Data science teams often face challenges when transitioning models from the development environment to production. These include difficulties integrating data science team’s models into the IT team’s production environment, the need to retrofit data science code to meet enterprise security and governance standards, gaining access to production grade data, and maintaining repeatability and reproducibility in machine learning (ML) pipelines, which can be difficult without a proper platform infrastructure and standardized templates.
This post, part of the “Governing the ML lifecycle at scale” series (Part 1, Part 2, Part 3), explains how to set up and govern a multi-account ML platform that addresses these challenges. The platform provides self-service provisioning of secure environments for ML teams, accelerated model development with predefined templates, a centralized model registry for collaboration and reuse, and standardized model approval and deployment processes.
An enterprise might have the following roles involved in the ML lifecycles. The functions for each role can vary from company to company. In this post, we assign the functions in terms of the ML lifecycle to each role as follows:
Lead data scientist – Provision accounts for ML development teams, govern access to the accounts and resources, and promote standardized model development and approval process to eliminate repeated engineering effort. Usually, there is one lead data scientist for a data science group in a business unit, such as marketing.
Data scientists – Perform data analysis, model development, model evaluation, and registering the models in a model registry.
ML engineers – Develop model deployment pipelines and control the model deployment processes.
Governance officer – Review the model’s performance including documentation, accuracy, bias and access, and provide final approval for models to be deployed.
Platform engineers – Define a standardized process for creating development accounts that conform to the company’s security, monitoring, and governance standards; create templates for model development; and manage the infrastructure and mechanisms for sharing model artifacts.
This ML platform provides several key benefits. First, it enables every step in the ML lifecycle to conform to the organization’s security, monitoring, and governance standards, reducing overall risk. Second, the platform gives data science teams the autonomy to create accounts, provision ML resources and access ML resources as needed, reducing resource constraints that often hinder their work.
Additionally, the platform automates many of the repetitive manual steps in the ML lifecycle, allowing data scientists to focus their time and efforts on building ML models and discovering insights from the data rather than managing infrastructure. The centralized model registry also promotes collaboration across teams, enables centralized model governance, increasing visibility into models developed throughout the organization and reducing duplicated work.
Finally, the platform standardizes the process for business stakeholders to review and consume models, smoothing the collaboration between the data science and business teams. This makes sure models can be quickly tested, approved, and deployed to production to deliver value to the organization.
Overall, this holistic approach to governing the ML lifecycle at scale provides significant benefits in terms of security, agility, efficiency, and cross-functional alignment.
In the next section, we provide an overview of the multi-account ML platform and how the different roles collaborate to scale MLOps.
Solution overview
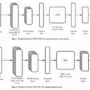
The following architecture diagram illustrates the solutions for a multi-account ML platform and how different personas collaborate within this platform.
There are five accounts illustrated in the diagram:
ML Shared Services Account – This is the central hub of the platform. This account manages templates for setting up new ML Dev Accounts, as well as SageMaker Projects templates for model development and deployment, in AWS Service Catalog. It also hosts a model registry to store ML models developed by data science teams, and provides a single location to approve models for deployment.
ML Dev Account – This is where data scientists perform their work. In this account, data scientists can create new SageMaker notebooks based on the needs, connect to data sources such as Amazon Simple Storage Service (Amazon S3) buckets, analyze data, build models and create model artifacts (for example, a container image), and more. The SageMaker projects, provisioned using the templates in the ML Shared Services Account, can speed up the model development process because it has steps (such as connecting to an S3 bucket) configured. The diagram shows one ML Dev Account, but there can be multiple ML Dev Accounts in an organization.
ML Test Account – This is the test environment for new ML models, where stakeholders can review and approve models before deployment to production.
ML Prod Account – This is the production account for new ML models. After the stakeholders approve the models in the ML Test Account, the models are automatically deployed to this production account.
Data Governance Account – This account hosts data governance services for data lake, central feature store, and fine-grained data access.
Key activities and actions are numbered in the preceding diagram. Some of these activities are performed by various personas, whereas others are automatically triggered by AWS services.
ML engineers create the pipelines in Github repositories, and the platform engineer converts them into two different Service Catalog portfolios: ML Admin Portfolio and SageMaker Project Portfolio. The ML Admin Portfolio will be used by the lead data scientist to create AWS resources (for example, SageMaker domains). The SageMaker Project Portfolio has SageMaker projects that data scientists and ML engineers can use to accelerate model training and deployment.
The platform engineer shares the two Service Catalog portfolios with workload accounts in the organization.
Data engineer prepares and governs datasets using services such as Amazon S3, AWS Lake Formation, and Amazon DataZone for ML.
The lead data scientist uses the ML Admin Portfolio to set up SageMaker domains and the SageMaker Project Portfolio to set up SageMaker projects for their teams.
