
In production generative AI applications, responsiveness is just as important as the intelligence behind the model. Whether it’s customer service teams handling time-sensitive inquiries or developers needing instant code suggestions, every second of delay, known as latency, can have a significant impact. As businesses increasingly use large language models (LLMs) for these critical tasks and processes, they face a fundamental challenge: how to maintain the quick, responsive performance users expect while delivering the high-quality outputs these sophisticated models promise.
The impact of latency on user experience extends beyond mere inconvenience. In interactive AI applications, delayed responses can break the natural flow of conversation, diminish user engagement, and ultimately affect the adoption of AI-powered solutions. This challenge is compounded by the increasing complexity of modern LLM applications, where multiple LLM calls are often needed to solve a single problem, significantly increasing total processing times.
During re:Invent 2024, we launched latency-optimized inference for foundation models (FMs) in Amazon Bedrock. This new inference feature provides reduced latency for Anthropic’s Claude 3.5 Haiku model and Meta’s Llama 3.1 405B and 70B models compared to their standard versions. This feature is especially helpful for time-sensitive workloads where rapid response is business critical.
In this post, we explore how Amazon Bedrock latency-optimized inference can help address the challenges of maintaining responsiveness in LLM applications. We’ll dive deep into strategies for optimizing application performance and improving user experience. Whether you’re building a new AI application or optimizing an existing one, you’ll find practical guidance on both the technical aspects of latency optimization and real-world implementation approaches. We begin by explaining latency in LLM applications.
Understanding latency in LLM applications
Latency in LLM applications is a multifaceted concept that goes beyond simple response times. When you interact with an LLM, you can receive responses in one of two ways: streaming or nonstreaming mode. In nonstreaming mode, you wait for the complete response before receiving any output—like waiting for someone to finish writing a letter. In streaming mode, you receive the response as it’s being generated—like watching someone type in real time.
To effectively optimize AI applications for responsiveness, we need to understand the key metrics that define latency and how they impact user experience. These metrics differ between streaming and nonstreaming modes and understanding them is crucial for building responsive AI applications.
Time to first token (TTFT) represents how quickly your streaming application starts responding. It’s the amount of time from when a user submits a request until they receive the beginning of a response (the first word, token, or chunk). Think of it as the initial reaction time of your AI application.
TTFT is affected by several factors:
Length of your input prompt (longer prompts generally mean higher TTFT)
Network conditions and geographic location (if the prompt is getting processed in a different region, it will take longer)
Calculation: TTFT = Time to first chunk/token – Time from request submission Interpretation: Lower is better
Output tokens per second (OTPS) indicates how quickly your model generates new tokens after it starts responding. This metric is crucial for understanding the actual throughput of your model and how it maintains its response speed throughout longer generations.
OTPS is influenced by:
Model size and complexity
Length of the generated response
Complexity of the task and prompt
System load and resource availability
Calculation: OTPS = Total number of output tokens / Total generation time Interpretation: Higher is better
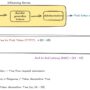
End-to-end latency (E2E) measures the total time from request to complete response. As illustrated in the figure above, this encompasses the entire interaction.
Key factors affecting this metric include:
Input prompt length
Requested output length
Model processing speed
Network conditions
Complexity of the task and prompt
Postprocessing requirements (for example, using Amazon Bedrock Guardrails or other quality checks)
Calculation: E2E latency = Time at completion of request – Time from request submission Interpretation: Lower is better
Although these metrics provide a solid foundation for understanding latency, there are additional factors and considerations that can impact the perceived performance of LLM applications. These metrics are shown in the following diagram.
The role of tokenization
An often-overlooked aspect of latency is how different models tokenize text differently. Each model’s tokenization strategy is defined by its provider during training and can’t be modified. For example, a prompt that generates 100 tokens in one model might generate 150 tokens in another. When comparing model performance, remember that these inherent tokenization differences can affect perceived response times, even when the models are equally efficient. Awareness of this variation can help you better interpret latency differences between models and make more informed decisions when selecting models for your applications.
Understanding user experience
The psychology of waiting in AI applications reveals interesting patterns about user expectations and satisfaction. Users tend to perceive response times differently based on the context and complexity of their requests. A slight delay in generating a complex analysis might be acceptable, and even a small lag in a conversational exchange can feel disruptive. This understanding helps us set appropriate optimization priorities for different types of applications.
