Troubleshooting infrastructure as code (IaC) errors often consumes valuable time and resources. Developers can spend multiple cycles searching for solutions across forums, troubleshooting repetitive issues, or trying to identify the root cause. These delays can lead to missed security errors or compliance violations, especially in complex, multi-account environments.
This post demonstrates how you can use Amazon Bedrock Agents to create an intelligent solution to streamline the resolution of Terraform and AWS CloudFormation code issues through context-aware troubleshooting. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI. Amazon Bedrock Agents is a fully managed service that helps developers create AI agents that can break down complex tasks into steps and execute them using FMs and APIs to accomplish specific business objectives.
Our solution uses Amazon Bedrock Agents to analyze error messages and code context, generating detailed troubleshooting steps for IaC errors. In organizations with multi-account AWS environments, teams often maintain a centralized AWS environment for developers to deploy applications. This setup makes sure that AWS infrastructure deployments using IaC align with organizational security and compliance measures. For specific IaC errors related to these compliance measures, such as those involving service control policies (SCPs) or resource-based policies, our solution intelligently directs developers to contact appropriate teams like Security or Enablement. This targeted guidance maintains security protocols and makes sure that sensitive issues are handled by the right experts. The solution is flexible and can be adapted for similar use cases beyond these examples.
Although we focus on Terraform Cloud workspaces in this example, the same principles apply to GitLab CI/CD pipelines or other continuous integration and delivery (CI/CD) approaches executing IaC code. By automating initial error analysis and providing targeted solutions or guidance, you can improve operational efficiency and focus on solving complex infrastructure challenges within your organization’s compliance framework.
Solution overview
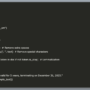
Before we dive into the deployment process, let’s walk through the key steps of the architecture as illustrated in the following figure.
The workflow for the Terraform solution is as follows:
Initial input through the Amazon Bedrock Agents chat console – The user begins by entering details about their Terraform error into the chat console for Amazon Bedrock Agents. This typically includes the Terraform Cloud workspace URL where the error occurred, and optionally, a Git repository URL and branch name if additional context is needed.
Error retrieval and context gathering – The Amazon Bedrock agent forwards these details to an action group that invokes the first AWS Lambda function (see the following Lambda function code). This function invokes another Lambda function (see the following Lambda function code) which retrieves the latest error message from the specified Terraform Cloud workspace. If a Git repository URL is provided, it also retrieves relevant Terraform files from the repository. This contextual information is then sent back to the first Lambda function.
Error analysis and response generation – Lambda function would then construct a detailed prompt that includes the error message, repository files (if available), and specific use case instructions. It then uses the Amazon Bedrock model to analyze the error and generate either troubleshooting steps or guidance to contact specific teams.
Interaction and user guidance – The agent displays the generated response to the user. For most Terraform errors, this includes detailed troubleshooting steps. For specific cases related to organizational policies (for example, service control policies or resource-based policies), the response directs the user to contact the appropriate team, such as Security or Enablement.
Continuous improvement – The solution can be continually updated with new specific use cases and organizational guidelines, making sure that the troubleshooting advice stays current with the organization’s evolving infrastructure and compliance requirements. For example:
SCP or IAM policy violations – Guides developers when they encounter permission issues due to SCPs or strict AWS Identity and Access Management (IAM) boundaries, offering alternatives or escalation paths.
VPC and networking restrictions – Flags non-compliant virtual private cloud (VPC) or subnet configurations (such as public subnets) and suggests security-compliant adjustments.
Encryption requirements – Detects missing or incorrect encryption for Amazon Simple Storage Service (Amazon S3) or Amazon Elastic Block Store (Amazon EBS) resources and recommends the appropriate configurations to align with compliance standards.
The following diagram illustrates the step-by-step process of how the solution works.
This solution streamlines the process of resolving Terraform errors, providing immediate, context-aware guidance to developers while making sure that sensitive or complex issues are directed to the appropriate teams. By using the capabilities of Amazon Bedrock Agents, it offers a scalable and intelligent approach to managing IaC challenges in large, multi-account AWS environments.
Prerequisites
To implement the solution, you need the following:
An understanding of Amazon Bedrock Agents, prompt engineering, Amazon Bedrock Knowledge Bases, Lambda functions, and IAM
An AWS account with appropriate IAM permissions to create agents and knowledge bases in Amazon Bedrock, Lambda functions, and IAM roles
A service role created for Amazon Bedrock Agents
Model access enabled for Amazon Bedrock
A GitLab account with a repository and a personal access token to access the repository
Create the Amazon Bedrock agent
To create and configure the Amazon Bedrock agent, complete the following steps:
On the Amazon Bedrock console, choose Agents in the navigation pane.
Choose Create agent.
Provide agent details, including agent name and description (optional).
Grant the agent permissions to AWS services through the IAM service role. This gives your agent access to required services, such as Lambda.
Select an FM from Amazon Bedrock (such as Anthropic’s Claude 3 Sonnet).