Data scientists subscribe to datasets, and use SageMaker notebooks to analyze data and develop models.
Data scientists use the SageMaker projects to build model training pipelines. These SageMaker projects automatically register the models in the model registry.
The lead data scientist approves the model locally in the ML Dev Account.
This step consists of the following sub-steps:
After the data scientists approve the model, it triggers an event bus in Amazon EventBridge that ships the event to the ML Shared Services Account.
The event in EventBridge triggers the AWS Lambda function that copies model artifacts (managed by SageMaker, or Docker images) from the ML Dev Account into the ML Shared Services Account, creates a model package in the ML Shared Services Account, and registers the new model in the model registry in the ML Shared Services account.
ML engineers review and approve the new model in the ML Shared Services account for testing and deployment. This action triggers a pipeline that was set up using a SageMaker project.
The approved models are first deployed to the ML Test Account. Integration tests will be run and endpoint validated before being approved for production deployment.
After testing, the governance officer approves the new model in the CodePipeline.
After the model is approved, the pipeline will continue to deploy the new model into the ML Prod Account, and creates a SageMaker endpoint.
The following sections provide details on the key components of this diagram, how to set them up, and sample code.
Set up the ML Shared Services Account
The ML Shared Services Account helps the organization standardize management of artifacts and resources across data science teams. This standardization also helps enforce controls across resources consumed by data science teams.
The ML Shared Services Account has the following features:
Service Catalog portfolios – This includes the following portfolios:
ML Admin Portfolio – This is intended to be used by the project admins of the workload accounts. It is used to create AWS resources for their teams. These resources can include SageMaker domains, Amazon Redshift clusters, and more.
SageMaker Projects Portfolio – This portfolio contains the SageMaker products to be used by the ML teams to accelerate their ML models’ development while complying with the organization’s best practices.
Central model registry – This is the centralized place for ML models developed and approved by different teams. For details on setting this up, refer to Part 2 of this series.
The following diagram illustrates this architecture.
As the first step, the cloud admin sets up the ML Shared Services Account by using one of the blueprints for customizations in AWS Control Tower account vending, as described in Part 1.
In the following sections, we walk through how to set up the ML Admin Portfolio. The same steps can be used to set up the SageMaker Projects Portfolio.
Bootstrap the infrastructure for two portfolios
After the ML Shared Services Account has been set up, the ML platform admin can bootstrap the infrastructure for the ML Admin Portfolio using sample code in the GitHub repository. The code contains AWS CloudFormation templates that can be later deployed to create the SageMaker Projects Portfolio.
Complete the following steps:
Clone the GitHub repo to a local directory:
git clone https://github.com/aws-samples/data-and-ml-governance-workshop.git
Change the directory to the portfolio directory:
cd data-and-ml-governance-workshop/module-3/ml-admin-portfolio
Install dependencies in a separate Python environment using your preferred Python packages manager:
python3 -m venv env
source env/bin/activate pip
install -r requirements.txt
Bootstrap your deployment target account using the following command:
cdk bootstrap aws://<target account id>/<target region> –profile <target account profile>
If you already have a role and AWS Region from the account set up, you can use the following command instead:
cdk bootstrap
Lastly, deploy the stack:
cdk deploy –all –require-approval never
When it’s ready, you can see the MLAdminServicesCatalogPipeline pipeline in AWS CloudFormation.
Navigate to AWS CodeStar Connections of the Service Catalog page, you can see there’s a connection named “codeconnection-service-catalog”. If you click the connection, you will notice that we need to connect it to GitHub to allow you to integrate it with your pipelines and start pushing code. Click the ‘Update pending connection’ to integrate with your GitHub account.
Once that is done, you need to create empty GitHub repositories to start pushing code to. For example, you can create a repository called “ml-admin-portfolio-repo”. Every project you deploy will need a repository created in GitHub beforehand.
Trigger CodePipeline to deploy the ML Admin Portfolio
Complete the following steps to trigger the pipeline to deploy the ML Admin Portfolio. We recommend creating a separate folder for the different repositories that will be created in the platform.
Get out of the cloned repository and create a parallel folder called platform-repositories:
cd ../../.. # (as many .. as directories you have moved in)
mkdir platform-repositories
Clone and fill the empty created repository:
cd platform-repositories
git clone https://github.com/example-org/ml-admin-service-catalog-repo.git
cd ml-admin-service-catalog-repo
cp -aR ../../ml-platform-shared-services/module-3/ml-admin-portfolio/. .
Push the code to the Github repository to create the Service Catalog portfolio:
git add .
git commit -m “Initial commit”
git push -u origin main
After it is pushed, the Github repository we created earlier is no longer empty. The new code push triggers the pipeline named cdk-service-catalog-pipeline to build and deploy artifacts to Service Catalog.
