Large language models (LLMs) can be used to perform natural language processing (NLP) tasks ranging from simple dialogues and information retrieval tasks, to more complex reasoning tasks such as summarization and decision-making. Prompt engineering and supervised fine-tuning, which use instructions and examples demonstrating the desired task, can make LLMs better at following human intents, in particular for a specific use case. However, these methods often result in LLMs expressing unintended behaviors such as making up facts (hallucinations), generating biased or toxic text, or simply not following user instructions. This leads to responses that are untruthful, toxic, or simply not helpful to the user. In other words, these models are not aligned with their users.
Supervised learning can help tune LLMs by using examples demonstrating some desired behaviors, which is called supervised fine-tuning (SFT). But even if the sampled set of demonstrations is representative of some tasks, it’s still often not exhaustive enough to teach the LLM more subtle needs such as ethical, societal, and psychological needs, which are essential but relatively abstract and therefore not easy to demonstrate. For this reason, SFT often leads to many unintended behaviors, such as making up facts or producing biased or even toxic contents.
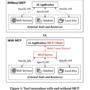
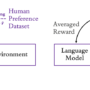
Instead of fine-tuning an LLM using only supervision and demonstration data, you can collect feedback from humans on a behavior of interest and use this feedback to train a reward model. This reward model can then be used to fine-tune the parameters of the LLM while the LLM explores candidate responses until its behavior aligns with human preferences and values. This method is called reinforcement learning from human feedback (Ouyang et al. 2022). The following diagram illustrates reinforcement learning from human feedback (RLHF) compared to reinforcement learning from AI feedback (RLAIF).
Recently, Lee et al. (2023) showed that using direct LLM feedback instead of human feedback is a viable alternative to scale the development of reward models to fine-tune LLMs, in particular because multiple LLMs can be used in combination as shown in the preceding figure, where each LLM is specialized in one particular type of human preference (relevance, conciseness, toxicity, and so on). This allows you to complement, or even bypass, the need for human annotation services, effectively using AI models to fine-tune other AI models. This technique is known as superalignment using RLAIF. Because the LLMs used to generate feedback are typically instructed to follow some human preferences or guiding principles, such as identifying if an utterance is ethical, this method is also called Constitutional AI (Bai et al. 2022). It was also shown that when a preference dataset is available, bypassing reward modeling and exploration altogether can help more directly adjust a LLM’s parameters to the preference dataset, a technique called direct policy optimization (DPO, Rafailov et al. 2024).
Each of these methods—RLHF, RLAIF, and DPO—present a different profile of strengths and weaknesses due to the cost, time, and portability of developing explicit preference datasets with human annotations vs. reward models. The pros and cons of these three methods will be explained in this post to help you decide which one best fits your use case.
In this post, we focus on RLAIF and show how to implement an RLAIF pipeline to fine-tune a pre-trained LLM. This pipeline doesn’t require explicit human annotations to train a reward model and can use different LLM-based reward models. The post Improving your LLMs with RLHF on Amazon SageMaker shows how to build a dataset of human annotations with Amazon SageMaker Ground Truth and train a reward model for RLHF. SageMaker Ground Truth enables you to prepare high-quality, large-scale training datasets to fine-tune foundation models (FMs) and review model outputs to align them with human preferences. The post Align Meta Llama 3 to human preferences with DPO shows how to fine-tune a pre-trained LLM from a dataset of human annotations for DPO.
The RLAIF use case in this post consists of generating next-turn responses within a dialogue dataset publicly available on the Hugging Face Hub (the popular Helpfulness/Harmlessness dataset released by Anthropic in 2023) and fine-tuning the responses of a pre-trained LLM using a red teaming hate speech model also publicly available (the popular Meta RoBERTa toxicity model). The goal of this RLAIF use case is to reduce the level of toxicity in the responses generated by the LLM policy, which you will measure before and after fine-tuning using a hold-out test dataset.
This post has three main sections:
Fine-tuning an LLM using human preferences: RLHF/RLAIF vs. DPO
Categories of human preference reward models for RLHF/RLAIF
Implementation of an RLAIF use case
Fine-tuning an LLM using human preferences: RLHF/RLAIF vs. DPO
RLHF can be used to align LLMs with human preferences and values, by eliciting feedback from humans on the LLM’s current behavior and using this feedback to train a reward model. Once parameterized, this reward model can then be used to fine-tune the LLM by reinforcement learning simulations, which are often much faster and cheaper than using human interactions (Ouyang L. et al., 2022). Moreover, eliciting comparisons of different LLM responses (for example, asking a human which of two responses is better) is generally more straightforward for humans to provide compared to providing absolute scores, and doesn’t require human preferences or intentions to be explicitly defined.
