This post was written with Darrel Cherry, Dan Siddall, and Rany ElHousieny of Clearwater Analytics.
As global trading volumes rise rapidly each year, capital markets firms are facing the need to manage large and diverse datasets to stay ahead. These datasets aren’t just expansive in volume; they’re critical in driving strategy development, enhancing execution, and streamlining risk management. The explosion of data creation and utilization, paired with the increasing need for rapid decision-making, has intensified competition and unlocked opportunities within the industry. To remain competitive, capital markets firms are adopting Amazon Web Services (AWS) Cloud services across the trade lifecycle to rearchitect their infrastructure, remove capacity constraints, accelerate innovation, and optimize costs.
Generative AI, AI, and machine learning (ML) are playing a vital role for capital markets firms to speed up revenue generation, deliver new products, mitigate risk, and innovate on behalf of their customers. A great example of such innovation is our customer Clearwater Analytics and their use of large language models (LLMs) hosted on Amazon SageMaker JumpStart, which has propelled asset management productivity and delivered AI-powered investment management productivity solutions to their customers.
In this post, we explore Clearwater Analytics’ foray into generative AI, how they’ve architected their solution with Amazon SageMaker, and dive deep into how Clearwater Analytics is using LLMs to take advantage of more than 18 years of experience within the investment management domain while optimizing model cost and performance.
About Clearwater Analytics
Clearwater Analytics (NYSE: CWAN) stands at the forefront of investment management technology. Founded in 2004 in Boise, Idaho, Clearwater has grown into a global software-as-a-service (SaaS) powerhouse, providing automated investment data reconciliation and reporting for over $7.3 trillion in assets across thousands of accounts worldwide. With a team of more than 1,600 professionals and a long-standing relationship with AWS dating back to 2008, Clearwater has consistently pushed the boundaries of financial technology innovation.
In May 2023, Clearwater embarked on a journey into the realm of generative AI, starting with a private, secure generative AI chat-based assistant for their internal workforce, enhancing client inquiries through Retrieval Augmented Generation (RAG). As a result, Clearwater was able to increase assets under management (AUM) over 20% without increasing operational headcount. By September of the same year, Clearwater unveiled its generative AI customer offerings at the Clearwater Connect User Conference, marking a significant milestone in their AI-driven transformation.
About SageMaker JumpStart
Amazon SageMaker JumpStart is an ML hub that can help you accelerate your ML journey. With SageMaker JumpStart, you can evaluate, compare, and select foundation models (FMs) quickly based on predefined quality and responsibility metrics to perform tasks such as article summarization and image generation. Pre-trained models are fully customizable for your use case with your data, and you can effortlessly deploy them into production with the user interface or AWS SDK. You can also share artifacts, including models and notebooks, within your organization to accelerate model building and deployment, and admins can control which models are visible to users within their organization.
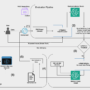
Clearwater’s generative AI solution architecture
Clearwater Analytics’ generative AI architecture supports a wide array of vertical solutions by merging extensive functional capabilities through the LangChain framework, domain knowledge through RAG, and customized LLMs hosted on Amazon SageMaker. This integration has resulted in a potent asset for both Clearwater customers and their internal teams.
The following image illustrates the solution architecture.
As of September 2024, the AI solution supports three core applications:
Clearwater Intelligent Console (CWIC) – Clearwater’s customer-facing AI application. This assistant framework is built upon three pillars:
Knowledge awareness – Using RAG, CWIC compiles and delivers comprehensive knowledge that is crucial for customers from intricate calculations of book value to period-end reconciliation processes.
Application awareness – Transforming novice users into power users instantly, CWIC guides clients to inquire about Clearwater’s applications and receive direct links to relevant investment reports. For instance, if a client needs information on their yuan exposure, CWIC employs its tool framework to identify and provide links to the appropriate currency exposure reports.
Data awareness – Digging deep into portfolio data, CWIC adeptly manages complex queries, such as validating book yield tie-outs, by accessing customer-specific data and performing real-time calculations.The following image shows a snippet of the generative AI assistance within the CWIC.
Crystal – Clearwater’s advanced AI assistant with expanded capabilities that empower internal teams’ operations. Crystal shares CWIC’s core functionalities but benefits from broader data sources and API access. Enhancements driven by Crystal have achieved efficiency gains between 25% and 43%, improving Clearwater’s ability to manage substantial increases in AUM without increases in staffing.
