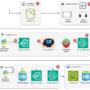
Enterprises—especially in the insurance industry—face increasing challenges in processing vast amounts of unstructured data from diverse formats, including PDFs, spreadsheets, images, videos, and audio files. These might include claims document packages, crash event videos, chat transcripts, or policy documents. All contain critical information across the claims processing lifecycle.
Traditional data preprocessing methods, though functional, might have limitations in accuracy and consistency. This might affect metadata extraction completeness, workflow velocity, and the extent of data utilization for AI-driven insights (such as fraud detection or risk analysis). To address these challenges, this post introduces a multi‐agent collaboration pipeline: a set of specialized agents for classification, conversion, metadata extraction, and domain‐specific tasks. By orchestrating these agents, you can automate the ingestion and transformation of a wide range of multimodal unstructured data—boosting accuracy and enabling end‐to‐end insights.
For teams processing a small volume of uniform documents, a single-agent setup might be more straightforward to implement and sufficient for basic automation. However, if your data spans diverse domains and formats—such as claims document packages, collision footage, chat transcripts, or audio files—a multi-agent architecture offers distinct advantages. Specialized agents allow for targeted prompt engineering, better debugging, and more accurate extraction, each tuned to a specific data type.
As volume and variety grow, this modular design scales more gracefully, allowing you to plug in new domain-aware agents or refine individual prompts and business logic—without disrupting the broader pipeline. Feedback from domain experts in the human-in-the-loop phase can also be mapped back to specific agents, supporting continuous improvement.
To support this adaptive architecture, you can use Amazon Bedrock, a fully managed service that makes it straightforward to build and scale generative AI applications using foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, DeepSeek, Luma, Meta, Mistral AI, poolside (coming soon), Stability AI, and Amazon through a single API. A powerful feature of Amazon Bedrock—Amazon Bedrock Agents—enables the creation of intelligent, domain-aware agents that can retrieve context from Amazon Bedrock Knowledge Bases, call APIs, and orchestrate multi-step tasks. These agents provide the flexibility and adaptability needed to process unstructured data at scale, and can evolve alongside your organization’s data and business workflows.
Solution overview
Our pipeline functions as an insurance unstructured data preprocessing hub with the following features:
Classification of incoming unstructured data based on domain rules
Metadata extraction for claim numbers, dates, and more
Conversion of documents into uniform formats (such as PDF or transcripts)
Conversion of audio/video data into structured markup format
Human validation for uncertain or missing fields
Enriched outputs and associated metadata will ultimately land in a metadata‐rich unstructured data lake, forming the foundation for fraud detection, advanced analytics, and 360‐degree customer views.
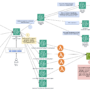
The following diagram illustrates the solution architecture.
The end-to-end workflow features a supervisor agent at the center, classification and conversion agents branching off, a human‐in‐the‐loop step, and Amazon Simple Storage Service (Amazon S3) as the final unstructured data lake destination.
Multi‐agent collaboration pipeline
This pipeline is composed of multiple specialized agents, each handling a distinct function such as classification, conversion, metadata extraction, and domain-specific analysis. Unlike a single monolithic agent that attempts to manage all tasks, this modular design promotes scalability, maintainability, and reuse. Individual agents can be independently updated, swapped, or extended to accommodate new document types or evolving business rules without impacting the overall system. This separation of concerns improves fault tolerance and enables parallel processing, resulting in faster and more reliable data transformation workflows.
Multi-agent collaboration offers the following metrics and efficiency gains:
Reduction in human validation time – Focused prompts tailored to specific agents will lead to cleaner outputs and less complicated verification, providing efficiency in validation time.
Faster iteration cycles and regression isolation – Changes to prompts or logic are scoped to individual agents, minimizing the area of effect of updates and significantly reducing regression testing effort during tuning or enhancement phases.
Improved metadata extraction accuracy, especially on edge cases – Specialized agents reduce prompt overload and allow deeper domain alignment, which improves field-level accuracy—especially when processing mixed document types like crash videos vs. claims document packages.