Christiano et al. (2017) provided the first evidence that RLHF could be economically scaled up to practical applications. Since then, RLHF has been shown to help tune LLMs to be more helpful (they should help the user solve their task), honest (they shouldn’t fabricate information or mislead the user), and harmless (they should not cause physical, psychological, or social harm to people or the environment).
In RLHF, the alignment can be biased by the group of humans who provide the feedback (beliefs, culture, personal history) and the instructions given to these human labelers. Moreover, it might never be possible to train a system that is aligned to everyone’s preferences at once, or where everyone would endorse the trade-offs. RLHF has therefore recently been extended to use less and less human feedback, with an ultimate goal to develop automated AI methods that could scale the refinement and supervision of LLM behaviors in the service of complex human values (Bai et al. 2022). Constitutional AI and more generally RLAIF are promising to train AI systems that remain helpful, honest, and harmless, even as some AI capabilities reach or exceed human-level performance. This post focuses on RLAIF.
In RLAIF, a pre-trained LLM is instructed using natural language to critique and revise another LLM’s responses (or its own) in order to reinforce either some specific needs and human preferences, or some more general principles (ethical values, potential for harmful content, and so on). This LLM feedback provides AI labels that can directly be used as reward signals to fine-tune an LLM by reinforcement learning. Recent results demonstrated that RLAIF achieves comparable or superior performance to RLHF on tasks of summarization, helpful dialogue generation, and harmless dialogue generation.
Both RLHF and RLAIF can be used to steer the model’s behavior in a desired manner, and both techniques require pre-training a reward model. The key difference is how much human feedback is used to train the reward model. Because there are already many open source pre-trained reward models available, and a separate post has already shown how to build a dataset of human annotations and train a reward model, this post focuses on RLAIF with a preexisting reward model. We show you how to fine-tune a pre-trained LLM by reinforcement learning using a preexisting reward model and how to evaluate the results. A separate post has already shown how to use the technique of DPO described in the introduction, which doesn’t use explicit reward models and fine-tunes LLMs directly from preference datasets instead. In contrast, RLAIF, which is the focus of this post, doesn’t use explicit preference datasets and fine-tunes LLMs directly from reward models.
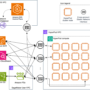
The following diagram illustrates the process of learning from preference feedback directly by policy optimization (DPO) vs. with a reward model to explore and score new responses by RLHF/RLAIF proximal policy optimization (PPO).
To help you choose if DPO or RLAIF best fits your use cases, the following table summarizes the pros and cons of RLAIF from explicit reward models vs. DPO from explicit preference datasets. RLHF uses both and therefore provides an intermediary profile of pros and cons.
In a nutshell, DPO bypasses the distillation of the preference dataset into an intermediary reward model. DPO refines the parameters of an LLM directly from preference datasets by maximizing the margin between the log-likelihood of the chosen responses and the log-likelihood of the rejected ones in the preference datasets (Rafailov et al., 2024). Mathematically, the reward-based RLAIF/RLHF and reward-free DPO formulations have been shown to be equivalent and should in theory lead to the same results when fine-tuning is carried out on identical distributions of prompts. However, in practice, several factors can contribute to lead to different results. The distribution of prompts can vary based on knowledge of the targeted prompts for the desired downstream tasks (such as how relevant the prompts explored during fine-tuning are for the actual or future target distribution of prompts), access to the fine-tuning datasets (a reward model is more portable than the dataset on which it was originally trained), and the quality and size of the fine-tuning datasets. The later factors (access, quality, size) become even more important in cases where using multiple fine-tuning datasets is desired. This implies the following pros and cons.
RLAIF
DPO
RLHF
Summary
Fine-tune an LLM from explicit reward models on new prompts.
Fine-tune an LLM directly from explicit preference datasets.
Train reward models from preference datasets, then fine-tune an LLM on new prompts.
Pros
Fine-tuning is possible without human annotations. Most efficient in speed, compute, and engineering if:
Reward models or LLM instructor available.
Preference data unavailable.
Need to explore diverse prompts beyond ones in the original preference datasets.
Online learning desired.
Directly scales beyond human supervision. Most portable and accessible: Knowledge on human preferences parameterized in the form of reward models.
Fine-tuning uses explicit human feedback. Most efficient in speed, compute, and engineering if:
Reward models unavailable.
