To fulfill their tasks, AI Agents need access to various capabilities including tools, data stores, prompt templates, and other agents. As organizations scale their AI initiatives, they face an exponentially growing challenge of connecting each agent to multiple tools, creating an M×N integration problem that significantly slows development and increases complexity.
Although protocols such as Model Context Protocol (MCP) and Agent2Agent (A2A) have emerged to address interoperability, implementing these solutions requires substantial engineering effort. Organizations must build MCP servers, convert existing APIs, manage infrastructure, build intelligent tools discovery, and implement security controls, all that while maintaining these integrations over time as protocols rapidly evolve and new major versions are released. As deployments grow to hundreds of agents and thousands of tools, enterprises need a more scalable and manageable solution.
Introducing Amazon Bedrock AgentCore Gateway
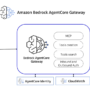
We’re excited to announce Amazon Bedrock AgentCore Gateway, a fully managed service that revolutionizes how enterprises connect AI agents with tools and services. AgentCore Gateway serves as a centralized tool server, providing a unified interface where agents can discover, access, and invoke tools.
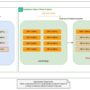
Built with native support for the MCP, Gateway enables seamless agent-to-tool communication while abstracting away security, infrastructure, and protocol-level complexities. This service provides zero-code MCP tool creation from APIs and AWS Lambda functions, intelligent tool discovery, built-in inbound and outbound authorization, and serverless infrastructure for MCP servers. You can focus on building intelligent agent experiences rather than managing connectivity with tools and services. The following diagram illustrates the AgentCore Gateway workflow.
Key capabilities of Amazon Bedrock AgentCore Gateway
The Amazon Bedrock AgentCore Gateway introduces a comprehensive set of capabilities designed to revolutionize tool integration for AI agents. At its core, Gateway offers powerful and secure API integration functionality that transforms existing REST APIs into MCP servers. This integration supports both OpenAPI specifications and Smithy models, so organizations can seamlessly convert their enterprise APIs into MCP-compatible tools. Beyond API integration, Gateway provides built-in support for Lambda functions so developers can connect their serverless computing resources as tools with defined schemas. Gateway provides the following key capabilities:
Security Guard – Manages OAuth authorization so only valid users and agents can access tools and resources. We will dive deeper into security in the following section.
Translation – Converts agent requests using protocols such as MCP into API requests and Lambda invocations, alleviating the need to manage protocol integration or version support.
Composition – Combines multiple APIs, functions, and tools into a single MCP endpoint for streamlined agent access.
Target extensibility – An AgentCore gateway is a central access point that serves as a unified interface for AI agents to discover and interact with tools. It handles authentication, request routing, and protocol translation between MCP and your APIs. Each gateway can manage multiple targets. A target represents a backend service or group of APIs that you want to expose as tools to AI agents. Targets can be AWS Lambda functions, OpenAPI specifications, or Smithy models. Each target can expose multiple tools, and Gateway automatically handles the conversion between MCP and the target’s built-in protocol. Gateway supports streamable http transport.
Infrastructure Manager – As a fully managed service, Gateway removes the burden of infrastructure management from organizations. It provides comprehensive infrastructure with built-in security features and robust observability capabilities. Teams no longer need to worry about hosting concerns, scaling issues, or maintaining the underlying infrastructure. The service automatically handles these aspects, providing reliable performance and seamless scaling as demand grows.
Semantic Tool Selection – Intelligent tool discovery represents another core capability of Gateway. As organizations scale to hundreds or thousands of tools, discovering the right tool becomes increasingly challenging for AI agents. Moreover, when agents are presented with too many tools simultaneously, they can experience something called “tool overload,” leading to hallucinations, incorrect tool selections, or inefficient execution paths that significantly impact performance. Gateway addresses these challenges by providing a special built-in tool named ‘x_amz_bedrock_agentcore_search’ that can be accessed using the standard MCP tools and call operation.
Security and authentication
Gateway implements a sophisticated dual-sided security architecture that handles both inbound access to Gateway itself and outbound connections to target services.
For inbound requests, Gateway follows the MCP authorization specification, using OAuth-based authorization to validate and authorize incoming tool calls. Gateway functions as an OAuth resource server. This means it can work with the OAuth Identity Provider your organization might use–whether that’s Amazon Cognito, Okta, Auth0, or your own OAuth provider. When you create a gateway, you can specify multiple approved client IDs and audiences, giving you granular control over which applications and agents can access your tools. The Gateway validates incoming requests against your OAuth provider, supporting both authorization code flow (3LO) and client credentials flow (2LO, commonly used for service-to-service communication).