Scalable efficiency gains with automated issue resolver agents – As automated issue resolver agents are added over time, processing time per document is expected to improve considerably, reducing manual touchpoints. These agents can be designed to use human-in-the-loop feedback mappings and intelligent data lake lookups to automate recurring fixes.
Unstructured Data Hub Supervisor Agent
The Supervisor Agent orchestrates the workflow, delegates tasks, and invokes specialized downstream agents. It has the following key responsibilities:
Receive incoming multimodal data and processing instructions from the user portal (multimodal claims document packages, vehicle damage images, audio transcripts, or repair estimates).
Forward each unstructured data type to the Classification Collaborator Agent to determine whether a conversion step is needed or direct classification is possible.
Coordinate specialized domain processing by invoking the appropriate agent for each data type—for example, a claims documents package is handled by the Claims Documentation Package Processing Agent, and repair estimates go to the Vehicle Repair Estimate Processing Agent.
Make sure that every incoming data eventually lands, along with its metadata, in the S3 data lake.
Classification Collaborator Agent
The Classification Collaborator Agent determines each file’s type using domain‐specific rules and makes sure it’s either converted (if needed) or directly classified. This includes the following steps:
Identify the file extension. If it’s DOCX, PPT, or XLS, it routes the file to the Document Conversion Agent first.
Output a unified classification result for each standardized document—specifying the category, confidence, extracted metadata, and next steps.
Document Conversion Agent
The Document Conversion Agent converts non‐PDF files into PDF and extracts initial metadata (creation date, file size, and so on). This includes the following steps:
Transform DOCX, PPT, XLS, and XLSX into PDF.
Capture embedded metadata.
Return the new PDF to the Classification Collaborator Agent for final classification.
Specialized classification agents
Each agent handles specific modalities of data:
Document Classification Agent:
Processes text‐heavy formats like claims document packages, standard operating procedure documents (SOPs), and policy documents
Extracts claim numbers, policy numbers, policy holder details, coverage dates, and expense amounts as metadata
Identifies missing items (for example, missing policy holder information, missing dates)
Transcription Classification Agent:
Focuses on audio or video transcripts, such as First Notice of Lost (FNOL) calls or adjuster follow‐ups
Classifies transcripts into business categories (such as first‐party claim or third‐party conversation) and extracts relevant metadata
Image Classification Agent:
Analyzes vehicle damage photos and collision videos for details like damage severity, vehicle identification, or location
Generates structured metadata that can be fed into downstream damage analysis systems
Additionally, we have defined specialized downstream agents:
Claims Document Package Processing Agent
Vehicle Repair Estimate Processing Agent
Vehicle Damage Analysis Processing Agent
Audio Video Transcription Processing Agent
Insurance Policy Document Processing Agent
After the high‐level classification identifies a file as, for example, a claims document package or repair estimate, the Supervisor Agent invokes the appropriate specialized agent to perform deeper domain‐specific transformation and extraction.
Metadata extraction and human-in-the-loop
Metadata is essential for automated workflows. Without accurate metadata fields—like claim numbers, policy numbers, coverage dates, loss dates, or claimant names—downstream analytics lack context. This part of the solution handles data extraction, error handling, and recovery through the following features:
Automated extraction – Large language models (LLMs) and domain‐specific rules parse critical data from unstructured content, identify key metadata fields, and flag anomalies early.
Data staging for review – The pipeline extracts metadata fields and stages each record for human review. This process presents the extracted fields—highlighting missing or incorrect values for human review.
Human-in-the-loop – Domain experts step in to validate and correct metadata during the human-in-the-loop phase, providing accuracy and context for key fields such as claim numbers, policyholder details, and event timelines. These interventions not only serve as a point-in-time error recovery mechanism but also lay the foundation for continuous improvement of the pipeline’s domain-specific rules, conversion logic, and classification prompts.
Eventually, automated issue resolver agents can be introduced in iterations to handle an increasing share of data fixes, further reducing the need for manual review. Several strategies can be introduced to enable this progression to improve resilience and adaptability over time:
Persisting feedback – Corrections made by domain experts can be captured and mapped to the types of issues they resolve. These structured mappings help refine prompt templates, update business logic, and generate targeted instructions to guide the design of automated issue resolver agents to emulate similar fixes in future workflows.