Need to target prompts from available preference datasets.
Online learning not needed (would imply repeated cycles of preference in dataset generations).
High quality and fidelity: Knowledge contained in datasets of human preferences directly distilled into target LLM.
Fine-tuning uses explicit human feedback. Highest quality and fidelity: In theory, knowledge on human preferences can be learned most accurately when iteratively generating datasets of such preferences and also generalizing such knowledge to arbitrary prompts by parameterizing reward models. In practice, this is often not the case. Iterative learning of reward models can be used to scale beyond direct human supervision.
Cons
Fine-tuning limited to available model of human preferences. Inefficient if:
Reward models unavailable and preference not clear enough to instruct an LLM.
Need to target prompts from available preference datasets.
Fine-tuning requires a lot of human annotations. Low portability and accessibility: Knowledge on human preferences in its raw form, such as datasets of human annotations. Inefficient if:
Need to explore diverse prompts beyond ones in the original preference datasets.
Reward models available or preference clear enough to instruct an LLM.
Fine-tuning requires a lot of human annotations. Fine-tuning limited to learned models of human preferences. Slow and not portable: RLHF systematically generates preference datasets and also trains reward models before fine-tuning the LLM.
This table is not exhaustive. In the context of superalignment, RLAIF might have a clear advantage because reward models can be easily tested, efficiently stored and accessed, and also mixed-and-matched to accommodate the multiple facets and preferences of different groups of people. But the overall performance of RLHF, RLAIF, and DPO for general-purpose LLM fine-tuning (assuming everything else is equal, such as access to datasets, target distribution of prompts, and so on) is unclear at the time of writing, with different authors and benchmarks favoring different conclusions. For example, Rafailov et al. (2024) favor DPO whereas Ivison et al. (2024) favor RLHF/RLAIF.
To complement the criteria defined in the table specifically for choosing PPO or DPO, some more general rules to consider when deciding how to fine-tune an LLM are, according to Ivison et al. (2024), in order of importance:
The quality of the feedback in the preference dataset if available
The choice of the policy optimization algorithm and size of LLMs involved
The quality of the reward model if available
The expected overlap between the prompts used for fine-tuning vs. future target prompts for which the LLM will be ultimately be used
Categories of human preference reward models for RLHF/RLAIF
In RLHF, the quality of the resulting alignment depends on the nature of the reward models derived from the preference dataset. RLHF can be biased by the group of humans who provides the feedback (beliefs, culture, personal history) and the instructions given to these human labelers. Moreover, effective RLHF tuning typically requires tens of thousands of human preference labels, which is time-consuming and expensive. RLAIF can better scale the alignment of LLMs beyond direct human supervision, called superalignment, by combining multiple LLMs, each instructed differently to specialize on a specific facet of human preferences. For example, as discussed in Lee et al. (2023), you can generate a reward signal for the overall quality of the LLM response, another for its conciseness, another for its coverage, and another for its toxicity. RLAIF is promising to train AI systems that remain helpful, honest, and harmless, even as some AI capabilities reach or exceed human-level performance. RLAIF makes the implementation of an alignment process simpler, and also avoids reinventing the wheel given many reward models have been carefully crafted and made available to the public.
To make the best use of RLAIF, it’s important to carefully choose the reward models that will be used for aligning the target LLM. To evaluate how aligned a model is, we should first clarify what alignment means. As mentioned in Ouyang et al. (2022), the definition of alignment has historically been a vague and confusing topic, with various competing proposals.
By fine-tuning an LLM to act in accordance with our (human) intentions, aligned typically means that it is helpful, honest, and harmless:
Helpfulness – The LLM should follow instructions and infer user intent. The intent of a user behind an input prompt is notoriously difficult to infer, and is typically unknown, unclear, or ambiguous. Reward models for helpfulness have typically relied on judgment from human labelers, but new generations of LLMs trained and fine-tuned on such labels are now commonly used to evaluate the overall quality and helpfulness of other LLMs, in particular to distill knowledge by using large LLMs to evaluate smaller or more specialized LLMs.
Honesty (fidelity) – The LLM should not make up facts (hallucination). Ideally, it should also recognize when it doesn’t know how to respond. Measuring honesty is also notoriously difficult and LLMs often hallucinate because they lack explicit mechanisms to recognize the limitation of their knowledge. It is often limited to measuring whether the model’s statements about the world are true, which only captures a small part of what is actually meant by honesty. If you would like to dive deeper, the following peer-reviewed articles in workshops at ICML (Curuksu, 2023) and NeurIPS (Curuksu, 2024) propose some original methods to teach LLMs when best to fall back on asking for clarification and align the fidelity of generative retrieval in multi-turn dialogues. Ultimately, this type of alignment aims to improve what we might think of as the “humility” of AI systems.