The outbound security model is equally flexible but varies by target type:
For AWS Lambda and Smithy model targets, AgentCore Gateway uses AWS Identity and Access Management (IAM) based authorization. The gateway assumes an IAM role you configure, which can have precisely scoped permissions for each target service. This integrates smoothly with existing AWS security practices and IAM policies.
For OpenAPI targets (REST APIs), Gateway supports two authentication methods:
API key – You can configure the key to be sent in either headers or query parameters with customizable parameter names
OAuth token for 2LO – For outbound OAuth authentication to target APIs, Gateway supports two-legged OAuth (2LO) client credentials grant type, enabling secure machine-to-machine communications without user interaction
Credentials are securely managed through AgentCore Identity’s resource credentials provider. Each target is associated with exactly one authentication configuration, facilitating clear security boundaries and audit trails. AgentCore Identity handles the complex security machinery while presenting a clean, simple interface to developers. You configure security one time during setup, and Gateway handles the token validation, outbound token caching (through AgentCore Identity), and secure communication from there.
Get started with Amazon Bedrock AgentCore Gateway
You can create gateways and add targets through multiple interfaces:
AWS SDK for Python (Boto3)
AWS Management Console
AWS Command Line Interface (AWS CLI)
AgentCore starter toolkit for fast and straightforward setup
The following practical examples and code snippets demonstrate the process of setting up and using Amazon Bedrock AgentCore Gateway.
Create a gateway
To create a gateway, use Amazon Cognito for inbound auth using the AWS Boto3:
gateway_client = boto3.client(‘bedrock-agentcore-control’)
auth_config = {
“customJWTAuthorizer”: {
“allowedClients”: ‘<cognito_client_id>‘, # Client MUST match with the ClientId configured in Cognito.
“discoveryUrl”: ‘<cognito_oauth_discovery_url>’
}
}
create_response = gateway_client.create_gateway(name=’DemoGateway’,
roleArn = ‘<IAM Role>’ # The IAM Role must have permissions to create/list/get/delete Gateway
protocolType=’MCP’,
authorizerType=’CUSTOM_JWT’,
authorizerConfiguration=auth_config,
description=’Demo AgentCore Gateway’
)
# Values with < > needs to be replaced with real values
Here is the reference to control plane and data plane APIs for Amazon Bedrock AgentCore.
Create gateway targets
Create a target for an existing API using OpenAPI specification with API key as an outbound auth:
# Create outbound credentials provider in AgentCore Identity
acps boto3client(service_name”bedrock-agentcore-control”)
responseacpscreate_api_key_credential_provider(
name”APIKey”,
apiKey”<your secret API key”
)
credentialProviderARN response[‘credentialProviderArn’]
# Specify OpenAPI spec file via S3 or inline
openapi_s3_target_config = {
“mcp”: {
“openApiSchema”: {
“s3”: {
“uri”: openapi_s3_uri
}
}
}
}
# API Key credentials provider configuration
api_key_credential_config = [
{
“credentialProviderType” : “API_KEY”,
“credentialProvider”: {
“apiKeyCredentialProvider”: {
“credentialParameterName”: “api_key”, # Replace this with the name of the api key name expected by the respective API provider. For passing token in the header, use “Authorization”
“providerArn”: credentialProviderARN,
“credentialLocation”:”QUERY_PARAMETER”, # Location of api key. Possible values are “HEADER” and “QUERY_PARAMETER”.
#”credentialPrefix”: ” ” # Prefix for the token. Valid values are “Basic”. Applies only for tokens.
}
}
}
]
# Add the OpenAPI target to the gateway
targetname=’DemoOpenAPITarget’
response = gateway_client.create_gateway_target(
gatewayIdentifier=gatewayID,
name=targetname,
description=’OpenAPI Target with S3Uri using SDK’,
targetConfiguration=openapi_s3_target_config,
credentialProviderConfigurations=api_key_credential_config)
Create a target for a Lambda function:
# Define the lambda target with tool schema. Replace the AWS Lambda function ARN below
lambda_target_config = {
“mcp”: {
“lambda”: {
“lambdaArn”: “<Your AWS Lambda function ARN>”,
“toolSchema”: {
“inlinePayload”: [
{
“name”: “get_order_tool”,
“description”: “tool to get the order”,
“inputSchema”: {
“type”: “object”,
“properties”: {
“orderId”: {
“type”: “string”
}
},
“required”: [
“orderId”