For troubleshooting Terraform errors through Amazon Bedrock Agents, attach the following instruction to the agent. This instruction makes sure that the agent gathers the required input from the user and executes the action group to provide detailed troubleshooting steps.
“You are a terraform code error specialist. Greet the user and ask for terraform workspace url, branch name, code repository url. Once received, trigger troubleshooting action group. Provide the troubleshooting steps to the user.”
Configure the Lambda function for the action group
After you configure the initial agent and add the preceding instruction to the agent, you need to create two Lambda functions:
The first Lambda function will be added to the action group, which is invoked by the Amazon Bedrock agent, and will subsequently trigger the second Lambda function using the invoke method. Refer to the Lambda function code for more details. Make sure the LAMBDA_2_FUNCTION_NAME environment variable is set.
The second Lambda function will handle fetching the Terraform workspace error and the associated Terraform code from GitLab. Refer to the Lambda function code. Make sure that the TERRAFORM_API_URL, TERRAFORM_SECRET_NAME, and VCS_SECRET_NAME environment variables are set.
After the Terraform workspace error and code details are retrieved, these details will be passed back to the first Lambda function, which will use the Amazon Bedrock API with an FM to generate and provide the appropriate troubleshooting steps based on the error and code information.
Add the action group to the Amazon Bedrock agent
Complete the following steps to add the action group to the Amazon Bedrock agent:
Add an action group to the Amazon Bedrock agent.
Assign a descriptive name (for example, troubleshooting) to the action group and provide a description. This helps clarify the purpose of the action group within the workflow.
For Action group type, select Define with function details.
For more details, see Define function details for your agent’s action groups in Amazon Bedrock.
For Action group invocation, choose the first Lambda function that you created previously.
This function runs the business logic required when an action is invoked. Make sure to choose the correct version of the first Lambda function. For more details on how to configure Lambda functions for action groups, see Configure Lambda functions to send information that an Amazon Bedrock agent elicits from the user.
For Action group function 1, provide a name and description.
Add the following parameters.
Name
Description
Type
Required
workspace_url
Terraform workspace url
string
True
repo_url
Code repository URL
string
True
branch_name
Code repository branch name
string
True
Test the solution
The following example is of a Terraform error due to a service control polcy. The troubleshooting steps provided would be aligned to address those specific constraints. The action group triggers the Lambda function, which follows structured single-shot prompting by passing the complete context—such as the error message and repository contents—in a single input to the Amazon Bedrock model to generate precise troubleshooting steps.
Example 1: The following screenshot shows an example of a Terraform error caused by an SCP limitation managed by the security team.
The following screenshot shows an example of the user interaction with Amazon Bedrock Agents and the troubleshooting steps provided.
Example 2: The following screenshot shows an example of a Terraform error due to a missing variable value.
The following screenshot shows an example of the user interaction with Amazon Bedrock Agents and the troubleshooting steps provided.
Clean up
The services used in this demo can incur costs. Complete the following steps to clean up your resources:
Delete the Lambda functions if they are no longer required.
Delete the action group and Amazon Bedrock agent you created.
Conclusion
IaC offers flexibility for managing cloud environments, but troubleshooting code errors can be time-consuming, especially in environments with strict organizational guardrails. This post demonstrated how Amazon Bedrock Agents, combined with action groups and generative AI models, streamlines and accelerates the resolution of Terraform errors while maintaining compliance with environment security and operational guidelines.
Using the capabilities of Amazon Bedrock Agents, developers can receive context-aware troubleshooting steps tailored to environment-related issues such as SCP or IAM violations, VPC restrictions, and encryption policies. The solution provides specific guidance based on the error’s context and directs users to the appropriate teams for issues that require further escalation. This reduces the time spent on IaC errors, improves developer productivity, and maintains organizational compliance.
Are you ready to streamline your cloud deployment process with the generative AI of Amazon Bedrock? Start by exploring the Amazon Bedrock User Guide to see how it can facilitate your organization’s transition to the cloud. For specialized assistance, consider engaging with AWS Professional Services to maximize the efficiency and benefits of using Amazon Bedrock.
About the Authors
Akhil Raj Yallamelli is a Cloud Infrastructure Architect at AWS, specializing in architecting cloud infrastructure solutions for enhanced data security and cost efficiency. He is experienced in integrating technical solutions with business strategies to create scalable, reliable, and secure cloud environments. Akhil enjoys developing solutions focusing on customer business outcomes, incorporating generative AI (Gen AI) technologies to drive innovation and cloud enablement. He holds an MS degree in Computer Science. Outside of his professional work, Akhil enjoys watching and playing sports.
Ebbey Thomas is a Senior Generative AI Specialist Solutions Architect at AWS. He designs and implements generative AI solutions that address specific customer business problems. He is recognized for simplifying complexity and delivering measurable business outcomes for clients. Ebbey holds a BS in Computer Engineering and an MS in Information Systems from Syracuse University.