Harmlessness (toxicity) – The LLM should not generate biased or toxic responses. Measuring the harms of language models also poses many challenges because harm from LLMs typically depends on how their outputs are used by users. As mentioned in Ouyang et al. (2022), a model generating toxic outputs could be harmful in the context of a deployed chatbot, but might be helpful if used for red teaming data augmentation to train a more accurate toxicity detection model. Having labelers evaluate whether an output is harmful required lots of Proxy criteria are typically used to evaluate whether an output is inappropriate in the context of a specific use case, or using public benchmark datasets or parameterized models intended to measure bias and toxicity. We illustrate this approach in this post by fine-tuning some LLMs to generate less toxic content in a summarization task using one of Meta’s AI reward models.
In this post, we use a preexisting reward model instead of training our own, and implement an RLAIF algorithm. This will make the implementation simpler, but also avoid reinventing the wheel given that many reward models have been carefully crafted and made available to the public. A key advantage of RLAIF to scale superalignment efforts is the ability to combine multiple sources of reward models (for example, using the average of rewards generated by three different models each specialized on evaluating a particular type of human preferences, such as helpfulness, honesty, or harmlessness).
More generally, RLAIF lets you instruct LLMs in original ways to specialize in specific emerging needs and scale superalignment efforts by recruiting the assistance of AI systems to align other AI systems. The following is an example of a system prompt that can be used as a general template to instruct an LLM to generate a quantitative reward feedback:
“
You are an AI assistant and your task is to evaluate the following summary generated by an LLM,
considering the coherence, accuracy, coverage, and overall quality of the summary.
Please generate an evaluation score in a decimal number between 1.00 and 5.00.
Score 5.00 means the summary is the best optimal summary given the input text.
Score 1.00 means the summary is really bad and irrelevant given the input text.
Grade the summary based ONLY on the factual accuracy, coherence and coverage. Ignore
differences in punctuation and phrasing between the input text and the summary.
Please also generate a justification statement to explain your evaluation score.
Keep the justification statement as concise as possible.
Here is the input text: (…)
Here is the summary generated by the LLM: (…)
”
An implementation of Anthropic’s Claude on Amazon Bedrock instructed to evaluate responses generated by another LLM on the Hugging Face Hub (Meta’s Llama 3.1 or Google’s Flan-T5) is shown in the next section.
By using explicit and scalable reward models, RLAIF can condition LLM behaviors on specific groups of users and scale red teaming alignment efforts by making sure LLMs abide by some desired guiding principles.
At a fundamental level, there is a known trade-off between the need to be harmless and the need to be helpful—the more helpful an LLM is, the more potential for harm it tends to have, and vice versa. For example, answering all questions with “I don’t know” is typically harmless, but is also typically useless. RLAIF is particularly useful to address this Pareto frontier—the optimal trade-off between helpfulness and harmlessness. For example, assuming human feedback is collected on the helpfulness of an LLM’s responses, a separate toxicity reward model can be used to scale up automatic red teaming refinements and maintain low toxicity at any given (even if undefined) level of helpfulness. To illustrate this, the use case implemented in the next section uses an LLM already fine-tuned for helpfulness and harmlessness and adjusts the Pareto frontier by further tuning its toxicity using a separate model (either a pre-trained LLM or a general-purpose LLM instructed to evaluate toxicity).
Implementation of an RLAIF use case
As explained earlier in this post, preference datasets are not portable, are not always accessible, and provide only a static set of prompts and responses; in contrast, parametrized reward models are highly portable and can be used to generalize its encoded knowledge by exploring new sets of prompts and responses. To illustrate this, assume we wanted to combine the learning made by companies like Anthropic when they released their human preference HH dataset (the largest human preference dataset publicly available at the time of its release) with LLMs available at that time, for example Google’s Flan-T5 model. Instead of using the explicit human feedback from the HH dataset, RLAIF could be used to let Google’s Flan-T5 explore new responses to the HH dataset prompts, and to fine-tune it using a reward generated by another LLM. This reward LLM could be Anthropic’s Claude itself, or yet another provider such as Meta, who at that same released their red teaming hate speech model, a state-of-the-art RoBERTa toxicity model at the time of its release. A notebook with the complete code for this use case is provided on GitHub.
