
Generative AI has emerged as a powerful tool for content creation, offering several key benefits that can significantly enhance the efficiency and effectiveness of content production processes such as creating marketing materials, image generation, content moderation etc. Constitutional AI and LangGraph‘s reflection mechanisms represent two complementary approaches to ensuring AI systems behave ethically – with Anthropic embedding principles during training while LangGraph implements them during inference/runtime through reflection and self-correction mechanisms. By using LanGraph’s Constitutional AI, content creators can streamline their workflow while maintaining high standards of user-defined compliance and ethical integrity. This method not only reduces the need for extensive human oversight but also enhances the transparency and accountability of content generation process by AI.
In this post, we explore practical strategies for using Constitutional AI to produce compliant content efficiently and effectively using Amazon Bedrock and LangGraph to build ConstitutionalChain for rapid content creation in highly regulated industries like finance and healthcare. Although AI offers significant productivity benefits, maintaining compliance with strict regulations are crucial. Manual validation of AI-generated content for regulatory adherence can be time-consuming and challenging. We also provide an overview of how Insagic, a Publicis Groupe company, integrated this concept into their existing healthcare marketing workflow using Amazon Bedrock. Insagic is a next-generation insights and advisory business that combines data, design, and dialogues to deliver actionable insights and transformational intelligence for healthcare marketers. It uses expertise from data scientists, behavior scientists, and strategists to drive better outcomes in the healthcare industry.
Understanding Constitutional AI
Constitutional AI is designed to align large language models (LLMs) with human values and ethical considerations. It works by integrating a set of predefined rules, principles, and constraints into the LLM’s core architecture and training process. This approach makes sure that the LLM operates within specified ethical and legal parameters, much like how a constitution governs a nation’s laws and actions.
The key benefits of Constitutional AI for content creation include:
Ethical alignment – Content generated using Constitutional AI is inherently aligned with predefined ethical standards
Legal compliance – The LLM is designed to operate within legal frameworks, reducing the risk of producing non-compliant content
Transparency – The principles guiding the LLM’s decision-making process are clearly defined and can be inspected
Reduced human oversight – By embedding ethical guidelines into the LLM, the need for extensive human review is significantly reduced
Let’s explore how you can harness the power of Constitutional AI to generate compliant content for your organization.
Solution overview
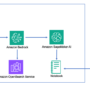
For this solution, we use Amazon Bedrock Knowledge Bases to store a repository of healthcare documents. We employ a Retrieval Augmented Generation (RAG) approach, first retrieving relevant context and synthesizing an answer based on the retrieved context, to generate articles based on the repository. We then use the open source orchestration framework LangGraph and ConstitutionalChain to generate, critique, and review prompts in an Amazon SageMaker notebook and develop an agentic workflow to generate compliance content. The following diagram illustrates this architecture.
This implementation demonstrates a sophisticated agentic workflow that not only generates responses based on a knowledge base but also employs a reflection technique to examine its outputs through ethical principles, allowing it to refine and improve its outputs. We upload a sample set of mental health documents to Amazon Bedrock Knowledge Bases and use those documents to write an article on mental health using a RAG-based approach. Later, we define a constitutional principle with a custom Diversity, Equity, and Inclusion (DEI) principle, specifying how to critique and revise responses for inclusivity.
Prerequisites
To deploy the solution, you need the following prerequisites:
An AWS account
Appropriate AWS Identity and Access Management (IAM) permissions to access an Amazon Simple Storage Service (Amazon S3) bucket, create Amazon Bedrock knowledge bases, and create a SageMaker notebook instance
Create an Amazon Bedrock knowledge base
To demonstrate this capability, we download a mental health article from the following GitHub repo and store it in Amazon S3. We then use Amazon Bedrock Knowledge Bases to index the articles. By default, Amazon Bedrock uses Amazon OpenSearch Serverless as a vector database. For full instructions to create an Amazon Bedrock knowledge base with Amazon S3 as the data source, see Create a knowledge base in Amazon Bedrock Knowledge Bases.
On the Amazon Bedrock console, create a new knowledge base.
Provide a name for your knowledge base and create a new IAM service role.
Choose Amazon S3 as the data source and provide the S3 bucket storing the mental health article.
Choose Amazon Titan Text Embeddings v2 as the embeddings model and OpenSearch Serverless as the vector store.
Choose Create Knowledge Base.