Contextual metadata lookups – As the unstructured data lake becomes increasingly metadata-rich—with deeper connections across policy numbers, claim IDs, vehicle info, and supporting documents— issue resolver agents with appropriate prompts can be introduced to perform intelligent dynamic lookups. For example, if a media file lacks a policy number but includes a claim number and vehicle information, an issue resolver agent can retrieve missing metadata by querying related indexed documents like claims document packages or repair estimates.
By combining these strategies, the pipeline becomes increasingly adaptive—continually improving data quality and enabling scalable, metadata-driven insights across the enterprise.
Metadata‐rich unstructured data lake
After each unstructured data type is converted and classified, both the standardized content
and metadata JSON files are stored in an unstructured data lake (Amazon S3). This repository unifies different data types (images, transcripts, documents) through shared metadata, enabling the following:
Fraud detection by cross‐referencing repeated claimants or contradictory details
Customer 360-degree profiles by linking claims, calls, and service records
Advanced analytics and real‐time queries
Multi‐modal, multi‐agentic pattern
In our AWS CloudFormation template, each multimodal data type follows a specialized flow:
Data conversion and classification:
The Supervisor Agent receives uploads and passes them to the Classification Collaborator Agent.
If needed, the Document Conversion Agent might step in to standardize the file.
The Classification Collaborator Agent’s classification step organizes the uploads into categories—FNOL calls, claims document packages, collision videos, and so on.
Document processing:
The Document Classification Agent and other specialized agents apply domain rules to extract metadata like claim numbers, coverage dates, and more.
The pipeline presents the extracted as well as missing information to the domain expert for correction or updating.
Audio/video analysis:
The Transcription Classification Agent handles FNOL calls and third‐party conversation transcripts.
The Audio Video Transcription Processing Agent or the Vehicle Damage Analysis Processing Agent further parses collision videos or damage photos, linking spoken events to visual evidence.
Markup text conversion:
Specialized processing agents create markup text from the fully classified and corrected metadata. This way, the data is transformed into a metadata-rich format ready for consumption by knowledge bases, Retrieval Augmented Generation (RAG) pipelines, or graph queries.
Human-in-the-loop and future improvements
The human‐in‐the‐loop component is key for verifying and adding missing metadata and fixing incorrect categorization of data. However, the pipeline is designed to evolve as follows:
Refined LLM prompts – Every correction from domain experts helps refine LLM prompts, reducing future manual steps and improving metadata consistency
Issue resolver agents – As metadata consistency improves over time, specialized fixers can handle metadata and classification errors with minimal user input
Cross referencing – Issue resolver agents can cross‐reference existing data in the metadata-rich S3 data lake to automatically fill in missing metadata
The pipeline evolves toward full automation, minimizing human oversight except for the most complex cases.
Prerequisites
Before deploying this solution, make sure that you have the following in place:
An AWS account. If you don’t have an AWS account, sign up for one.
Access as an AWS Identity and Access Management (IAM) administrator or an IAM user that has permissions for:
Deploying AWS CloudFormation.
Creating and managing S3 buckets and uploading objects.
Creating and updating Amazon Simple Queue Service (Amazon SQS) queues, AWS Lambda functions, Amazon Bedrock, Amazon Bedrock Agents, Amazon Bedrock Knowledge Bases, Amazon OpenSearch Service, and Amazon API Gateway.
Creating and managing IAM roles.
Access to Amazon Bedrock. Make sure Amazon Bedrock is available in your AWS Region, and you have explicitly enabled the FMs you plan to use (for example, Anthropic’s Claude or Cohere). Refer to Add or remove access to Amazon Bedrock foundation models for guidance on enabling models for your AWS account. This solution was tested in us-west-2. Make sure that you have enabled the required FMs:
claude-3-5-haiku-20241022-v1:0
claude-3-5-sonnet-20241022-v2:0
claude-3-haiku-20240307-v1:0
titan-embed-text-v2:0
Set the API Gateway integration timeout from the default 29 seconds to 180 seconds, as introduced in this announcement, in your AWS account by submitting a service quota increase for API Gateway integration timeout.