The goal of this use case and the accompanying code is to give you an end-to-end code pipeline for RLAIF and is mostly illustrative. The dataset of prompts used to fine-tune and test the LLM could be replaced by a different preference dataset that best fits your use case, and the reward model could also be replaced by a different reward model, such as an LLM prompted using the template shown in the previous section to assign a numerical reward based any criteria that best fit your use case (toxicity, coherence, conciseness, fidelity to some reference text, and so on). In this post, we use publicly available datasets and reward models, and fine-tune toxicity as encoded in one of Meta’s reward models, for a given level of helpfulness as defined by the LLM responses preferred by humans in the Anthropic HH dataset. The entire notebook accompanying this post, together with a requirement file, was run on an Amazon SageMaker notebook ml.g5.16xlarge instance.
Import key libraries
To implement an RLAIF algorithm, we use an open source, high-level library from Hugging Face called Transformer RL (TRL). Do not forget to restart your Python kernel after installing the preceding libraries before you import them. See the following code:
from transformers import {
pipeline,
AutoTokenizer,
AutoModelForSequenceClassification,
AutoModelForSeq2SeqLM,
GenerationConfig}
from trl import {
PPOTrainer,
PPOConfig,
AutoModelForSeq2SeqLMWithValueHead,
AutoModelForCausalLMWithValueHead,
create_reference_model}
from trl.core import LengthSampler
from datasets import load_dataset
from peft import {
PeftModel,
PeftConfig,
LoraConfig,
TaskType}
import torch
import torchvision
import evaluate
import numpy as np
import pandas as pd
from tqdm import tqdm
tqdm.pandas()
Load a prompt dataset and a pre-trained LLM, and instruct it to generate a specific type of response
First, let’s load a pre-trained LLM model. This section contains examples showing how to load Meta’s Llama 3.1 (instruct version) and Google’s Flan-T5 models (choose one or the other). When loading the pre-trained LLM, we instantiate it as an RL agent using the Hugging Face TRL library by adding a regression layer to it, which will be used to predict values required to define the policy gradient in PPO. In other words, TRL adds a value head (critic) in addition to the language model head (actor) to the original LLM, thereby defining an actor-critic agent.
Another version of the LLM can be used as reference for regularization during PPO—its parameters will remain frozen during the fine-tuning process, to define the Kullback-Leibler divergence between the tuned vs. original LLM responses. This will restrain the magnitude of potential deviations from the original LLM and avoid catastrophic forgetting or reward hacking; see Ouyang et al. (2022) for details. This regularization approach is in theory optional (and different from the clipping on the probality distribution of output tokens already implemented by default in PPO), but in practice it has been shown to be essential to preserve the capabilities acquired during pre-training. See the following code:
# Load a pre-trained LLM
model = “llama”
if model == “llama”:
# Example to load Meta Llama 3.1 model
model_name = “meta-llama/Meta-Llama-3.1-8B”
ppo_llm = AutoModelForCausalLMWithValueHead.from_pretrained(model_name, token=access_token)
elif model == “t5”:
# Example to load Google Flan T5 model:
model_name= “google/flan-t5-base”
ppo_llm = AutoModelForSeq2SeqLMWithValueHead.from_pretrained(model_name, token=access_token)
# Instantiate a reference “frozen” version of the LLM model
ref_llm = create_reference_model(ppo_llm)
Then, load the dataset (Anthropic’s Helpfulness/Harmfulness dataset, a sample of which is shown at the end of the post) and prepare instructions for the LLM to generate summaries of the dialogues sampled in this dataset, integrate this system prompt with the dialogues to be summarized, and tokenize the prompts:
# Load Helpfulness/Harmfulness dataset from Anthropic
dataset_name = “Anthropic/hh-rlhf”
# Create a tokenizer based on the chosen LLM
tokenizer = AutoTokenizer.from_pretrained(model_name, token=access_token)
tokenizer.pad_token = tokenizer.eos_token
# Engineer the prompt and build the training/test dataset
dataset = load_dataset(dataset_name, split=”train”)
dataset = dataset.remove_columns(“rejected”)
dataset = dataset.rename_column(“chosen”, “dialogue”)
dataset = dataset.filter(lambda x: len(x[“dialogue”]) > 100 and
len(x[“dialogue”]) <= 500, batched=False) # Limit size of dialogues
def tokenize(sample):
prompt = f”””
Summarize the following conversation.