Consistency over speed
Consistent response times, even if slightly slower, often lead to better user satisfaction than highly variable response times with occasional quick replies. This is crucial for streaming responses and implementing optimization strategies.
Keeping users engaged
When processing times are longer, simple indicators such as “Processing your request” or “loading animations” messages help keep users engaged, especially during the initial response time. In such scenarios, you want to optimize for TTFT.
Balancing speed, quality, and cost
Output quality often matters more than speed. Users prefer accurate responses over quick but less reliable ones. Consider benchmarking your user experience to find the best latency for your use case, considering that most humans can’t read faster than 225 words per minute and therefore extremely fast response can hinder user experience.
By understanding these nuances, you can make more informed decisions to optimize your AI applications for better user experience.
Latency-optimized inference: A deep dive
Amazon Bedrock latency-optimized inference capabilities are designed to provide higher OTPS and quicker TTFT, enabling applications to handle workloads more reliably. This optimization is available in the US East (Ohio) AWS Region for select FMs, including Anthropic’s Claude 3.5 Haiku and Meta’s Llama 3.1 models (both 405B and 70B versions). The optimization supports the following models:
Higher OTPS – Faster token generation after the model starts responding
Quicker TTFT – Faster initial response time
Implementation
To enable latency optimization, you need to set the latency parameter to optimized in your API calls:
# Using converse api without streaming
response = bedrock_runtime.converse(
modelId=’us.anthropic.claude-3-5-haiku-20241022-v1:0′,
messages=[{
‘role’: ‘user’,
‘content’: [{
‘text’:’Write a story about music generating AI models’
}]
}],
performanceConfig={‘latency’: ‘optimized’}
)
For streaming responses:
# using converse API with streaming
response = bedrock_runtime.converse_stream(
modelId=’us.anthropic.claude-3-5-haiku-20241022-v1:0′,
messages=[{
‘role’: ‘user’,
‘content’: [{
‘text’:’Write a story about music generating AI models’
}]
}],
performanceConfig={‘latency’: ‘optimized’}
)
Benchmarking methodology and results
To understand the performance gains both for TTFT and OTPS, we conducted an offline experiment with around 1,600 API calls spread across various hours of the day and across multiple days. We used a dummy dataset comprising different task types: sequence-counting, story-writing, summarization, and translation. The input prompt ranged from 100 tokens to 100,000 tokens, and the output tokens ranged from 100 to 1,000 output tokens. These tasks were chosen to represent varying complexity levels and various model output lengths. Our test setup was hosted in the US West (Oregon) us-west-2 Region, and both the optimized and standard models were hosted in US East (Ohio) us-east-2 Region. This cross-Region setup introduced realistic network variability, helping us measure performance under conditions similar to real-world applications.
When analyzing the results, we focused on the key latency metrics discussed earlier: TTFT and OTPS. As a quick recap, lower TTFT values indicate faster initial response times, and higher OTPS values represent faster token generation speeds. We also looked at the 50th percentile (P50) and 90th percentile (P90) values to understand both typical performance and performance boundaries under challenging or upper bound conditions. Following the central limit theorem, we observed that, with sufficient samples, our results converged toward consistent values, providing reliable performance indicators.
It’s important to note that these results are from our specific test environment and datasets. Your actual results may vary based on your specific use case, prompt length, expected model response length, network conditions, client location, and other implementation components. When conducting your own benchmarks, make sure your test dataset represents your actual production workload characteristics, including typical input lengths and expected output patterns.
Benchmark results
Our experiments with the latency-optimized models revealed substantial performance improvements across both TTFT and OTPS metrics. The results in the following table show the comparison between standard and optimized versions of Anthropic’s Claude 3.5 Haiku and Meta’s Llama 3.1 70B models. For each model, we ran multiple iterations of our test scenarios to promote reliable performance. The improvements were particularly notable in high-percentile measurements, suggesting more consistent performance even under challenging conditions.
Model
Inference profile
TTFT P50 (in seconds)
TTFT P90 (in seconds)
OTPS P50
OTPS P90
us.anthropic.claude-3-5-haiku-20241022-v1:0
Optimized
0.6
1.4
85.9
152.0
us.anthropic.claude-3-5-haiku-20241022-v1:0
Standard
1.1
2.9
48.4
67.4
Improvement
-42.20%
-51.70%
77.34%
125.50%
us.meta.llama3-1-70b-instruct-v1:0
Optimized
0.4
1.2
137.0
203.7
us.meta.llama3-1-70b-instruct-v1:0
Standard
0.9
42.8
30.2
32.4
Improvement
-51.65%
-97.10%
353.84%
529.33%
These results demonstrate significant improvements across all metrics for both models. For Anthropic’s Claude 3.5 Haiku model, the optimized version achieved up to 42.20% reduction in TTFT P50 and up to 51.70% reduction in TTFT P90, indicating more consistent initial response times. Additionally, the OTPS saw improvements of up to 77.34% at the P50 level and up to 125.50% at the P90 level, enabling faster token generation.