]}}]}}}}
# Create outbound auth config. For AWS Lambda function, its always IAM.
credential_config = [
{
“credentialProviderType” : “GATEWAY_IAM_ROLE”
}
]
# Add AWS Lambda target to the gateway
targetname=’LambdaUsingSDK’
response = gateway_client.create_gateway_target(
gatewayIdentifier=gatewayID,
name=targetname,
description=’Lambda Target using SDK’,
targetConfiguration=lambda_target_config,
credentialProviderConfigurations=credential_config)
Use Gateway with different agent frameworks
Use Gateway with Strands Agents integration:
from strands import Agent
import logging
def create_streamable_http_transport():
return streamablehttp_client(gatewayURL,headers={“Authorization”: f”Bearer {token}”})
client = MCPClient(create_streamable_http_transport)
with client:
# Call the listTools
tools = client.list_tools_sync()
# Create an Agent with the model and tools
agent = Agent(model=yourmodel,tools=tools) ## you can replace with any model you like
# Invoke the agent with the sample prompt. This will only invoke MCP listTools and retrieve the list of tools the LLM has access to. The below does not actually call any tool.
agent(“Hi , can you list all tools available to you”)
# Invoke the agent with sample prompt, invoke the tool and display the response
agent(“Check the order status for order id 123 and show me the exact response from the tool”)
Use Gateway with LangChain integration:
from langchain_mcp_adapters.client import MultiServerMCPClient
from langgraph.prebuilt import create_react_agent
from langchain.chat_models import init_chat_model
client = MultiServerMCPClient(
{
“healthcare”: {
“url”: gateway_endpoint,
“transport”: “streamable_http”,
“headers”:{“Authorization”: f”Bearer {jwt_token}”}
}
}
)
agent = create_react_agent(
LLM,
tools,
prompt=systemPrompt
)
Implement semantic search
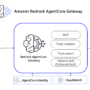
You can opt in to semantic search when creating a gateway. It automatically provisions a powerful built-in tool called x_amz_bedrock_agentcore_search that enables intelligent tool discovery through natural language queries. Use the output of the search tool in place of MCP’s list operation for scalable and performant tool discovery. The following diagram illustrates how you can use the MCP search tool.
To enable semantic search, use the following code:
# Enable semantic search of tools
search_config = {
“mcp”: {“searchType”: “SEMANTIC”, “supportedVersions”: [“2025-03-26″]}
}
# Create the gateway
response = agentcore_client.create_gateway(
name=gateway_name,
roleArn=gateway_role_arn,
authorizerType=”CUSTOM_JWT”,
description=gateway_desc,
protocolType=”MCP”,
authorizerConfiguration=auth_config,
protocolConfiguration=search_config,
)
def tool_search(gateway_endpoint, jwt_token, query):
toolParams = {
“name”: “x_amz_bedrock_agentcore_search”,
“arguments”: {“query”: query},
}
toolResp = invoke_gateway_tool(
gateway_endpoint=gateway_endpoint, jwt_token=jwt_token, tool_params=toolParams
)
tools = toolResp[“result”][“structuredContent”][“tools”]
return tools
To find the entire code sample, visit the Semantic search tutorial in the amazon-bedrock-agentcore-samples GitHub repository.
Assess Gateway performance using monitoring and observability
Amazon Bedrock AgentCore Gateway provides observability through integration with Amazon CloudWatch and AWS CloudTrail, for detailed monitoring and troubleshooting of your tool integrations. The observability features include multiple dimensions of gateway operations through detailed metrics: usage metrics (TargetType, IngressAuthType, EgressAuthType, RequestsPerSession), invocation metrics (Invocations, ConcurrentExecutions, Sessions), performance metrics (Latency, Duration, TargetExecutionTime), and error rates (Throttles, SystemErrors, UserErrors). The performance metrics can be analyzed using various statistical methods (Average, Minimum, Maximum, p50, p90, p99) and are tagged with relevant dimensions for granular analysis, including Operation, Resource, and Name . For operational logging, Gateway integrates with CloudTrail to capture both management and data events, providing a complete audit trail of API interactions. The metrics are accessible through both the Amazon Bedrock AgentCore console and CloudWatch console, where you can create custom dashboards, set up automated alerts, and perform detailed performance analysis.