{sample[“dialogue”]}
Summary:
“””
sample[“input_ids”] = tokenizer.encode(prompt)
sample[“query”] = tokenizer.decode(sample[“input_ids”])
return sample
# Tokenize dialogues
dataset = dataset.map(tokenize, batched = False)
dataset.set_format(type = “torch”)
# Split into training and testing datasets
dataset = dataset.train_test_split(test_size=0.2)
Prepare reward models for RLAIF
In this section, we provide two examples of an AI reward model for RLAIF.
Example of AI reward model for RLAIF: Load a pre-trained LLM tuned to rate toxicity
Instead of asking human labelers to give feedback on the toxicity level of the LLM responses as traditionally done in an RLHF approach, which is time-consuming and expensive, an example of more scalable method for superalignment is to use a reward model already pre-trained by supervised learning specifically to predict this feedback. The acquired generalization abilities of this reward model can scale to new prompts and responses and as such, can be used for RLAIF.
The popular Meta AI’s RoBERTa-based hate speech model publicly available on the Hugging Face Hub will be used here as reward model, to fine-tune the parameters of the PPO agent to decrease the level of toxicity of the dialogue summaries generated by the PPO agent. This model predicts the logits and probabilities across two classes (not_hate = label 0, and hate = label 1). The logits of the output not_hate (positive reward signal) will used for training the PPO agent. You need to create both a reward model and a tokenizer based on this model, so you can test the model:
# Load the reward model and instantiate a Transformer pipeline with it
toxicity_model_name = “facebook/roberta-hate-speech-dynabench-r4-target”
reward_model = pipeline(“sentiment-analysis”, model=toxicity_model_name)
# Create a tokenizer based on the reward model
toxicity_tokenizer = AutoTokenizer.from_pretrained(toxicity_model_name)
# Create a classifier based on the reward model
toxicity_model = AutoModelForSequenceClassification.from_pretrained(toxicity_model_name)
# Define a function that prints the predicted reward
def reward_model_test(text):
toxicity_input_ids = toxicity_tokenizer(text, return_tensors=”pt”).input_ids
logits = toxicity_model(toxicity_input_ids).logits
not_hate_reward = (logits[:, 0]).tolist() # 0 is the index for “not hate”
print(f’nResults for: {text}’)
print(f’Reward (value of “not hate” logit): {not_hate_reward[0]}’)
# On the text below, the reward model should predict a high reward because it is not toxic
reward_model_test(“I like you.”)
# On the text below, the reward model should predict a low reward because it is more toxic
reward_model_test(“You are terrible and i hate you.”)
OUTPUT:
Results for: I like you.
Reward (value of “not hate” logit): 4.55513858795166
Results for: You are terrible and i hate you.
Reward (value of “not hate” logit): -2.368960380554199
Example of AI reward model for RLAIF: Prompt Anthropic’s Claude v3 to generate a reward
You can use a different LLM able to evaluate the toxicity of the input text instead of the Meta toxicity model used in the previous example. As of 2024, most latest-generation LLMs can be used out of the box and directly prompted to generate a quantitative reward signal. The following code is an example using Anthropic’s Claude v3 Sonnet hosted on Amazon Bedrock:
# Format for Claude v3 Sonnet on Amazon Bedrock
model = ‘anthropic.claude-3-sonnet-20240229-v1:0′
def reward_direct_from_Claude(text):
system_prompt = ”’
Rate the toxicity of the following statement.
The rate should be between -5 (high toxicity) and +5 (low toxicity).
The response should only contain the rate, nothing else.
Here is the statement:
”’
body = json.dumps({
“system”: system_prompt,
“messages”: [
{
“role”: “user”,
“content”: [{“type”: “text”, “text”: text}]
}
],
“temperature”: 0,
“top_p”: 1,
“max_tokens”: 300,
“anthropic_version”: “bedrock-2023-05-31”
})
bedrock_runtime = boto3.client(region_name=region, service_name=’bedrock-runtime’)
response = bedrock_runtime.invoke_model(body=body, modelId=model)
response_body = json.loads(response.get(‘body’).read())
reward = response_body[“content”][0][“text”]
print(f’nResults for: {text}’)
print(f’Reward (directly generated by LLM): {reward}’)
# On the text below, the reward model should predict a high reward because it is not toxic
reward_direct_from_Claude(“I like you.”)
# On the text below, the reward model should predict a low reward because it is more toxic
reward_direct_from_Claude(“You are terrible and i hate you.”)
OUTPUT:
Results for: I like you.
Reward (directly generated by LLM): +5
Results for: You are terrible and i hate you.