It takes about 10 minutes for the pipeline to finish running. When it’s complete, you can find a portfolio named ML Admin Portfolio on the Portfolios page on the Service Catalog console.
Repeat the same steps to set up the SageMaker Projects Portfolio, make sure you’re using the sample code (sagemaker-projects-portfolio) and create a new code repository (with a name such as sm-projects-service-catalog-repo).
Share the portfolios with workload accounts
You can share the portfolios with workload accounts in Service Catalog. Again, we use ML Admin Portfolio as an example.
On the Service Catalog console, choose Portfolios in the navigation pane.
Choose the ML Admin Portfolio.
On the Share tab, choose Share.
In the Account info section, provide the following information:
For Select how to share, select Organization node.
Choose Organizational Unit, then enter the organizational unit (OU) ID of the workloads OU.
In the Share settings section, select Principal sharing.
Choose Share.Selecting the Principal sharing option allows you to specify the AWS Identity and Access Management (IAM) roles, users, or groups by name for which you want to grant permissions in the shared accounts.
On the portfolio details page, on the Access tab, choose Grant access.
For Select how to grant access, select Principal Name.
In the Principal Name section, choose role/ for Type and enter the name of the role that the ML admin will assume in the workload accounts for Name.
Choose Grant access.
Repeat these steps to share the SageMaker Projects Portfolio with workload accounts.
Confirm available portfolios in workload accounts
If the sharing was successful, you should see both portfolios available on the Service Catalog console, on the Portfolios page under Imported portfolios.
Now that the service catalogs in the ML Shared Services Account have been shared with the workloads OU, the data science team can provision resources such as SageMaker domains using the templates and set up SageMaker projects to accelerate ML models’ development while complying with the organization’s best practices.
We demonstrated how to create and share portfolios with workload accounts. However, the journey doesn’t stop here. The ML engineer can continue to evolve existing products and develop new ones based on the organization’s requirements.
The following sections describe the processes involved in setting up ML Development Accounts and running ML experiments.
Set up the ML Development Account
The ML Development account setup consists of the following tasks and stakeholders:
The team lead requests the cloud admin to provision the ML Development Account.
The cloud admin provisions the account.
The team lead uses shared Service Catalog portfolios to provisions SageMaker domains, set up IAM roles and give access, and get access to data in Amazon S3, or Amazon DataZone or AWS Lake Formation, or a central feature group, depending on which solution the organization decides to use.
Run ML experiments
Part 3 in this series described multiple ways to share data across the organization. The current architecture allows data access using the following methods:
Option 1: Train a model using Amazon DataZone – If the organization has Amazon DataZone in the central governance account or data hub, a data publisher can create an Amazon DataZone project to publish the data. Then the data scientist can subscribe to the Amazon DataZone published datasets from Amazon SageMaker Studio, and use the dataset to build an ML model. Refer to the sample code for details on how to use subscribed data to train an ML model.
Option 2: Train a model using Amazon S3 – Make sure the user has access to the dataset in the S3 bucket. Follow the sample code to run an ML experiment pipeline using data stored in an S3 bucket.
Option 3: Train a model using a data lake with Athena – Part 2 introduced how to set up a data lake. Follow the sample code to run an ML experiment pipeline using data stored in a data lake with Amazon Athena.
Option 4: Train a model using a central feature group – Part 2 introduced how to set up a central feature group. Follow the sample code to run an ML experiment pipeline using data stored in a central feature group.
You can choose which option to use depending on your setup. For options 2, 3, and 4, the SageMaker Projects Portfolio provides project templates to run ML experiment pipelines, steps including data ingestion, model training, and registering the model in the model registry.
In the following example, we use option 2 to demonstrate how to build and run an ML pipeline using a SageMaker project that was shared from the ML Shared Services Account.
On the SageMaker Studio domain, under Deployments in the navigation pane, choose Projects
Choose Create project.
There is a list of projects that serve various purposes. Because we want to access data stored in an S3 bucket for training the ML model, choose the project that uses data in an S3 bucket on the Organization templates tab.
Follow the steps to provide the necessary information, such as Name, Tooling Account(ML Shared Services account id), S3 bucket(for MLOPS) and then create the project.
It takes a few minutes to create the project.
After the project is created, a SageMaker pipeline is triggered to perform the steps specified in the SageMaker project. Choose Pipelines in the navigation pane to see the pipeline.You can choose the pipeline to see the Directed Acyclic Graph (DAG) of the pipeline. When you choose a step, its details show in the right pane.
The last step of the pipeline is registering the model in the current account’s model registry. As the next step, the lead data scientist will review the models in the model registry, and decide if a model should be approved to be promoted to the ML Shared Services Account.