Deploy the solution with AWS CloudFormation
Complete the following steps to set up the solution resources:
Sign in to the AWS Management Console as an IAM administrator or appropriate IAM user.
Choose Launch Stack to deploy the CloudFormation template.
Provide the necessary parameters and create the stack.
For this setup, we use us-west-2 as our Region, Anthropic’s Claude 3.5 Haiku model for orchestrating the flow between the different agents, and Anthropic’s Claude 3.5 Sonnet V2 model for conversion, categorization, and processing of multimodal data.
If you want to use other models on Amazon Bedrock, you can do so by making appropriate changes in the CloudFormation template. Check for appropriate model support in the Region and the features that are supported by the models.
It will take about 30 minutes to deploy the solution. After the stack is deployed, you can view the various outputs of the CloudFormation stack on the Outputs tab, as shown in the following screenshot.
The provided CloudFormation template creates multiple S3 buckets (such as DocumentUploadBucket, SampleDataBucket, and KnowledgeBaseDataBucket) for raw uploads, sample files, Amazon Bedrock Knowledge Bases references, and more. Each specialized Amazon Bedrock agent or Lambda function uses these buckets to store intermediate or final artifacts.
The following screenshot is an illustration of the Amazon Bedrock agents that are deployed in the AWS account.
The next section outlines how to test the unstructured data processing workflow.
Test the unstructured data processing workflow
In this section, we present different use cases to demonstrate the solution. Before you begin, complete the following steps:
Locate the APIGatewayInvokeURL value from the CloudFormation stack’s outputs. This URL launches the Insurance Unstructured Data Preprocessing Hub in your browser.
Download the sample data files from the designated S3 bucket (SampleDataBucketName) to your local machine. The following screenshots show the bucket details from CloudFormation stack’s outputs and the contents of the sample data bucket.
With these details, you can now test the pipeline by uploading the following sample multimodal files through the Insurance Unstructured Data Preprocessing Hub Portal:
Claims document package (ClaimDemandPackage.pdf)
Vehicle repair estimate (collision_center_estimate.xlsx)
Collision video with supported audio (carcollision.mp4)
First notice of loss audio transcript (fnol.mp4)
Insurance policy document (ABC_Insurance_Policy.docx)
Each multimodal data type will be processed through a series of agents:
Supervisor Agent – Initiates the processing
Classification Collaborator Agent – Categorizes the multimodal data
Specialized processing agents – Handle domain-specific processing
Finally, the processed files, along with their enriched metadata, are stored in the S3 data lake. Now, let’s proceed to the actual use cases.
Use Case 1: Claims document package
This use case demonstrates the complete workflow for processing a multimodal claims document package. By uploading a PDF document to the pipeline, the system automatically classifies the document type, extracts essential metadata, and categorizes each page into specific components.
Choose Upload File in the UI and choose the pdf file.
The file upload might take some time depending on the document size.
When the upload is complete, you can confirm that the extracted metadata values are follows:
Claim Number: 0112233445
Policy Number: SF9988776655
Date of Loss: 2025-01-01
Claimant Name: Jane Doe
The Classification Collaborator Agent identifies the document as a Claims Document Package. Metadata (such as claim ID and incident date) is automatically extracted and displayed for review.
For this use case, no changes are made—simply choose Continue Preprocessing to proceed.
The processing stage might take up to 15 minutes to complete. Rather than manually checking the S3 bucket (identified in the CloudFormation stack outputs as KnowledgeBaseDataBucket) to verify that 72 files—one for each page and its corresponding metadata JSON—have been generated, you can monitor the progress by periodically choosing Check Queue Status. This lets you view the current state of the processing queue in real time.
The pipeline further categorizes each page into specific types (for example, lawyer letter, police report, medical bills, doctor’s report, health forms, x-rays). It also generates corresponding markup text files and metadata JSON files.