Best practices
Gateway offers an enhanced debugging option through the exceptionLevel property, which can be enabled during Gateway creation or updated as shown in the following code example:
create_response = gateway_client.create_gateway(name=’DemoGateway’,
roleArn = ‘<IAM Role>’ # The IAM Role must have permissions to create/list/get/delete Gateway
protocolType=’MCP’,
authorizerType=’CUSTOM_JWT’,
authorizerConfiguration=auth_config,
description=’Demo AgentCore Gateway’,
exceptionLevel=”DEBUG” # Debug mode for granular error messages
)
When activated, this feature provides more granular error messages in the content text block (with isError:true) during Gateway testing, facilitating quicker troubleshooting and integration. When documenting and extracting Open APIs for Gateway, focus on clear, natural language descriptions that explain real-world use cases. Include detailed field descriptions, validation rules, and examples for complex data structures while maintaining consistent terminology throughout. For optimal tool discovery, incorporate relevant business domain keywords naturally in descriptions and provide context about when to use each API. Finally, test semantic search effectiveness so tools are discoverable through natural language queries. Regular reviews and updates are essential to maintain documentation quality as APIs evolve.When extracting APIs from larger specifications, identify the core functionality needed for agent tasks, maintain semantic relationships between components, and preserve security definitions. Follow a systematic extraction process: review the full specification, map agent use cases to specific endpoints, extract relevant paths and schemas while maintaining dependencies, and validate the extracted specification.The following are the best practices on grouping your APIs into a Gateway target:
Start with the use case and group your MCP tools based on the agentic application’s business domain similar to domain-driven design principles applicable to the microservices paradigm.
You can attach only one resource credentials provider for outbound authorization for the Gateway target. Group the tools based on the outbound authorizer.
Group your APIs based on the type of the APIs, that is, OpenAPI, Smithy, or AWS Lambda, serving as a bridge to other enterprise APIs.
When onboarding tools to Gateway, organizations should follow a structured process that includes security and vulnerability checks. Implement a review pipeline that scans API specifications for potential security risks, maintains proper authentication mechanisms, and validates data handling practices. For runtime tool discovery, use the semantic search capabilities in Gateway, but also consider design-time agent-tool mapping for critical workflows to provide predictable behavior.
Enrich tool metadata with detailed descriptions, usage examples, and performance characteristics to improve discoverability and aid in appropriate tool selection by agents. To maintain consistency across your enterprise, integrate Gateway with a centralized tool registry that serves as a single source of truth. This can be achieved using open source solutions such as the MCP Registry Publisher Tool, which publishes MCP server details to an MCP registry. Regularly synchronize Gateway’s tool inventory with this central registry for up-to-date and consistent tool availability across your AI landscape. These practices can help maintain a secure, well-organized, and efficiently discoverable tool solution within Gateway, facilitating seamless agent-tool interactions while can align with enterprise governance standards.
What customers are saying
Innovaccer, a leading healthcare technology company, shares their experience:
“AI has massive potential in healthcare, but getting the foundation right is key. That’s why we’re building HMCP (Healthcare Model Context Protocol) on Amazon Bedrock AgentCore Gateway, which has been a game-changer, automatically converting our existing APIs into MCP-compatible tools and scaling seamlessly as we grow. It gives us the secure, flexible base we need to make sure AI agents can safely and responsibly interact with healthcare data, tools, and workflows. With this partnership, we’re accelerating AI innovation with trust, compliance, and real-world impact at the core.”
—Abhinav Shashank, CEO & Co-founder, Innovaccer
Conclusion
Amazon Bedrock AgentCore Gateway represents a significant advancement in enterprise AI agent development. By providing a fully managed, secure, and scalable solution for tool integration, Gateway enables organizations to accelerate their AI initiatives while maintaining enterprise-grade security and governance. As part of the broader Amazon Bedrock AgentCore suite, Gateway works seamlessly with other capabilities including Runtime, Identity, Code Interpreter, Memory, Browser, and Observability to provide a comprehensive domain for building and scaling AI agent applications.
For more detailed information and advanced configurations, refer to the code samples on GitHub, the Amazon Bedrock AgentCore Gateway Developer Guide and Amazon AgentCore Gateway pricing.
About the authors
Dhawal Patel is a Principal Machine Learning Architect at Amazon Web Services (AWS). He has worked with organizations ranging from large enterprises to mid-sized startups on problems related to distributed computing and AI. He focuses on deep learning, including natural language processing (NLP) and computer vision domains. He helps customers achieve high-performance model inference on Amazon SageMaker.
Mike Liu is a Principal Product Manager at Amazon, where he works at the intersection of agentic AI and foundational model development. He led the product roadmap for Amazon Bedrock Agents and is now helping customers achieve superior performance using model customization on Amazon Nova models. Prior to Amazon, he worked on AI/ML software in Google Cloud and ML accelerators at Intel.
Kartik Rustagi works as a Software Development Manager in Amazon AI. He and his team focus on enhancing the conversation capability of chat bots powered by Amazon Lex. When not at work, he enjoys exploring the outdoors and savoring different cuisines.