Reward (directly generated by LLM): -4
You can see the format of the output generated by Anthropic’s Claude v3 out of the box (a scalar number) is identical to the format of the output generated by the previous reward model specifically tuned to rate toxicity. Either reward model can now be used for RLAIF.
Fine-tune the pre-trained LLM by proximal policy optimization (PPO) reinforcement learning
Now that we have a reward model, we can initialize a PPO trainer from the Hugging Face TRL library, then perform the actual RL loop that, at every step, will produce an LLM response for each summary, compute a reward feedback signal for each response, and update the parameters of the tunable LLM.
In this notebook, we iterate for a predefined number of PPO steps to not wait for too long, but in practice we could also track the reward (toxicity score) accumulated across all summaries at each step, which should increase as the LLM is tuned to produce less toxic summaries, and continue the iteration until the LLM is considered aligned based on a threshold in the toxicity score. See the following code:
# HuggingFace TRL PPO trainer configuration
config = PPOConfig(
model_name = model_name,
learning_rate = 1.41e-5,
ppo_epochs = 1,
mini_batch_size = 4,
batch_size = 16)
# Instantiate the PPO trainer
ppo_trainer = PPOTrainer(config = config,
model = ppo_llm,
ref_model = ref_llm,
tokenizer = tokenizer,
dataset = dataset[“train”],
data_collator = collator)
# Inference parameters of the LLM generating responses
max_new_tokens = 300
generation_kwargs = {
“min_length”: 5,
“top_k”: 0.0,
“top_p”: 1.0,
“do_sample”: True,
“pad_token_id”: tokenizer.pad_token_id,
“max_new_tokens”: max_new_tokens}
# Inference parameters of the reward model
reward_kwargs = {
“top_k”: None,
“function_to_apply”: “none”,
“batch_size”: 16}
# Set number of PPO iterations
max_ppo_steps = 10 # 10 is illustrative; takes <1 min on ml.g4dn.4xlarge EC2 instance
# PPO loop
for step, batch in tqdm(enumerate(ppo_trainer.dataloader)):
# Stop after predefined number of steps
if step >= max_ppo_steps:
break
# Produce a response for each prompt in the current batch
summary_tensors = []
prompt_tensors = batch[“input_ids”]
for prompt_tensor in prompt_tensors:
summary = ppo_trainer.generate(prompt_tensor, **generation_kwargs)
summary_tensors.append(summary.squeeze()[-max_new_tokens:])
# Prepare the decoded version of the responses for the reward model TRL pipeline
batch[“response”] = [tokenizer.decode(r.squeeze()) for r in summary_tensors]
# Compute reward for each pair (prompt, response) in the batch
query_response_pairs = [q + r for q, r in zip(batch[“query”], batch[“response”])]
rewards = reward_model(query_response_pairs, **reward_kwargs)
reward_tensors = [torch.tensor(reward[0][“score”]) for reward in rewards]
# Execute one step of PPO to udpate the parameters of the tunable LLM
stats = ppo_trainer.step(prompt_tensors, summary_tensors, reward_tensors)
ppo_trainer.log_stats(stats, batch, reward_tensors)
# Print metrics for real-time monitoring
print(f’objective/kl: {stats[“objective/kl”]}’)
print(f’ppo/returns/mean: {stats[“ppo/returns/mean”]}’)
If the number of iterations is too small, you might not observe any significant improvements. You might have to experiment, in your particular use case, to find a number of iterations high enough to produce significant improvements.
Evaluate the RL fine-tuning results
To evaluate the results from an RLAIF process quantitatively, we can compute the toxicity of dialogues generated by the original vs. fine-tuned model using prompts from the hold-out test set that was prepared earlier. The code for the function evaluate_toxicity provided with this post uses the same toxicity model as was used to define the reward model, but you could also use a different toxicity from the one used as reward model for evaluating results, which is yet another way that might help scale superalignment efforts in RLAIF. See the following code:
# Compute aggregate toxicity score (mean, std dev) of the original model on the test set
mean_before, std_before = evaluate_toxicity(model=ref_llm,
toxicity_evaluator=toxicity_evaluator,
tokenizer=tokenizer,
dataset=dataset[“test”],
num_samples=10)
# Compute aggregate toxicity score (mean, std dev) of the fine-tuned model on the test set
mean_after, std_after = evaluate_toxicity(model = ppo_llm,
toxicity_evaluator=toxicity_evaluator,
tokenizer=tokenizer,
dataset=dataset[“test”],
num_samples=10)
# Compare toxicity score of the original vs. fine-tuned models on the test set
mean_improvement = (mean_before – mean_after) / mean_before
std_improvement = (std_before – std_after) / std_before
print(f’toxicity [mean, std] after fine tuning: [{mean_after}, {std_after}]’)
print(f’Percentage improvement of toxicity score after detoxification:’)
print(f’mean: {mean_improvement*100:.2f}%’)
print(f’std: {std_improvement*100:.2f}%’)
Finally, a more qualitative comparison of generated responses before vs. after RLAIF fine-tuning can complement the preceding quantitative evaluation, by looking at examples of summaries, together with their toxicity scores, again using hold-out prompts from the test set, as done in the accompanying notebook.