Finally, the processed text and metadata JSON files are stored in the unstructured S3 data lake.
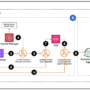
The following diagram illustrates the complete workflow.
Use Case 2: Collision center workbook for vehicle repair estimate
In this use case, we upload a collision center workbook to trigger the workflow that converts the file, extracts repair estimate details, and stages the data for review before final storage.
Choose Upload File and choose the xlsx workbook.
Wait for the upload to complete and confirm that the extracted metadata is accurate:
Claim Number: CLM20250215
Policy Number: SF9988776655
Claimant Name: John Smith
Vehicle: Truck
The Document Conversion Agent converts the file to PDF if needed, or the Classification Collaborator Agent identifies it as a repair estimate. The Vehicle Repair Estimate Processing Agent extracts cost lines, part numbers, and labor hours.
Review and update the displayed metadata as necessary, then choose Continue Preprocessing to trigger final storage.
The finalized file and metadata are stored in Amazon S3.
The following diagram illustrates this workflow.
Use Case 3: Collision video with audio transcript
For this use case, we upload a video showing the accident scene to trigger a workflow that analyzes both visual and audio data, extracts key frames for collision severity, and stages metadata for review before final storage.
Choose Upload File and choose the mp4 video.
Wait until the upload is complete, then review the collision scenario and adjust the displayed metadata to correct omissions or inaccuracies as follows:
Claim Number: 0112233445
Policy Number: SF9988776655
Date of Loss: 01-01-2025
Claimant Name: Jane Doe
Policy Holder Name: John Smith
The Classification Collaborator Agent directs the video to either the Audio/Video Transcript or Vehicle Damage Analysis agent. Key frames are analyzed to determine collision severity.
Review and update the displayed metadata (for example, policy number, location), then choose Continue Preprocessing to initiate final storage.
Final transcripts and metadata are stored in Amazon S3, ready for advanced analytics such as verifying story consistency.
The following diagram illustrates this workflow.
Use Case 4: Audio transcript between claimant and customer service associate
Next, we upload a video that captures the claimant reporting an accident to trigger the workflow that extracts an audio transcript and identifies key metadata for review before final storage.
Choose Upload File and choose mp4.
Wait until the upload is complete, then review the call scenario and adjust the displayed metadata to correct any omissions or inaccuracies as follows:
Claim Number: Not Assigned Yet
Policy Number: SF9988776655
Claimant Name: Jane Doe
Policy Holder Name: John Smith
Date Of Loss: January 1, 2025 8:30 AM
The Classification Collaborator Agent routes the file to the Audio/Video Transcript Agent for processing. Key metadata attributes are automatically identified from the call.
Review and correct any incomplete metadata, then choose Continue Preprocessing to proceed.
Final transcripts and metadata are stored in Amazon S3, ready for advanced analytics (for example, verifying story consistency).
The following diagram illustrates this workflow.
Use Case 5: Auto insurance policy document
For our final use case, we upload an insurance policy document to trigger the workflow that converts and classifies the document, extracts key metadata for review, and stores the finalized output in Amazon S3.
Choose Upload File and choose docx.
Wait until the upload is complete, and confirm that the extracted metadata values are as follows:
Policy Number: SF9988776655
Policy type: Auto Insurance
Effective Date: 12/12/2024
Policy Holder Name: John Smith
The Document Conversion Agent transforms the document into a standardized PDF format if required. The Classification Collaborator Agent then routes it to the Document Classification Agent for categorization as an Auto Insurance Policy Document. Key metadata attributes are automatically identified and presented for user review.
Review and correct incomplete metadata, then choose Continue Preprocessing to trigger final storage.
The finalized policy document in markup format, along with its metadata, is stored in Amazon S3—ready for advanced analytics such as verifying story consistency.
The following diagram illustrates this workflow.
Similar workflows can be applied to other types of insurance multimodal data and documents by uploading them on the Data Preprocessing Hub Portal. Whenever needed, this process can be enhanced by introducing specialized downstream Amazon Bedrock agents that collaborate with the existing Supervisor Agent, Classification Agent, and Conversion Agents.