CWIC Specialists – Their most recent solution CWIC Specialists are domain-specific generative AI agents equipped to handle nuanced investment tasks, from accounting to regulatory compliance. These agents can work in single or multi-agentic workflows to answer questions, perform complex operations, and collaborate to solve various investment-related tasks. These specialists assist both internal teams and customers in domain specific areas, such as investment accounting, regulatory requirements, and compliance information. Each specialist is underpinned by thousands of pages of domain documentation, which feeds into the RAG system and is used to train smaller, specialized models with Amazon SageMaker JumpStart. This approach enhances cost-effectiveness and performance to promote high-quality interactions.
In the next sections, we dive deep into how Clearwater analytics is using Amazon SageMaker JumpStart to fine-tune models for productivity improvement and to deliver new AI services.
Clearwater’s Use of LLMs hosted on Amazon SageMaker JumpStart
Clearwater employs a two-pronged strategy for using LLMs. This approach addresses both high-complexity scenarios requiring powerful language models and domain-specific applications demanding rapid response times.
Advanced foundation models – For tasks involving intricate reasoning or creative output, Clearwater uses state-of-the-art pre-trained models such as Anthropic’s Claude or Meta’s Llama. These models excel in handling complex queries and generating innovative solutions.
Fine-tuned models for specialized knowledge – In cases where domain-specific expertise or swift responses are crucial, Clearwater uses fine-tuned models. These customized LLMs are optimized for industries or tasks that require accuracy and efficiency.
Fine-tuned models through domain adaptation with Amazon SageMaker JumpStart
Although general LLMs are powerful, their accuracy can be put to the test in specialized domains. This is where domain adaptation, also known as continued pre-training, comes into play. Domain adaptation is a sophisticated form of transfer learning that allows a pre-trained model to be fine-tuned for optimal performance in a different, yet related, target domain. This approach is particularly valuable when there’s a scarcity of labeled data in the target domain but an abundance in a related source domain.
These are some of the key benefits for domain adaptation:
Cost-effectiveness – Creating a curated set of questions and answers for instruction fine-tuning can be prohibitively expensive and time-consuming. Domain adaptation eliminates the need for thousands of manually created Q&As.
Comprehensive learning – Unlike instruction tuning, which only learns from provided questions, domain adaptation extracts information from entire documents, resulting in a more thorough understanding of the subject matter.
Efficient use of expertise – Domain adaptation frees up human experts from the time-consuming task of generating questions so they can focus on their primary responsibilities.
Faster deployment – With domain adaptation, specialized AI models can be developed and deployed more quickly, accelerating time to market for AI-powered solutions.
AWS has been at the forefront of domain adaptation, creating a framework to allow creating powerful, specialized AI models. Using this framework, Clearwater has been able to train smaller, faster models tailored to specific domains without the need for extensive labeled datasets. This innovative approach allows Clearwater to power digital specialists with a finely tuned model trained on a particular domain. The result? More responsive LLMs that form the backbone of their cutting-edge generative AI services.
The evolution of fine-tuning with Amazon SageMaker JumpStart
Clearwater is collaborating with AWS to enhance their fine-tuning processes. Amazon SageMaker JumpStart offered them a framework for domain adaptation. During the year, Clearwater has witnessed significant improvements in the user interface and effortlessness of fine-tuning using SageMaker JumpStart.
For instance, the code required to set up and fine-tune a GPT-J-6B model has been drastically streamlined. Previously, it required a data scientist to write over 100 lines of code within an Amazon SageMaker Notebook to identify and retrieve the proper image, set the right training script, and import the right hyperparameters. Now, using SageMaker JumpStart and advancements in the field, the process has streamlined to a few lines of code:
estimator = JumpStartEstimator(
model_id=model_id,
hyperparameters={“epoch”: “3”, “per_device_train_batch_size”: “4”},
)
# initiate the traning process with the path of the data
estimator.fit(
{“train”: training_dataset_s3_path, “validation”: validation_dataset_s3_path}, logs=True
)
A fine-tuning example: Clearwater’s approach
For Clearwater’s AI, the team successfully fine-tuned a GPT-J-6B (huggingface-textgeneration1-gpt-j- 6bmodel) model with domain adaptation using Amazon SageMaker JumpStart. The following are the concrete steps used for the fine-tuning process to serve as a blueprint for others to implement similar strategies. A detailed tutorial can found in this amazon-sagemaker-examples repo.
Document assembly – Gather all relevant documents that will be used for training. This includes help content, manuals, and other domain-specific text. The data Clearwater used for training this model is public help content which contains no client data. Clearwater exclusively uses client data, with their collaboration and approval, to fine-tune a model dedicated solely to the specific client. Curation, cleaning and de-identification of data is necessary for training and subsequent tuning operations.