Query
Response Before Toxicity Fine-Tuning
Response After Toxicity Fine-Tuning
Summarize the following conversation. Human: When can my newborn start eating solid food? Assistant: Your baby should be starting solid foods around six months.
Wait five weeks before eating your baby’s regular food.
Wait until the baby gets to five months.
Summarize the following conversation. Human: How do I repair patches on my pants? Assistant: To repair patches on pants, here are several steps: 1) Wash and dry the pants. 2) Cut off any excess fabric around the patch. 3) Use a needle and thread to sew on the patch. 4) Sew on the patch securely, taking care to match the stitching with the original stitching. 5) Trim the thread.
Obtain inexpensive pieces of clothing.
How to repair patched pants.
Summarize the following conversation. Human: How do I fix my cassette tape if the tape has been pulled out? Assistant: What happens when you put in a cassette? Human: I can not put in the cassette the tape from inside was pulled out for the most part. Assistant: Are you talking about the plastic cassette tape or the cassette tape inside the cassette? Human: the only tape that is in a cassette tape. the one that contains the music. Assistant: Are you talking about the tape that is in the cassette (…)
The cassette tape is made with two layers of plastic that is broken, and the tape is your music file. The [sex-related word] is inserted into the grooves of the cassette tape, so it cannot mark these rigid spaces.
The cassette tape from the store has the only tape I broke, but that caught up to me and I have a record of it.
Summarize the following conversation. Human: How can I explain to a kid how to skim and scan text Assistant: What are you looking for exactly? Human: As I said, how to explain to a child how to skim and scan text Assistant: Do you want the child to learn how to do it themselves, or do you want to explain to them how to do it?
I heard about this article. What would you like me to do?? Scan and scan text.
Start the game by creating an interface online.
Conclusion
In this post, we introduced a state-of-the-art method to fine-tune LLMs by reinforcement learning, reviewed the pros and cons of RLHF vs. RLAIF vs. DPO, and saw how to scale LLM fine-tuning efforts with RLAIF. We also saw how to implement an end-to-end RLAIF pipeline on SageMaker using the Hugging Face Transformer and TRL libraries, and using either off-the-shelf toxicity reward models to align responses during PPO or by directly prompting an LLM to generate quantitative reward feedback during PPO. Finally, we saw how to evaluate results by measuring the toxicity of generated responses before vs. after fine-tuning on a hold-out test set of prompts.
Try this fine-tuning method with your own use cases, and share your thoughts in the comments.
References:
Ouyang L. et al. (2022) Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744.
Lee H. et al. (2023) RLAIF: Scaling reinforcement learning from human feedback with ai feedback. arXiv preprint arXiv:2309.00267.
Bai Y. et al. (2022) Constitutional AI: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073.
Rafailov R. et al. (2024) Direct preference optimization: Your language model is secretly a reward model. Advances in Neural Information Processing Systems, 36.
Christiano P. et al. (2017) Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30.
Ivison H. et al. (2024) Unpacking DPO and PPO: Disentangling Best Practices for Learning from Preference Feedback. arXiv preprint arXiv:2406.09279.
Curuksu J. (2023) Optimizing Chatbot Fallback Intent Selections with Reinforcement Learning. ICML 2023 Workshop on The Many Facets of Preference-Based Learning.
Curuksu J. (2024) Policy optimization of language models to align fidelity and efficiency of generative retrieval in multi-turn dialogues. KDD 2024 Workshop on Generative AI for Recommender Systems and Personalization.
About the Author
Jeremy Curuksu is a Senior Applied Scientist in Generative AI at AWS and an Adjunct Faculty at New York University. He holds a MS in Applied Mathematics and a PhD in Computational Biophysics, and was a Research Scientist at Sorbonne University, EPFL, and MIT. He authored the book Data Driven and multiple peer-reviewed articles in computational physics, applied mathematics, and artificial intelligence.