Amazon Bedrock Knowledge Bases integration
To use the newly processed data in the data lake, complete the following steps to ingest the data in Amazon Bedrock Knowledge Bases and interact with the data lake using a structured workflow. This integration allows for dynamic querying across different document types, enabling deeper insights from multimodal data.
Choose Chat with Your Documents to open the chat interface.
Choose Sync Knowledge Base to initiate the job that ingests and indexes the newly processed files and the available metadata into the Amazon Bedrock knowledge base.
After the sync is complete (which might take a couple of minutes), enter your queries in the text box. For example, set Policy Number to SF9988776655 and try asking:
“Retrieve details of all claims filed against the policy number by multiple claimants.”
“What is the nature of Jane Doe’s claim, and what documents were submitted?”
“Has the policyholder John Smith submitted any claims for vehicle repairs, and are there any estimates on file?”
Choose Send and review the system’s response.
This integration enables cross-document analysis, so you can query across multimodal data types like transcripts, images, claims document packages, repair estimates, and claim records to reveal customer 360-degree insights from your domain-aware multi-agent pipeline. By synthesizing data from multiple sources, the system can correlate information, uncover hidden patterns, and identify relationships that might not have been evident in isolated documents.
A key enabler of this intelligence is the rich metadata layer generated during preprocessing. Domain experts actively validate and refine this metadata, providing accuracy and consistency across diverse document types. By reviewing key attributes—such as claim numbers, policyholder details, and event timelines—domain experts enhance the metadata foundation, making it more reliable for downstream AI-driven analysis.
With rich metadata in place, the system can now infer relationships between documents more effectively, enabling use cases such as:
Identifying multiple claims tied to a single policy
Detecting inconsistencies in submitted documents
Tracking the complete lifecycle of a claim from FNOL to resolution
By continuously improving metadata through human validation, the system becomes more adaptive, paving the way for future automation, where issue resolver agents can proactively identify and self-correct missing and inconsistent metadata with minimal manual intervention during the data ingestion process.
Clean up
To avoid unexpected charges, complete the following steps to clean up your resources:
Delete the contents from the S3 buckets mentioned in the outputs of the CloudFormation stack.
Delete the deployed stack using the AWS CloudFormation console.
Conclusion
By transforming unstructured insurance data into metadata‐rich outputs, you can accomplish the following:
Accelerate fraud detection by cross‐referencing multimodal data
Enhance customer 360-degree insights by uniting claims, calls, and service records
Support real‐time decisions through AI‐assisted search and analytics
As this multi‐agent collaboration pipeline matures, specialized issue resolver agents and refined LLM prompts can further reduce human involvement—unlocking end‐to‐end automation and improved decision‐making. Ultimately, this domain‐aware approach future‐proofs your claims processing workflows by harnessing raw, unstructured data as actionable business intelligence.
To get started with this solution, take the following next steps:
Deploy the CloudFormation stack and experiment with the sample data.
Refine domain rules or agent prompts based on your team’s feedback.
Use the metadata in your S3 data lake for advanced analytics like real‐time risk assessment or fraud detection.
Connect an Amazon Bedrock knowledge base to KnowledgeBaseDataBucket for advanced Q&A and RAG.
With a multi‐agent architecture in place, your insurance data ceases to be a scattered liability, becoming instead a unified source of high‐value insights.
Refer to the following additional resources to explore further:
Automate tasks in your application using AI agents
Retrieve data and generate AI responses with Amazon Bedrock Knowledge Bases
Amazon Bedrock Samples GitHub repo
About the Author
Piyali Kamra is a seasoned enterprise architect and a hands-on technologist who has over two decades of experience building and executing large scale enterprise IT projects across geographies. She believes that building large scale enterprise systems is not an exact science but more like an art, where you can’t always choose the best technology that comes to one’s mind but rather tools and technologies must be carefully selected based on the team’s culture , strengths, weaknesses and risks, in tandem with having a futuristic vision as to how you want to shape your product a few years down the road.