Test set creation – Develop a set of questions and answers that will be used to evaluate the model’s performance before and after fine-tuning. Clearwater has implemented a sophisticated model evaluation system for additional assessment of performance for open source and commercial models. This is covered more in the Model evaluation and optimization section later in this post.
Pre-trained model deployment – Deploy the original, pre-trained GPT-J-6B model.
Baseline testing – Use the question set to test the pre-trained model, establishing a performance baseline.
Pre-trained model teardown – Remove the pre-trained model to free up resources.
Data preparation – Upload the assembled documents to an S3 bucket, making sure they’re in a format suitable for the fine-tuning process.
Fine-tuning – Train the new model using the uploaded documents, adjusting hyperparameters as needed.
Fine-tuned model testing – Evaluate the fine-tuned model using the same question set used for the baseline.
Fine-tuned model teardown – If not immediately needed, tear down the fine-tuned model to optimize resource usage.
RAG comparison – Test a RAG-based system using the same question set for an additional point of comparison.
Performance evaluation – Analyze the results from all tests to assess the effectiveness of the fine-tuning process.
This is how the results look before tuning an open source model (GGPT-J-6B), after tuning, and using a commercial model with a larger context window (Claude-3.5-Sonnet).
Prompt
What does Clearwater Compliance module do?
Reference Answer
The Clearwater Compliance module supports client investment policies, providing daily updates, including compliance warnings and violations. Clearwater’s Compliance module monitors various portfolio characteristics, including asset and security type allocation, sector exposure, investment time horizon, and credit quality. The Compliance module enables users to establish and update investment policies, monitor changes to accounts, and provide audit reporting. Rules provide flexibility to evaluate data from the individual security-level to aggregate values at the portfolio-level. User-identified investments can also be prohibited. Multiple investment policies can be applied to individual accounts and aggregates of accounts.
GPT-J-6B pre-trained
GPT-J-6B fine-tuned
Claude-3.5-Sonnet with RAG
The Clearwater Compliance module is an integrated set of controls you can use to manage your compliance with the federal and state requirements for the handling and transportation of hazardous materials.
The Clearwater Compliance module is a suite of tools designed to help clients monitor and manage their compliance policies and procedures. · Compliance Overview dashboard – Provides a high-level view of compliance policies and a history of compliance policy changes. · Compliance Settings tool – Users can update compliance settings, such as the frequency at which compliance policies are checked and the level of compliance required to access a compliance-restricted area of the website. · Compliance Audit report – Provides a detailed list of policies and rules that weren’t met. The report includes a breakdown of rule violations and the actions required to bring the policies into compliance. · Compliance Notifications tool – Sends notifications to designated recipients, such as the client’s compliance officer, when a compliance rule is about to expire or has been violated. · Compliance Documents tool – Users can upload and manage compliance policies and rules.
The Clearwater Compliance module is a sophisticated tool designed to support and monitor client investment policies. Here’s what it does: · Daily Monitoring – Provides daily updates, including compliance warnings and violations, to foster ongoing adherence to investment policies. · Portfolio characteristic tracking –Monitors various aspects of portfolios, including asset and security type allocation, sector exposure, investment time horizon, and credit quality. · Policy management – Users can establish, update, and manage investment policies through the module. · Flexible rule application – Allows for the evaluation of compliance rules at both individual security and portfolio levels. · Custom policy creation – Clearwater works with clients to create compliance rules based on their specific investment policies and interpretations. · Multi-account support – Multiple investment policies can be applied to individual accounts or aggregates of accounts. · Reporting and auditing – Generates audit reports and provides tools for monitoring account changes. · Risk mitigation – Offers integrated, customized daily reports on the Clearwater Reporting Site, to proactively manage risk. · Regulatory compliance – Includes external and regulatory policies when provided by the client, providing broader compliance coverage. · Violation tracking – Identifies compliance rule violations, tracks the number of days in violation, and allows for resolution statements.
Although the Compliance module is comprehensive, it has some limitations. It only supports objective rules using data available within the Clearwater system and doesn’t cover areas such as pre-trade compliance, investments without publicly available data, or scenario testing.
Overall, the Clearwater Compliance module serves as a robust tool for maintaining investment policy compliance, offering daily monitoring, customization, and reporting features to support effective risk management and regulatory adherence.
Model evaluation and optimization
Clearwater employs a sophisticated evaluation system to assess the performance of new models available on Amazon SageMaker JumpStart. This means that only models demonstrating superior capabilities are integrated into the production environment.