Import statements and set up an Amazon Bedrock client
Follow the instructions provided in the README file in the GitHub repo. Clone the GitHub repo to make a local copy. We recommend running this code in a SageMaker JupyterLab environment. The following code imports the necessary libraries, including Boto3 for AWS services, LangChain components, and Streamlit. It sets up an Amazon Bedrock client and configures Anthropic’s Claude 3 Haiku model with specific parameters.
import boto3
from langchain_aws import ChatBedrock
…
bedrock_runtime = boto3.client(service_name=”bedrock-runtime”, region_name=”us-east-1″)
llm = ChatBedrock(client=bedrock_runtime, model_id=”anthropic.claude-3-haiku-20240307-v1:0″)
…..
Define Constitutional AI components
Next, we define a Critique class to structure the output of the critique process. Then we create prompt templates for critique and revision. Lastly, we set up chains using LangChain for generating responses, critiques, and revisions.
# LangChain Constitutional chain migration to LangGraph
class Critique(TypedDict):
“””Generate a critique, if needed.”””
critique_needed: Annotated[bool, …, “Whether or not a critique is needed.”]
critique: Annotated[str, …, “If needed, the critique.”]
critique_prompt = ChatPromptTemplate.from_template(
“Critique this response according to the critique request. ”
…
)
revision_prompt = ChatPromptTemplate.from_template(
“Revise this response according to the critique and reivsion request.nn”
….
)
chain = llm | StrOutputParser()
critique_chain = critique_prompt | llm.with_structured_output(Critique)
revision_chain = revision_prompt | llm | StrOutputParser()
Define a State class and refer to the Amazon Bedrock Knowledge Bases retriever
We define a LangGraph State class to manage the conversation state, including the query, principles, responses, and critiques:
# LangGraph State
class State(TypedDict):
query: str
constitutional_principles: List[ConstitutionalPrinciple]
Next, we set up an Amazon Bedrock Knowledge Bases retriever to extract the relevant information. We refer to the Amazon Bedrock knowledge base we created earlier to create an article based on mental health documents. Make sure to update the knowledge base ID in the following code with the knowledge base you created in previous steps:
#—————————————————————–
# Amazon Bedrock KnowledgeBase
from langchain_aws.retrievers import AmazonKnowledgeBasesRetriever
retriever = AmazonKnowledgeBasesRetriever(
knowledge_base_id=”W3NMIJXLUE”, # Change it to your Knowledge base ID
…
)
Create LangGraph nodes and a LangGraph graph along with constitutional principles
The next section of code integrates graph-based workflow orchestration, ethical principles, and a user-friendly interface to create a sophisticated Constitutional AI model. The following diagram illustrates the workflow.
It uses a StateGraph to manage the flow between RAG and critique/revision nodes, incorporating a custom DEI principle to guide the LLM’s responses. The system is presented through a Streamlit application, which provides an interactive chat interface where users can input queries and view the LLM’s initial responses, critiques, and revised answers. The application also features a sidebar displaying a graph visualization of the workflow and a description of the applied ethical principle. This comprehensive approach makes sure that the LLM’s outputs are not only knowledge-based but also ethically aligned by using customizable constitutional principles that guide a reflection flow (critique and revise), all while maintaining a user-friendly experience with features like chat history management and a clear chat option.
Streamlit application
The Streamlit application component of this code creates an interactive and user-friendly interface for the Constitutional AI model. It sets up a side pane that displays a visualization of the LLM’s workflow graph and provides a description of the DEI principle being applied. The main interface features a chat section where users can input their queries and view the LLM’s responses.
# ————————————————————————
# Streamlit App
# Clear Chat History fuction
def clear_screen():
st.session_state.messages = [{“role”: “assistant”, “content”: “How may I assist you today?”}]
with st.sidebar:
st.subheader(‘Constitutional AI Demo’)
…..
ConstitutionalPrinciple(
name=”DEI Principle”,
critique_request=”Analyze the content for any lack of diversity, equity, or inclusion. Identify specific instances where the text could be more inclusive or representative of diverse perspectives.”,
revision_request=”Rewrite the content by incorporating critiques to be more diverse, equitable, and inclusive. Ensure representation of various perspectives and use inclusive language throughout.”