The gains for Meta’s Llama 3.1 70B model are even more impressive, with the optimized version achieving up to 51.65% reduction in TTFT P50 and up to 97.10% reduction in TTFT P90, providing consistently rapid initial responses. Furthermore, the OTPS saw a massive boost, with improvements of up to 353.84% at the P50 level and up to 529.33% at the P90 level, enabling up to 5x faster token generation in some scenarios.
Although these benchmark results show the powerful impact of latency-optimized inference, they represent just one piece of the optimization puzzle. To make best use of these performance improvements and achieve the best possible response times for your specific use case, you’ll need to consider additional optimization strategies beyond merely enabling the feature.
Comprehensive guide to LLM latency optimization
Even though Amazon Bedrock latency-optimized inference offers great improvements from the start, getting the best performance requires a well-rounded approach to designing and implementing your application. In the next section, we explore some other strategies and considerations to make your application as responsive as possible.
Prompt engineering for latency optimization
When optimizing LLM applications for latency, the way you craft your prompts affects both input processing and output generation.
To optimize your input prompts, follow these recommendations:
Keep prompts concise – Long input prompts take more time to process and increase TTFT. Create short, focused prompts that prioritize necessary context and information.
Break down complex tasks – Instead of handling large tasks in a single request, break them into smaller, manageable chunks. This approach helps maintain responsiveness regardless of task complexity.
Smart context management – For interactive applications such as chatbots, include only relevant context instead of entire conversation history.
Token management – Different models tokenize text differently, meaning the same input can result in different numbers of tokens. Monitor and optimize token usage to keep performance consistent. Use token budgeting to balance context preservation with performance needs.
To engineer for brief outputs, follow these recommendations:
Engineer for brevity – Include explicit length constraints in your prompts (for example, “respond in 50 words or less”)
Use system messages – Set response length constraints through system messages
Balance quality and length – Make sure response constraints don’t compromise output quality
One of the best ways to make your AI application feel faster is to use streaming. Instead of waiting for the complete response, streaming shows the response as it’s being generated—like watching someone type in real-time. Streaming the response is one of the most effective ways to improve perceived performance in LLM applications maintaining user engagement.
These techniques can significantly reduce token usage and generation time, improving both latency and cost-efficiency.
Building production-ready AI applications
Although individual optimizations are important, production applications require a holistic approach to latency management. In this section, we explore how different system components and architectural decisions impact overall application responsiveness.
System architecture and end-to-end latency considerations
In production environments, overall system latency extends far beyond model inference time. Each component in your AI application stack contributes to the total latency experienced by users. For instance, when implementing responsible AI practices through Amazon Bedrock Guardrails, you might notice a small additional latency overhead. Similar considerations apply when integrating content filtering, user authentication, or input validation layers. Although each component serves a crucial purpose, their cumulative impact on latency requires careful consideration during system design.
Geographic distribution plays a significant role in application performance. Model invocation latency can vary considerably depending on whether calls originate from different Regions, local machines, or different cloud providers. This variation stems from data travel time across networks and geographic distances. When designing your application architecture, consider factors such as the physical distance between your application and model endpoints, cross-Region data transfer times, and network reliability in different Regions. Data residency requirements might also influence these architectural choices, potentially necessitating specific Regional deployments.
Integration patterns significantly impact how users perceive application performance. Synchronous processing, although simpler to implement, might not always provide the best user experience. Consider implementing asynchronous patterns where appropriate, such as pre-fetching likely responses based on user behavior patterns or processing noncritical components in the background. Request batching for bulk operations can also help optimize overall system throughput, though it requires careful balance with response time requirements.
As applications scale, additional infrastructure components become necessary but can impact latency. Load balancers, queue systems, cache layers, and monitoring systems all contribute to the overall latency budget. Understanding these components’ impact helps in making informed decisions about infrastructure design and optimization strategies.
