems—from optimizing global supply chains to enabling real-time video analytics and multilingual search. When he’s not building AI solutions, Pranav enjoys playing strategic games like chess, traveling to discover new cultures, and mentoring aspiring AI practitioners. You can find Pranav on LinkedIn.
Sumedha Swamy is a Senior Manager of Product Management at Amazon Web Services (AWS), where he leads several areas of the Amazon SageMaker, including SageMaker Studio – the industry-leading integrated development environment for machine learning, developer and administrator experiences, AI infrastructure, and SageMaker SDK.