)
“””)
st.button(‘Clear Screen’, on_click=clear_screen)
# Store LLM generated responses
if “messages” not in st.session_state.keys():
st.session_state.messages = [{“role”: “assistant”, “content”: “How may I assist you today?”}]
# Chat Input – User Prompt
if prompt := st.chat_input():
….
with st.spinner(f”Generating…”):
….
with st.chat_message(“assistant”):
st.markdown(“**[initial response]**”)
….
st.session_state.messages.append({“role”: “assistant”, “content”: “[revised response] ” + generation[‘response’]})
The application maintains a chat history, displaying both user inputs and LLM responses, including the initial response, any critiques generated, and the final revised response. Each step of the LLM’s process is clearly labeled and presented to the user. The interface also includes a Clear Screen button to reset the chat history. When processing a query, the application shows a loading spinner and displays the runtime, providing transparency into the LLM’s operation. This comprehensive UI design allows users to interact with the LLM while observing how constitutional principles are applied to refine the LLM’s outputs.
Test the solution using the Streamlit UI
In the Streamlit application, when a user inputs a query, the application initiates the process by creating and compiling the graph defined earlier. It then streams the execution of this graph, which includes the RAG and critique/revise steps. During this process, the application displays real-time updates for each node’s execution, showing the user what’s happening behind the scenes. The system measures the total runtime, providing transparency about the processing duration. When it’s complete, the application presents the results in a structured manner within the chat interface. It displays the initial LLM-generated response, followed by any critiques made based on the constitutional principles, and finally shows the revised response that incorporates these ethical considerations. This step-by-step presentation allows users to see how the LLM’s response evolves through the constitutional AI process, from initial generation to ethical refinement. As mentioned, in the GitHub README file, in order to run the Streamlit application, use the following code:
pip install -r requirements.txt
streamlit run main.py
For details on using a Jupyter proxy to access the Streamlit application, refer to Build Streamlit apps in Amazon SageMaker Studio.
Modify the Studio URL, replacing lab? with proxy/8501/.
How Insagic uses Constitutional AI to generate compliant content
Insagic uses real-world medical data to help brands understand people as patients and patients as people, enabling them to deliver actionable insights in the healthcare marketing space. Although generating deep insights in the health space can yield profound dividends, it must be done with consideration for compliance and the personal nature of health data. By defining federal guidelines as constitutional principles, Insagic makes sure that the content delivered by generative AI complies with federal guidelines for healthcare marketing.
Clean up
When you have finished experimenting with this solution, clean up your resources to prevent AWS charges from being incurred:
Empty the S3 buckets.
Delete the SageMaker notebook instance.
Delete the Amazon Bedrock knowledge base.
Conclusion
This post demonstrated how to implement a sophisticated generative AI solution using Amazon Bedrock and LangGraph to generate compliant content. You can also integrate this workflow to generate responses based on a knowledge base and apply ethical principles to critique and revise its outputs, all within an interactive web interface. Insagic is looking at more ways to incorporate this into existing workflows by defining custom principles to achieve compliance goals.
You can expand this concept further by incorporating Amazon Bedrock Guardrails. Amazon Bedrock Guardrails and LangGraph Constitutional AI can create a comprehensive safety system by operating at different levels. Amazon Bedrock provides API-level content filtering and safety boundaries, and LangGraph implements constitutional principles in reasoning workflows. Together, they enable multi-layered protection through I/O filtering, topic restrictions, ethical constraints, and logical validation steps in AI applications.
Try out the solution for your own use case, and leave your feedback in the comments.
About the authors
Sriharsh Adari is a Senior Solutions Architect at Amazon Web Services (AWS), where he helps customers work backwards from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data platform transformations across industry verticals. His core area of expertise include Technology Strategy, Data Analytics, and Data Science. In his spare time, he enjoys playing sports, binge-watching TV shows, and playing Tabla.
David Min is a Senior Partner Sales Solutions Architect at Amazon Web Services (AWS) specializing in Generative AI, where he helps customers transform their businesses through innovative AI solutions. Throughout his career, David has helped numerous organizations across industries bridge the gap between cutting-edge AI technology and practical business applications, focusing on executive engagement and successful solution adoption.
Stephen Garth is a Data Scientist at Insagic, where he develops advanced machine learning solutions, including LLM-powered automation tools and deep clustering models for actionable, consumer insights. With a strong background spanning software engineering, healthcare data science, and computational research, he is passionate to bring his expertise in AI-driven analytics and large-scale data processing to drive solutions.
Chris Cocking specializes in scalable enterprise application design using multiple programming languages. With a nearly 20 years of experience, he excels in LAMP and IIS environments, SEO strategies, and most recently designing agentic systems. Outside of work, Chris is an avid bassist and music lover, which helps fuel his creativity and problem-solving skills.