Complex tasks often require orchestrating multiple model calls or breaking down problems into subtasks. Consider a content generation system that first uses a fast model to generate an outline, then processes different sections in parallel, and finally uses another model for coherence checking and refinement. This orchestration approach requires careful attention to cumulative latency impact while maintaining output quality. Each step needs appropriate timeouts and fallback mechanisms to provide reliable performance under various conditions.
Prompt caching for enhanced performance
Although our focus is on latency-optimized inference, it’s worth noting that Amazon Bedrock also offers prompt caching (in preview) to optimize for both cost and latency. This feature is particularly valuable for applications that frequently reuse context, such as document-based chat assistants or applications with repetitive query patterns. When combined with latency-optimized inference, prompt caching can provide additional performance benefits by reducing the processing overhead for frequently used contexts.
Prompt routing for intelligent model selection
Similar to prompt caching, Amazon Bedrock Intelligent Prompt Routing (in preview) is another powerful optimization feature. This capability automatically directs requests to different models within the same model family based on the complexity of each prompt. For example, simple queries can be routed to faster, more cost-effective models, and complex requests that require deeper understanding are directed to more sophisticated models. This automatic routing helps optimize both performance and cost without requiring manual intervention.
Architectural considerations and caching
Application architecture plays a crucial role in overall latency optimization. Consider implementing a multitiered caching strategy that includes response caching for frequently requested information and smart context management for historical information. This isn’t only about storing exact matches—consider implementing semantic caching that can identify and serve responses to similar queries.
Balancing model sophistication, latency, and cost
In AI applications, there’s a constant balancing act between model sophistication, latency, and cost, as illustrated in the diagram. Although more advanced models often provide higher quality outputs, they might not always meet strict latency requirements. In such cases, using a less sophisticated but faster model might be the better choice. For instance, in applications requiring near-instantaneous responses, opting for a smaller, more efficient model could be necessary to meet latency goals, even if it means a slight trade-off in output quality. This approach aligns with the broader need to optimize the interplay between cost, speed, and quality in AI systems.
Features such as Amazon Bedrock Intelligent Prompt Routing help manage this balance effectively. By automatically handling model selection based on request complexity, you can optimize for all three factors—quality, speed, and cost—without requiring developers to commit to a single model for all requests.
As we’ve explored throughout this post, optimizing LLM application latency involves multiple strategies, from using latency-optimized inference and prompt caching to implementing intelligent routing and careful prompt engineering. The key is to combine these approaches in a way that best suits your specific use case and requirements.
Conclusion
Making your AI application fast and responsive isn’t a one-time task, it’s an ongoing process of testing and improvement. Amazon Bedrock latency-optimized inference gives you a great starting point, and you’ll notice significant improvements when you combine it with the strategies we’ve discussed.
Ready to get started? Here’s what to do next:
Try our sample notebook to benchmark latency for your specific use case
Enable latency-optimized inference in your application code
Set up Amazon CloudWatch metrics to monitor your application’s performance
Remember, in today’s AI applications, being smart isn’t enough, being responsive is just as important. Start implementing these optimization strategies today and watch your application’s performance improve.
About the Authors
Ishan Singh is a Generative AI Data Scientist at Amazon Web Services, where he helps customers build innovative and responsible generative AI solutions and products. With a strong background in AI/ML, Ishan specializes in building Generative AI solutions that drive business value. Outside of work, he enjoys playing volleyball, exploring local bike trails, and spending time with his wife and dog, Beau.
Yanyan Zhang is a Senior Generative AI Data Scientist at Amazon Web Services, where she has been working on cutting-edge AI/ML technologies as a Generative AI Specialist, helping customers use generative AI to achieve their desired outcomes. Yanyan graduated from Texas A&M University with a PhD in Electrical Engineering. Outside of work, she loves traveling, working out, and exploring new things.
Rupinder Grewal is a Senior AI/ML Specialist Solutions Architect with AWS. He currently focuses on serving of models and MLOps on Amazon SageMaker. Prior to this role, he worked as a Machine Learning Engineer building and hosting models. Outside of work, he enjoys playing tennis and biking on mountain trails.
Vivek Singh is a Senior Manager, Product Management at AWS AI Language Services team. He leads the Amazon Transcribe product team. Prior to joining AWS, he held product management roles across various other Amazon organizations such as consumer payments and retail. Vivek lives in Seattle, WA and enjoys running, and hiking.
Ankur Desai is a Principal Product Manager within the AWS AI Services team.