Approve ML models
The lead data scientist should review the trained ML models and approve the candidate model in the model registry of the development account. After an ML model is approved, it triggers a local event, and the event buses in EventBridge will send model approval events to the ML Shared Services Account, and the artifacts of the models will be copied to the central model registry. A model card will be created for the model if it’s a new one, or the existing model card will update the version.
The following architecture diagram shows the flow of model approval and model promotion.
Model deployment
After the previous step, the model is available in the central model registry in the ML Shared Services Account. ML engineers can now deploy the model.
If you had used the sample code to bootstrap the SageMaker Projects portfolio, you can use the Deploy real-time endpoint from ModelRegistry – Cross account, test and prod option in SageMaker Projects to set up a project to set up a pipeline to deploy the model to the target test account and production account.
On the SageMaker Studio console, choose Projects in the navigation pane.
Choose Create project.
On the Organization templates tab, you can view the templates that were populated earlier from Service Catalog when the domain was created.
Select the template Deploy real-time endpoint from ModelRegistry – Cross account, test and prod and choose Select project template.
Fill in the template:
The SageMakerModelPackageGroupName is the model group name of the model promoted from the ML Dev Account in the previous step.
Enter the Deployments Test Account ID for PreProdAccount, and the Deployments Prod Account ID for ProdAccount.
The pipeline for deployment is ready. The ML engineer will review the newly promoted model in the ML Shared Services Account. If the ML engineer approves model, it will trigger the deployment pipeline. You can see the pipeline on the CodePipeline console.
The pipeline will first deploy the model to the test account, and then pause for manual approval to deploy to the production account. ML engineer can test the performance and Governance officer can validate the model results in the test account. If the results are satisfactory, Governance officer can approve in CodePipeline to deploy the model to production account.
Conclusion
This post provided detailed steps for setting up the key components of a multi-account ML platform. This includes configuring the ML Shared Services Account, which manages the central templates, model registry, and deployment pipelines; sharing the ML Admin and SageMaker Projects Portfolios from the central Service Catalog; and setting up the individual ML Development Accounts where data scientists can build and train models.
The post also covered the process of running ML experiments using the SageMaker Projects templates, as well as the model approval and deployment workflows. Data scientists can use the standardized templates to speed up their model development, and ML engineers and stakeholders can review, test, and approve the new models before promoting them to production.
This multi-account ML platform design follows a federated model, with a centralized ML Shared Services Account providing governance and reusable components, and a set of development accounts managed by individual lines of business. This approach gives data science teams the autonomy they need to innovate, while providing enterprise-wide security, governance, and collaboration.
We encourage you to test this solution by following the AWS Multi-Account Data & ML Governance Workshop to see the platform in action and learn how to implement it in your own organization.
About the authors
Jia (Vivian) Li is a Senior Solutions Architect in AWS, with specialization in AI/ML. She currently supports customers in financial industry. Prior to joining AWS in 2022, she had 7 years of experience supporting enterprise customers use AI/ML in the cloud to drive business results. Vivian has a BS from Peking University and a PhD from University of Southern California. In her spare time, she enjoys all the water activities, and hiking in the beautiful mountains in her home state, Colorado.
Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 3 decades of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure, scalable, reliable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he enjoys riding motorcycle and walking with his dogs.
Dr. Alessandro Cerè is a GenAI Evaluation Specialist and Solutions Architect at AWS. He assists customers across industries and regions in operationalizing and governing their generative AI systems at scale, ensuring they meet the highest standards of performance, safety, and ethical considerations. Bringing a unique perspective to the field of AI, Alessandro has a background in quantum physics and research experience in quantum communications and quantum memories. In his spare time, he pursues his passion for landscape and underwater photography.
Alberto Menendez is a DevOps Consultant in Professional Services at AWS. He helps accelerate customers’ journeys to the cloud and achieve their digital transformation goals. In his free time, he enjoys playing sports, especially basketball and padel, spending time with family and friends, and learning about technology.
Sovik Kumar Nath is an AI/ML and Generative AI senior solution architect with AWS. He has extensive experience designing end-to-end machine learning and business analytics solutions in finance, operations, marketing, healthcare, supply chain management, and IoT. He has double masters degrees from the University of South Florida, University of Fribourg, Switzerland, and a bachelors degree from the Indian Institute of Technology, Kharagpur. Outside of work, Sovik enjoys traveling, taking ferry rides, and watching movies.
Viktor Malesevic is a Senior Machine Learning Engineer within AWS Professional Services, leading teams to build advanced machine learning solutions in the cloud. He’s passionate about making AI impactful, overseeing the entire process from modeling to production. In his spare time, he enjoys surfing, cycling, and traveling.