Clearwater’s LLM operations (LLMOps) pipeline plays a crucial role in this process, automating the evaluation and seamless integration of new models. This commitment to using the most effective LLMs for each unique task with cutting-edge technology and optimal performance is the cornerstone of Clearwater’s approach.
The evaluation phase is crucial for determining the success of the fine-tuning process. As you determine the evaluation process and framework that should be used, you need to make sure they fit the criteria for their domain. At Clearwater, we designed our own internal evaluation framework to meet the specific needs of our investment management and accounting domains.
Here are key considerations:
Performance comparison – The fine-tuned model should outperform the pre-trained model on domain-specific tasks. If it doesn’t, it might indicate that the pre-trained model already had significant knowledge in this area.
RAG benchmark – Compare the fine-tuned model’s performance against a RAG system using a pre-trained model. If the fine-tuned model doesn’t at least match RAG performance, troubleshooting is necessary.
Troubleshooting checklist:
Data format suitability for fine-tuning
Completeness of the training dataset
Hyperparameter optimization
Potential overfitting or underfitting
Cost-benefit analysis. That is, estimate the operational costs of using a RAG system with a pre-tuned model (for example, Claude-3.5 Sonnet) compared with deploying the fine-tuned model at production scale.
Advance considerations:
Iterative fine-tuning – Consider multiple rounds of fine-tuning, gradually introducing more specific or complex data.
Multi-task learning – If applicable, fine-tune the model on multiple related domains simultaneously to improve its versatility.
Continual learning – Implement strategies to update the model with new information over time without full retraining.
Conclusion
For businesses and organizations seeking to harness the power of AI in specialized domains, domain adaptation presents significant opportunities. Whether you’re in healthcare, finance, legal services, or any other specialized field, adapting LLMs to your specific needs can provide a significant competitive advantage.
By following this comprehensive approach with Amazon SageMaker, organizations can effectively adapt LLMs to their specific domains, achieving better performance and potentially more cost-effective solutions than generic models with RAG systems. However, the process requires careful monitoring, evaluation, and optimization to achieve the best results.
As we’ve observed with Clearwater’s success, partnering with an experienced AI company such as AWS can help navigate the complexities of domain adaptation and unlock its full potential. By embracing this technology, you can create AI solutions that are not just powerful, but also truly tailored to your unique requirements and expertise.
The future of AI isn’t just about bigger models, but smarter, more specialized ones. Domain adaptation is paving the way for this future, and those who harness its power will emerge as leaders in their respective industries.
Get started with Amazon SageMaker JumpStart on your fine-tuning LLM journey today.
About the Authors
Darrel Cherry is a Distinguished Engineer with over 25 years of experience leading organizations to create solutions for complex business problems. With a passion for emerging technologies, he has architected large cloud and data processing solutions, including machine learning and deep learning AI applications. Darrel holds 19 US patents and has contributed to various industry publications. In his current role at Clearwater Analytics, Darrel leads technology strategy for AI solutions, as well as Clearwater’s overall enterprise architecture. Outside the professional sphere, he enjoys traveling, auto racing, and motorcycling, while also spending quality time with his family.
Dan Siddall, a Staff Data Scientist at Clearwater Analytics, is a seasoned expert in generative AI and machine learning, with a comprehensive understanding of the entire ML lifecycle from development to production deployment. Recognized for his innovative problem-solving skills and ability to lead cross-functional teams, Dan leverages his extensive software engineering background and strong communication abilities to bridge the gap between complex AI concepts and practical business solutions.
Rany ElHousieny is an Engineering Leader at Clearwater Analytics with over 30 years of experience in software development, machine learning, and artificial intelligence. He has held leadership roles at Microsoft for two decades, where he led the NLP team at Microsoft Research and Azure AI, contributing to advancements in AI technologies. At Clearwater, Rany continues to leverage his extensive background to drive innovation in AI, helping teams solve complex challenges while maintaining a collaborative approach to leadership and problem-solving.
Pablo Redondo is a Principal Solutions Architect at Amazon Web Services. He is a data enthusiast with over 18 years of FinTech and healthcare industry experience and is a member of the AWS Analytics Technical Field Community (TFC). Pablo has been leading the AWS Gain Insights Program to help AWS customers achieve better insights and tangible business value from their data analytics and AI/ML initiatives. In his spare time, Pablo enjoys quality time with his family and plays pickleball in his hometown of Petaluma, CA.
Prashanth Ganapathy is a Senior Solutions Architect in the Small Medium Business (SMB) segment at AWS. He enjoys learning about AWS AI/ML services and helping customers meet their business outcomes by building solutions for them. Outside of work, Prashanth enjoys photography, travel, and trying out different cuisines.